Corso
Lavorare con i dati geospaziali in Python
4 h
17.8K
In questa sezione vedremo tecniche di data augmentation per audio, testo, immagini e approcci avanzati.
Approfondisci trasformazioni e manipolazioni di immagini con esercizi pratici nel nostro percorso di abilità Image Processing with Python.
La data augmentation può essere applicata a tutte le applicazioni di machine learning in cui è difficile acquisire dati di qualità. Inoltre, può aiutare a migliorare robustezza e prestazioni del modello in tutti i campi di studio.
Acquisire ed etichettare dataset di imaging medico è dispendioso in termini di tempo e costi. Serve anche un esperto di dominio per validare il dataset prima dell’analisi. Usare trasformazioni geometriche e altre tecniche può aiutarti ad addestrare modelli di machine learning robusti e accurati.
Ad esempio, nel caso della classificazione della polmonite, puoi usare ritagli casuali, zoom, stretching e trasformazioni dello spazio colore per migliorare le prestazioni del modello. Tuttavia, presta attenzione a certe augmentations perché possono produrre l’effetto opposto. Per esempio, rotazioni casuali e riflessioni lungo l’asse x non sono consigliate per i dataset di radiografie.
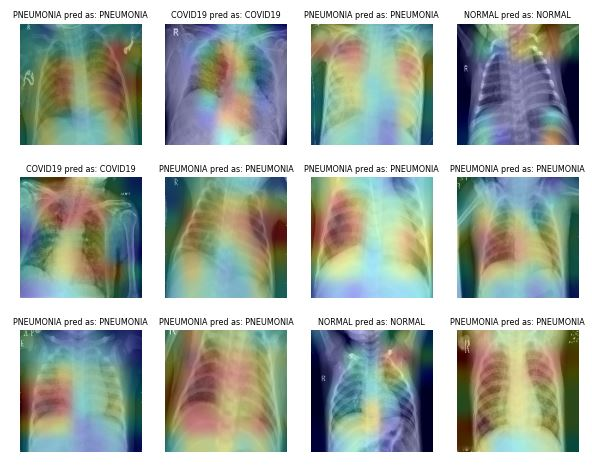
Immagine da ibrahimsobh.github.io | kaggle-COVID19-Classification
I dati disponibili sulle auto a guida autonoma sono limitati e le aziende usano ambienti simulati per generare dati sintetici tramite reinforcement learning. Questo può aiutarti ad addestrare e testare applicazioni di machine learning in cui la sicurezza dei dati è un problema.

Immagine di David Silver | Autonomous Visualization System from Uber ATG
Le possibilità dei dati aumentati come simulazione sono infinite, perché possono essere usati per generare scenari reali.
La data augmentation per il testo è usata in genere quando i dati di qualità sono limitati e migliorare la metrica di performance è prioritario. Puoi applicare sinonimia, word embedding, scambio di caratteri, inserimento ed eliminazione casuale. Queste tecniche sono preziose anche per le lingue con poche risorse.
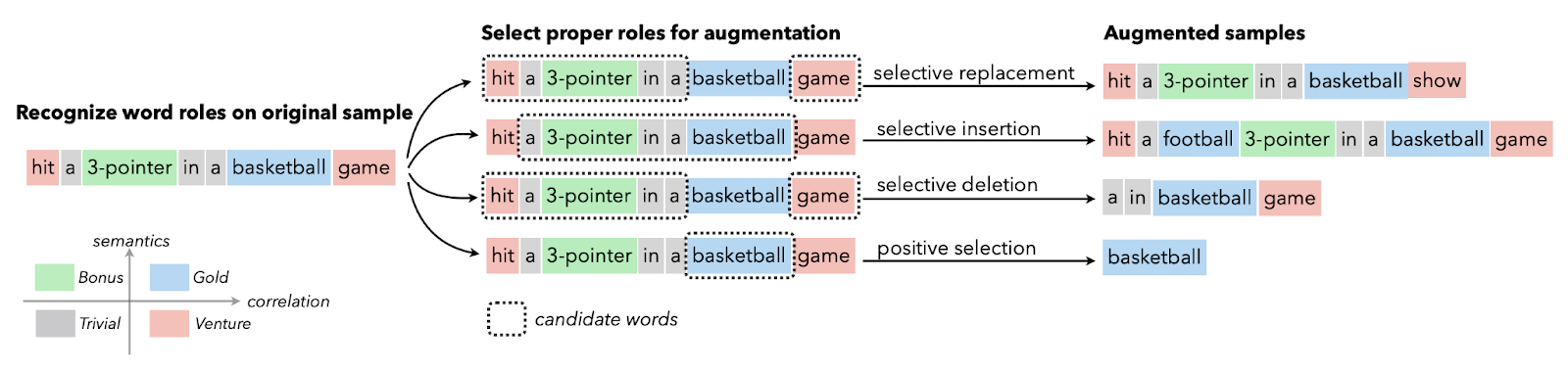
Immagine da Papers With Code | Selective Text Augmentation with Word Roles for Low-Resource Text Classification.
I ricercatori usano l’augmentation per i modelli linguistici in scenari con alto tasso di errore di riconoscimento, generazione sequenza-a-sequenza e classificazione del testo.
Nella classificazione dei suoni e nel riconoscimento vocale, la data augmentation fa miracoli. Migliora le prestazioni del modello anche in lingue con poche risorse.
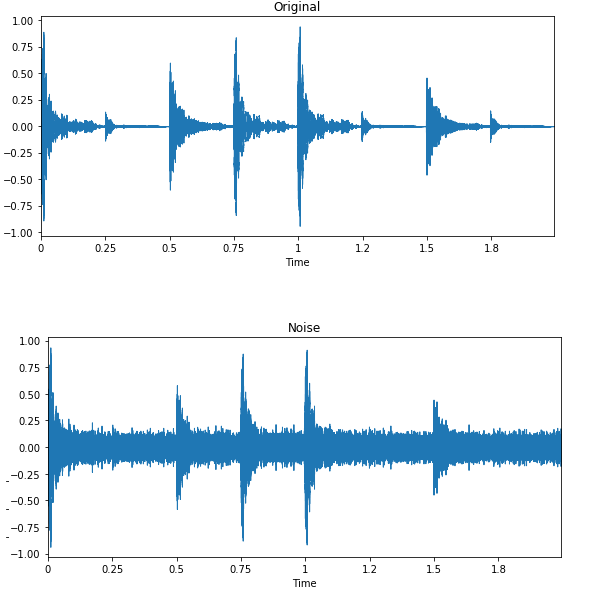
Immagine di Edward Ma | Noise Injection
L’iniezione di rumore casuale, lo shifting e la variazione dell’intonazione possono aiutarti a produrre modelli speech-to-text all’avanguardia. Puoi anche usare le GAN per generare suoni realistici per un’applicazione specifica.
Sebbene la data augmentation sia uno strumento potente per potenziare i modelli di machine learning, solleva diverse questioni etiche che richiedono attenzione:
Per sfruttare responsabilmente la data augmentation, chi la utilizza dovrebbe convalidare i dati aumentati, affrontare i bias e garantire la conformità agli standard etici e legali pertinenti.
In questo tutorial impareremo ad aumentare i dati di immagine usando Keras e TensorFlow. Inoltre, vedrai come usare i dati aumentati per addestrare un semplice classificatore binario. Il codice riportato sotto è una versione modificata dell’esempio ufficiale di TensorFlow.
Ti consigliamo di seguire il tutorial scrivendo il codice in autonomia. Il sorgente con output è disponibile in questo DataLab workbook.
Useremo TensorFlow e Keras per la data augmentation e matplotlib per visualizzare le immagini.
%%capture
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
La collezione di TensorFlow Dataset è enorme. Trovi dataset di testo, audio, video, grafi, serie temporali e immagini. In questo tutorial useremo il dataset cats_vs_dogs. Il dataset pesa 786,68 MiB, applicheremo varie tecniche di image augmentation e addestreremo un classificatore binario.
Nel codice seguente abbiamo caricato l’80% per il training, il 10% per la validazione e il 10% per il test, con etichette e metadati.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Nel dataset ci sono due classi: “cat” e “dog”.
num_classes = metadata.features['label'].num_classes
print(num_classes)2Useremo degli iteratori per estrarre solo quattro immagini casuali con etichette dal training set e visualizzarle con la funzione `.imshow()` di matplotlib.
try:
get_label_name = metadata.features['label'].int2str
train_iter = iter(train_ds)
fig = plt.figure(figsize=(7, 8))
for x in range(4):
image, label = next(train_iter)
fig.add_subplot(1, 4, x + 1)
plt.imshow(image)
plt.axis('off')
plt.title(get_label_name(label))
except StopIteration:
print("Dataset iterator is empty!")
Come possiamo vedere, abbiamo ottenuto varie immagini di cani e una di gatto.

Di solito usiamo keras.Sequential() per costruire il modello, ma possiamo anche usarlo per aggiungere i layer di augmentation.
Nell’esempio ridimensioniamo e riscaliamo l’immagine usando Keras Sequential e i layer di image augmentation. Prima ridimensioniamo l’immagine a 180x180 e poi la riscalamo di 1/255. La dimensione ridotta aiuta a risparmiare tempo, memoria e calcolo.
Come si vede, abbiamo passato correttamente l’immagine attraverso il layer di augmentation e l’output finale è ridimensionato e riscalato.
IMG_SIZE = 180
resize_and_rescale = keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
result = resize_and_rescale(image)
plt.axis('off')
plt.imshow(result);
1
Applichiamo flip e rotazione casuali alla stessa immagine. Useremo un loop, subplot e imshow per visualizzare sei immagini con augmentations geometriche casuali.
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.4),
])
plt.figure(figsize=(8, 7))
for i in range(6):
augmented_image = data_augmentation(image)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_image.numpy()/255)
plt.axis("off")Nota: se visualizzi l’avviso “WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).”, prova a convertire l’immagine in numpy e a dividerla per 255. Otterrai un output nitido invece di un’immagine slavata.

Oltre alle semplici augmentations, puoi applicare anche RandomContrast, RandomCrop, CenterCrop e RandomZoom alle immagini.
Ci sono due modi per applicare le augmentations alle immagini. Il primo è aggiungere direttamente i layer di augmentation al modello.
model = keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
# Add the model layers
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1,activation='sigmoid')
])Nota: la data augmentation è inattiva durante la fase di test. Funziona solo con Model.fit, non con Model.evaluate o Model.predict.
Il secondo metodo è applicare la data augmentation all’intero train set usando Dataset.map.
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y))Creeremo una funzione di pre-processing per processare train, validation e test set.
La funzione:
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)Creeremo un modello semplice con layer convoluzionali e densi. Assicurati che l’input shape corrisponda alla forma dell’immagine.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1,activation='softmax')
])Ora compileremo il modello e lo addestreremo per un’epoca. L’optimizer è Adam, la loss è la Binary Cross Entropy e la metrica è l’accuratezza.
Come si può osservare, abbiamo ottenuto il 51% di accuratezza in validazione in una singola esecuzione. Puoi addestrarlo per più epoche e ottimizzare gli iperparametri per ottenere risultati migliori.
La parte di costruzione e training del modello serve solo a darti un’idea di come aumentare le immagini e addestrare il modello.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)582/582 [==============================] - 98s 147ms/step - loss: 0.6993 - accuracy: 0.4961 - val_loss: 0.6934 - val_accuracy: 0.5185loss, acc = model.evaluate(test_ds)73/73 [==============================] - 4s 48ms/step - loss: 0.6932 - accuracy: 0.5013Impara a condurre analisi di immagini e a costruire, addestrare e valutare reti convoluzionali seguendo il corso Image Processing with Keras.
In questa sezione impareremo ad aumentare le immagini con TensorFlow per avere un controllo più fine della data augmentation.
Caricheremo nuovamente il dataset cats_vs_dogs con etichette e metadati.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Invece dell’immagine del gatto useremo quella del cane e applicheremo varie tecniche di augmentation.
image, label = next(iter(train_ds))
plt.imshow(image)
plt.title(get_label_name(label));
1
Creeremo la funzione visualize() per mostrare la differenza tra immagine originale e aumentata.
La funzione è piuttosto semplice. Prende in input l’immagine originale e la funzione di augmentation e visualizza la differenza con matplotlib.
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.axis("off")
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
plt.axis("off")Come si vede, abbiamo ribaltato l’immagine da sinistra a destra usando la funzione tf.image. È molto più semplice di keras.Sequential().
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
1
Convertiamo l’immagine in scala di grigi usando tf.image.rgb_to_grayscale().
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
1
Puoi anche regolare la saturazione con un fattore pari a 3.
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
1
Regola la luminosità fornendo un fattore di brightness.
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
1
Ritaglia l’immagine dal centro usando una frazione centrale di 0,5.
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
1
Ruota l’immagine di 90 gradi usando la funzione tf.image.rot90().
rotated = tf.image.rot90(image)
visualize(image, rotated)
1
Come i layer di Keras, anche tf.image() dispone di funzioni di augmentation casuali. Nell’esempio seguente applicheremo una luminosità casuale all’immagine e mostreremo più risultati.
Come si vede, la prima immagine è un po’ più scura e le due successive sono più luminose.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)


Come in Keras, possiamo applicare una funzione di data augmentation all’intero dataset usando Dataset.map().
def augment(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
image = tf.image.random_crop(image, size=[IMG_SIZE, IMG_SIZE, 3])
image = tf.image.random_brightness(image, max_delta=0.5)
return image, label
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)ImageDataGenerator() di Keras è ancora più semplice. Funziona al meglio quando carichi i dati da una directory locale o da un CSV.
Nell’esempio scaricheremo e caricheremo un piccolo dataset CIFAR10 dalla libreria predefinita dei dataset Keras.
Dopodiché applicheremo l’augmentation usando keras.preprocessing.image.ImageDataGenerator(). La funzione ruoterà casualmente, varierà altezza e larghezza e farà il flip orizzontale delle immagini.
Infine, faremo il fit di ImageDataGenerator() sul training set e mostreremo sei immagini con augmentations casuali.
Nota: la dimensione delle immagini è 32x32, quindi la visualizzazione è a bassa risoluzione.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
datagen = keras.preprocessing.image.ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
datagen.fit(x_train)
for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6):
for i in range(0, 6):
plt.subplot(2,3,i+1)
plt.imshow(X_batch[i]/255)
plt.axis('off')
break
In questa sezione vedremo altri strumenti open source che puoi usare per applicare varie tecniche di data augmentation e migliorare le prestazioni del modello.
Le trasformazioni per immagini sono disponibili nel modulo torchvision.transforms. Come in Keras, puoi aggiungere i layer di trasformazione all’interno di torch.nn.Sequential o applicare separatamente una funzione di augmentation al dataset.
Augmentor è un pacchetto Python per l’augmentation e la generazione artificiale di immagini. Puoi eseguire Perspective Skewing, Elastic Distortions, Rotating, Shearing, Cropping e Mirroring. Augmentor include anche funzionalità di base per il pre-processing delle immagini.
Albumentations è uno strumento Python veloce e flessibile per l’augmentation di immagini. È ampiamente usato in competizioni di machine learning, nell’industria e nella ricerca per migliorare le prestazioni delle reti neurali convoluzionali profonde.
Imgaug è uno strumento open source per l’augmentation di immagini. Supporta un’ampia varietà di tecniche, come rumore gaussiano, contrasto, nitidezza, ritaglio, trasformazioni affini e flip. Ha un’interfaccia stocastica semplice ma potente e include keypoint, bounding box, heatmap e mappe di segmentazione.
OpenCV è un’enorme libreria open source per computer vision, machine learning ed elaborazione di immagini. È generalmente utilizzata per costruire applicazioni in tempo reale. Puoi usare OpenCV per aumentare immagini e video senza complicazioni.
Le funzioni di image augmentation offerte da TensorFlow e Keras sono comode. Ti basta aggiungere un layer di augmentation, tf.image() o ImageDataGenerator() per eseguire l’augmentation. Oltre ai framework di deep learning, puoi usare strumenti standalone come Augmentor, Albumentations, OpenCV e Imgaug per applicare la data augmentation.
In questo tutorial abbiamo visto vantaggi, limitazioni, applicazioni e tecniche della data augmentation. Inoltre, abbiamo applicato l’image augmentation al dataset cats_vs_dogs usando Keras e TensorFlow. Se vuoi approfondire l’elaborazione di immagini, consulta il nostro percorso di abilità Image Processing with Python. Ti insegnerà le basi della trasformazione e manipolazione delle immagini, l’analisi di immagini medicali e l’image processing avanzato con Keras.
Corsi principali
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

