Kurs
Arbeiten mit Geodaten in Python
4 Std.
17.7K
In diesem Abschnitt lernen wir Audio-, Text-, Bild- und erweiterte Datenerweiterungstechniken kennen.
Lerne mehr über Bildtransformation und -manipulation mit praktischen Übungen in unserem Skill Track Bildverarbeitung mit Python.
Die Datenerweiterung kann bei allen Anwendungen des maschinellen Lernens eingesetzt werden, bei denen die Beschaffung hochwertiger Daten eine Herausforderung darstellt. Außerdem kann sie dazu beitragen, die Robustheit und Leistungsfähigkeit von Modellen in allen Bereichen zu verbessern.
Das Erfassen und Beschriften medizinischer Bilddaten ist zeitaufwändig und teuer. Außerdem brauchst du einen Fachexperten, der den Datensatz validiert, bevor du die Datenanalyse durchführst. Mit geometrischen und anderen Transformationen kannst du robuste und genaue Machine-Learning-Modelle trainieren.
Bei der Klassifizierung von Lungenentzündungen kannst du zum Beispiel zufälliges Zuschneiden, Zoomen, Dehnen und Farbraumtransformationen verwenden, um die Leistung des Modells zu verbessern. Allerdings musst du bei bestimmten Vergrößerungen vorsichtig sein, da sie zu gegenteiligen Ergebnissen führen können. Zum Beispiel sind zufällige Drehungen und Spiegelungen entlang der x-Achse für den Röntgenbilddatensatz nicht zu empfehlen.
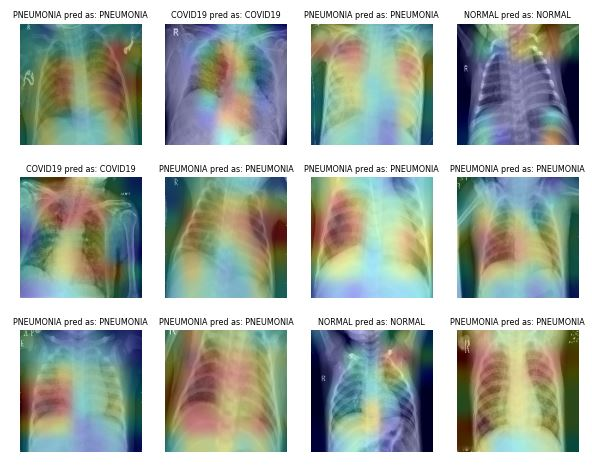
Bild von ibrahimsobh.github.io | kaggle-COVID19-Classification
Es gibt nur wenige Daten über selbstfahrende Autos, und die Unternehmen nutzen simulierte Umgebungen, um mithilfe von Reinforcement Learning synthetische Daten zu erzeugen. Es kann dir helfen, Anwendungen für maschinelles Lernen zu trainieren und zu testen, bei denen Datensicherheit ein Thema ist.

Bild von David Silver | Autonomes Visualisierungssystem von Uber ATG
Die Möglichkeiten von Augmented Data als Simulation sind endlos, denn sie können genutzt werden, um reale Szenarien zu erzeugen.
Die Textdatenerweiterung wird in der Regel in Situationen verwendet, in denen die Qualität der Daten begrenzt ist und die Verbesserung der Leistungskennzahl Vorrang hat. Du kannst Synonymerweiterung, Worteinbettung, Zeichentausch und zufälliges Einfügen und Löschen anwenden. Diese Techniken sind auch für ressourcenarme Sprachen nützlich.
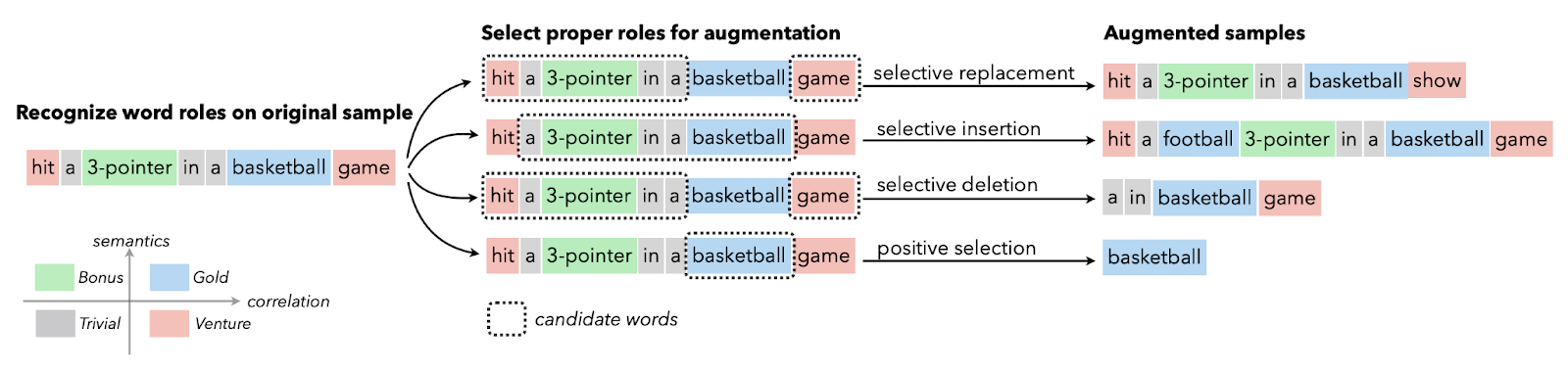
Image from Papers With Code | Selective Text Augmentation with Word Roles for Low-Resource Text Classification.
Forscher nutzen die Texterweiterung für die Sprachmodelle in Szenarien mit hoher Fehlerquote, bei der Generierung von Sequenz-zu-Sequenz-Daten und bei der Textklassifizierung.
Bei der Geräuschklassifizierung und Spracherkennung wirkt die Datenerweiterung wahre Wunder. Sie verbessert die Leistung des Modells auch bei Sprachen mit geringen Ressourcen.
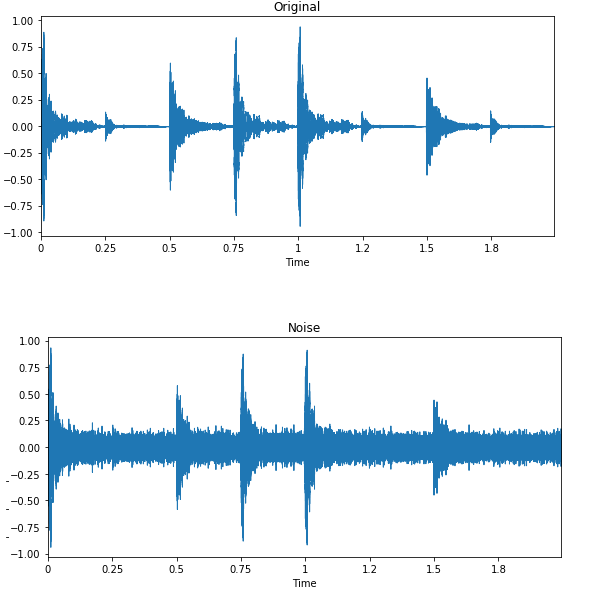
Bild von Edward Ma | Noise Injection
Die Zufallsgeräuschinjektion, das Verschieben und Ändern der Tonhöhe kann dir helfen, hochmoderne Sprache-zu-Text-Modelle zu erstellen. Du kannst GANs auch verwenden, um realistische Klänge für eine bestimmte Anwendung zu erzeugen.
In diesem Tutorial lernen wir, wie man Bilddaten mit Keras und Tensorflow anreichert. Außerdem lernst du, wie du mit deinen erweiterten Daten einen einfachen binären Klassifikator trainieren kannst. Der unten stehende Code ist die modifizierte Version des offiziellen TensorFlow-Beispiels.
Wir empfehlen dir, das Kodiertutorial zu befolgen und selbst zu üben. Der Quellcode mit den Ausgaben ist in dieser DataLab-Arbeitsmappe verfügbar.
Wir werden TensorFlow und Keras für die Datenerweiterung und Matplotlib für die Darstellung der Bilder verwenden.
%%capture
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from keras import layers
import kerasDie TensorFlow-Datensatzsammlung ist riesig. Du kannst Text-, Audio-, Video-, Grafik-, Zeitreihen- und Bilddatensätze finden. In diesem Lernprogramm verwenden wir den Datensatz "cats_vs_dogs". Der Datensatz hat eine Größe von 786,68 MB, und wir werden verschiedene Bildvergrößerungen anwenden und den binären Klassifikator trainieren.
Im folgenden Code haben wir 80 % Trainings-, 10 % Validierungs- und 10 % Testdatensatz mit Labels und Metadaten geladen.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Im Datensatz gibt es zwei Klassen: "Katze" und "Hund".
num_classes = metadata.features['label'].num_classes
print(num_classes)2Wir werden Iteratoren verwenden, um nur vier zufällige Bilder mit Beschriftungen aus der Trainingsmenge zu extrahieren und sie mit der Matplotlib-Funktion `.imshow()` anzuzeigen.
get_label_name = metadata.features['label'].int2str
train_iter = iter(train_ds)
fig = plt.figure(figsize=(7, 8))
for x in range(4):
image, label = next(train_iter)
fig.add_subplot(1, 4, x+1)
plt.imshow(image)
plt.axis('off')
plt.title(get_label_name(label));Wie wir sehen können, haben wir verschiedene Hundebilder und ein Katzenbild.

Normalerweise verwenden wir keras.Sequential(), um das Modell zu erstellen, aber wir können es auch verwenden, um Erweiterungsschichten hinzuzufügen.
In diesem Beispiel ändern wir die Größe und Skalierung des Bildes mithilfe von Keras Sequential und Image Augmentation Layern. Wir verkleinern das Bild zunächst auf 180X180 und skalieren es dann um 1/255. Die kleine Bildgröße hilft uns, Zeit, Speicherplatz und Rechenleistung zu sparen.
Wie wir sehen können, haben wir das Bild erfolgreich durch die Augmentierungsschicht geleitet und die endgültige Ausgabe ist in der Größe verändert und neu skaliert.
IMG_SIZE = 180
resize_and_rescale = keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
result = resize_and_rescale(image)
plt.axis('off')
plt.imshow(result);
1
Wenden wir nun eine zufällige Spiegelung und Drehung auf dasselbe Bild an. Wir verwenden Loop, Subplot und Imshow, um sechs Bilder mit zufälligen geometrischen Erweiterungen anzuzeigen.
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.4),
])
plt.figure(figsize=(8, 7))
for i in range(6):
augmented_image = data_augmentation(image)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_image.numpy()/255)
plt.axis("off")Hinweis: Wenn die Meldung "WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers)." auftritt, versuche dein Bild in Numpy zu konvertieren und durch 255 zu teilen. Es zeigt dir das klare Ergebnis anstelle eines verwaschenen Bildes.

Neben der einfachen Vergrößerung kannst du auch RandomContrast, RandomCrop, HeightCrop, WidthCrop und RandomZoom auf die Bilder anwenden.
Es gibt zwei Möglichkeiten, die Bilder zu vergrößern. Die erste Methode besteht darin, die Erweiterungsschichten direkt zum Modell hinzuzufügen.
model = keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
# Add the model layers
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1,activation='sigmoid')
])Hinweis: Die Datenerweiterung ist während der Testphase inaktiv. Sie funktioniert nur für Model.fit, nicht für Model.evaluate oder Model.predict.
Die zweite Methode besteht darin, die Datenerweiterung mit Dataset.map auf den gesamten Zugsatz anzuwenden.
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y))Wir werden eine Datenvorverarbeitungsfunktion erstellen, um Trainings-, Validitäts- und Testmengen zu verarbeiten.
Die Funktion wird:
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)Wir werden ein einfaches Modell mit Faltung und dichten Schichten erstellen. Achte darauf, dass die Eingabeform der Bildform ähnlich ist.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1,activation='softmax')
])Wir erstellen nun das Modell und trainieren es für eine Epoche. Der Optimierer ist Adam, die Verlustfunktion ist Binary Cross Entropy und die Metrik ist Genauigkeit.
Wie wir sehen können, haben wir in einem einzigen Durchgang eine Validierungsgenauigkeit von 51 % erreicht. Du kannst es für mehrere Epochen trainieren und Hyperparameter optimieren, um noch bessere Ergebnisse zu erzielen.
Der Teil über die Modellerstellung und das Training soll dir nur eine Vorstellung davon geben, wie du die Bilder erweitern und das Modell trainieren kannst.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)582/582 [==============================] - 98s 147ms/step - loss: 0.6993 - accuracy: 0.4961 - val_loss: 0.6934 - val_accuracy: 0.5185loss, acc = model.evaluate(test_ds)73/73 [==============================] - 4s 48ms/step - loss: 0.6932 - accuracy: 0.5013Im Kurs Bildverarbeitung mit Keras lernst du, Bildanalysen durchzuführen und Faltungsnetzwerke zu konstruieren, zu trainieren und zu bewerten.
In diesem Abschnitt werden wir lernen, Bilder mit TensorFlow zu erweitern, um eine bessere Kontrolle über die Datenerweiterung zu haben.
Wir laden den Datensatz cats_vs_dogs erneut mit Labels und Metadaten.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Anstelle eines Katzenbildes verwenden wir ein Hundebild und wenden verschiedene Augmentierungstechniken an.
image, label = next(iter(train_ds))
plt.imshow(image)
plt.title(get_label_name(label));
1
Wir werden die Funktion visualisieren erstellen, um den Unterschied zwischen dem ursprünglichen und dem erweiterten Bild anzuzeigen.
Die Funktion ist ziemlich einfach. Sie nimmt das Originalbild und die Augmentierungsfunktion als Eingabe und zeigt die Differenz mithilfe von Matplotlib an.
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.axis("off")
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
plt.axis("off")Wie wir sehen können, haben wir das Bild mit der Funktion tf.image von links nach rechts gespiegelt. Es ist viel einfacher als keras.Sequential.
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
1
Konvertieren wir das Bild mit "tf.image.rgb_to_grayscale" in Graustufen.
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
1
Du kannst auch die Sättigung um den Faktor 3 anpassen.
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
1
Stelle die Helligkeit ein, indem du einen Helligkeitsfaktor angibst.
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
1
Schneide das Bild von der Mitte aus mit einem Mittelteil von 0,5 zu.
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
1
Drehe das Bild mit der Funktion `tf.image.rot90` um 90 Grad.
rotated = tf.image.rot90(image)
visualize(image, rotated)
1
Genau wie Keras-Layer verfügt auch tf.image über Funktionen zur zufälligen Erweiterung. Im folgenden Beispiel werden wir die Zufallshelligkeit auf das Bild anwenden und mehrere Ergebnisse anzeigen.
Wie wir sehen können, ist das erste Bild etwas dunkler und die nächsten beiden Bilder sind heller.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)


Genau wie bei Keras können wir mit Dataset.map eine Datenerweiterungsfunktion auf den gesamten Datensatz anwenden.
def augment(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
image = tf.image.random_crop(image, size=[IMG_SIZE, IMG_SIZE, 3])
image = tf.image.random_brightness(image, max_delta=0.5)
return image, label
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)Der Keras ImageDataGenerator ist noch einfacher. Es funktioniert am besten, wenn du Daten aus einem lokalen Verzeichnis oder einer CSV-Datei lädst.
In diesem Beispiel laden wir einen kleinen CIFAR10-Datensatz aus der Keras-Standarddatensatzbibliothek herunter und laden ihn.
Danach wenden wir die Augmentierung mit dem `keras.preprocessing.image.ImageDataGenerator` an. Die Funktion dreht die Bilder nach dem Zufallsprinzip, ändert ihre Höhe und Breite und spiegelt sie horizontal.
Schließlich passen wir ImageDataGenerator an den Trainingsdatensatz an und zeigen sechs Bilder mit zufälligen Erweiterungen an.
Hinweis: Die Bildgröße beträgt 32x32, wir haben also eine niedrig aufgelöste Anzeige.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
datagen = keras.preprocessing.image.ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
datagen.fit(x_train)
for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6):
for i in range(0, 6):
plt.subplot(2,3,i+1)
plt.imshow(X_batch[i]/255)
plt.axis('off')
break
In diesem Abschnitt lernen wir weitere Open-Source-Tools kennen, mit denen du verschiedene Techniken zur Datenerweiterung anwenden und die Leistung des Modells verbessern kannst.
Die Bildtransformation ist im torchvision.transforms Modul verfügbar. Ähnlich wie bei Keras kannst du Transformationsschichten innerhalb von torch.nn.Sequential hinzufügen oder eine Augmentierungsfunktion separat auf den Datensatz anwenden.
Augmentor ist ein Python-Paket zur Bilderweiterung und künstlichen Bilderzeugung. Du kannst perspektivische Verzerrungen, elastische Verzerrungen, Drehen, Scheren, Beschneiden und Spiegeln durchführen. Augmentor verfügt auch über grundlegende Funktionen zur Bildvorverarbeitung.
Albumentations ist ein schnelles und flexibles Python-Tool zur Bildvergrößerung. Es wird häufig bei Wettbewerben zum maschinellen Lernen, in der Industrie und in der Forschung eingesetzt, um die Leistung von tiefen faltigen neuronalen Netzen zu verbessern.
Imgaug ist ein Open-Source-Tool zur Bildverbesserung. Es unterstützt eine Vielzahl von Augmentierungstechniken wie Gaußsches Rauschen, Kontrast, Schärfe, Zuschneiden, Affinität und Spiegelung. Es hat eine einfache, aber leistungsstarke stochastische Oberfläche und verfügt über Keypoints, Bounding Boxes, Heatmaps und Segmentierungskarten.
OpenCV ist eine umfangreiche Open-Source-Bibliothek für Computer Vision, maschinelles Lernen und Bildverarbeitung. Sie wird im Allgemeinen bei der Entwicklung von Echtzeitanwendungen eingesetzt. Mit OpenCV kannst du Bilder und Videos mühelos erweitern.
Die von Tensorflow und Keras bereitgestellten Funktionen zur Bildvergrößerung sind praktisch. Du musst nur einen Augmentierungslayer, ein tf.image oder einen ImageDataGenerator hinzufügen, um eine Augmentierung durchzuführen. Neben Deep Learning Frameworks kannst du auch eigenständige Tools wie Augmentor, Albumentations, OpenCV und Imgaug verwenden, um Daten zu erweitern.
In diesem Tutorium haben wir die Vorteile, Grenzen, Anwendungen und Techniken der Datenerweiterung kennengelernt. Außerdem haben wir gelernt, mit Keras und Tensorflow eine Bildverbesserung auf den Datensatz Katzen vs. Hunde anzuwenden. Wenn du mehr über Bildverarbeitung lernen möchtest, schau dir den Skill Track Bildverarbeitung mit Python an. Er vermittelt dir die Grundlagen der Bildtransformation und -manipulation, der medizinischen Bildanalyse und der fortgeschrittenen Bildverarbeitung mit Keras.
Top Kurse
Kurs
Kurs
Kurs
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui
Tutorial
Sejal Jaiswal
