Courses
Làm việc với Dữ liệu Không gian địa lý trong Python
4 giờ
17.8K
Trong phần này, chúng ta sẽ tìm hiểu về các kỹ thuật data augmentation cho âm thanh, văn bản, hình ảnh và các phương pháp nâng cao.
Tìm hiểu thêm về biến đổi và thao tác ảnh với các bài tập thực hành trong lộ trình kỹ năng Image Processing with Python.
Data augmentation có thể áp dụng cho mọi ứng dụng máy học nơi việc thu thập dữ liệu chất lượng gặp khó khăn. Hơn nữa, nó có thể giúp cải thiện độ vững và hiệu năng mô hình trên mọi lĩnh vực nghiên cứu.
Việc thu thập và gán nhãn các bộ dữ liệu ảnh y khoa tốn thời gian và chi phí. Bạn cũng cần chuyên gia lĩnh vực để thẩm định dữ liệu trước khi phân tích. Sử dụng các biến đổi hình học và các phép biến đổi khác có thể giúp bạn huấn luyện các mô hình máy học vững vàng và chính xác.
Ví dụ, trong bài toán Phân loại Viêm phổi, bạn có thể dùng cắt, thu phóng, kéo giãn ngẫu nhiên và biến đổi không gian màu để cải thiện hiệu năng mô hình. Tuy nhiên, cần cẩn trọng với một số phép tăng cường vì có thể cho kết quả ngược. Chẳng hạn, xoay ngẫu nhiên và phản chiếu theo trục x không được khuyến nghị với dữ liệu ảnh X-quang.
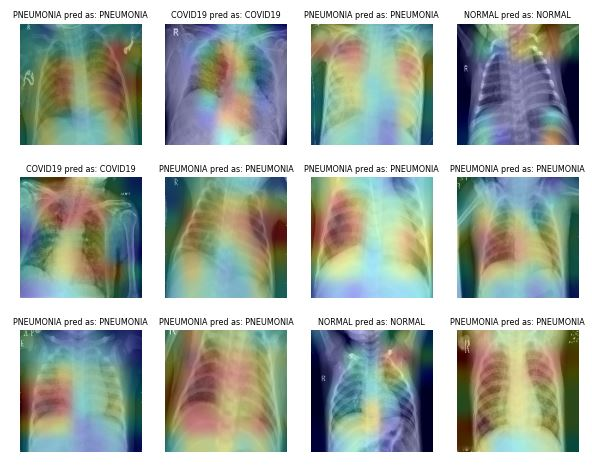
Hình ảnh từ ibrahimsobh.github.io | kaggle-COVID19-Classification
Dữ liệu cho xe tự hành còn hạn chế, và các công ty đang dùng môi trường mô phỏng để tạo dữ liệu tổng hợp bằng học tăng cường. Cách này giúp bạn huấn luyện và kiểm thử các ứng dụng máy học trong bối cảnh dữ liệu nhạy cảm về bảo mật.

Hình ảnh bởi David Silver | Autonomous Visualization System from Uber ATG
Khả năng dùng dữ liệu tăng cường để mô phỏng là vô tận, vì có thể tạo ra các kịch bản gần với thế giới thực.
Tăng cường dữ liệu văn bản thường được dùng khi dữ liệu chất lượng hạn chế, và ưu tiên là cải thiện chỉ số hiệu năng. Bạn có thể áp dụng mở rộng bằng từ đồng nghĩa, nhúng từ, hoán chuyển ký tự, và chèn/xóa ngẫu nhiên. Những kỹ thuật này cũng hữu ích cho các ngôn ngữ ít tài nguyên.
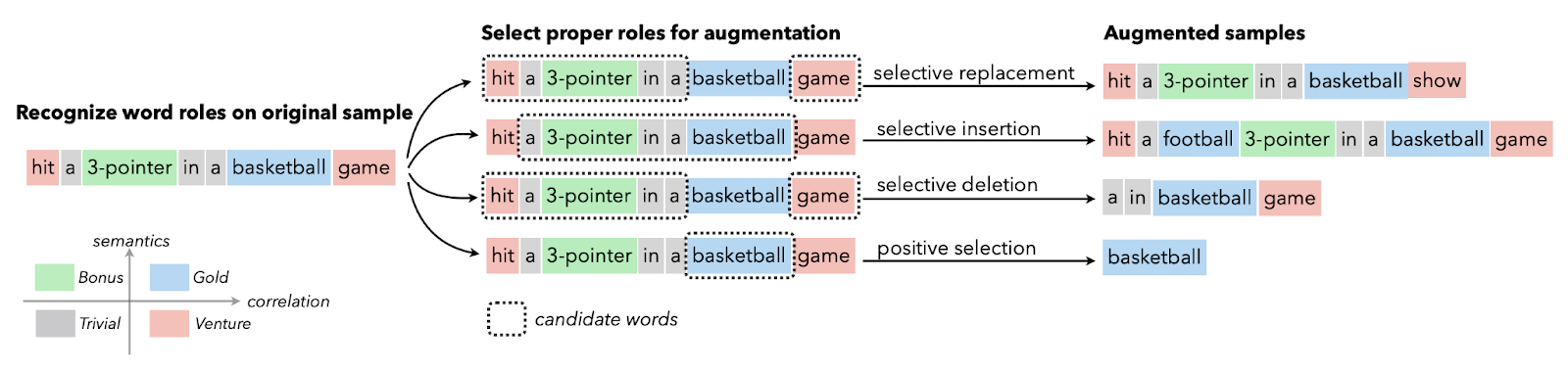
Hình ảnh từ Papers With Code | Selective Text Augmentation with Word Roles for Low-Resource Text Classification.
Các nhà nghiên cứu sử dụng tăng cường văn bản cho mô hình ngôn ngữ trong bối cảnh nhận dạng có lỗi cao, sinh dữ liệu chuỗi-đến-chuỗi và phân loại văn bản.
Trong phân loại âm thanh và nhận dạng giọng nói, data augmentation đem lại hiệu quả rõ rệt. Nó cải thiện hiệu năng mô hình ngay cả với các ngôn ngữ ít tài nguyên.
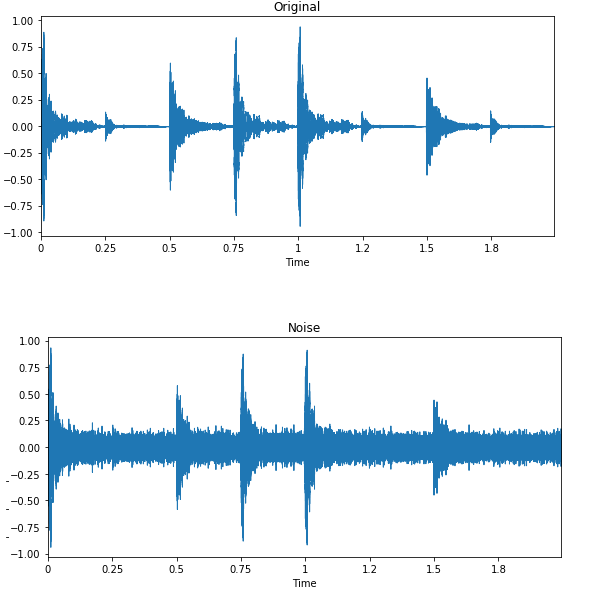
Hình ảnh bởi Edward Ma | Noise Injection
Chèn nhiễu ngẫu nhiên, dịch chuyển và thay đổi cao độ có thể giúp bạn tạo ra các mô hình chuyển giọng nói thành văn bản hiện đại. Bạn cũng có thể dùng GAN để tạo ra âm thanh chân thực cho các ứng dụng cụ thể.
Mặc dù data augmentation là công cụ mạnh mẽ để nâng cao mô hình máy học, nó đặt ra một số vấn đề đạo đức cần cân nhắc kỹ lưỡng:
Để khai thác data augmentation một cách có trách nhiệm, người thực hành nên thẩm định dữ liệu đã tăng cường, xử lý thiên lệch và đảm bảo tuân thủ các tiêu chuẩn đạo đức và pháp lý liên quan.
Trong hướng dẫn này, chúng ta sẽ học cách tăng cường dữ liệu ảnh bằng Keras và TensorFlow. Ngoài ra, bạn sẽ học cách dùng dữ liệu đã tăng cường để huấn luyện một bộ phân loại nhị phân đơn giản. Mã nguồn dưới đây là phiên bản đã chỉnh sửa của ví dụ chính thức của TensorFlow.
Chúng tôi khuyến nghị bạn thực hành theo hướng dẫn mã. Mã nguồn kèm kết quả có trong sổ tay DataLab này.
Chúng ta sẽ dùng TensorFlow và Keras cho data augmentation và matplotlib để hiển thị ảnh.
%%capture
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
Bộ sưu tập TensorFlow Dataset rất phong phú. Bạn có thể tìm thấy các tập dữ liệu văn bản, âm thanh, video, đồ thị, chuỗi thời gian và hình ảnh. Trong hướng dẫn này, chúng ta sẽ dùng tập cats_vs_dogs. Kích thước tập dữ liệu là 786,68 MiB, và chúng ta sẽ áp dụng nhiều phép tăng cường ảnh rồi huấn luyện bộ phân loại nhị phân.
Trong đoạn mã dưới đây, chúng ta đã tải 80% dữ liệu cho huấn luyện, 10% cho validation và 10% cho kiểm thử, kèm nhãn và siêu dữ liệu.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Có hai lớp trong tập dữ liệu: ‘cat’ và ‘dog’.
num_classes = metadata.features['label'].num_classes
print(num_classes)2Chúng ta sẽ dùng iterator để trích xuất bốn ảnh ngẫu nhiên kèm nhãn từ tập huấn luyện và hiển thị bằng hàm `.imshow()` của matplotlib.
try:
get_label_name = metadata.features['label'].int2str
train_iter = iter(train_ds)
fig = plt.figure(figsize=(7, 8))
for x in range(4):
image, label = next(train_iter)
fig.add_subplot(1, 4, x + 1)
plt.imshow(image)
plt.axis('off')
plt.title(get_label_name(label))
except StopIteration:
print("Dataset iterator is empty!")
Như bạn thấy, chúng ta nhận được nhiều ảnh chó và một ảnh mèo.

Thông thường chúng ta dùng keras.Sequential() để xây dựng mô hình, nhưng cũng có thể dùng nó để thêm các lớp augmentation.
Trong ví dụ này, chúng ta thay đổi kích thước và tỉ lệ ảnh bằng Keras Sequential và các lớp augmentation. Trước tiên, chúng ta đổi kích thước ảnh về 180x180 rồi chuẩn hóa về 1/255. Kích thước ảnh nhỏ sẽ giúp tiết kiệm thời gian, bộ nhớ và tính toán.
Như bạn thấy, chúng ta đã truyền ảnh qua lớp augmentation thành công, và đầu ra cuối cùng đã được đổi kích thước và chuẩn hóa.
IMG_SIZE = 180
resize_and_rescale = keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
result = resize_and_rescale(image)
plt.axis('off')
plt.imshow(result);
1
Hãy áp dụng lật và xoay ngẫu nhiên lên cùng một ảnh. Chúng ta sẽ dùng vòng lặp, subplot và imshow để hiển thị sáu ảnh với biến đổi hình học ngẫu nhiên.
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.4),
])
plt.figure(figsize=(8, 7))
for i in range(6):
augmented_image = data_augmentation(image)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_image.numpy()/255)
plt.axis("off")Lưu ý: nếu bạn gặp cảnh báo “WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).”, hãy thử chuyển ảnh sang numpy và chia cho 255. Cách này sẽ hiển thị kết quả rõ ràng thay vì ảnh bị nhạt màu.

Ngoài các phép tăng cường đơn giản, bạn cũng có thể áp dụng RandomContrast, RandomCrop, CenterCrop và RandomZoom cho ảnh.
Có hai cách để áp dụng augmentation cho ảnh. Cách thứ nhất là thêm trực tiếp các lớp augmentation vào mô hình.
model = keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
# Add the model layers
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1,activation='sigmoid')
])Lưu ý: data augmentation sẽ không hoạt động trong giai đoạn kiểm thử. Nó chỉ chạy trong Model.fit, không chạy trong Model.evaluate hay Model.predict.
Cách thứ hai là áp dụng data augmentation cho toàn bộ tập huấn luyện bằng Dataset.map.
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y))Chúng ta sẽ tạo một hàm tiền xử lý dữ liệu để xử lý tập train, valid và test.
Hàm sẽ:
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)Chúng ta sẽ tạo một mô hình đơn giản với các lớp tích chập và dày đặc. Hãy đảm bảo kích thước đầu vào giống với kích thước ảnh.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1,activation='softmax')
])Bây giờ chúng ta sẽ biên dịch mô hình và huấn luyện trong một epoch. Bộ tối ưu là Adam, hàm mất mát là Binary Cross Entropy, và chỉ số là accuracy.
Như có thể thấy, chúng ta đạt 51% độ chính xác trên tập validation trong một lần chạy. Bạn có thể huấn luyện nhiều epoch và tinh chỉnh siêu tham số để có kết quả tốt hơn.
Phần xây dựng và huấn luyện mô hình chỉ nhằm minh họa cách bạn có thể tăng cường ảnh và huấn luyện mô hình.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)582/582 [==============================] - 98s 147ms/step - loss: 0.6993 - accuracy: 0.4961 - val_loss: 0.6934 - val_accuracy: 0.5185loss, acc = model.evaluate(test_ds)73/73 [==============================] - 4s 48ms/step - loss: 0.6932 - accuracy: 0.5013Học cách phân tích ảnh, xây dựng, huấn luyện và đánh giá mạng tích chập bằng cách tham gia khóa Image Processing with Keras.
Trong phần này, chúng ta sẽ học cách tăng cường ảnh bằng TensorFlow để kiểm soát chi tiết hơn việc augmentation.
Chúng ta sẽ nạp lại tập cats_vs_dogs kèm nhãn và siêu dữ liệu.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Thay vì ảnh mèo, lần này chúng ta sẽ dùng ảnh chó và áp dụng các kỹ thuật augmentation khác nhau.
image, label = next(iter(train_ds))
plt.imshow(image)
plt.title(get_label_name(label));
1
Chúng ta sẽ tạo hàm visualize() để hiển thị sự khác biệt giữa ảnh gốc và ảnh đã tăng cường.
Hàm này khá đơn giản. Nó nhận ảnh gốc và hàm augmentation làm đầu vào, sau đó hiển thị sự khác biệt bằng matplotlib.
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.axis("off")
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
plt.axis("off")Như bạn thấy, chúng ta đã lật ảnh từ trái sang phải bằng hàm tf.image. Cách này đơn giản hơn keras.Sequential().
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
1
Hãy chuyển ảnh sang thang xám bằng tf.image.rgb_to_grayscale().
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
1
Bạn cũng có thể điều chỉnh độ bão hòa với hệ số 3.
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
1
Điều chỉnh độ sáng bằng cách cung cấp một hệ số độ sáng.
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
1
Cắt ảnh từ trung tâm với tỷ lệ trung tâm là 0,5.
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
1
Xoay ảnh 90 độ bằng hàm tf.image.rot90().
rotated = tf.image.rot90(image)
visualize(image, rotated)
1
Tương tự các lớp Keras, tf.image() cũng có các hàm augmentation ngẫu nhiên. Trong ví dụ dưới đây, chúng ta sẽ áp dụng độ sáng ngẫu nhiên lên ảnh và hiển thị nhiều kết quả.
Như bạn thấy, ảnh đầu tiên tối hơn, và hai ảnh tiếp theo sáng hơn.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)


Tương tự Keras, chúng ta có thể áp dụng hàm data augmentation cho toàn bộ tập dữ liệu bằng Dataset.map().
def augment(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
image = tf.image.random_crop(image, size=[IMG_SIZE, IMG_SIZE, 3])
image = tf.image.random_brightness(image, max_delta=0.5)
return image, label
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)Keras ImageDataGenerator() còn đơn giản hơn. Nó hoạt động tốt nhất khi bạn nạp dữ liệu từ thư mục cục bộ hoặc CSV.
Trong ví dụ này, chúng ta sẽ tải và nạp một tập CIFAR10 nhỏ từ thư viện tập dữ liệu mặc định của Keras.
Sau đó, chúng ta sẽ áp dụng augmentation bằng keras.preprocessing.image.ImageDataGenerator(). Hàm này sẽ xoay ngẫu nhiên, thay đổi chiều cao và chiều rộng, và lật ngang ảnh.
Cuối cùng, chúng ta fit ImageDataGenerator() vào tập huấn luyện và hiển thị sáu ảnh với augmentation ngẫu nhiên.
Lưu ý: kích thước ảnh là 32x32, nên hiển thị độ phân giải thấp.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
datagen = keras.preprocessing.image.ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
datagen.fit(x_train)
for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6):
for i in range(0, 6):
plt.subplot(2,3,i+1)
plt.imshow(X_batch[i]/255)
plt.axis('off')
break
Trong phần này, chúng ta sẽ tìm hiểu các công cụ mã nguồn mở khác mà bạn có thể dùng để thực hiện nhiều kỹ thuật data augmentation và cải thiện hiệu năng mô hình.
Biến đổi ảnh có trong mô-đun torchvision.transforms. Tương tự Keras, bạn có thể thêm các lớp biến đổi trong torch.nn.Sequential hoặc áp dụng hàm augmentation riêng trên tập dữ liệu.
Augmentor là gói Python cho tăng cường ảnh và tạo ảnh nhân tạo. Bạn có thể thực hiện Nghiêng phối cảnh, Biến dạng đàn hồi, Xoay, Cắt xiên, Cắt xén và Soi gương. Augmentor cũng có các chức năng tiền xử lý ảnh cơ bản.
Albumentations là công cụ Python nhanh và linh hoạt cho tăng cường ảnh. Nó được dùng rộng rãi trong các cuộc thi máy học, công nghiệp và nghiên cứu để cải thiện hiệu năng của mạng nơ-ron tích chập sâu.
Imgaug là công cụ mã nguồn mở cho tăng cường ảnh. Nó hỗ trợ đa dạng kỹ thuật augmentation như nhiễu Gaussian, tương phản, độ nét, cắt, biến đổi affine và lật. Công cụ có giao diện ngẫu nhiên hóa đơn giản nhưng mạnh mẽ, kèm hỗ trợ keypoint, hộp giới hạn, bản đồ nhiệt và bản đồ phân đoạn.
OpenCV là thư viện mã nguồn mở lớn cho thị giác máy tính, máy học và xử lý ảnh. Nó thường được dùng để xây dựng ứng dụng thời gian thực. Bạn có thể dùng OpenCV để tăng cường ảnh và video một cách dễ dàng.
Các hàm tăng cường ảnh do TensorFlow và Keras cung cấp rất tiện lợi. Bạn chỉ cần thêm một lớp augmentation, tf.image(), hoặc ImageDataGenerator() để thực hiện augmentation. Ngoài các framework học sâu, bạn có thể dùng các công cụ độc lập như Augmentor, Albumentations, OpenCV và Imgaug để thực hiện data augmentation.
Trong hướng dẫn này, chúng ta đã tìm hiểu ưu điểm, hạn chế, ứng dụng và kỹ thuật của data augmentation. Bên cạnh đó, chúng ta đã học cách áp dụng tăng cường ảnh trên tập cats_vs_dogs bằng Keras và TensorFlow. Nếu bạn quan tâm đến xử lý ảnh, hãy xem lộ trình kỹ năng Image Processing with Python. Lộ trình sẽ dạy bạn những kiến thức cơ bản về biến đổi và thao tác ảnh, phân tích ảnh y khoa và xử lý ảnh nâng cao bằng Keras.
Khóa học hàng đầu
Courses
Courses
Courses