Cursus
Werken met georuimtelijke data in Python
4 Hr
17.8K
In deze sectie behandelen we audio-, tekst-, beeld- en geavanceerde augmentatietechnieken.
Leer meer over beeldtransformatie en -manipulatie met praktijkoefeningen in onze Image Processing with Python skill track.
Data-augmentatie is toepasbaar op alle machinelearningtoepassingen waarin het lastig is om kwalitatieve data te verkrijgen. Bovendien kan het helpen de robuustheid en prestaties van modellen te verbeteren in alle vakgebieden.
Het verzamelen en labelen van medische beeldvormingsdatasets is tijdrovend en duur. Je hebt ook een inhoudsdeskundige nodig om de dataset te valideren voordat je data-analyse uitvoert. Het gebruik van geometrische en andere transformaties kan je helpen om robuuste en nauwkeurige machinelearningmodellen te trainen.
Bijvoorbeeld, in het geval van longontstekingclassificatie kun je willekeurige crops, zoomen, rekken en kleurruimtetransformaties gebruiken om de modelprestaties te verbeteren. Wees echter voorzichtig met bepaalde augmentaties, omdat die een averechts effect kunnen hebben. Zo worden willekeurige rotatie en reflectie langs de x-as niet aanbevolen voor röntgenbeeld-datasets.
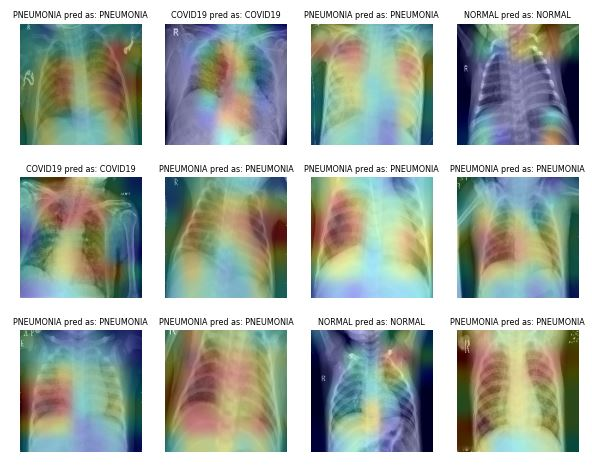
Afbeelding van ibrahimsobh.github.io | kaggle-COVID19-Classification
Er is beperkte data beschikbaar over zelfrijdende auto’s, en bedrijven gebruiken gesimuleerde omgevingen om synthetische data te genereren met reinforcement learning. Dit kan helpen bij het trainen en testen van machinelearningtoepassingen waar dataveiligheid een issue is.

Afbeelding door David Silver | Autonomous Visualization System from Uber ATG
De mogelijkheden van aangevulde data als simulatie zijn eindeloos, omdat je er realistische scenario’s mee kunt genereren.
Tekstaugmentatie wordt meestal gebruikt in situaties met beperkte datakwaliteit, waarbij het verbeteren van de prestatie-indicator prioriteit heeft. Je kunt synoniemen-augmentatie, word embeddings, karakterwissel en willekeurige invoeging en verwijdering toepassen. Deze technieken zijn ook waardevol voor talen met weinig middelen.
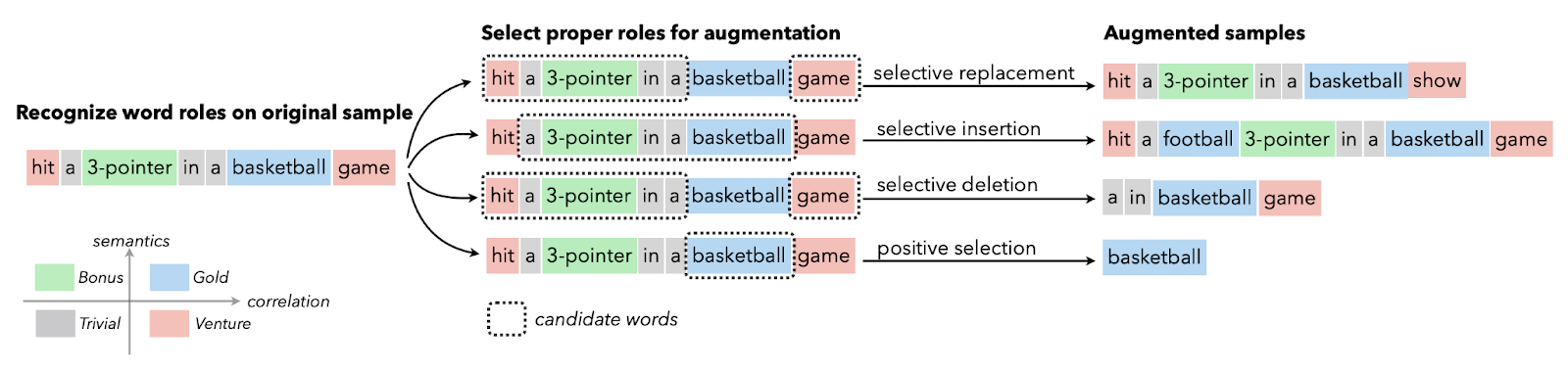
Afbeelding van Papers With Code | Selective Text Augmentation with Word Roles for Low-Resource Text Classification.
Onderzoekers gebruiken tekstaugmentatie voor taalmodellen in scenario’s met hoge foutherkenning, sequence-to-sequence-datageneratie en tekstclassificatie.
Bij geluidsclassificatie en spraakherkenning werkt data-augmentatie uitstekend. Het verbetert de modelprestaties zelfs voor talen met weinig middelen.
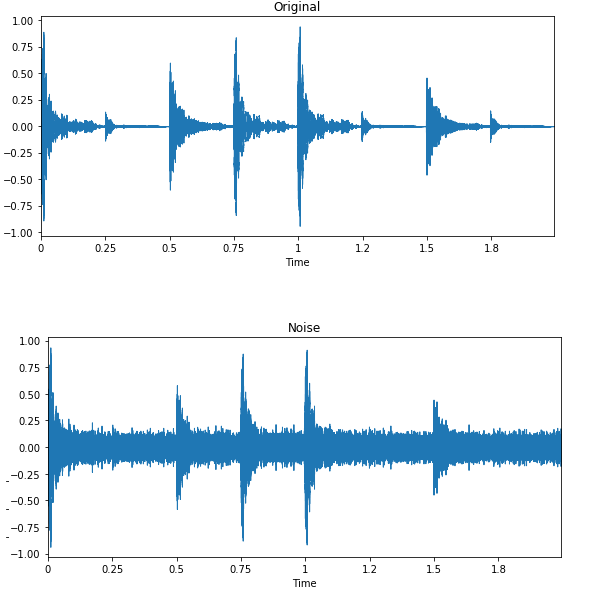
Afbeelding door Edward Ma | Noise Injection
Willekeurige ruisinjectie, shiften en het veranderen van de toonhoogte kunnen je helpen state-of-the-art spraak-naar-tekstmodellen te bouwen. Je kunt ook GANs gebruiken om realistische geluiden voor een specifieke toepassing te genereren.
Hoewel data-augmentatie een krachtig hulpmiddel is om machinelearningmodellen te verbeteren, brengt het verschillende ethische zorgen met zich mee die zorgvuldige afweging vereisen:
Om data-augmentatie verantwoord te benutten, moeten practitioners aangevulde data valideren, bias aanpakken en zorgen voor naleving van relevante ethische en juridische standaarden.
In deze tutorial leer je hoe je beelddata kunt aanvullen met Keras en TensorFlow. Bovendien leer je hoe je je aangevulde data gebruikt om een eenvoudige binaire classifier te trainen. De onderstaande code is een aangepaste versie van het officiële voorbeeld van TensorFlow.
We raden aan de code-tutorial te volgen en zelf te oefenen. De broncode met outputs is beschikbaar in dit DataLab-werkboek.
We gebruiken TensorFlow en Keras voor data-augmentatie en matplotlib om de afbeeldingen weer te geven.
%%capture
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
De collectie TensorFlow Dataset is enorm. Je vindt er tekst-, audio-, video-, graf-, tijdreeks- en afbeeldingsdatasets. In deze tutorial gebruiken we de cats_vs_dogs dataset. De dataset is 786,68 MiB groot, en we passen verschillende beeldaugmentaties toe en trainen de binaire classifier.
In de onderstaande code hebben we 80% training, 10% validatie en 10% testset geladen met labels en metadata.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Er zijn twee klassen in de dataset: ‘cat’ en ‘dog’.
num_classes = metadata.features['label'].num_classes
print(num_classes)2We gebruiken iterators om slechts vier willekeurige afbeeldingen met labels uit de trainingsset te halen en ze weer te geven met de matplotlib-functie `.imshow()`.
try:
get_label_name = metadata.features['label'].int2str
train_iter = iter(train_ds)
fig = plt.figure(figsize=(7, 8))
for x in range(4):
image, label = next(train_iter)
fig.add_subplot(1, 4, x + 1)
plt.imshow(image)
plt.axis('off')
plt.title(get_label_name(label))
except StopIteration:
print("Dataset iterator is empty!")
Zoals je ziet hebben we verschillende hondenafbeeldingen en één kattenafbeelding.

We gebruiken meestal keras.Sequential() om het model te bouwen, maar je kunt het ook gebruiken om augmentatielagen toe te voegen.
In dit voorbeeld resizen en rescalen we de afbeelding met Keras Sequential en augmentatielagen. We resizen de afbeelding eerst naar 180x180 en rescalen daarna met 1/255. De kleine afbeeldingsgrootte helpt tijd, geheugen en rekenkracht te besparen.
Zoals je ziet hebben we de afbeelding succesvol door de augmentatielaag gehaald, en de uiteindelijke output is geresized en gerescaled.
IMG_SIZE = 180
resize_and_rescale = keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
result = resize_and_rescale(image)
plt.axis('off')
plt.imshow(result);
1
Laten we willekeurig spiegelen en roteren toepassen op dezelfde afbeelding. We gebruiken een loop, subplot en imshow om zes afbeeldingen met willekeurige geometrische augmentatie te tonen.
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.4),
])
plt.figure(figsize=(8, 7))
for i in range(6):
augmented_image = data_augmentation(image)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_image.numpy()/255)
plt.axis("off")Let op: als je de melding “WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).” krijgt, probeer je afbeelding dan naar numpy te converteren en door 255 te delen. Dan krijg je een helder resultaat in plaats van een fletse afbeelding.

Naast eenvoudige augmentatie kun je ook RandomContrast, RandomCrop, CenterCrop en RandomZoom toepassen op afbeeldingen.
Er zijn twee manieren om augmentatie op afbeeldingen toe te passen. De eerste methode is door de augmentatielagen direct aan het model toe te voegen.
model = keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
# Add the model layers
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1,activation='sigmoid')
])Let op: data-augmentatie is inactief tijdens de testfase. Het werkt alleen voor Model.fit, niet voor Model.evaluate of Model.predict.
De tweede methode is om de data-augmentatie toe te passen op de volledige trainingsset met Dataset.map.
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y))We maken een datapreprocessingfunctie om de train-, validatie- en testsets te verwerken.
De functie zal:
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)We maken een eenvoudig model met convolutionele en dense lagen. Zorg dat de inputvorm overeenkomt met de afbeeldingsgrootte.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1,activation='softmax')
])We compileren nu het model en trainen het één epoch. De optimizer is Adam, de verliesfunctie is Binary Cross Entropy en de metric is accuracy.
Zoals je ziet haalden we 51% validatienauwkeurigheid in één run. Je kunt meer epochs trainen en hyperparameters optimaliseren voor betere resultaten.
Het modelbouw- en trainingsgedeelte is vooral bedoeld om je een idee te geven hoe je afbeeldingen kunt aanvullen en vervolgens het model kunt trainen.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)582/582 [==============================] - 98s 147ms/step - loss: 0.6993 - accuracy: 0.4961 - val_loss: 0.6934 - val_accuracy: 0.5185loss, acc = model.evaluate(test_ds)73/73 [==============================] - 4s 48ms/step - loss: 0.6932 - accuracy: 0.5013Leer beeldanalyse uitvoeren, en convolutionele netwerken bouwen, trainen en evalueren in de cursus Image Processing with Keras.
In deze sectie leren we afbeeldingen aan te vullen met TensorFlow om meer controle te hebben over data-augmentatie.
We laden de cats_vs_dogs-dataset opnieuw met labels en metadata.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)In plaats van een kattenafbeelding gebruiken we nu de hondenafbeelding en passen we verschillende augmentatietechnieken toe.
image, label = next(iter(train_ds))
plt.imshow(image)
plt.title(get_label_name(label));
1
We maken de functie visualize() om het verschil tussen de originele en aangevulde afbeelding te tonen.
De functie is vrij eenvoudig. Hij neemt de originele afbeelding en de augmentatiefunctie als input en toont het verschil met matplotlib.
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.axis("off")
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
plt.axis("off")Zoals je ziet hebben we de afbeelding van links naar rechts gespiegeld met de tf.image-functie. Het is veel eenvoudiger dan keras.Sequential().
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
1
Laten we de afbeelding converteren naar grijswaarden met tf.image.rgb_to_grayscale().
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
1
Je kunt de verzadiging ook aanpassen met een factor 3.
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
1
Pas de helderheid aan door een helderheidsfactor op te geven.
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
1
Crop de afbeelding vanuit het midden met een centrale fractie van 0,5.
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
1
Roteer de afbeelding 90 graden met de functie tf.image.rot90().
rotated = tf.image.rot90(image)
visualize(image, rotated)
1
Net als Keras-lagen heeft tf.image() ook willekeurige augmentatiefuncties. In het onderstaande voorbeeld passen we willekeurige helderheid toe op de afbeelding en tonen we meerdere resultaten.
Zoals je ziet is de eerste afbeelding wat donkerder en de volgende twee zijn helderder.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)


Net als bij Keras kunnen we een data-augmentatiefunctie toepassen op de volledige dataset met Dataset.map().
def augment(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
image = tf.image.random_crop(image, size=[IMG_SIZE, IMG_SIZE, 3])
image = tf.image.random_brightness(image, max_delta=0.5)
return image, label
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)De Keras-ImageDataGenerator() is nog eenvoudiger. Deze werkt het best wanneer je data laadt uit een lokale map of CSV.
In het voorbeeld downloaden en laden we een kleine CIFAR10-dataset uit de standaard Keras-bibliotheek.
Daarna passen we augmentatie toe met keras.preprocessing.image.ImageDataGenerator(). De functie roteert willekeurig, verandert hoogte en breedte en spiegelt de afbeeldingen horizontaal.
Tot slot fitten we ImageDataGenerator() op de trainingsdataset en tonen we zes afbeeldingen met willekeurige augmentatie.
Let op: de afbeeldingsgrootte is 32x32, dus de weergave heeft een lage resolutie.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
datagen = keras.preprocessing.image.ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
datagen.fit(x_train)
for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6):
for i in range(0, 6):
plt.subplot(2,3,i+1)
plt.imshow(X_batch[i]/255)
plt.axis('off')
break
In deze sectie kijken we naar andere openbrontools die je kunt gebruiken om verschillende augmentatietechnieken toe te passen en de modelprestaties te verbeteren.
Beeldtransformaties zijn beschikbaar in de module torchvision.transforms. Net als bij Keras kun je transformatielagen toevoegen binnen torch.nn.Sequential of een aparte augmentatiefunctie toepassen op de dataset.
Augmentor is een Python-pakket voor beeldaugmentatie en kunstmatige afbeeldingsgeneratie. Je kunt Perspective Skewing, Elastic Distortions, Rotating, Shearing, Cropping en Mirroring uitvoeren. Augmentor bevat ook basisfunctionaliteit voor beeldpreprocessing.
Albumentations is een snelle en flexibele Python-tool voor beeldaugmentatie. Het wordt veel gebruikt in machinelearningcompetities, de industrie en onderzoek om de prestaties van diepe convolutionele neurale netwerken te verbeteren.
Imgaug is een openbrontool voor beeldaugmentatie. Het ondersteunt een breed scala aan augmentatietechnieken, zoals Gaussiaanse ruis, contrast, scherpte, crop, affine en flip. Het heeft een eenvoudige maar krachtige stochastische interface en wordt geleverd met keypoints, bounding boxes, heatmaps en segmentatiekaarten.
OpenCV is een uitgebreide openbronbibliotheek voor computervisie, machine learning en beeldverwerking. Het wordt doorgaans gebruikt voor realtime toepassingen. Je kunt OpenCV gebruiken om afbeeldingen en video’s moeiteloos te augmenteren.
De beeldaugmentatiefuncties van TensorFlow en Keras zijn erg handig. Je hoeft alleen een augmentatielaag, tf.image() of ImageDataGenerator() toe te voegen om augmentatie uit te voeren. Naast deep-learningframeworks kun je ook losse tools zoals Augmentor, Albumentations, OpenCV en Imgaug gebruiken voor data-augmentatie.
In deze tutorial hebben we de voordelen, beperkingen, toepassingen en technieken van data-augmentatie behandeld. Verder hebben we beeldaugmentatie toegepast op de cats_vs_dogs-dataset met Keras en TensorFlow. Wil je meer leren over beeldverwerking? Bekijk dan onze Image Processing with Python-skill track. Die leert je de basis van beeldtransformatie en -manipulatie, medische beeldanalyse en geavanceerde beeldverwerking met Keras.
Topcursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
