Cours
Travailler avec des données géospatiales en Python
4 h
17.7K
Dans cette section, nous apprendrons à connaître les techniques d'augmentation des données audio, textuelles et d'images, ainsi que les techniques avancées d'augmentation des données.
Apprenez-en plus sur la transformation et la manipulation d'images avec des exercices pratiques dans notre cursus de compétences Traitement d'images avec Python.
L'augmentation des données peut s'appliquer à toutes les applications d'apprentissage automatique pour lesquelles l'acquisition de données de qualité est difficile. En outre, elle peut contribuer à améliorer la robustesse et la performance des modèles dans tous les domaines d'étude.
L'acquisition et l'étiquetage d'ensembles de données d'imagerie médicale sont longs et coûteux. Vous avez également besoin d'un expert en la matière pour valider l'ensemble de données avant de procéder à l'analyse des données. L'utilisation de transformations géométriques et autres peut vous aider à former des modèles d'apprentissage automatique robustes et précis.
Par exemple, dans le cas de la classification de la pneumonie, vous pouvez utiliser des recadrages aléatoires, des zooms, des étirements et des transformations de l'espace colorimétrique pour améliorer les performances du modèle. Cependant, vous devez faire attention à certaines augmentations car elles peuvent avoir des résultats opposés. Par exemple, la rotation aléatoire et la réflexion le long de l'axe x ne sont pas recommandées pour l'ensemble de données d'imagerie radiographique.
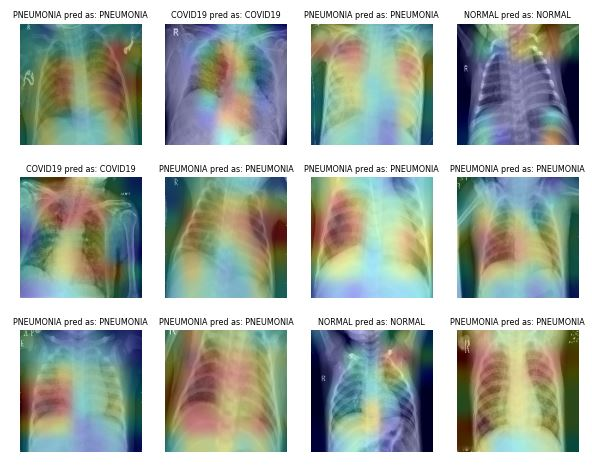
Image de ibrahimsobh.github.io | kaggle-COVID19-Classification
Les données disponibles sur les voitures autonomes sont limitées et les entreprises utilisent des environnements simulés pour générer des données synthétiques à l'aide de l'apprentissage par renforcement. Il peut vous aider à former et à tester des applications d'apprentissage automatique lorsque la sécurité des données est un problème.

Image par David Silver | Système de visualisation autonome d'Uber ATG
Les possibilités des données augmentées en tant que simulation sont infinies, car elles peuvent être utilisées pour générer des scénarios du monde réel.
L'augmentation des données textuelles est généralement utilisée dans des situations où la qualité des données est limitée et où l'amélioration de la mesure de la performance est prioritaire. Vous pouvez appliquer l'augmentation des synonymes, l'intégration de mots, l'échange de caractères, ainsi que l'insertion et la suppression aléatoires. Ces techniques sont également utiles pour les langues à faibles ressources.
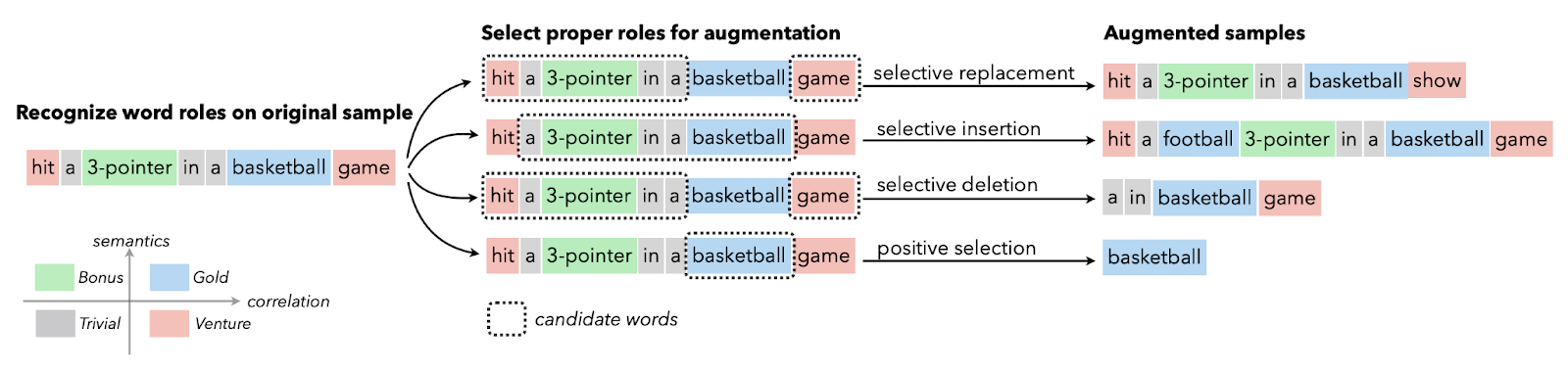
Image from Papers With Code | Augmentation sélective du texte avec des rôles de mots pour la classification de textes à faibles ressources.
Les chercheurs utilisent l'augmentation de texte pour les modèles de langue dans les scénarios de reconnaissance avec un taux d'erreur élevé, la génération de données de séquence à séquence et la classification de texte.
Dans la classification des sons et la reconnaissance vocale, l'augmentation des données fait des merveilles. Il améliore les performances du modèle même pour les langues à faibles ressources.
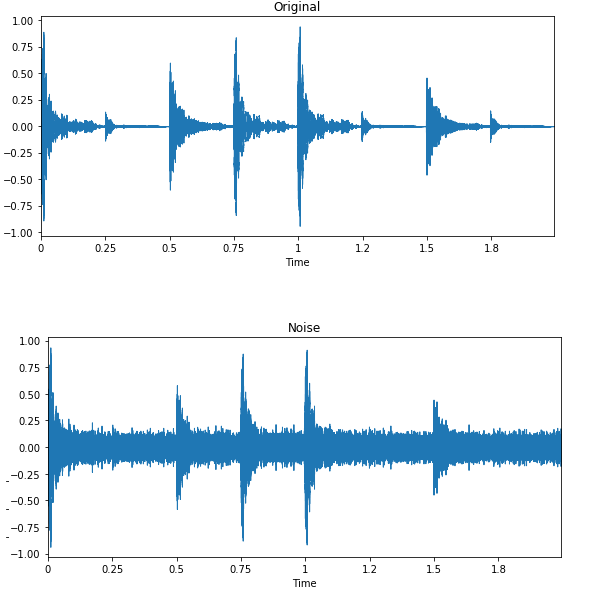
Image par Edward Ma | Noise Injection
L'injection de bruit aléatoire, le décalage et la modification de la hauteur peuvent vous aider à produire des modèles de conversion de la parole en texte à la pointe de la technologie. Vous pouvez également utiliser les GAN pour générer des sons réalistes pour une application particulière.
Dans ce tutoriel, nous allons apprendre à augmenter les données d'une image en utilisant Keras et Tensorflow. En outre, vous apprendrez à utiliser vos données augmentées pour former un simple classificateur binaire. Le code mentionné ci-dessous est la version modifiée de l'exemple officiel de TensorFlow.
Nous vous recommandons de suivre le tutoriel de codage et de vous entraîner par vous-même. Le code source avec les résultats est disponible dans ce classeur DataLab.
Nous utiliserons TensorFlow et Keras pour l'augmentation des données et matplotlib pour l'affichage des images.
%%capture
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from keras import layers
import kerasLa collection de données TensorFlow est énorme. Vous pouvez trouver des ensembles de données textuelles, audio, vidéo, graphiques, séries chronologiques et images. Dans ce tutoriel, nous utiliserons le jeu de données "cats_vs_dogs". La taille de l'ensemble de données est de 786,68 MiB, et nous appliquerons diverses augmentations d'images et entraînerons le classificateur binaire.
Dans le code ci-dessous, nous avons chargé 80 % de l'ensemble de formation, 10 % de l'ensemble de validation et 10 % de l'ensemble de test avec des étiquettes et des métadonnées.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)L'ensemble de données comporte deux classes : "chat" et "chien".
num_classes = metadata.features['label'].num_classes
print(num_classes)2Nous utiliserons des itérateurs pour extraire seulement quatre images aléatoires avec des étiquettes de l'ensemble d'apprentissage et les afficher à l'aide de la fonction matplotlib `.imshow()`.
get_label_name = metadata.features['label'].int2str
train_iter = iter(train_ds)
fig = plt.figure(figsize=(7, 8))
for x in range(4):
image, label = next(train_iter)
fig.add_subplot(1, 4, x+1)
plt.imshow(image)
plt.axis('off')
plt.title(get_label_name(label));Comme vous pouvez le constater, nous avons obtenu plusieurs images de chiens et une image de chat.

Nous utilisons généralement keras.Sequential() pour construire le modèle, mais nous pouvons également l'utiliser pour ajouter des couches d'augmentation.
Dans l'exemple, nous redimensionnons et remettons à l'échelle l'image à l'aide des couches séquentielles et d'augmentation d'image de Keras. Nous allons d'abord redimensionner l'image à 180X180, puis la redimensionner à 1/255. La petite taille de l'image nous permettra d'économiser du temps, de la mémoire et des ressources informatiques.
Comme nous pouvons le voir, nous avons réussi à faire passer l'image par la couche d'augmentation, et la sortie finale est redimensionnée et remise à l'échelle.
IMG_SIZE = 180
resize_and_rescale = keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
result = resize_and_rescale(image)
plt.axis('off')
plt.imshow(result);
1
Appliquons une inversion et une rotation aléatoires à la même image. Nous utiliserons loop, subplot et imshow pour afficher six images avec une augmentation géométrique aléatoire.
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.4),
])
plt.figure(figsize=(8, 7))
for i in range(6):
augmented_image = data_augmentation(image)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_image.numpy()/255)
plt.axis("off")Note: si vous rencontrez "WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers)", essayez de convertir votre image en numpy et de la diviser par 255. Il vous montrera un résultat clair au lieu d'une image délavée.

Outre l'augmentation simple, vous pouvez également appliquer les fonctions RandomContrast, RandomCrop, HeightCrop, WidthCrop et RandomZoom aux images.
Il y a deux façons d'appliquer l'augmentation aux images. La première méthode consiste à ajouter directement les couches d'augmentation au modèle.
model = keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
# Add the model layers
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1,activation='sigmoid')
])Remarque: l'augmentation des données est inactive pendant la phase de test. Il ne fonctionnera que pour Model.fit, pas pour Model.evaluate ou Model.predict.
La deuxième méthode consiste à appliquer l'augmentation des données à l'ensemble du train à l'aide de Dataset.map.
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y))Nous allons créer une fonction de prétraitement des données pour traiter les ensembles de formation, de validation et de test.
La fonction sera:
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)Nous allons créer un modèle simple avec convolution et couches denses. Assurez-vous que la forme de l'entrée est similaire à celle de l'image.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1,activation='softmax')
])Nous allons maintenant compiler le modèle et l'entraîner pendant une période. L'optimiseur est Adam, la fonction de perte est l'entropie croisée binaire et la métrique est la précision.
Comme nous pouvons le constater, nous avons obtenu une précision de validation de 51 % en une seule fois. Vous pouvez l'entraîner pendant plusieurs époques et optimiser les hyperparamètres pour obtenir des résultats encore meilleurs.
La partie relative à la construction du modèle et à l'entraînement vise simplement à vous donner une idée de la manière dont vous pouvez enrichir les images et entraîner le modèle.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)582/582 [==============================] - 98s 147ms/step - loss: 0.6993 - accuracy: 0.4961 - val_loss: 0.6934 - val_accuracy: 0.5185loss, acc = model.evaluate(test_ds)73/73 [==============================] - 4s 48ms/step - loss: 0.6932 - accuracy: 0.5013Apprenez à effectuer des analyses d'images et à construire, former et évaluer des réseaux de convolution en suivant le cours Image Processing with Keras.
Dans cette section, nous apprendrons à augmenter les images à l'aide de TensorFlow afin d'avoir un contrôle plus fin de l'augmentation des données.
Nous allons charger à nouveau l'ensemble de données cats_vs_dogs avec les étiquettes et les métadonnées.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Au lieu d'une image de chat, nous utiliserons une image de chien et appliquerons diverses techniques d'augmentation.
image, label = next(iter(train_ds))
plt.imshow(image)
plt.title(get_label_name(label));
1
Nous allons créer la fonction visualize pour afficher la différence entre l'image originale et l'image augmentée.
La fonction est assez simple. Il prend en entrée l'image originale et la fonction d'augmentation et affiche la différence à l'aide de matplotlib.
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.axis("off")
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
plt.axis("off")Comme vous pouvez le constater, nous avons retourné l'image de gauche à droite à l'aide de la fonction tf.image. Il est beaucoup plus simple que keras.Sequential.
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
1
Convertissons l'image en niveaux de gris en utilisant `tf.image.rgb_to_grayscale`.
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
1
Vous pouvez également ajuster la saturation par un facteur de 3.
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
1
Réglez la luminosité en indiquant un facteur de luminosité.
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
1
Recadrez l'image à partir du centre en utilisant une fraction centrale de 0,5.
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
1
Faites pivoter l'image de 90 degrés en utilisant la fonction `tf.image.rot90`.
rotated = tf.image.rot90(image)
visualize(image, rotated)
1
Tout comme les couches Keras, tf.image dispose également de fonctions d'augmentation aléatoire. Dans l'exemple ci-dessous, nous appliquerons la luminosité aléatoire à l'image et afficherons plusieurs résultats.
Comme vous pouvez le constater, la première image est un peu plus sombre, et les deux images suivantes sont plus claires.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)


Tout comme keras, nous pouvons appliquer une fonction d'augmentation des données à l'ensemble du jeu de données à l'aide de Dataset.map.
def augment(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
image = tf.image.random_crop(image, size=[IMG_SIZE, IMG_SIZE, 3])
image = tf.image.random_brightness(image, max_delta=0.5)
return image, label
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)Le générateur Keras ImageDataGenerator est encore plus simple. Il fonctionne mieux lorsque vous chargez des données à partir d'un répertoire local ou d'un fichier CSV.
Dans cet exemple, nous allons télécharger et charger un petit jeu de données CIFAR10 à partir de la bibliothèque de jeux de données par défaut de Keras.
Ensuite, nous appliquerons l'augmentation en utilisant `keras.preprocessing.image.ImageDataGenerator`. Cette fonction permet de faire pivoter les images de manière aléatoire, de modifier leur hauteur et leur largeur et de les retourner horizontalement.
Enfin, nous adapterons ImageDataGenerator à l'ensemble de données d'apprentissage et afficherons six images avec une augmentation aléatoire.
Remarque: la taille de l'image est de 32x32, ce qui signifie que nous disposons d'un écran à faible résolution.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
datagen = keras.preprocessing.image.ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
datagen.fit(x_train)
for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6):
for i in range(0, 6):
plt.subplot(2,3,i+1)
plt.imshow(X_batch[i]/255)
plt.axis('off')
break
Dans cette section, nous allons découvrir d'autres outils open-source que vous pouvez utiliser pour réaliser diverses techniques d'augmentation des données et améliorer les performances du modèle.
La transformation d'images est disponible dans le module torchvision.transforms. Comme pour Keras, vous pouvez ajouter des couches de transformation dans torch.nn.Sequential ou appliquer une fonction d'augmentation séparément sur l'ensemble de données.
Augmentor est un package Python pour l'augmentation d'images et la génération d'images artificielles. Vous pouvez effectuer des distorsions de perspective, des distorsions élastiques, des rotations, des cisaillements, des recadrages et des miroirs. Augmentor est également doté d'une fonctionnalité de prétraitement d'image de base.
Albumentations est un outil Python rapide et flexible pour l'augmentation d'images. Il est largement utilisé dans les concours d'apprentissage automatique, dans l'industrie et dans la recherche pour améliorer les performances des réseaux neuronaux convolutionnels profonds.
Imgaug est un outil open-source pour l'augmentation d'images. Il prend en charge une grande variété de techniques d'augmentation, telles que le bruit gaussien, le contraste, la netteté, le recadrage, l'affinité et le retournement. Il dispose d'une interface stochastique simple mais puissante, et il est fourni avec des points clés, des boîtes de délimitation, des cartes thermiques et des cartes de segmentation.
OpenCV est une bibliothèque massive à code source ouvert pour la vision par ordinateur, l'apprentissage automatique et le traitement d'images. Il est généralement utilisé dans la construction d'applications en temps réel. Vous pouvez utiliser OpenCV pour enrichir des images et des vidéos sans problème.
Les fonctions d'augmentation d'image fournies par Tensorflow et Keras sont pratiques. Il vous suffit d'ajouter une couche d'augmentation, tf.image ou ImageDataGenerator pour effectuer l'augmentation. Outre les cadres d'apprentissage profond, vous pouvez utiliser des outils autonomes tels que Augmentor, Albumentations, OpenCV et Imgaug pour procéder à l'augmentation des données.
Dans ce tutoriel, nous avons appris les avantages, les limites, les applications et les techniques de l'augmentation des données. De plus, nous avons appris à appliquer l'augmentation d'image sur l'ensemble de données chats vs. chiens en utilisant Keras et Tensorflow. Si vous souhaitez en savoir plus sur le traitement d'images, consultez le cursus Traitement d'images avec Python. Il vous enseignera les bases de la transformation et de la manipulation d'images, de l'analyse d'images médicales et du traitement d'images avancé à l'aide de Keras.
Cours supérieurs
Cours
Cours
Cours
Tutoriel
DataCamp Team
Tutoriel
Aditya Sharma
Tutoriel
Sejal Jaiswal
Tutoriel
DataCamp Team
Tutoriel
DataCamp Team
Tutoriel
Abid Ali Awan