
Program
Pengembangan Model Bahasa Besar
16 Hr
Bertumpu pada kesuksesan QwQ dan Qwen2.5, Qwen3 mewakili lompatan besar dalam penalaran, kreativitas, dan kemampuan percakapan. Dengan akses terbuka ke model dense dan Mixture-of-Experts (MoE), mulai dari 0,6B hingga 235B-A22B parameter, Qwen3 dirancang untuk unggul dalam beragam tugas.
Dalam tutorial ini, kita akan melakukan fine-tuning model Qwen3-32B pada dataset penalaran medis. Tujuannya adalah mengoptimalkan kemampuan model untuk bernalar dan merespons secara akurat terhadap pertanyaan pasien, memastikan pendekatan yang presisi dan efisien untuk tanya jawab medis.
Kami selalu memperbarui pembaca tentang perkembangan terbaru AI melalui The Median, buletin gratis setiap Jumat yang merangkum cerita kunci pekan ini. Berlangganan dan tetap tajam hanya dalam beberapa menit per minggu:
Jika Anda ingin mempelajari lebih lanjut tentang Qwen 3 dan bagaimana ia bersaing, lihat panduan pengantar kami untuk model ini, Qwen 3: Fitur, Perbandingan dengan DeepSeek-R1, Akses, dan Lainnya.

Gambar oleh Penulis
Buka dasbor RunPod Anda dan pastikan saldo minimal $5. Selanjutnya, pilih model A100 SXM dan pilih versi PyTorch terbaru. Terakhir, klik tombol “Deploy On-Demand” untuk meluncurkan Pod Anda.
Sumber: My Pods
Ubah pengaturan Pod Anda dan atur ukuran disk kontainer menjadi 100 GB. Selain itu, sertakan token akses Hugging Face Anda sebagai variabel lingkungan.
Sumber: My Pods
Setelah pengaturan diterapkan, klik “Connect” untuk meluncurkan Jupyter Lab.
Sumber: My Pods
Jupyter Lab sudah dilengkapi paket dan ekstensi yang diperlukan, sehingga Anda bisa langsung mulai melatih tanpa penyiapan tambahan.
Sumber: My Pods
Sebelum melanjutkan, pastikan semua paket Python yang diperlukan telah terpasang dan diperbarui.
Jalankan perintah berikut di sel Jupyter Notebook:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersGunakan token akses Hugging Face yang Anda simpan sebelumnya untuk masuk ke Hugging Face Hub.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Meskipun kita memiliki 80GB VRAM, kita akan memuat model Qwen3 menggunakan kuantisasi 4-bit. Ini memungkinkan kita memasukkan model ke GPU dengan mudah dan melakukan fine-tuning tanpa repot.
Unduh dan muat model serta tokenizer Qwen3-32B dari Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 3. Memuat dan Memroses Dataset
3. Memuat dan Memroses DatasetPada bagian ini, kita akan berfokus pada pengembangan gaya prompt yang mendorong model untuk melakukan pemikiran kritis. Kita akan membuat struktur prompt yang mencakup sistem prompt dengan placeholder untuk pertanyaan, rantai pemikiran, dan jawaban akhir.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Berikutnya, kita akan membuat fungsi Python yang akan menggunakan gaya train prompt dan menerapkan nilai yang sesuai untuk membuat kolom “text”.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Lalu, kita akan memuat 2000 sampel pertama dari dataset FreedomIntelligence/medical-o1-reasoning-SFT, kemudian menerapkan fungsi formatting_prompts_func untuk membuat kolom “text”.
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Seperti terlihat, kolom text berisi sistem prompt, instruksi, pertanyaan, rantai pemikiran, dan jawaban atas pertanyaan.

STF trainer yang baru tidak menerima tokenizer, jadi kita akan mengubah tokenizer menjadi data collator menggunakan fungsi transformer sederhana.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Gaya prompt untuk inferensi berbeda dari prompt pelatihan. Ia mencakup semua hal dari gaya prompt pelatihan kecuali rantai pemikiran dan jawaban.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Untuk menguji performa model sebelum fine-tuning, kita akan mengambil sampel ke-11 dari dataset dan memberikannya ke model setelah diformat dan dikonversi menjadi token.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Hasilnya, kita menerima bagian pemikiran yang panjang dan tidak ada jawaban, bahkan setelah 1200 token baru. Ini cukup berbeda dari dataset yang ringkas dan padat.

Sekarang kita akan menerapkan LoRA (Low-Rank Adaptation). LoRA bekerja dengan membekukan sebagian besar parameter model dan menambahkan sejumlah kecil parameter yang dapat dilatih, yang ditambahkan dalam format dekomposisi low-rank. Ini memungkinkan model beradaptasi dengan tugas baru tanpa perlu memperbarui atau menyimpan seluruh bobot model.
Pendekatan ini hemat memori, lebih cepat, dan hemat biaya, sambil tetap mencapai akurasi yang sebanding dengan fine-tuning penuh.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Sekarang kita akan mengonfigurasi dan menginisialisasi SFTTrainer (Supervised Fine-Tuning Trainer), sebuah abstraksi tingkat tinggi yang disediakan oleh pustaka transformers dan trl dari Hugging Face. SFTTrainer menyederhanakan proses fine-tuning dengan mengintegrasikan komponen kunci—seperti dataset, model, data collator, argumen pelatihan, dan konfigurasi LoRA—ke dalam alur kerja yang terpadu.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Sebelum memulai pelatihan, kita akan membersihkan cache dan membebaskan sebagian RAM dan GPU VRAM untuk menghindari masalah kehabisan memori (OOM) selama proses pelatihan. Berikut caranya:
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Saat pelatihan dimulai, Anda akan melihat pod Anda menggunakan 100% GPU dan 85% GPU VRAM. Ini menunjukkan bahwa kita berada di titik optimal.
Waktu pelatihan memakan 42 menit untuk selesai, dan seperti terlihat, training loss berkurang secara bertahap.
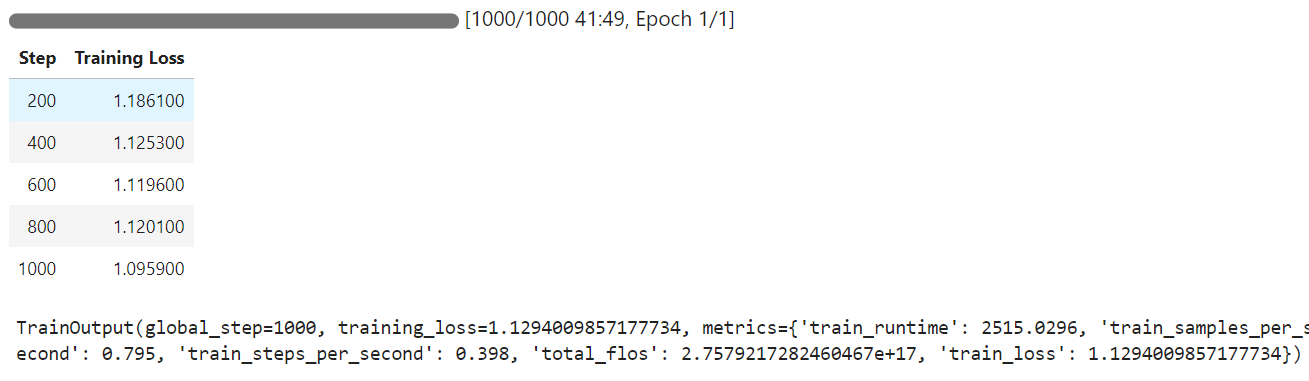
Sekarang kita akan menguji model yang telah di-fine-tune pada sampel yang sama seperti sebelumnya dan kemudian membandingkan hasilnya.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Bagian pemikiran menjadi lebih singkat dan jawabannya presisi, selaras dengan dataset. Ini hasil yang sangat baik.

Mari uji performa Qwen3 yang telah di-fine-tune pada sampel lain dari dataset.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Sekali lagi, proses berpikirnya presisi dan singkat, dan responsnya akurat, mirip dengan dataset.

Jika Anda mengalami kesulitan melakukan fine-tuning pada model Qwen3 Anda, silakan lihat notebook pendamping: fine-tuning-qwen-3.
Langkah terakhir adalah menyimpan model dan tokenizer lalu mengunggahnya ke Hugging Face Hub, sehingga kita dapat membangun aplikasi atau membagikannya dengan komunitas open-source.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Setelah model dan tokenizer diunggah, akan dihasilkan tautan ke repositori. Sebagai contoh: kingabzpro/Qwen-3-32B-Medical-Reasoning · Hugging Face
Sumber: kingabzpro/Qwen-3-32B-Medical-Reasoning
Repositori model memiliki tag yang sesuai, deskripsi, notebook pendamping, dan semua berkas yang diperlukan agar Anda bisa memuat dan mengujinya sendiri.
Qwen-3 mewakili langkah penting lainnya menuju demokratisasi AI. Anda dapat dengan mudah mengunduh Qwen-3, menjalankannya di PC (tanpa akses internet), melakukan fine-tuning, atau bahkan meng-host di server lokal Anda. Benar-benar, Qwen-3 mewujudkan prinsip AI terbuka.
Dalam tutorial ini, kita telah mempelajari cara melakukan fine-tuning model Qwen-3 pada dataset penalaran medis menggunakan platform Runpod. Menariknya, seluruh proses menelan biaya kurang dari $3. Untuk lebih meningkatkan performa fine-tuning, Anda dapat melatih model pada seluruh dataset setidaknya selama 3 epoch.
Anda dapat mempelajari lebih lanjut tentang model Qwen 3 melalui panduan kami, Qwen 3: Fitur, Perbandingan dengan DeepSeek-R1, Akses, dan Lainnya. Anda juga dapat melihat panduan kami tentang Cara Menggunakan Qwen 2.4-VL Secara Lokal dan Fine-Tuning DeepSeek R1 (Model Penalaran).
Kursus Teratas di DataCamp
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
