
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
Com base no sucesso do QwQ e do Qwen2.5o Qwen3 representa um grande avanço em termos de raciocínio, criatividade e recursos de conversação. Com acesso aberto a modelos densos e modelos Mixture-of-Experts (MoE)com parâmetros que variam de 0,6B a 235B-A22B, o Qwen3 foi projetado para se destacar em uma ampla gama de tarefas.
Neste tutorial, faremos o ajuste fino do modelo Qwen3-32B em um conjunto de dados de raciocínio médico. O objetivo é otimizar a capacidade do modelo de raciocinar e responder com precisão às consultas dos pacientes, garantindo que ele adote uma abordagem precisa e eficiente para responder a perguntas médicas.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
Se você quiser saber mais sobre o Qwen 3 e como ele se comporta, consulte nosso guia de introdução ao modelo, Qwen 3: Recursos, comparação do DeepSeek-R1, acesso e muito mais.

Imagem do autor
Vá para seu RunPod e verifique se você tem um mínimo de US$ 5 em sua conta. Em seguida, escolha o modelo A100 SXM e selecione a versão mais recente do PyTorch. Por fim, clique no botão "Deploy On-Demand" para iniciar seu Pod.
Fonte: Meus pods
Modifique as configurações do Pod e ajuste o tamanho do disco do contêiner para 100 GB. Além disso, inclua seu token de acesso ao Hugging Face como uma variável de ambiente.
Fonte: Meus pods
Depois que as configurações forem aplicadas, clique em "Connect" (Conectar) para iniciar o Jupyter Lab.
Fonte: Meus pods
O Jupyter Lab vem pré-instalado com os pacotes e extensões necessários, permitindo que você inicie o treinamento sem configurações adicionais.
Fonte: Meus pods
Antes de continuar, verifique se todos os pacotes Python necessários estão instalados e atualizados.
Execute os seguintes comandos em uma célula do Jupyter Notebook:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersUse o token de acesso Hugging Face que você salvou anteriormente para fazer login no Hugging Face Hub.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Embora tenhamos 80 GB de VRAM, carregaremos o modelo Qwen3 usando quantização de 4 bits. quantização de 4 bits. Isso nos permitirá ajustar facilmente o modelo na GPU e fazer o ajuste fino sem problemas.
Baixe e carregue o modelo Qwen3-32B e o tokenizador do Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 . Carregamento e processamento do conjunto de dados
. Carregamento e processamento do conjunto de dadosNesta seção, vamos nos concentrar no desenvolvimento de um estilo de prompt que incentive o modelo a se envolver no pensamento crítico. Criaremos uma estrutura de prompt que inclui um prompt de sistema com espaços reservados para a pergunta, uma cadeia de pensamento e a resposta final.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Em seguida, criaremos a função Python que usará o estilo de prompt de trem e aplicará o respectivo valor a ele para criar a coluna "text".
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Em seguida, carregaremos as primeiras 2.000 amostras do arquivo FreedomIntelligence/medical-o1-reasoning-SFT e, em seguida, aplicaremos a função formatting_prompts_func para criar a coluna "text".
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Como você pode ver, a coluna de texto contém o prompt do sistema, as instruções, as perguntas, a cadeia de raciocínio e as respostas à pergunta.

O novo instrutor do STF não aceita o tokenizador, portanto, converteremos o tokenizador em um coletor de dados usando a função de transformação simples.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)O estilo do prompt de inferência é diferente do prompt de trem. Ele inclui tudo do estilo de prompt de treinamento, exceto a cadeia de pensamento e a resposta.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Para testar o desempenho do modelo antes do ajuste fino, pegaremos a 11ª amostra do conjunto de dados e a forneceremos ao modelo após a formatação e a conversão em tokens.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Como resultado, recebemos um longo período de reflexão e nenhuma resposta, mesmo depois dos 1.200 novos tokens. Isso é bem diferente do conjunto de dados, que é curto e conciso.

Agora vamos implementar LoRA (Low-Rank Adaptation). O LoRA funciona congelando a maioria dos parâmetros do modelo e introduzindo um pequeno conjunto de parâmetros treináveis, que são adicionados em um formato de decomposição de baixa classificação. Isso permite que o modelo se adapte a novas tarefas sem a necessidade de atualizar ou armazenar o conjunto completo de pesos do modelo.
Essa abordagem é eficiente em termos de memória, mais rápida e econômica e, ao mesmo tempo, atinge uma precisão comparável ao ajuste fino completo.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Agora vamos configurar e inicializar o SFTTrainer (Supervised Fine-Tuning Trainer), uma abstração de alto nível fornecida pelas bibliotecas de transformadores e trl da Hugging Face. O SFTTrainer simplifica o processo de ajuste fino ao integrar os principais componentes, como conjunto de dados, modelo, agrupador de dados, argumentos de treinamento e configuração de LoRA, em um único fluxo de trabalho otimizado.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Antes de iniciarmos o treinamento, limparemos o cache e liberaremos um pouco de RAM e VRAM da GPU para evitar problemas de falta de memória (OOM) durante o processo de treinamento. Veja como podemos fazer isso:
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Quando o treinamento começar, você perceberá que o pod está usando 100% da GPU e 85% da VRAM da GPU. Isso indica que atingimos o ponto ideal.
O tempo de treinamento levou 42 minutos para ser concluído e, como você pode ver, a perda de treinamento diminuiu gradualmente.
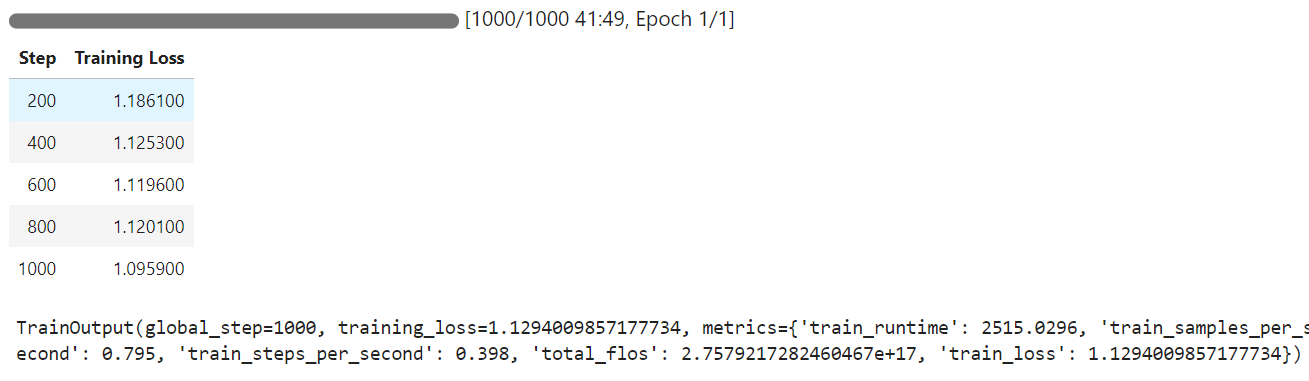
Agora, testaremos o modelo ajustado na mesma amostra de antes e compararemos os resultados.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Reduzimos a seção de raciocínio e a resposta precisa, o que se alinha com o conjunto de dados. Esse é um resultado incrível.

Vamos testar o desempenho do Qwen3 ajustado em outra amostra do conjunto de dados.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Mais uma vez, o processo de raciocínio foi preciso e curto, e a resposta foi precisa, semelhante ao conjunto de dados.

Se você estiver tendo problemas para fazer o ajuste fino do seu modelo Qwen3, consulte o notebook complementar: ajuste fino-qwen-3.
A etapa final é salvar o modelo e o tokenizador e carregá-los no hub Hugging Face, o que nos permite criar um aplicativo ou compartilhar o modelo com a comunidade de código aberto.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Depois que o modelo e o tokenizador forem carregados, será gerado um link para o repositório. Por exemplo: kingabzpro/Qwen-3-32B-Medical-Reasoning - Hugging Face
Fonte: kingabzpro/Qwen-3-32B-Medical-Reasoning
O repositório de modelos tem as tags apropriadas, uma descrição, um notebook complementar e todos os arquivos necessários para você carregar e testar.
O Qwen-3 representa outro passo significativo em direção à democratização da IA. Você pode baixar facilmente o Qwen-3, executá-lo em seu PC (sem acesso à Internet), ajustá-lo ou até mesmo hospedá-lo em seu servidor local. Na verdade, o Qwen-3 incorpora os princípios da IA aberta.
Neste tutorial, aprendemos a fazer o ajuste fino do modelo Qwen-3 em um conjunto de dados de raciocínio médico usando a plataforma Runpod. Notavelmente, todo o processo custou menos de US$ 3. Para melhorar ainda mais o desempenho do ajuste fino, você pode treinar o modelo no conjunto de dados completo por pelo menos 3 épocas.
Você pode saber mais sobre o modelo Qwen 3 em nosso guia, Qwen 3: Recursos, comparação do DeepSeek-R1, acesso e muito mais. Você também pode ver nossos guias sobre Como usar o Qwen 2.4-VL localmente e Ajuste fino do DeepSeek R1 (modelo de raciocínio).
Principais cursos da DataCamp
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Aashi Dutt
Tutorial
Dimitri Didmanidze

