
Programma
Sviluppare modelli linguistici di grandi dimensioni
16 h
Sulla scia del successo di QwQ e Qwen2.5, Qwen3 rappresenta un grande passo avanti in termini di ragionamento, creatività e capacità conversazionali. Con accesso aperto sia a modelli densi sia a modelli Mixture-of-Experts (MoE), da 0,6B a 235B-A22B parametri, Qwen3 è progettato per eccellere in un'ampia gamma di task.
In questo tutorial, effettueremo il fine-tuning del modello Qwen3-32B su un dataset di ragionamento medico. L'obiettivo è ottimizzare la capacità del modello di ragionare e rispondere con precisione alle domande dei pazienti, assicurando un approccio accurato ed efficiente al question answering in ambito medico.
Tieniti aggiornato sulle ultime novità dell'IA con The Median, la nostra newsletter gratuita del venerdì che riassume le notizie chiave della settimana. Iscriviti e rimani sul pezzo in pochi minuti alla settimana:
Se vuoi saperne di più su Qwen 3 e su come si posiziona rispetto agli altri, dai un'occhiata alla nostra guida introduttiva al modello, Qwen 3: funzionalità, confronto con DeepSeek-R1, accesso e altro.

Immagine dell'autore
Vai alla tua dashboard di RunPod e assicurati di avere almeno $5 nel tuo account. Poi scegli il modello A100 SXM e seleziona la versione più recente di PyTorch. Infine, clicca sul pulsante “Deploy On-Demand” per avviare il tuo Pod.
Fonte: My Pods
Modifica le impostazioni del Pod e imposta la dimensione del disco del container a 100 GB. Inoltre, aggiungi il tuo token di accesso a Hugging Face come variabile d'ambiente.
Fonte: My Pods
Una volta applicate le impostazioni, clicca su “Connect” per avviare Jupyter Lab.
Fonte: My Pods
Jupyter Lab arriva preinstallato con i pacchetti e le estensioni necessari, permettendoti di iniziare l'addestramento senza ulteriori setup.
Fonte: My Pods
Prima di procedere, assicurati che tutti i pacchetti Python richiesti siano installati e aggiornati.
Esegui i seguenti comandi in una cella di Jupyter Notebook:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersUsa il token di accesso a Hugging Face salvato in precedenza per accedere a Hugging Face Hub.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Anche se abbiamo 80GB di VRAM, caricheremo il modello Qwen3 usando la quantizzazione a 4 bit. Questo ci permetterà di adattare facilmente il modello alla GPU e di effettuare il fine-tuning senza problemi.
Scarica e carica il modello e il tokenizer Qwen3-32B da Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 3. Caricamento e preparazione del dataset
3. Caricamento e preparazione del datasetIn questa sezione ci concentreremo sullo sviluppo di uno stile di prompt che incoraggi il modello a pensare in modo critico. Creeremo una struttura di prompt che includa un prompt di sistema con placeholder per la domanda, una chain of thought e la risposta finale.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""A seguire, creeremo la funzione Python che utilizzerà lo stile del prompt di training e applicherà i rispettivi valori per creare la colonna “text”.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Quindi caricheremo i primi 2000 campioni dal dataset FreedomIntelligence/medical-o1-reasoning-SFT e applicheremo la funzione formatting_prompts_func per creare la colonna “text”.
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Come possiamo vedere, la colonna text contiene il prompt di sistema, le istruzioni, le domande, la chain of thought e le risposte alla domanda.

Il nuovo trainer STF non accetta il tokenizer, quindi convertirermo il tokenizer in un data collator usando la semplice funzione di transformers.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Lo stile del prompt per l'inferenza è diverso da quello di training. Include tutto dallo stile di training tranne la chain of thought e la risposta.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Per testare le prestazioni del modello prima del fine-tuning, prenderemo l'11° campione del dataset e lo forniremo al modello dopo la formattazione e la conversione in token.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Di conseguenza, abbiamo ricevuto una lunga parte di “pensiero” e nessuna risposta, anche dopo 1200 nuovi token. Questo è piuttosto diverso dal dataset, che è breve e conciso.

Ora implementeremo LoRA (Low-Rank Adaptation). LoRA funziona congelando la maggior parte dei parametri del modello e introducendo un piccolo set di parametri addestrabili, aggiunti in un formato di decomposizione a basso rango. Questo permette al modello di adattarsi a nuovi task senza dover aggiornare o memorizzare l'intero set di pesi.
Questo approccio è efficiente in memoria, più veloce ed economico, pur mantenendo un'accuratezza paragonabile al fine-tuning completo.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Ora configureremo e inizializzeremo l'SFTTrainer (Supervised Fine-Tuning Trainer), un'astrazione di alto livello fornita dalle librerie transformers e trl di Hugging Face. L'SFTTrainer semplifica il processo di fine-tuning integrando componenti chiave—come dataset, modello, data collator, argomenti di training e configurazione LoRA— in un unico workflow snello.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Prima di iniziare l'addestramento, svuoteremo la cache e libereremo un po' di RAM e VRAM della GPU per evitare problemi di out-of-memory (OOM) durante il processo. Ecco come farlo:
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Quando l'addestramento inizia, noterai che il tuo pod utilizza il 100% della GPU e l'85% della VRAM della GPU. Questo indica che abbiamo trovato il giusto equilibrio.
Il tempo di addestramento è stato di 42 minuti e, come puoi vedere, la training loss si è ridotta gradualmente.
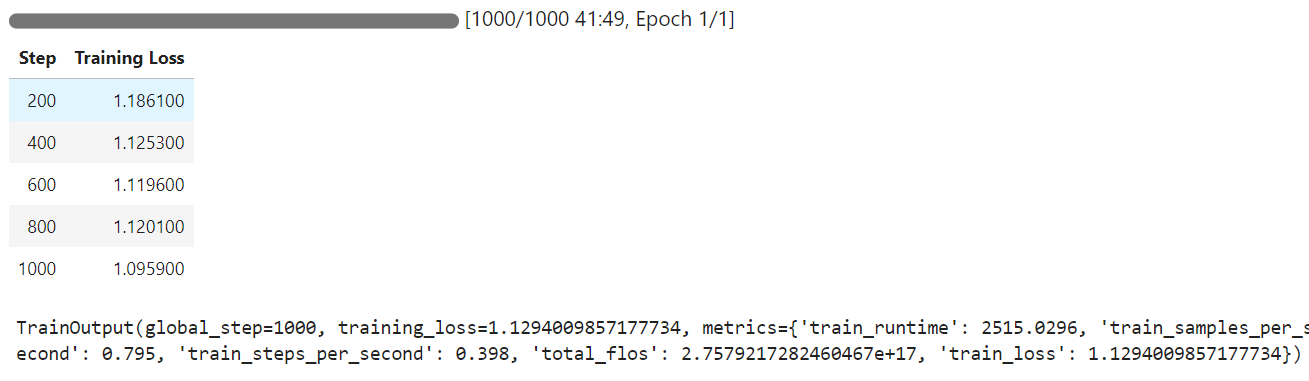
Ora testeremo il modello fine-tunato sullo stesso campione di prima e poi confronteremo i risultati.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Abbiamo accorciato la sezione di “pensiero” e reso la risposta precisa, in linea con il dataset. Un ottimo risultato.

Mettiamo alla prova le prestazioni del Qwen3 fine-tunato su un altro campione del dataset.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Ancora una volta, il processo di pensiero è stato preciso e breve, e la risposta accurata, in linea con il dataset.

Se riscontri problemi nel fine-tuning del tuo modello Qwen3, consulta il notebook di accompagnamento: fine-tuning-qwen-3.
Il passo finale è salvare il modello e il tokenizer e caricarli su Hugging Face Hub, così da poter costruire un'applicazione o condividere il modello con la community open source.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Una volta caricati modello e tokenizer, verrà generato un link al repository. Ad esempio: kingabzpro/Qwen-3-32B-Medical-Reasoning · Hugging Face
Fonte: kingabzpro/Qwen-3-32B-Medical-Reasoning
Il repository del modello ha i tag appropriati, una descrizione, un notebook di accompagnamento e tutti i file necessari per caricarlo e testarlo in autonomia.
Qwen-3 rappresenta un altro passo significativo verso la democratizzazione dell'IA. Puoi scaricare facilmente Qwen-3, eseguirlo sul tuo PC (anche senza accesso a internet), effettuare il fine-tuning o persino ospitarlo sul tuo server locale. Davvero, Qwen-3 incarna i principi dell'open AI.
In questo tutorial abbiamo visto come effettuare il fine-tuning del modello Qwen-3 su un dataset di ragionamento medico usando la piattaforma Runpod. Sorprendentemente, l'intero processo è costato meno di $3. Per migliorare ulteriormente le prestazioni del tuo fine-tuning, puoi addestrare il modello sull'intero dataset per almeno 3 epoche.
Puoi approfondire il modello Qwen 3 con la nostra guida, Qwen 3: funzionalità, confronto con DeepSeek-R1, accesso e altro. Puoi anche consultare le nostre guide su Come usare Qwen 2.4-VL in locale e Fine-tuning di DeepSeek R1 (Reasoning Model).
I migliori corsi DataCamp
Programma
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

