
programa
Desarrollar grandes modelos lingüísticos
16 h
Basándose en el éxito de QwQ y Qwen2.5Qwen3 representa un gran salto adelante en razonamiento, creatividad y capacidades conversacionales. Con acceso abierto tanto a modelos densos como a modelos de Mezcla de Expertos (MoE)que van desde los parámetros 0,6B hasta los 235B-A22B, Qwen3 está diseñado para sobresalir en una amplia gama de tareas.
En este tutorial, pondremos a punto el modelo Qwen3-32B en un conjunto de datos de razonamiento médico. El objetivo es optimizar la capacidad del modelo para razonar y responder con precisión a las consultas de los pacientes, asegurándose de que adopta un enfoque preciso y eficaz para responder a las preguntas médicas.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
Si quieres saber más sobre Qwen 3 y cómo se comporta, consulta nuestra guía introductoria al modelo, Qwen 3: Características, comparación DeepSeek-R1, acceso y más.

Imagen del autor
Ve a tu RunPod y asegúrate de que tienes un mínimo de 5 $ en tu cuenta. A continuación, elige el modelo A100 SXM y selecciona la última versión de PyTorch. Por último, haz clic en el botón "Desplegar bajo demanda" para lanzar tu Pod.
Fuente: Mis vainas
Modifica la configuración de tu Pod y ajusta el tamaño del disco contenedor a 100 GB. Además, incluye tu token de acceso a Cara de Abrazo como variable de entorno.
Fuente: Mis vainas
Una vez aplicados los ajustes, haz clic en "Conectar" para iniciar Jupyter Lab.
Fuente: Mis vainas
Jupyter Lab viene preinstalado con los paquetes y extensiones necesarios, lo que te permite empezar a formarte sin configuraciones adicionales.
Fuente: Mis vainas
Antes de continuar, asegúrate de que todos los paquetes de Python necesarios están instalados y actualizados.
Ejecuta los siguientes comandos en una celda de Jupyter Notebook:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersUtiliza el token de acceso a Hugging Face que guardaste anteriormente para iniciar sesión en Hugging Face Hub.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Aunque tengamos 80 GB de VRAM, cargaremos el modelo Qwen3 utilizando 4 bits cuantificación. Esto nos permitirá adaptar fácilmente el modelo a la GPU y ajustarlo sin problemas.
Descarga y carga el modelo Qwen3-32B y el tokenizador de Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 . Cargar y procesar el conjunto de datos
. Cargar y procesar el conjunto de datosEn esta sección, nos centraremos en desarrollar un estilo de indicación que anime al modelo a participar en el pensamiento crítico. Crearemos una estructura de avisos que incluya un sistema de avisos con marcadores de posición para la pregunta, una cadena de pensamiento y la respuesta final.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""A continuación, crearemos la función Python que utilizará el estilo de indicación de tren y le aplicará el valor correspondiente para crear la columna "texto".
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}A continuación, cargaremos las 2000 primeras muestras del archivo FreedomIntelligence/medical-o1-razonamiento-SFT y aplicaremos la función formatting_prompts_func para crear la columna "texto".
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Como podemos ver, la columna de texto contiene la indicación del sistema, las instrucciones, las preguntas, la cadena de pensamiento y las respuestas a la pregunta.

El nuevo entrenador STF no acepta el tokenizador, así que convertiremos el tokenizador en un recopilador de datos utilizando la función transformador simple.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)El estilo del indicador de inferencia es diferente del indicador de tren. Incluye todo lo del estilo de aviso de entrenamiento excepto la cadena de pensamiento y respuesta.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Para probar el rendimiento del modelo antes de afinarlo, tomaremos la 11ª muestra del conjunto de datos y se la proporcionaremos al modelo después de formatearla y convertirla en tokens.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Como resultado, recibimos una larga parte pensante y ninguna respuesta, incluso después de los 1200 nuevos tokens. Esto es muy diferente del conjunto de datos, que es breve y conciso.

Ahora aplicaremos LoRA (Adaptación de bajo rango). LoRA funciona congelando la mayoría de los parámetros del modelo e introduciendo un pequeño conjunto de parámetros entrenables, que se añaden en un formato de descomposición de bajo rango. Esto permite que el modelo se adapte a nuevas tareas sin necesidad de actualizar o almacenar el conjunto completo de pesos del modelo.
Este enfoque es eficiente en memoria, más rápido y rentable, al tiempo que consigue una precisión comparable a la del ajuste fino completo.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Ahora configuraremos e inicializaremos el SFTTrainer (Entrenador de Ajuste Fino Supervisado), una abstracción de alto nivel proporcionada por las bibliotecas de transformadores y trl de Hugging Face. El SFTTrainer simplifica el proceso de ajuste integrando los componentes clave -como el conjunto de datos, el modelo, el cotejador de datos, los argumentos de entrenamiento y la configuración de LoRA- en un flujo de trabajo único y racionalizado.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Antes de empezar el entrenamiento, borraremos la caché y liberaremos algo de RAM y VRAM de la GPU para evitar problemas de falta de memoria (OOM) durante el proceso de entrenamiento. He aquí cómo podemos hacerlo:
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Cuando comience el entrenamiento, notarás que tu pod está utilizando el 100% de la GPU y el 85% de la VRAM de la GPU. Esto indica que hemos dado en el clavo.
El tiempo de entrenamiento fue de 42 minutos, y como puedes ver, la pérdida de entrenamiento se redujo gradualmente.
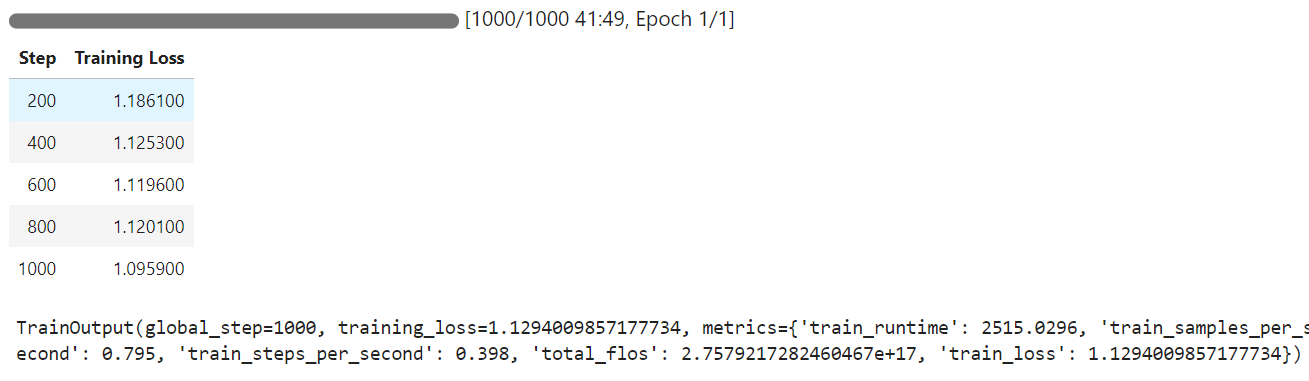
Ahora probaremos el modelo afinado en la misma muestra que antes y luego compararemos los resultados.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Hemos acortado la sección de pensamiento y la respuesta precisa, lo que se ajusta al conjunto de datos. Es un resultado asombroso.

Probemos el rendimiento del Qwen3 afinado en otra muestra del conjunto de datos.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Una vez más, el proceso de pensamiento fue preciso y breve, y la respuesta fue exacta, similar a la del conjunto de datos.

Si tienes problemas para ajustar tu modelo Qwen3, consulta el cuaderno que lo acompaña: ajuste-qwen-3.
El paso final es guardar el modelo y el tokenizador y subirlos al hub Cara Abrazada, lo que nos permitirá crear una aplicación o compartir el modelo con la comunidad de código abierto.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Una vez cargados el modelo y el tokenizador, se generará un enlace al repositorio. Por ejemplo kingabzpro/Qwen-3-32B-Medical-Reasoning - Cara de abrazo
Fuente: kingabzpro/Qwen-3-32B-Medical-Reasoning
El repositorio del modelo tiene las etiquetas apropiadas, una descripción, un cuaderno complementario y todos los archivos necesarios para que los cargues y pruebes tú mismo.
Qwen-3 representa otro paso significativo hacia la democratización de la IA. Puedes descargar fácilmente Qwen-3, ejecutarlo en tu PC (sin acceso a Internet), ponerlo a punto o incluso alojarlo en tu servidor local. Verdaderamente, Qwen-3 encarna los principios de la IA abierta.
En este tutorial, hemos aprendido a afinar el modelo Qwen-3 en un conjunto de datos de razonamiento médico utilizando la plataforma Runpod. Sorprendentemente, todo el proceso costó menos de 3 $. Para mejorar aún más el rendimiento de tu ajuste fino, puedes entrenar el modelo en el conjunto de datos completo durante al menos 3 épocas.
Puedes obtener más información sobre el modelo Qwen 3 con nuestra guía, Qwen 3: Características, comparación DeepSeek-R1, acceso y más. También puedes consultar nuestras guías sobre Cómo utilizar Qwen 2.4-VL localmente y Cómo afinar DeepSeek R1 (Modelo de razonamiento).
Los mejores cursos de DataCamp
programa
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Abid Ali Awan



