
Tracks
Phát triển các mô hình ngôn ngữ quy mô lớn
16 giờ
Tiếp nối thành công của QwQ và Qwen2.5, Qwen3 là một bước tiến lớn về khả năng suy luận, sáng tạo và đối thoại. Với quyền truy cập mở vào cả mô hình dense và Mixture-of-Experts (MoE) với quy mô từ 0.6B đến 235B-A22B tham số, Qwen3 được thiết kế để vượt trội trong nhiều tác vụ.
Trong hướng dẫn này, chúng ta sẽ tinh chỉnh mô hình Qwen3-32B trên một bộ dữ liệu suy luận y khoa. Mục tiêu là tối ưu khả năng suy luận và phản hồi chính xác trước các câu hỏi của bệnh nhân, đảm bảo mô hình áp dụng cách tiếp cận chuẩn xác và hiệu quả cho bài toán hỏi đáp y khoa.
Chúng tôi cập nhật cho độc giả những thông tin mới nhất về AI qua The Median, bản tin miễn phí mỗi thứ Sáu tóm lược các câu chuyện chính trong tuần. Đăng ký để bắt kịp chỉ trong vài phút mỗi tuần:
Nếu bạn muốn tìm hiểu thêm về Qwen 3 và cách so sánh của nó, hãy xem hướng dẫn nhập môn về mô hình, Qwen 3: Tính năng, so sánh với DeepSeek-R1, cách truy cập và hơn thế nữa.

Ảnh: Tác giả
Truy cập bảng điều khiển RunPod của bạn và đảm bảo tài khoản có tối thiểu 5 USD. Tiếp theo, chọn GPU A100 SXM và phiên bản PyTorch mới nhất. Cuối cùng, nhấn nút “Deploy On-Demand” để khởi chạy Pod.
Nguồn: My Pods
Chỉnh sửa cài đặt Pod và tăng dung lượng đĩa container lên 100 GB. Đồng thời thêm access token của Hugging Face dưới dạng biến môi trường.
Nguồn: My Pods
Khi đã áp dụng cài đặt, nhấp “Connect” để mở Jupyter Lab.
Nguồn: My Pods
Jupyter Lab được cài sẵn các gói và tiện ích cần thiết, cho phép bạn bắt đầu huấn luyện mà không cần thiết lập thêm.
Nguồn: My Pods
Trước khi tiếp tục, hãy đảm bảo tất cả các gói Python cần thiết đã được cài đặt và cập nhật.
Chạy các lệnh sau trong một ô của Jupyter Notebook:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersSử dụng access token Hugging Face mà bạn đã lưu để đăng nhập vào Hugging Face Hub.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Dù có 80GB VRAM, chúng ta vẫn sẽ tải mô hình Qwen3 với lượng tử hóa 4-bit. Cách này giúp mô hình dễ dàng vừa với GPU và tinh chỉnh thuận lợi.
Tải mô hình và tokenizer Qwen3-32B từ Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 3. Tải và xử lý bộ dữ liệu
3. Tải và xử lý bộ dữ liệuTrong phần này, chúng ta sẽ phát triển một phong cách nhắc lệnh (prompt) khuyến khích mô hình tư duy phản biện. Ta sẽ tạo cấu trúc prompt gồm lời nhắc hệ thống với chỗ trống cho câu hỏi, chuỗi suy nghĩ và phản hồi cuối cùng.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Tiếp theo, chúng ta sẽ tạo hàm Python sử dụng phong cách prompt huấn luyện và điền các giá trị tương ứng để tạo cột “text”.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Sau đó, chúng ta sẽ tải 2000 mẫu đầu tiên từ bộ dữ liệu FreedomIntelligence/medical-o1-reasoning-SFT rồi áp dụng hàm formatting_prompts_func để tạo cột “text”.
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Như ta thấy, cột văn bản chứa prompt hệ thống, hướng dẫn, câu hỏi, chuỗi suy nghĩ và câu trả lời.

Trình huấn luyện STF mới không chấp nhận tokenizer, vì vậy chúng ta sẽ chuyển tokenizer thành data collator bằng hàm đơn giản của transformers.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Phong cách prompt cho suy luận khác với prompt huấn luyện. Nó giữ mọi thứ từ prompt huấn luyện trừ phần chuỗi suy nghĩ và phản hồi.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Để kiểm tra hiệu năng mô hình trước khi tinh chỉnh, chúng ta sẽ lấy mẫu thứ 11 trong bộ dữ liệu, định dạng và chuyển thành token rồi đưa vào mô hình.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Kết quả là ta nhận được phần suy nghĩ rất dài và không có câu trả lời, ngay cả sau 1200 token mới. Điều này khá khác so với bộ dữ liệu, vốn ngắn gọn súc tích.

Giờ chúng ta sẽ triển khai LoRA (Low-Rank Adaptation). LoRA hoạt động bằng cách đóng băng phần lớn tham số của mô hình và thêm một tập nhỏ tham số có thể huấn luyện theo dạng phân rã hạng thấp. Điều này cho phép mô hình thích nghi với tác vụ mới mà không cần cập nhật hoặc lưu toàn bộ trọng số mô hình.
Cách tiếp cận này tiết kiệm bộ nhớ, nhanh và chi phí thấp nhưng vẫn đạt độ chính xác tương đương với tinh chỉnh toàn phần.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Tiếp theo, chúng ta sẽ cấu hình và khởi tạo SFTTrainer (Supervised Fine-Tuning Trainer), một lớp trừu tượng cấp cao do thư viện transformers và trl của Hugging Face cung cấp. SFTTrainer đơn giản hóa quá trình tinh chỉnh bằng cách tích hợp các thành phần chính — như bộ dữ liệu, mô hình, data collator, tham số huấn luyện và cấu hình LoRA — vào một quy trình thống nhất.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Trước khi bắt đầu huấn luyện, chúng ta sẽ dọn cache và giải phóng một phần RAM và VRAM GPU để tránh lỗi tràn bộ nhớ (OOM) trong quá trình huấn luyện. Thực hiện như sau:
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Khi huấn luyện bắt đầu, bạn sẽ thấy pod sử dụng 100% GPU và khoảng 85% VRAM GPU. Điều này cho thấy chúng ta đã đạt điểm tối ưu.
Thời gian huấn luyện mất 42 phút và như bạn thấy, training loss giảm dần.
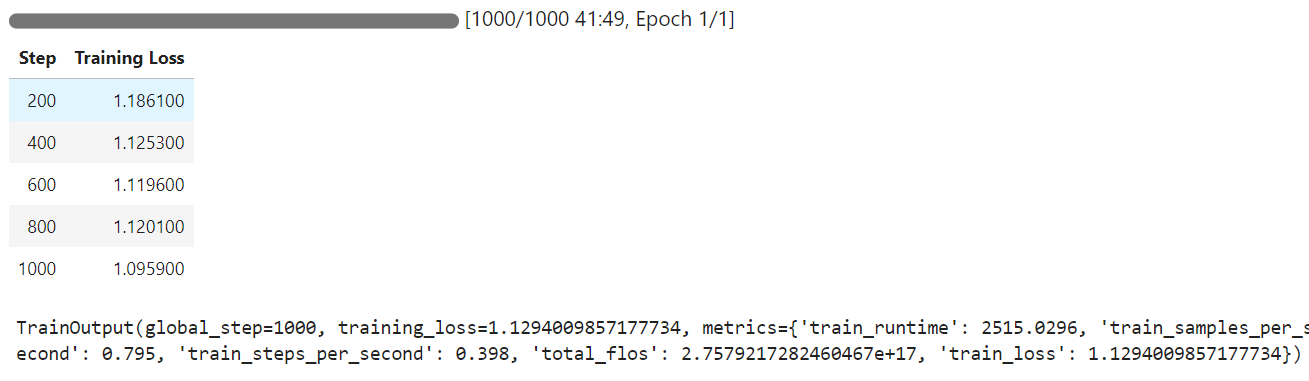
Giờ chúng ta sẽ kiểm thử mô hình đã tinh chỉnh trên cùng mẫu như trước và so sánh kết quả.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Phần suy nghĩ đã ngắn gọn hơn và câu trả lời chính xác, phù hợp với bộ dữ liệu. Đây là kết quả rất tốt.

Hãy kiểm thử hiệu năng của Qwen3 đã tinh chỉnh trên một mẫu khác trong bộ dữ liệu.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Một lần nữa, quá trình suy nghĩ ngắn gọn, chính xác và phản hồi đúng, tương tự bộ dữ liệu.

Nếu bạn gặp khó khăn khi tinh chỉnh mô hình Qwen3, hãy xem sổ tay đi kèm: fine-tuning-qwen-3.
Bước cuối cùng là lưu mô hình và tokenizer rồi tải chúng lên Hugging Face Hub, cho phép chúng ta xây dựng ứng dụng hoặc chia sẻ mô hình với cộng đồng mã nguồn mở.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Sau khi tải mô hình và tokenizer lên, sẽ tạo liên kết tới kho lưu trữ. Ví dụ: kingabzpro/Qwen-3-32B-Medical-Reasoning · Hugging Face
Nguồn: kingabzpro/Qwen-3-32B-Medical-Reasoning
Kho mô hình có gắn thẻ phù hợp, mô tả, sổ tay đi kèm và đầy đủ tệp cần thiết để bạn tự tải và kiểm thử.
Qwen-3 là một bước tiến đáng kể hướng tới dân chủ hóa AI. Bạn có thể dễ dàng tải Qwen-3, chạy trên PC (không cần internet), tinh chỉnh hoặc thậm chí tự lưu trữ trên máy chủ nội bộ. Thật sự, Qwen-3 thể hiện tinh thần của AI mở.
Trong hướng dẫn này, chúng ta đã học cách tinh chỉnh mô hình Qwen-3 trên bộ dữ liệu suy luận y khoa bằng nền tảng Runpod. Đáng chú ý, toàn bộ quá trình tốn chưa đến 3 USD. Để cải thiện hiệu năng tinh chỉnh, bạn có thể huấn luyện mô hình trên toàn bộ bộ dữ liệu trong ít nhất 3 epoch.
Bạn có thể tìm hiểu thêm về mô hình Qwen 3 qua hướng dẫn Qwen 3: Tính năng, so sánh với DeepSeek-R1, cách truy cập và hơn thế nữa. Bạn cũng có thể xem các hướng dẫn về Cách sử dụng Qwen 2.4-VL cục bộ và Tinh chỉnh DeepSeek R1 (Mô hình Suy luận).
Các khóa học hàng đầu trên DataCamp
Tracks
Courses
Courses