
Cursus
Développer des LLM
16 h
S'appuyant sur le succès de QwQ et de Qwen2.5Qwen3 représente une avancée majeure en matière de raisonnement, de créativité et de capacités conversationnelles. Avec un accès ouvert aux modèles denses et mélange d'experts (MoE)allant de 0,6B à 235B-A22B, Qwen3 est conçu pour exceller dans un large éventail de tâches.
Dans ce tutoriel, nous allons affiner le modèle Qwen3-32B sur un ensemble de données de raisonnement médical. L'objectif est d'optimiser la capacité du modèle à raisonner et à répondre avec précision aux questions des patients, en veillant à ce qu'il adopte une approche précise et efficace pour répondre aux questions médicales.
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
Si vous souhaitez en savoir plus sur le Qwen 3 et ses performances, consultez notre guide d'introduction au modèle, Qwen 3 : Fonctionnalités, comparaison avec DeepSeek-R1, accès, et plus encore.

Image par l'auteur
Accédez à votre RunPod et assurez-vous d'avoir un minimum de 5 $ sur votre compte. Choisissez ensuite le modèle A100 SXM et sélectionnez la dernière version de PyTorch. Enfin, cliquez sur le bouton "Déployer à la demande" pour lancer votre Pod.
Source : Mes gousses
Modifiez vos paramètres Pod et ajustez la taille du disque du conteneur à 100 Go. De plus, incluez votre jeton d'accès à Hugging Face en tant que variable d'environnement.
Source : Mes gousses
Une fois les paramètres appliqués, cliquez sur "Connect" pour lancer Jupyter Lab.
Source : Mes gousses
Jupyter Lab est livré préinstallé avec les paquets et les extensions nécessaires, ce qui vous permet de commencer la formation sans installation supplémentaire.
Source : Mes gousses
Avant de poursuivre, assurez-vous que tous les paquets Python requis sont installés et à jour.
Exécutez les commandes suivantes dans une cellule Jupyter Notebook :
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersUtilisez le jeton d'accès Hugging Face que vous avez enregistré précédemment pour vous connecter à Hugging Face Hub.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Même si nous disposons de 80 Go de VRAM, nous chargerons le modèle Qwen3 en utilisant une quantification de 4 bits. quantification de 4 bits. Cela nous permettra d'adapter facilement le modèle au GPU et de l'affiner sans problème.
Téléchargez et chargez le modèle Qwen3-32B et le tokenizer depuis Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 . Chargement et traitement de l'ensemble de données
. Chargement et traitement de l'ensemble de donnéesDans cette section, nous nous concentrerons sur le développement d'un style d'invite qui encourage le modèle à s'engager dans une réflexion critique. Nous créerons une structure d'invite qui comprendra une invite système avec des espaces réservés pour la question, une chaîne de pensée et la réponse finale.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Ensuite, nous allons créer la fonction Python qui utilisera le style d'invite de train et lui appliquera la valeur correspondante pour créer la colonne "texte".
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Ensuite, nous chargerons les 2000 premiers échantillons de la base de données de FreedomIntelligence/medical-o1-reasoning-SFT puis nous appliquerons la fonction formatting_prompts_func pour créer la colonne "texte".
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Comme vous pouvez le constater, la colonne de texte contient l'invite du système, les instructions, les questions, la chaîne de pensée et les réponses à la question.

Le nouvel entraîneur STF n'accepte pas le tokenizer, nous allons donc convertir le tokenizer en un collateur de données à l'aide de la fonction de transformation simple.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Le style de l'invite à la déduction est différent de celui de l'invite au train. Il comprend tout le style de l'invite de formation, à l'exception de la chaîne de pensée et de la réponse.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Pour tester les performances du modèle avant de l'affiner, nous prendrons le 11e échantillon de l'ensemble de données et le fournirons au modèle après l'avoir formaté et converti en jetons.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])En conséquence, nous avons reçu un long délai de réflexion et aucune réponse, même après l'envoi des 1200 nouveaux jetons. Ceci est très différent de l'ensemble de données, qui est court et concis.

Nous allons maintenant mettre en œuvre LoRA (Low-Rank Adaptation). La méthode LoRA consiste à geler la majorité des paramètres du modèle et à introduire un petit ensemble de paramètres susceptibles d'être entraînés, qui sont ajoutés sous la forme d'une décomposition de faible rang. Cela permet au modèle de s'adapter à de nouvelles tâches sans qu'il soit nécessaire de mettre à jour ou de stocker l'ensemble des poids du modèle.
Cette approche est économe en mémoire, plus rapide et moins coûteuse, tout en permettant d'obtenir une précision comparable à celle d'un réglage fin complet.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Nous allons maintenant configurer et initialiser le SFTTrainer (Supervised Fine-Tuning Trainer), une abstraction de haut niveau fournie par les bibliothèques transformers et trl de Hugging Face. Le SFTTrainer simplifie le processus de mise au point en intégrant les composants clés - tels que le jeu de données, le modèle, le collecteur de données, les arguments d'entraînement et la configuration LoRA - dans un flux de travail unique et rationalisé.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Avant de commencer l'entraînement, nous allons vider le cache et libérer un peu de RAM et de VRAM du GPU afin d'éviter les problèmes de mémoire défaillante (OOM) pendant le processus d'entraînement. Voici comment nous pouvons y parvenir :
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Lorsque l'entraînement commence, vous remarquerez que votre pod utilise 100 % du GPU et 85 % de la VRAM du GPU. Cela indique que nous avons atteint le point idéal.
L'entraînement a duré 42 minutes et, comme vous pouvez le constater, la perte d'entraînement s'est progressivement réduite.
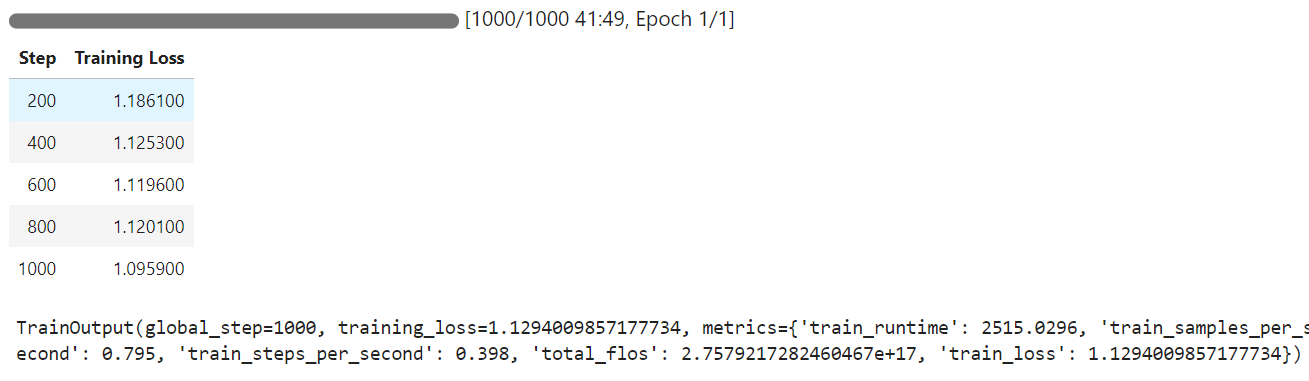
Nous allons maintenant tester le modèle affiné sur le même échantillon que précédemment et comparer les résultats.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Nous avons raccourci la section de réflexion et la réponse précise, ce qui correspond à l'ensemble des données. C'est un résultat étonnant.

Testons les performances du Qwen3 affiné sur un autre échantillon de l'ensemble de données.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Une fois de plus, le processus de réflexion a été précis et court, et la réponse a été exacte, comme dans l'ensemble des données.

Si vous avez des difficultés à régler votre modèle Qwen3, veuillez consulter le cahier d'accompagnement : réglage-qwen-3.
L'étape finale consiste à enregistrer le modèle et le tokenizer et à les télécharger vers le hub Hugging Face, ce qui nous permet de construire une application ou de partager le modèle avec la communauté open-source.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Une fois le modèle et le tokenizer téléchargés, un lien vers le référentiel sera généré. Par exemple : kingabzpro/Qwen-3-32B-Medical-Reasoning - Hugging Face
Source : kingabzpro/Qwen-3-32B-Raisonnement médical
Le référentiel de modèles contient les balises appropriées, une description, un cahier d'accompagnement et tous les fichiers nécessaires pour que vous puissiez les charger et les tester vous-même.
Qwen-3 représente une autre étape importante vers la démocratisation de l'IA. Vous pouvez facilement télécharger Qwen-3, l'exécuter sur votre PC (sans accès à Internet), le peaufiner ou même l'héberger sur votre serveur local. Qwen-3 incarne véritablement les principes de l'IA ouverte.
Dans ce tutoriel, nous avons appris à affiner le modèle Qwen-3 sur un ensemble de données de raisonnement médical à l'aide de la plateforme Runpod. Fait remarquable, l'ensemble du processus a coûté moins de 3 dollars. Pour améliorer encore les performances de votre réglage fin, vous pouvez entraîner le modèle sur l'ensemble des données pendant au moins 3 époques.
Vous pouvez en savoir plus sur le modèle Qwen 3 grâce à notre guide, Qwen 3 : Fonctionnalités, comparaison avec DeepSeek-R1, accès, et plus encore. Vous pouvez également consulter nos guides sur Comment utiliser Qwen 2.4-VL en local ? et Ajustement de DeepSeek R1 (modèle de raisonnement).
Les meilleurs cours de DataCamp
Cursus
Cours
Cours
blog
Zoumana Keita
15 min
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Samuel Shaibu


