
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Aufbauend auf dem Erfolg von QwQ und Qwen2.5stellt Qwen3 einen großen Sprung nach vorne dar, was das logische Denken, die Kreativität und die Konversationsfähigkeiten angeht. Mit offenem Zugang zu sowohl dichten als auch Mixture-of-Experts (MoE) Modellemit Parametern von 0,6B bis 235B-A22B ist Qwen3 so konzipiert, dass es sich für eine Vielzahl von Aufgaben eignet.
In diesem Lernprogramm werden wir das Qwen3-32B-Modell anhand eines Datensatzes zum medizinischen Reasoning feinabstimmen. Ziel ist es, die Fähigkeit des Modells zu optimieren, auf Patientenanfragen genau zu reagieren und sicherzustellen, dass es einen präzisen und effizienten Ansatz zur Beantwortung medizinischer Fragen verfolgt.
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Wenn du mehr über das Qwen 3 erfahren möchtest und wie es abschneidet, schau dir unseren Einführungsleitfaden zu dem Modell an: Qwen 3: Funktionen, DeepSeek-R1 Vergleich, Zugang und mehr.

Bild vom Autor
Gehe zu deinem RunPod Dashboard und vergewissere dich, dass du mindestens 5 $ auf deinem Konto hast. Als Nächstes wählst du das Modell A100 SXM aus und wählst die neueste Version von PyTorch. Zum Schluss klickst du auf die Schaltfläche "On-Demand bereitstellen", um deinen Pod zu starten.
Quelle: Meine Schoten
Ändere deine Pod-Einstellungen und passe die Größe der Container-Festplatte auf 100 GB an. Füge außerdem dein Hugging Face-Zugangs-Token als Umgebungsvariable hinzu.
Quelle: Meine Schoten
Sobald die Einstellungen übernommen wurden, klicke auf "Verbinden", um Jupyter Lab zu starten.
Quelle: Meine Schoten
Jupyter Lab wird mit den notwendigen Paketen und Erweiterungen vorinstalliert, so dass du ohne zusätzliche Einstellungen mit dem Training beginnen kannst.
Quelle: Meine Schoten
Bevor du fortfährst, stelle sicher, dass alle erforderlichen Python-Pakete installiert und auf dem neuesten Stand sind.
Führe die folgenden Befehle in einer Zelle von Jupyter Notebook aus:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersVerwende das Hugging Face-Zugangs-Token, das du zuvor gespeichert hast, um dich bei Hugging Face Hub anzumelden.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Obwohl wir 80 GB VRAM haben, laden wir das Qwen3-Modell mit 4-Bit Quantisierung. So können wir das Modell leicht auf den Grafikprozessor anpassen und es ohne Probleme feinabstimmen.
Lade das Qwen3-32B-Modell und den Tokenizer von Hugging Face Hub herunter und lade sie.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 . Laden und Verarbeiten des Datensatzes
. Laden und Verarbeiten des DatensatzesIn diesem Abschnitt werden wir uns darauf konzentrieren, einen Aufforderungsstil zu entwickeln, der das Modell zu kritischem Denken anregt. Wir werden eine Prompt-Struktur erstellen, die einen Systemprompt mit Platzhaltern für die Frage, eine Gedankenkette und die endgültige Antwort enthält.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Als Nächstes erstellen wir die Python-Funktion, die den Stil der Zugabfrage verwendet und den entsprechenden Wert darauf anwendet, um die Spalte "Text" zu erstellen.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Dann laden wir die ersten 2000 Proben aus dem FreedomIntelligence/medical-o1-reasoning-SFT Datensatz und wenden dann die Funktion formatting_prompts_func an, um die Spalte "Text" zu erstellen.
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Wie wir sehen können, enthält die Textspalte die Systemaufforderung, Anweisungen, Fragen, Gedankenketten und Antworten auf die Frage.

Der neue STF-Trainer akzeptiert den Tokenizer nicht, also wandeln wir den Tokenizer mit der einfachen Transformatorfunktion in einen Datensammler um.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Der Stil der Schlussfolgerungsaufforderung unterscheidet sich von dem der Zugaufforderung. Er enthält alles aus dem Trainingsprompt-Stil, außer der Gedankenkette und der Antwort.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Um die Leistung des Modells vor der Feinabstimmung zu testen, nehmen wir die elfte Probe aus dem Datensatz und stellen sie dem Modell zur Verfügung, nachdem wir sie formatiert und in Tokens umgewandelt haben.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Als Ergebnis erhielten wir eine lange Denkpause und keine Antwort, auch nicht nach den 1200 neuen Token. Das ist ganz anders als der Datensatz, der kurz und prägnant ist.

Wir werden nun implementieren LoRA (Low-Rank Adaptation). Bei LoRA werden die meisten Parameter des Modells eingefroren und ein kleiner Satz trainierbarer Parameter eingeführt, die in Form einer Low-Rank-Zerlegung hinzugefügt werden. So kann sich das Modell an neue Aufgaben anpassen, ohne dass der gesamte Satz von Modellgewichten aktualisiert oder gespeichert werden muss.
Dieser Ansatz ist speichereffizient, schneller und kostengünstiger und erreicht dennoch eine Genauigkeit, die mit einer vollständigen Feinabstimmung vergleichbar ist.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Jetzt konfigurieren und initialisieren wir den SFTTrainer (Supervised Fine-Tuning Trainer), eine High-Level-Abstraktion, die von den Hugging Face-Bibliotheken transformers und trl bereitgestellt wird. Der SFTTrainer vereinfacht den Feinabstimmungsprozess, indem er die wichtigsten Komponenten - wie Datensatz, Modell, Datensammler, Trainingsargumente und LoRA-Konfiguration - in einen einzigen, optimierten Arbeitsablauf integriert.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Bevor wir mit dem Training beginnen, leeren wir den Cache und geben etwas Arbeitsspeicher und GPU-VRAM frei, um zu vermeiden, dass während des Trainings OOM-Probleme (Out-of-Memory) auftreten. Hier ist, wie wir das tun können:
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Wenn das Training beginnt, wirst du feststellen, dass dein Pod 100% der GPU und 85% des GPU-VRAMs nutzt. Das zeigt, dass wir den richtigen Punkt getroffen haben.
Das Training dauerte 42 Minuten, und wie du siehst, hat sich der Trainingsverlust allmählich verringert.
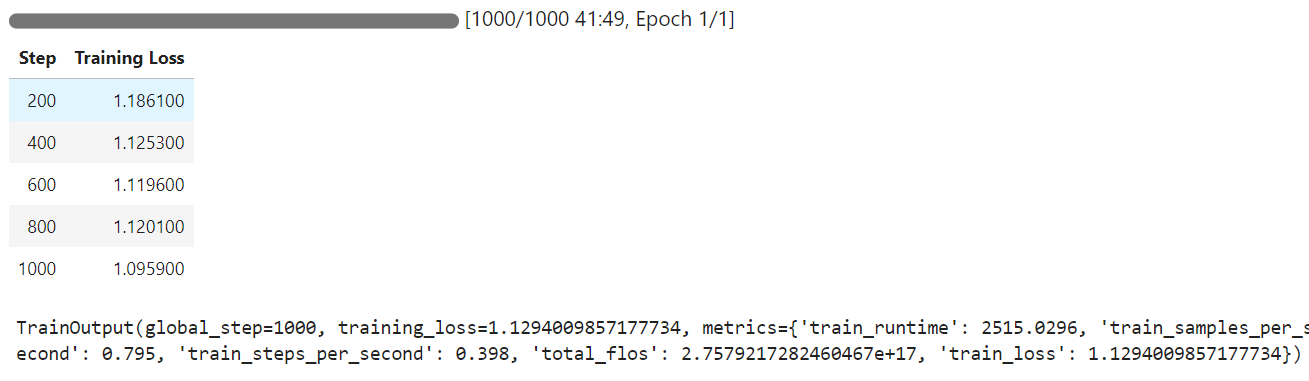
Wir werden nun das feinabgestimmte Modell an derselben Stichprobe wie zuvor testen und die Ergebnisse vergleichen.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Wir haben den Denkabschnitt und die genaue Antwort gekürzt, was mit dem Datensatz übereinstimmt. Das ist ein erstaunliches Ergebnis.

Testen wir die Leistung des fein abgestimmten Qwen3 an einem weiteren Beispiel aus dem Datensatz.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Auch hier war der Denkprozess präzise und kurz und die Antwort war genau, ähnlich wie beim Datensatz.

Wenn du Probleme mit der Feinabstimmung deines Qwen3-Modells hast, schaue bitte im Begleitheft nach: feinabstimmung-qwen-3.
Im letzten Schritt werden das Modell und der Tokenizer gespeichert und in den Hugging Face Hub hochgeladen, damit wir eine Anwendung erstellen oder das Modell mit der Open-Source-Community teilen können.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Sobald das Modell und der Tokenizer hochgeladen sind, wird ein Link zum Repository erstellt. Zum Beispiel: kingabzpro/Qwen-3-32B-Medical-Reasoning - Hugging Face
Quelle: kingabzpro/Qwen-3-32B-Medical-Reasoning
Das Modell-Repository enthält die entsprechenden Tags, eine Beschreibung, ein begleitendes Notizbuch und alle notwendigen Dateien, die du selbst laden und testen kannst.
Qwen-3 ist ein weiterer wichtiger Schritt zur Demokratisierung der KI. Du kannst Qwen-3 ganz einfach herunterladen, auf deinem PC (ohne Internetzugang) ausführen, feinjustieren oder sogar auf deinem lokalen Server hosten. Qwen-3 verkörpert wirklich die Prinzipien der offenen KI.
In diesem Tutorial haben wir gelernt, wie wir das Qwen-3-Modell mit Hilfe der Runpod-Plattform auf einen medizinischen Datensatz abstimmen können. Bemerkenswerterweise kostete der gesamte Prozess weniger als 3 Dollar. Um die Leistung deines Feintunings weiter zu verbessern, kannst du das Modell mindestens 3 Epochen lang mit dem gesamten Datensatz trainieren.
Mehr über das Modell Qwen 3 erfährst du in unserem Leitfaden, Qwen 3: Funktionen, DeepSeek-R1 Vergleich, Zugang und mehr. Du kannst dir auch unsere Anleitungen ansehen zu Wie man Qwen 2.4-VL lokal nutzt und Feinabstimmung von DeepSeek R1 (Reasoning Model).
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Zoumana Keita
15 Min.
Blog
Blog
Nathaniel Taylor-Leach
Tutorial
Matt Crabtree
Tutorial
Adel Nehme
