
Leerpad
Grote taalmodellen ontwikkelen
16 Hr
Voortbouwend op het succes van QwQ en Qwen2.5 markeert Qwen3 een grote sprong voorwaarts in redeneren, creativiteit en gesprekscapaciteiten. Met open toegang tot zowel dichte als Mixture-of-Experts (MoE)-modellen, variërend van 0,6B tot 235B-A22B parameters, is Qwen3 ontworpen om uit te blinken in een breed scala aan taken.
In deze tutorial fine-tunen we het Qwen3-32B-model op een dataset voor medisch redeneren. Het doel is om het vermogen van het model te optimaliseren om te redeneren en nauwkeurig te reageren op patiëntvragen, zodat het een precieze en efficiënte aanpak hanteert voor medische vraag- en antwoordtaken.
We houden onze lezers op de hoogte van het laatste AI-nieuws via The Median, onze gratis vrijdagse nieuwsbrief die de belangrijkste verhalen van de week samenvat. Abonneer je en blijf scherp in een paar minuten per week:
Wil je meer leren over Qwen 3 en hoe het zich verhoudt? Bekijk dan onze introductiegids voor het model, Qwen 3: Features, DeepSeek-R1 Comparison, Access, and More.

Afbeelding door auteur
Ga naar je RunPod-dashboard en zorg dat je minimaal $5 op je account hebt. Kies vervolgens het A100 SXM-model en selecteer de nieuwste versie van PyTorch. Klik ten slotte op de knop “Deploy On-Demand” om je Pod te starten.
Bron: My Pods
Pas je Pod-instellingen aan en stel de containerschijf in op 100 GB. Voeg daarnaast je Hugging Face-toegangstoken toe als omgevingsvariabele.
Bron: My Pods
Zodra de instellingen zijn toegepast, klik je op “Connect” om Jupyter Lab te starten.
Bron: My Pods
Jupyter Lab wordt geleverd met de benodigde pakketten en extensies, zodat je direct kunt trainen zonder extra setup.
Bron: My Pods
Controleer voordat je verdergaat of alle vereiste Python-pakketten zijn geïnstalleerd en up-to-date zijn.
Voer de volgende commando’s uit in een Jupyter Notebook-cel:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersGebruik het Hugging Face-toegangstoken dat je eerder hebt opgeslagen om in te loggen op Hugging Face Hub.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Hoewel we 80GB VRAM hebben, laden we het Qwen3-model met 4-bit kwantisatie. Hierdoor past het model gemakkelijk op de GPU en kunnen we het zonder gedoe fine-tunen.
Download en laad het Qwen3-32B-model en de tokenizer van Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 3. De dataset laden en verwerken
3. De dataset laden en verwerkenIn deze sectie richten we ons op het ontwikkelen van een promptstijl die het model aanzet tot kritisch denken. We maken een promptstructuur met een systeem-prompt en placeholders voor de vraag, een keten van gedachten en de uiteindelijke reactie.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Vervolgens maken we de Python-functie die de train-promptstijl gebruikt en de juiste waarden toepast om de kolom “text” te creëren.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Daarna laden we de eerste 2000 samples uit de FreedomIntelligence/medical-o1-reasoning-SFT-dataset en passen vervolgens de functie formatting_prompts_func toe om de kolom “text” aan te maken.
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Zoals we zien, bevat de tekstkolom de systeem-prompt, instructies, vragen, keten van gedachten en antwoorden op de vraag.

De nieuwe STF-trainer accepteert de tokenizer niet, dus we zetten de tokenizer om in een data-collator met behulp van de eenvoudige transformer-functie.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)De inferentie-promptstijl verschilt van de train-prompt. Hij bevat alles van de train-promptstijl behalve de keten van gedachten en de reactie.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Om de prestaties van het model vóór fine-tuning te testen, nemen we de 11e sample uit de dataset en bieden die aan het model aan na formatteren en converteren naar tokens.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Daardoor kregen we een lang denkstuk en geen antwoord, zelfs niet na 1200 nieuwe tokens. Dit wijkt af van de dataset, die kort en bondig is.

We implementeren nu LoRA (Low-Rank Adaptation). LoRA werkt door het grootste deel van de modelparameters te bevriezen en een kleine set trainbare parameters toe te voegen, in een low-rank-decompositie. Zo kan het model zich aanpassen aan nieuwe taken zonder de volledige modelgewichten te updaten of op te slaan.
Deze aanpak is geheugenvriendelijk, sneller en kostenefficiënt, terwijl de nauwkeurigheid vergelijkbaar blijft met volledige fine-tuning.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)We configureren en initialiseren nu de SFTTrainer (Supervised Fine-Tuning Trainer), een high-level abstractie uit de transformers- en trl-bibliotheken van Hugging Face. De SFTTrainer vereenvoudigt het fine-tuningproces door kernonderdelen—zoals de dataset, het model, de data-collator, trainingsargumenten en de LoRA-configuratie—te integreren in één gestroomlijnde workflow.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Voordat we beginnen met trainen, legen we de cache en maken we wat RAM en GPU-VRAM vrij om OOM-problemen (out-of-memory) tijdens het trainingsproces te voorkomen. Zo doe je dat:
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Wanneer de training start, zie je dat je pod 100% van de GPU en 85% van de GPU-VRAM gebruikt. Dit geeft aan dat we de sweet spot hebben bereikt.
De training duurde 42 minuten en zoals je ziet nam de training loss geleidelijk af.
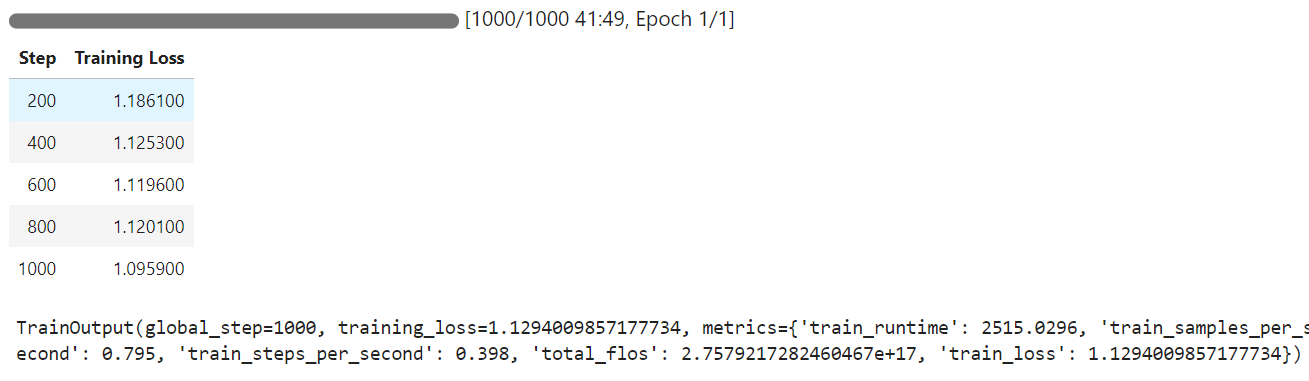
We testen nu het gefinetunede model op dezelfde sample als eerder en vergelijken vervolgens de resultaten.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])We hebben het denkstuk ingekort en een precieze antwoordstijl gekregen, in lijn met de dataset. Een uitstekend resultaat.

Laten we de prestaties van de gefinetunede Qwen3 testen op een andere sample uit de dataset.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Opnieuw was het denkproces precies en kort, en de reactie nauwkeurig, vergelijkbaar met de dataset.

Heb je problemen met het fine-tunen van je Qwen3-model? Raadpleeg dan de bijbehorende notebook: fine-tuning-qwen-3.
De laatste stap is het model en de tokenizer opslaan en uploaden naar de Hugging Face Hub, zodat we een applicatie kunnen bouwen of het model kunnen delen met de open-sourcecommunity.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Zodra het model en de tokenizer zijn geüpload, wordt er een link naar de repository gegenereerd. Bijvoorbeeld: kingabzpro/Qwen-3-32B-Medical-Reasoning · Hugging Face
Bron: kingabzpro/Qwen-3-32B-Medical-Reasoning
De modelrepository heeft de juiste tags, een beschrijving, een bijbehorende notebook en alle benodigde bestanden zodat je het zelf kunt laden en testen.
Qwen-3 betekent opnieuw een belangrijke stap richting de democratisering van AI. Je kunt Qwen-3 eenvoudig downloaden, op je pc draaien (zonder internettoegang), fine-tunen of zelfs hosten op je lokale server. Qwen-3 belichaamt echt de principes van open AI.
In deze tutorial hebben we geleerd hoe je het Qwen-3-model kunt fine-tunen op een dataset voor medisch redeneren met behulp van het Runpod-platform. Opmerkelijk genoeg kostte het hele proces minder dan $3. Om de prestaties van je fine-tuning verder te verbeteren, kun je het model op de volledige dataset trainen voor minstens 3 epochs.
Je kunt meer leren over het Qwen 3-model met onze gids, Qwen 3: Features, DeepSeek-R1 Comparison, Access, and More. Bekijk ook onze gidsen over How to Use Qwen 2.4-VL Locally en Fine-Tuning DeepSeek R1 (Reasoning Model).
Topcursussen bij DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
