
Program
Büyük Dil Modelleri Geliştirme
16 sa
QwQ ve Qwen2.5’in başarısı üzerine inşa edilen Qwen3, akıl yürütme, yaratıcılık ve sohbet yeteneklerinde büyük bir sıçrama anlamına geliyor. 0,6B’den 235B-A22B parametreye kadar hem yoğun hem de Mixture-of-Experts (MoE) modellerine açık erişimle Qwen3, çok çeşitli görevlerde üstün performans gösterecek şekilde tasarlanmıştır.
Bu eğitimde, Qwen3-32B modelini tıbbi akıl yürütme veri kümesi üzerinde ince ayar yapacağız. Amaç, modelin hasta sorularına mantık yürüterek doğru yanıt verme becerisini optimize etmek; tıbbi soru-cevapta kesin ve verimli bir yaklaşım benimsemesini sağlamaktır.
Okurlarımızı en güncel yapay zeka gelişmelerinden haberdar etmek için haftanın öne çıkan haberlerini özetleyen ücretsiz Cuma bültenimiz The Median’ı gönderiyoruz. Abone olun, haftada sadece birkaç dakikada gündemi yakalayın:
Qwen 3 hakkında daha fazla bilgi edinmek ve diğer modellerle karşılaştırmasını görmek isterseniz, giriş niteliğindeki rehberimize göz atın: Qwen 3: Özellikler, DeepSeek-R1 Karşılaştırması, Erişim ve Daha Fazlası.

Görsel: Yazar
RunPod panonuza gidin ve hesabınızda en az 5 $ bulunduğundan emin olun. Ardından A100 SXM modelini seçin ve PyTorch’un en son sürümünü tercih edin. Son olarak Pod’unuzu başlatmak için “Deploy On-Demand” düğmesine tıklayın.
Kaynak: Pod’larım
Pod ayarlarınızı değiştirin ve konteyner disk boyutunu 100 GB’a ayarlayın. Ayrıca, ortama değişkeni olarak Hugging Face erişim belirtecinizi ekleyin.
Kaynak: Pod’larım
Ayarlar uygulandıktan sonra Jupyter Lab’i başlatmak için “Connect”e tıklayın.
Kaynak: Pod’larım
Jupyter Lab, gerekli paketler ve uzantılar önceden yüklenmiş olarak gelir; ek kurulum gerektirmeden eğitime başlayabilirsiniz.
Kaynak: Pod’larım
Devam etmeden önce, gerekli tüm Python paketlerinin kurulu ve güncel olduğundan emin olun.
Aşağıdaki komutları bir Jupyter Notebook hücresinde çalıştırın:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformersHugging Face Hub’a giriş yapmak için daha önce kaydettiğiniz Hugging Face erişim belirtecini kullanın.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)80 GB VRAM’imiz olsa da Qwen3 modelini 4 bit kuantizasyon ile yükleyeceğiz. Bu sayede modeli GPU’ya kolayca sığdırıp zahmetsizce ince ayar yapabileceğiz.
Hugging Face Hub’dan Qwen3-32B modelini ve tokenizer’ını indirin ve yükleyin.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model_dir = "Qwen/Qwen3-32B"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
model.config.use_cache = False
model.config.pretraining_tp = 1 3. Veri Kümesini Yükleme ve İşleme
3. Veri Kümesini Yükleme ve İşlemeBu bölümde, modelin eleştirel düşünmeye yönelmesini teşvik eden bir istem stili geliştirmeye odaklanacağız. Soru, düşünce zinciri ve nihai yanıt için yer tutucular içeren bir sistem istemi yapısı oluşturacağız.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Ardından, eğitim istemi stilini kullanacak ve “text” sütununu oluşturmak için ilgili değeri buna uygulayacak Python fonksiyonunu oluşturacağız.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Daha sonra FreedomIntelligence/medical-o1-reasoning-SFT veri kümesinden ilk 2000 örneği yükleyecek ve ardından “text” sütununu oluşturmak için formatting_prompts_func fonksiyonunu uygulayacağız.
from datasets import load_dataset
dataset = load_dataset(
"FreedomIntelligence/medical-o1-reasoning-SFT",
"en",
split="train[0:2000]",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
dataset["text"][10]Görüldüğü gibi, text sütunu sistem istemini, talimatları, soruları, düşünce zincirini ve yanıtları içeriyor.

Yeni STF eğiticisi tokenizer’ı kabul etmiyor; bu nedenle tokenizer’ı basit bir transformer fonksiyonu kullanarak bir data collator’a dönüştüreceğiz.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Çıkarım istem stili, eğitim isteminden farklıdır. Eğitim istem stilindeki her şeyi içerir ancak düşünce zinciri ve yanıt bölümü yoktur.
inference_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
"""
Modelin ince ayar öncesi performansını test etmek için, veri kümesindeki 11. örneği alıp, biçimlendirdikten ve token’lara dönüştürdükten sonra modele vereceğiz.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Sonuç olarak, 1200 yeni token sonrasında bile uzun bir düşünme bölümü aldık ve yanıt gelmedi. Bu, kısa ve öz olan veri kümesinden oldukça farklı.

Şimdi LoRA (Low-Rank Adaptation) uygulayacağız. LoRA, modelin parametrelerinin büyük kısmını dondurup düşük-rank ayrışım formatında eklenen küçük bir eğitilebilir parametre seti tanıtarak çalışır. Böylece, tam model ağırlıklarını güncellemeden veya depolamadan modelin yeni görevlere uyum sağlaması mümkün olur.
Bu yaklaşım, bellek açısından verimli, daha hızlı ve maliyet-etkindir; yine de tam ince ayara yakın doğruluk elde eder.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Şimdi, Hugging Face’in transformers ve trl kütüphanelerinin sağladığı yüksek seviyeli bir soyutlama olan SFTTrainer’ı (Denetimli İnce Ayar Eğiticisi) yapılandırıp başlatacağız. SFTTrainer, veri kümesi, model, data collator, eğitim argümanları ve LoRA konfigürasyonu gibi temel bileşenleri tek ve akıcı bir iş akışında bir araya getirerek ince ayar sürecini basitleştirir.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Eğitime başlamadan önce, eğitim sırasında bellek yetersizliği (OOM) sorunlarıyla karşılaşmamak için önbelleği temizleyip bir miktar RAM ve GPU VRAM boşaltacağız. Bunu şu şekilde yapabiliriz:
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Eğitim başladığında, pod’unuzun GPU’nun %100’ünü ve GPU VRAM’inin %85’ini kullandığını göreceksiniz. Bu, ideal dengeyi yakaladığımızı gösterir.
Eğitim 42 dakikada tamamlandı ve görüldüğü üzere eğitim kaybı kademeli olarak azaldı.
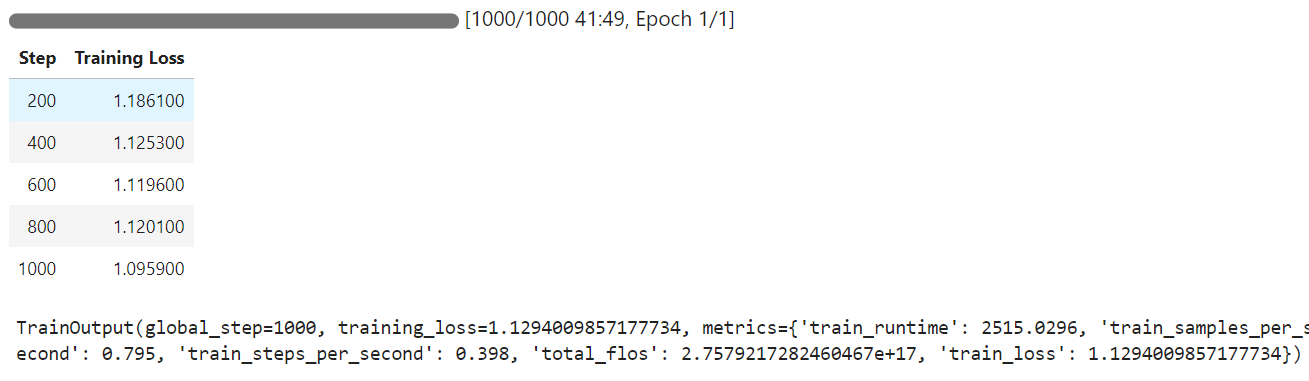
Şimdi, ince ayarlı modeli öncekiyle aynı örnek üzerinde test edip sonuçları karşılaştıralım.
question = dataset[10]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Düşünme bölümü kısaldı ve yanıt netleşti; bu da veri kümesiyle uyumlu. Harika bir sonuç.

İnce ayarlı Qwen3’ün performansını veri kümesinden başka bir örnekte test edelim.
question = dataset[100]['Question']
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Yine, düşünme süreci kısa ve isabetliydi; yanıt da veri kümesine benzer şekilde doğruydu.

Qwen3 modelinizi ince ayarlamada sorun yaşıyorsanız, eşlik eden not defterine bakın: fine-tuning-qwen-3.
Son adım, modeli ve tokenizer’ı kaydedip Hugging Face hub’ına yüklemektir; böylece bir uygulama geliştirebilir veya modeli açık kaynak topluluğuyla paylaşabilirsiniz.
new_model_name = "Qwen-3-32B-Medical-Reasoning"
model.push_to_hub(new_model_name)
tokenizer.push_to_hub(new_model_name)Model ve tokenizer yüklendiğinde depo bağlantısı oluşturulur. Örneğin: kingabzpro/Qwen-3-32B-Medical-Reasoning · Hugging Face
Kaynak: kingabzpro/Qwen-3-32B-Medical-Reasoning
Model deposunda uygun etiketler, bir açıklama, eşlik eden bir not defteri ve sizin de yükleyip test edebilmeniz için gerekli tüm dosyalar bulunmaktadır.
Qwen-3, yapay zekânın demokratikleşmesi yolunda bir başka önemli adımı temsil ediyor. Qwen-3’ü kolayca indirebilir, PC’nizde (internet erişimi olmadan) çalıştırabilir, ince ayar yapabilir veya yerel sunucunuzda barındırabilirsiniz. Gerçekten de Qwen-3, açık yapay zekâ ilkelerini somutlaştırıyor.
Bu eğitimde, Runpod platformunu kullanarak Qwen-3 modelini tıbbi akıl yürütme veri kümesi üzerinde nasıl ince ayar yapacağımızı öğrendik. Dikkat çekici bir şekilde, tüm süreç 3 $’tan daha ucuza mal oldu. İnce ayar performansınızı daha da artırmak için modeli tam veri kümesi üzerinde en az 3 epoch eğitebilirsiniz.
Qwen 3 modeli hakkında daha fazla bilgiyi şu rehberimizde bulabilirsiniz: Qwen 3: Özellikler, DeepSeek-R1 Karşılaştırması, Erişim ve Daha Fazlası. Ayrıca şu rehberlerimize de göz atabilirsiniz: Qwen 2.4-VL Yerelde Nasıl Kullanılır ve DeepSeek R1’i (Akıl Yürütme Modeli) İnce Ayarlama.
Öne Çıkan DataCamp Kursları
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
