
Kursus
Fine-Tuning dengan Llama 3
2 Hr
3.8K
In this tutorial, you will set up a remote H100 SXM instance on Vast.ai, serve Qwen3.5-27B with vLLM, connect it to OpenCode, and test its agentic coding ability on a real FastAPI project.
We are deliberately not using llama.cpp here. While llama.cpp is excellent for many local inference setups, running a quantized 27B model through it often comes with trade-offs: lower output quality, reduced coding performance, and more setup friction.
For larger models like Qwen3.5-27B, quantization can noticeably hurt reliability, and local deployments through llama.cpp can become difficult to manage if you want smooth, production-like agent behavior.
Instead, this tutorial uses vLLM on a rented H100 SXM GPU. That gives you a more stable OpenAI-compatible endpoint, better performance from the full model, and a much cleaner setup for agentic coding workflows.
You can see our separate guide on running Qwen3.5-397B-A17B locally.
Before you begin, make sure you have:
An H100 SXM is a strong choice for this setup because Qwen3.5-27B needs plenty of memory and fast throughput, especially for longer context windows and smoother coding-focused inference.
We are using Vast.ai because it is a GPU marketplace that usually gives you far more flexibility on price and hardware than a traditional single-vendor cloud.
You can rent anything from community-hosted machines to Secure Cloud / datacenter offers, which Vast marks with a blue datacenter label. For a setup like this, I strongly recommend choosing one of those blue-labeled datacenter machines for better reliability and a smoother experience.
Start by creating a Vast.ai account and adding enough credit to cover your session. Then open the search page, pick the PyTorch template with Jupyter enabled, and look for a 1x H100 SXM offer.
Pricing changes constantly on Vast.ai because it is a live marketplace, so treat any hourly rate as approximate rather than fixed.
Once you rent the machine, go to the Instances tab. When the status changes to Open, click the Open button to launch the instance portal in your browser.
From there, you can open Jupyter and start a terminal session directly on the remote machine.
For this tutorial, keep two terminals open:
Keeping these tasks separate makes the workflow much easier to manage once the model server is running.
In this step, you will create an isolated Python environment, install vLLM, and launch Qwen3.5-27B as an OpenAI-compatible API that OpenCode can talk to.
vLLM is a high-throughput inference engine for large language models, designed to serve models efficiently through an API.
In your first terminal, create a clean workspace for the model server:
mkdir qwen-servercd qwen-server/uv venv --python 3.12source .venv/bin/activateThis gives you a dedicated Python 3.12 environment so the model server dependencies stay isolated from the rest of the machine.
Now install vLLM:
uv pip install vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
This installs the inference engine that will expose Qwen3.5 through an OpenAI-compatible API.
Note: You may not need the nightly wheels for this setup, since current vLLM support for Qwen3.5 often works with the standard installation as well.
Once vLLM is installed, start the model server with:
vllm serve Qwen/Qwen3.5-27B \
--host 127.0.0.1 \
--port 8000 \
--api-key local-dev-key \
--served-model-name qwen3.5-27b-local \
--tensor-parallel-size 1 \
--max-model-len 64000 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser qwen3The first time you run this command, vLLM will download the model and tokenizer files.
After that, it will load the model into GPU memory. Once everything is ready, you should see a message showing that the server startup is complete.
This launches Qwen3.5-27B locally on port 8000 and protects the endpoint with the API key local-dev-key.
A few details here matter:
--served-model-name gives the model a name OpenCode can reference--enable-auto-tool-choice supports agent-style behavior--tool-call-parser qwen3_coder is suited for Qwen coding workflows--reasoning-parser qwen3 helps handle Qwen’s reasoning output correctlyLeave this terminal running once the server is ready.
In this step, you will open a second terminal, install OpenCode, and connect it to the local vLLM endpoint you started in Step 2.
OpenCode is an open-source coding agent that can run in the terminal and connect to local models through its provider configuration.
Go back to the instance portal and open a second Jupyter terminal. Keep your first terminal running, since that is the one serving Qwen3.5 through vLLM.
If clicking the Jupyter Terminal button opens the same terminal again, you can usually open another one by changing the number at the end of the terminal URL. For example, if your current terminal ends in /terminals/1, change it to /terminals/2.
This second terminal will be your OpenCode terminal, while the first one continues running the model server.
Run the following command to install OpenCode:
curl -fsSL https://opencode.ai/install | bash
Then refresh your shell:
exec bashThis reloads your shell, so the opencode command is available right away.
OpenCode looks for its global config in ~/.config/opencode/opencode.json, and its provider settings support custom baseURL and apiKey values. That makes it a good fit for a local OpenAI-compatible server like the one you launched with vLLM.
Create the config file with:
mkdir -p ~/.config/opencode && cat > ~/.config/opencode/opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"vllm": {
"npm": "@ai-sdk/openai-compatible",
"name": "Local vLLM",
"options": {
"baseURL": "http://127.0.0.1:8000/v1",
"apiKey": "local-dev-key"
},
"models": {
"qwen3.5-27b-local": {
"name": "Qwen3.5-27B Local"
}
}
}
},
"model": "vllm/qwen3.5-27b-local",
"small_model": "vllm/qwen3.5-27b-local"
}
EOFThis tells OpenCode to use your local vLLM endpoint at http://127.0.0.1:8000/v1 instead of a hosted API. It also uses the same API key you set when launching the vLLM server in Step 2, so OpenCode can authenticate successfully.
Now, create a project directory for testing the coding agent:
mkdir investment-apicd investment-apiopencode
This launches OpenCode inside the investment-api folder and uses your local Qwen3.5 model as its backend.
From here, you can begin asking it to inspect files, explain code, or generate new project components using the model running on your rented GPU.
Now it is time to test the full setup on a real coding task.
I first started with a very simple prompt just to make sure everything was working. Within a second, I got a reply back, which was a good sign that the model was connected properly.
Next, I gave it a more realistic agentic coding task:
"Build a FastAPI backend for investment market data that
collects the latest public data every few minutes for S&P 500,
gold, silver, Brent, major indices, and selected stocks."After around a minute of reasoning, the model started asking useful follow-up questions. It asked which data source to use, what kind of storage or database should be used, and which stock tickers to include.
This was a good sign, because it showed that the model was not just jumping into code blindly. It was trying to clarify the requirements first.
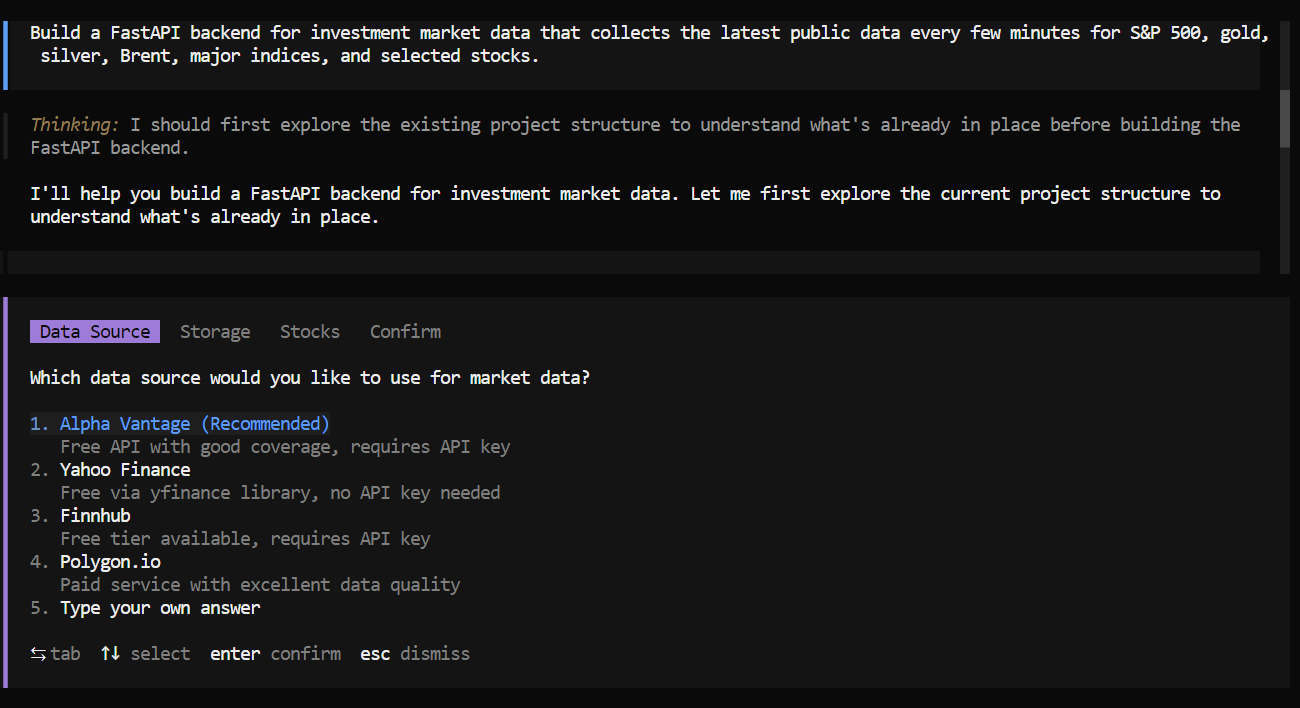
Once that was done, it created a plan and started working through the task step by step. It broke the problem into smaller tasks, added them to its to-do list, and then completed each part one by one.
In less than five minutes, it had created the full project structure and generated a mostly working FastAPI backend, which is very fast for a task like this.
After that, I asked it to test the API and run a smoke test. As a result, we got an almost-working financial API. There were still a few issues to fix, but for a short run like this, the performance was very impressive.
We now have a complete local coding setup running on a rented Vast.ai H100 SXM instance. In this tutorial, we used vLLM to serve Qwen3.5-27B through an OpenAI-compatible API, and then connected that endpoint to OpenCode to use the model in an agentic coding workflow.
This approach gives us a practical way to run a strong open-weight coding model on real tasks without depending on a hosted provider. It also gives us more control over the full stack, from the model server to the coding interface.
Compared with trying to run a heavily quantized 27B model locally through llama.cpp, this setup is often more stable and better suited for serious coding work. We avoid many of the performance trade-offs, memory limitations, and setup issues that can show up when pushing larger models into a purely local environment.
Another big advantage is performance. With this setup, we get very high tokens-per-second throughput, a large context length, and a much smoother overall coding experience. That makes it far more practical for longer prompts, multi-file tasks, and agent-style workflows where the model needs room to reason and keep track of more context.
Top DataCamp Courses
Kursus
Kursus
Kursus
Tutorials
Abid Ali Awan
Tutorials
Abid Ali Awan
Tutorials
Abid Ali Awan
Tutorials
Abid Ali Awan
Tutorials
Abid Ali Awan
Tutorials
Abid Ali Awan
