

Track
AI Agent Fundamentals
6 hr
Alibaba just unveiled its latest large language model, Qwen3.5. This latest model comes in response to new releases, such as GPT-5.3 Codex and Claude Opus 4.6, both of which impressed us.
Qwen 3.5 is ‘built for the agentic AI era’ according to Alibaba, and the vision-language model is reportedly cheaper and more efficient than its predecessor, posting some impressive, frontier-class performance stats in several benchmarks.
Alibaba is also releasing Qwen3.5-Plus, a premium version of the model with a 1-million token context window, which has Gemini 3 firmly in its sights.
In this article, I’ll walk you through the key new features of Qwen3.5 and Qwen3.5-Plus, examining how they stack up to competitors, what the benchmarks are looking like, and exploring how you can access the new models.
Make sure to check out our guides on the latest competitor models as well, such as Claude Sonnet 4.6 or GPT-5.3 Instant.
Qwen3.5 is the latest generation in Alibaba’s large language model (LLM) series, Qwen3.5-397B-A17B. In contrast to the preceding Qwen3 model family, Qwen3.5 combines specialized models into a single native vision-language model. Like earlier Qwen models, it is open-source under the Apache 2.0 license.
It is positioned as a general-purpose foundation model for both consumer and enterprise use cases and is designed for native multimodal and agentic workflows. Qwen3.5-397B-A17B offers two modes:
Qwen3.5-Plus is a hosted, API-only, service corresponding to Qwen3.5-397B-A17B and is not an open‑weight model itself. The release note was slightly confusing in this regard: its mention of Qwen3.5-Plus might be read as a separate model, but in reality, it is Alibaba’s proprietary service built on the same model.
While Qwen3.5-Plus is based on the Qwen3.5-397B-A17B model, there are some differences to note. It can only be accessed via the Alibaba Cloud Model Studio on a pay-per-token basis, and via the Qwen Chat UI with limited access.
Qwen3.5-Plus uses an extended context window of 1 million tokens, compared to the 256K token context window of the standard Qwen3.5 model. In addition to “Thinking” and “Fast”, Qwen3.5-Plus additionally includes an “Auto” mode with adaptive thinking, which, in addition to thinking, can use tools such as search and a code interpreter.
Let’s take a look at some of the new features available with Qwen3.5:
Similar to OpenAI combining its standard and Codex models in the recent GPT-5.3 Codex release, Alibaba combined text, vision, and UI interaction in a single model.
Qwen3.5 was jointly trained on text, images, UI screenshots, and structured content. It supports visual question answering, document understanding, and chart/table interpretation, and handles pixel-level grounding to identify and interact with on-screen elements.
This brings us to the next key focus of the new Qwen3.5 model. Because of extensive training on UI screenshots, the model can recognize and act on mobile and desktop interfaces. This enables the model to execute multi-step workflows like:
This makes Qwen3.5 ideal for productivity automation. By using natural language instructions, you can allow the Qwen visual agent to act across multiple apps, completing complex workflows. It can even maintain a state over long interaction sequences, enabling robust tool and app orchestration.
Qwen3.5 is a fairly huge model, with 397 billion total parameters, although only 17 billion are activated per token, thanks to the mixture-of-experts architecture. Essentially, this means it has the intelligence of a giant model, with the speed and cost efficiency of a much smaller one.
In real terms, this means that, compared to Qwen3-Max, Qwen3.5 397B-A17B is 19x faster at decoding long-context tasks (256k tokens) and 8.6x faster for standard workflows. Crucially, this speed doesn’t compromise on intelligence; it still matches the reasoning and coding performance of Qwen3-Max and outperforms Qwen3-VL, thanks to the early fusion of text and video.
With the improved performance, we also see cost efficiencies with this model.
Similarly, a native, FP8 pipeline (processing data in 8-bit precision, rather than the standard 16-bit), means that Qwen3.5 cuts the memory required to run by 50%. This means calculations can happen faster, improving speeds by over 10% at the trillion-token scale.
Qwen3.5 also features an impressive 250k vocabulary, allowing it to express complex concepts with fewer tokens. Along with multi-token predications, the model can ‘guess’ several future words in a single step, reducing token costs by 10-60% across 201 languages.
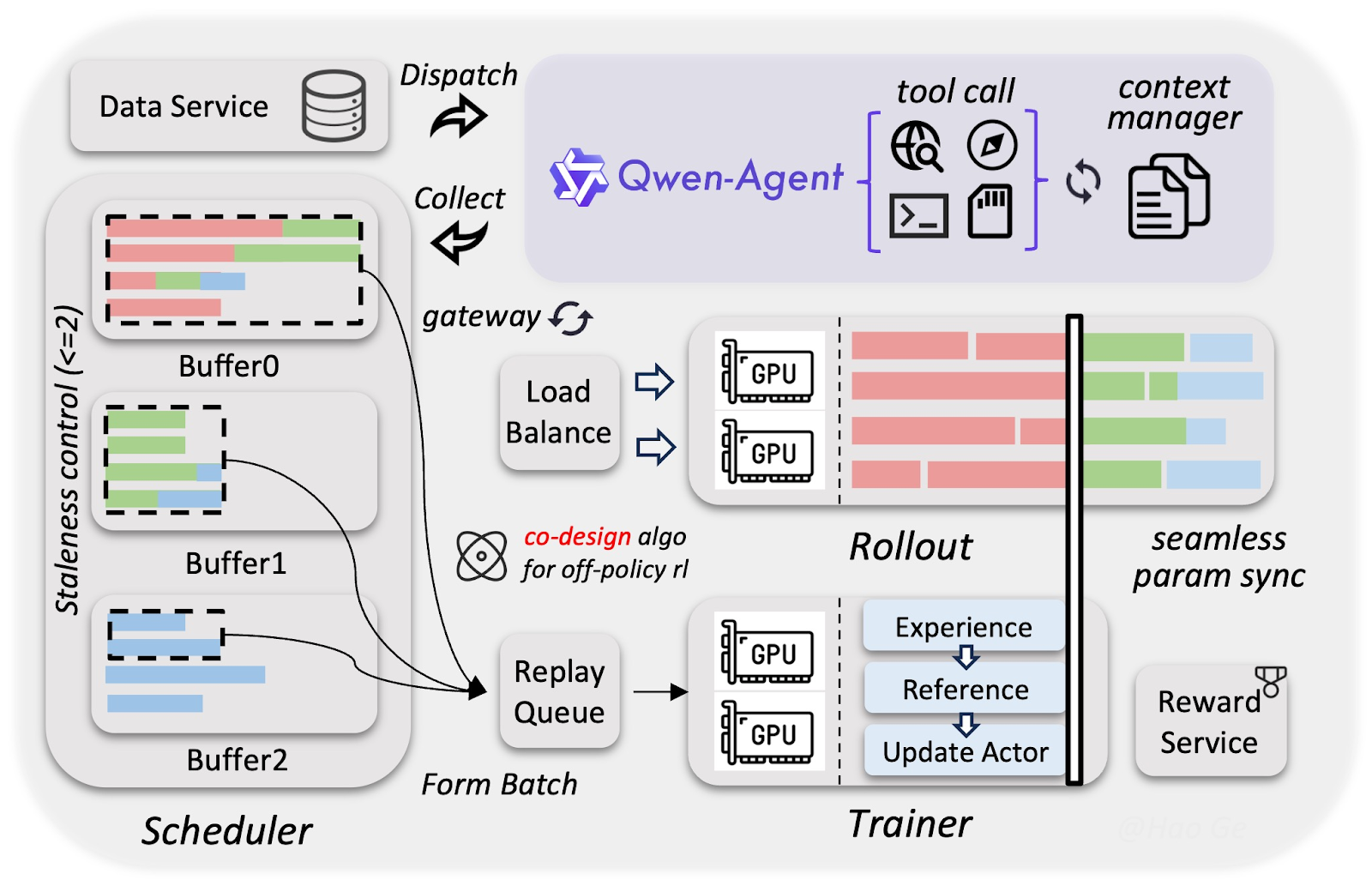
The development process of Qwen3.5 used a custom infrastructure that makes training multimodal and agentic models (almost) as fast and cheap as pure text models. The special approach in training Qwen3.5 comes down to three key components:
The Alibaba team collected way more visual-text data than for the Qwen3 model family, but filtered it very strictly to ensure high-quality inputs. The resulting high-quality dataset lets the 397B parameter model match the smarts of much larger 1T-parameter models, such as Qwen3-Max.
Vision and language parts were trained separately, but simultaneously. Since neither has to wait while the other computes, the resulting overlap delivers almost 100% training throughput compared to pure text models.
Using FP8 compression (essentially storing numbers with half the bits) and speculative decoding (guessing ahead), agents run thousands of tasks simultaneously while training happens in the background without waiting. This accelerated training without significant quality loss, so Qwen3.5 learned complex agent skills, such UI clicking or multi-step tasks, 3-5x faster.
The performance of Alibaba’s new model has already been validated across many tasks. We will focus on results in the focus areas of agentic and multimodal workflows, as well as on more general reasoning skills.
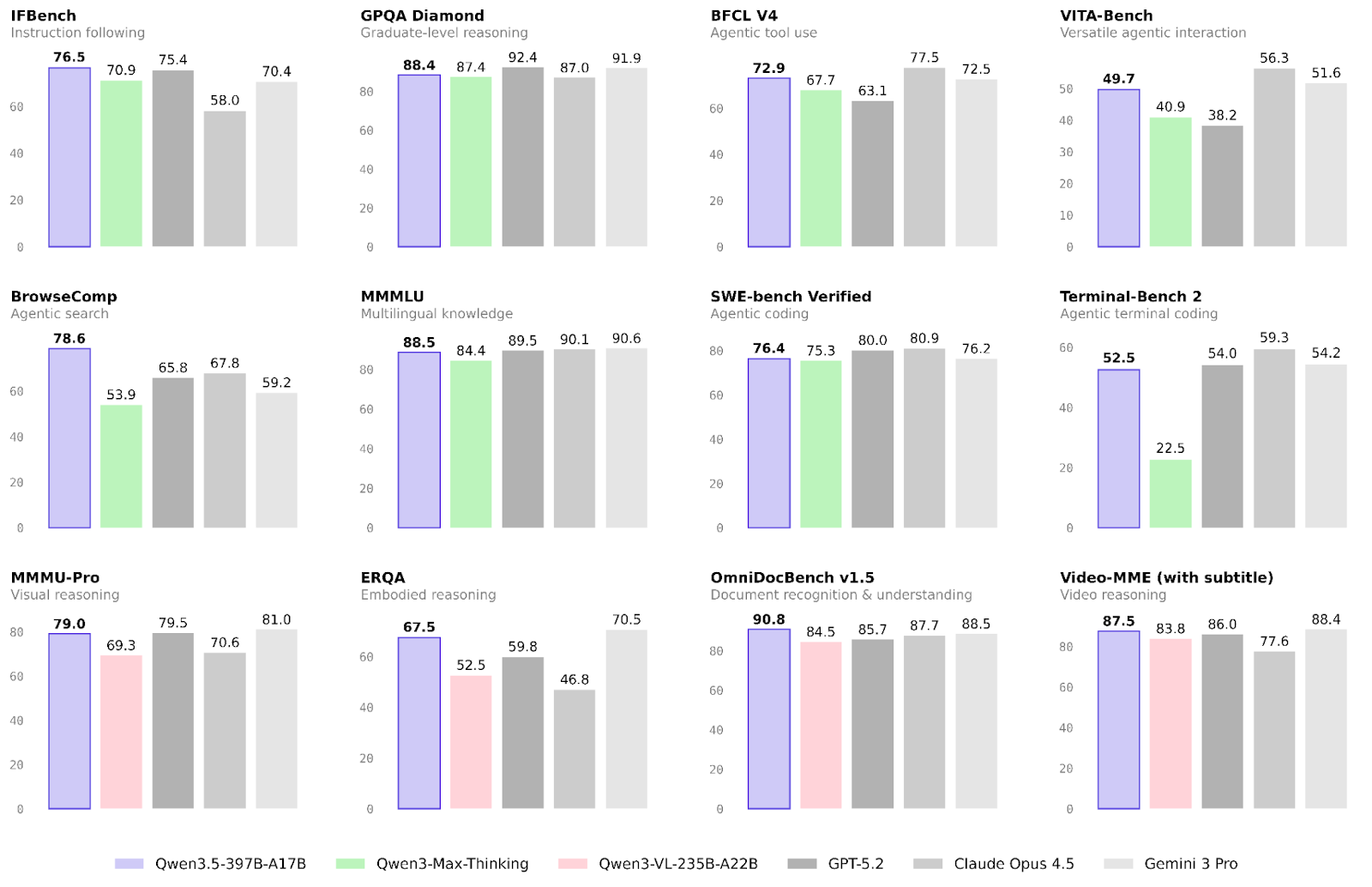
The area in which Qwen3.5 improved the most compared to the Qwen3 family is agentic workflows.
Multimodality is another field that has seen significant improvements over the previous model family. This is especially true for embodied reasoning and document recognition:
Reasoning and knowledge were very clearly not the main focus areas of this release. Still, there are slight improvements in these areas, especially in terms of reliability.
Similar to previous models, the Qwen3.5 models are open source and can be used in multiple different ways: Directly in the chat app, via the API, downloaded for local deployment, or integrated into custom setups.
You can access Qwen3.5 directly at chat.qwen.ai in the familiar chat interface.
The model selection dropdown offers both Qwen3.5-397B-A17B and Qwen3.5-Plus models, as well as a couple of previous models from the Qwen3 model family and Qwen2.5-Max.
Qwen 3.5 API access works the same as Qwen3: OpenAI-compatible endpoints via ModelScope (free tier, daily quotas) or DashScope/Model Studio (paid, includes Qwen3.5-Plus). Update your model ID to qwen3.5-397b-a17b or qwen3.5-plus and you're good to go.
As previously mentioned, the Qwen3.5-397B-A17B model weights were released under the Apache 2.0 license. You can run Qwen3.5 locally using tools such as Ollama, LM Studio, or vLLM.
The weights can be downloaded from:
With new visual agents, enhanced performance, and cost optimization, the release of Qwen3.5 is impressive, putting pressure not only on other Chinese models but also challenging models from OpenAI and Anthropic.
As with other new releases this year, such as GPT-5.3-Codex and Claude Opus 4.6, the focus is certainly shifting towards agentic AI. The rapid success of OpenClaw has proven that people are clamouring for practical uses for AI, and models such as Qwen3.5, Seedance 2.0, and the rumoured upcoming release from DeepSeek show that China is fast becoming the market leader in AI models.
Top AI Courses
Track
Course
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
6 min
blog
Alex Olteanu
8 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Aashi Dutt




