Kursus
Merancang Sistem Agentic dengan LangChain
3 Hr
12.9K
Qwen3.5 adalah seri model Qwen terbaru dari Alibaba dan dibangun di atas performa kuat model Qwen sebelumnya dalam tugas penalaran, pemrograman, dan multimodal.
Evaluasi tolok ukur independen menunjukkan bahwa model Qwen3.5-397B-A17B meraih skor tinggi pada pengujian yang banyak digunakan seperti LiveCodeBench dan AIME26, seringkali melampaui model terdepan seperti GPT-5.2 dan Claude Opus 4.5 pada mayoritas kategori yang dievaluasi, serta menghasilkan throughput yang jauh lebih tinggi dibandingkan generasi Qwen sebelumnya.
Sumber: Qwen/Qwen3.5-397B-A17B · Hugging Face
Dalam tutorial ini, kita akan:
Sebelum menjalankan Qwen3.5 secara lokal, pastikan konfigurasi Anda memenuhi persyaratan perangkat keras dan perangkat lunak untuk inferensi yang lancar. Dalam tutorial ini, kami menggunakan GPU NVIDIA H200 dengan VRAM 141GB, dipasangkan dengan RAM sistem 240GB, yang memberi kami lebih dari cukup memori untuk menjalankan versi MXFP4_MOE dari Qwen3.5 secara efisien dengan offloading MoE.
Sebagai acuan, kuantisasi dinamis 4-bit Unsloth UD-Q4_K_XL menggunakan sekitar 214GB ruang disk. Ini dapat langsung muat pada 256GB M3 Ultra, dan juga berjalan baik pada satu GPU 24GB dengan RAM 256GB, mencapai 25+ token per detik dengan offloading MoE. Kuantisasi 3-bit yang lebih kecil dapat muat dalam RAM 192GB, sementara versi presisi lebih tinggi 8-bit mungkin memerlukan hingga 512GB gabungan RAM dan VRAM.
Secara umum, untuk performa terbaik, gabungan VRAM + RAM sebaiknya kurang lebih menyamai ukuran model terkuantisasi yang Anda unduh. Jika tidak, llama.cpp dapat melakukan offload ke penyimpanan SSD, tetapi inferensi akan lebih lambat.
Di sisi perangkat lunak, Anda harus memasang driver GPU NVIDIA terbaru, bersama dengan CUDA Toolkit yang mutakhir, untuk memastikan kompatibilitas penuh dengan llama.cpp dan inferensi bertenaga CUDA.
Setelah prasyarat siap, mari ikuti panduan langkah demi langkah untuk menggunakan Qwen 3.5 secara lokal:
Untuk menjalankan Qwen3.5 secara lokal, Anda memerlukan akses ke mesin dengan GPU bertenaga. Karena sebagian besar laptop dan PC desktop tidak memiliki VRAM atau memori yang cukup untuk menangani model sebesar ini, kita akan menggunakan mesin virtual GPU di cloud.
Dalam tutorial ini, kami menggunakan Hyperbolic untuk menjalankan model secara privat. Anda juga dapat menggunakan penyedia lain seperti RunPod, Vast.ai, atau platform VM GPU apa pun yang Anda sukai. Kami memilih Hyperbolic karena saat ini menawarkan instance GPU yang paling hemat biaya.
Mulailah dengan meluncurkan instance baru dengan satu GPU H200.
Setelah mesin boot, Anda akan melihat alamat IP publik dan perintah SSH yang diperlukan untuk tersambung dari terminal lokal Anda.
Sebelum terhubung, pastikan SSH telah disiapkan secara lokal dan Anda menambahkan kunci SSH publik saat membuat mesin virtual.
Setelah instance siap, sambungkan menggunakan SSH dengan port forwarding. Ini penting karena kita ingin mengakses server inferensi llama.cpp secara lokal melalui port 8080:
ssh -L 8080:localhost:8080 root@129.212.191.53Saat pertama kali terhubung, ketik yes untuk konfirmasi, lalu autentikasi menggunakan kunci SSH Anda.
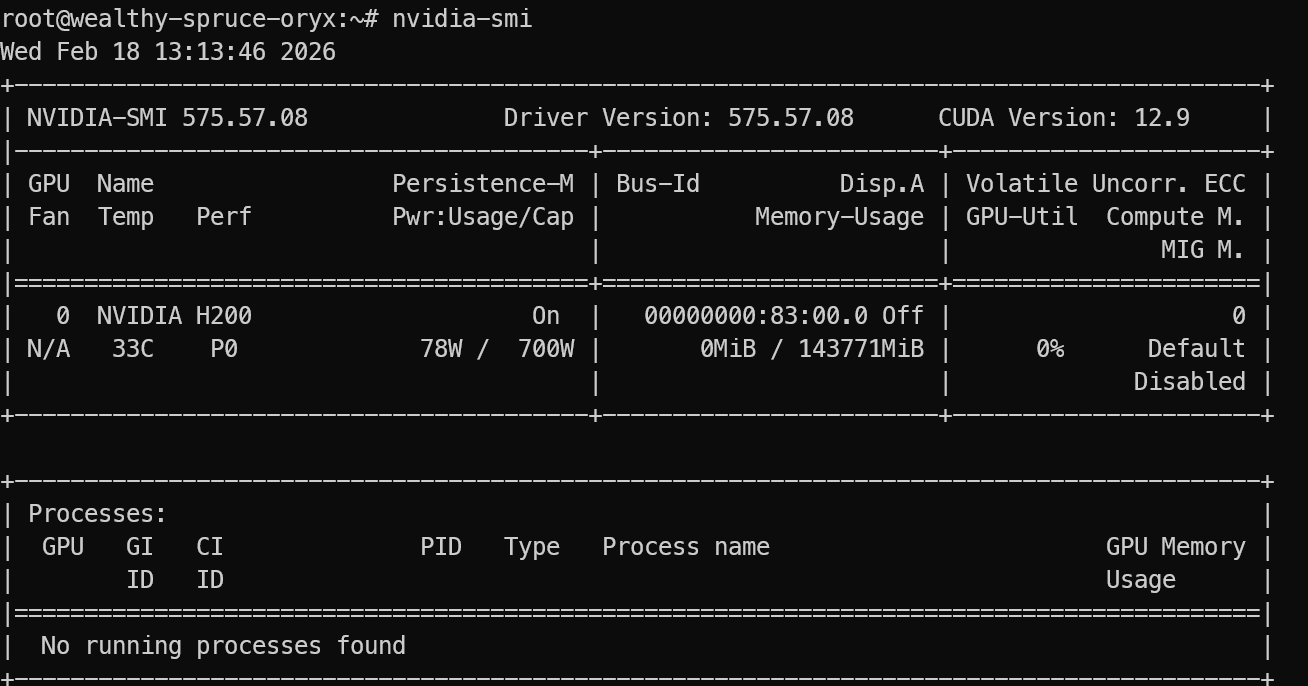
Setelah login, verifikasi bahwa GPU terdeteksi dengan benar:
nvidia-smi Anda seharusnya melihat NVIDIA H200 tercantum pada output.
Terakhir, instal paket Linux yang diperlukan untuk mengunduh, membangun, dan menjalankan llama.cpp:
sudo apt update
sudo apt install pciutils build-essential cmake curl libcurl4-openssl-dev -ySetelah selesai, lingkungan Anda siap untuk menginstal llama.cpp dan menjalankan Qwen3.5 secara lokal.
llama.cpp adalah mesin inferensi open-source berbasis C dan C++ yang memungkinkan Anda menjalankan model bahasa besar secara lokal dengan penyiapan minimal, dan mendukung akselerasi CPU maupun GPU.
Pertama, klon repositori llama.cpp:
git clone https://github.com/ggml-org/llama.cppSelanjutnya, konfigurasikan build berkemampuan CUDA dengan CMake. Kita mengaktifkan CUDA dengan -DGGML_CUDA=ON, dan menetapkan arsitektur CUDA ke 90a karena kita menggunakan NVIDIA H200 (kelas Hopper). Ini membantu build menghasilkan kode GPU yang dioptimalkan untuk fitur Hopper.
cmake llama.cpp -B llama.cpp/build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES="90a"
Sekarang kompilasi biner server. llama-server adalah server REST bawaan yang memungkinkan Anda mengekspos llama.cpp sebagai endpoint API:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-server
Terakhir, salin biner yang telah dikompilasi ke folder utama agar mudah dijalankan:
cp llama.cpp/build/bin/llama-* llama.cppSetelah llama.cpp terpasang, langkah berikutnya adalah mengunduh bobot model Qwen3.5 dalam format GGUF. Berkas-berkas ini besar, jadi menggunakan CLI Hugging Face adalah cara paling andal untuk mengambilnya langsung ke mesin GPU Anda.
Kita memasang Python terlebih dahulu karena alat unduh dan utilitas autentikasi Hugging Face didistribusikan sebagai paket Python. Meskipun llama.cpp sendiri ditulis dalam C++, Python memudahkan pengelolaan unduhan dan transfer model.
Mulailah dengan memasang pip:
sudo apt install python3-pipSelanjutnya, pasang klien Hugging Face Hub beserta penunjang performa. hf_transfer dan hf-xet mempercepat unduhan secara signifikan, yang penting saat mengambil ratusan gigabita berkas model:
pip -q install -U huggingface_hub hf-xet
pip -q install -U hf_transferSekarang unduh model Qwen3.5 dari Hugging Face. Dalam tutorial ini, kita hanya mengambil varian MXFP4_MOE, yang dioptimalkan untuk inferensi MoE yang efisien:
hf download unsloth/Qwen3.5-397B-A17B-GGUF \
--local-dir models/Qwen3.5 \
--include "*MXFP4_MOE*"
Setelah unduhan selesai, berkas model akan disimpan di dalam models/Qwen3.5, siap dimuat ke llama.cpp untuk inferensi lokal.
Sekarang kita dapat menjalankan Qwen3.5 menggunakan llama-server. Ini memberi kita endpoint API yang kompatibel dengan OpenAI yang dapat dipanggil dari alat dan aplikasi lokal.
Kami mengoptimalkan server untuk konfigurasi satu GPU dengan melakukan tiga hal utama. Pertama, kami mengaktifkan --fit on agar llama.cpp otomatis menyeimbangkan model di antara VRAM GPU dan RAM sistem, alih-alih gagal saat model tidak sepenuhnya muat di VRAM.
Kedua, kami menggunakan jendela konteks yang lebih besar dengan --ctx-size 16384 agar server dapat menangani prompt yang lebih panjang. Ketiga, kami mengaktifkan --jinja dan meneruskan --chat-template-kwargs untuk mengontrol format chat dan menonaktifkan mode thinking demi respons yang lebih cepat dan langsung.
Jalankan server dengan:
./llama.cpp/llama-server \
--model models/Qwen3.5/MXFP4_MOE/Qwen3.5-397B-A17B-MXFP4_MOE-00001-of-00006.gguf \
--alias "Qwen3.5" \
--host 0.0.0.0 \
--port 8080 \
--fit on \
--jinja \
--ctx-size 16384 \
--temp 0.7 \
--top-p 0.8 \
--top-k 20 \
--min-p 0.00 \
--chat-template-kwargs "{\"enable_thinking\": false}"Saat model memuat, Anda akan melihat penggunaan VRAM GPU dan memori sistem sekaligus, yang diharapkan untuk model MoE besar.

Setelah pemuatan selesai, server dapat diakses pada:
0.0.0.0:8080 di VMhttp://127.0.0.1:8080 di mesin lokal Anda setelah port forwarding SSH
Biarkan server tetap berjalan. Di PC lokal Anda, buka terminal baru dan sambungkan kembali dengan port forwarding SSH:
ssh -L 8080:localhost:8080 root@129.212.191.53Lalu uji server dengan menampilkan daftar model yang tersedia:
curl -s http://127.0.0.1:8080/v1/modelsJika Anda melihat Qwen3.5 dalam respons, server Anda berjalan dengan benar, dan Anda siap memanggilnya dari OpenAI SDK dan aplikasi lokal Anda.

Sekarang server inferensi Qwen3.5 sudah berjalan, langkah berikutnya adalah memverifikasi bahwa server berfungsi dengan benar dengan aplikasi klien nyata. Salah satu keunggulan terbesar llama.cpp adalah llama-server mengekspos API yang kompatibel dengan OpenAI, yang berarti Anda dapat menggunakan OpenAI SDK resmi tanpa mengubah struktur kode Anda.
Pertama, pasang paket Python OpenAI di mesin lokal Anda (atau di dalam VM jika Anda mau):
pip install openai Sekarang jalankan skrip uji sederhana. Ini terhubung ke endpoint yang diteruskan secara lokal di http://127.0.0.1:8080/v1 alih-alih server cloud OpenAI.
python3 - <<'PY'
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="Qwen3.5",
messages=[
{"role": "user", "content": "Write one sentence about AI agents."}
]
)
print(response.choices[0].message.content)
PYBeberapa detail penting untuk dipahami di sini:
base_url mengarah ke server Qwen3.5 lokal Anda, bukan API OpenAI.api_key tetap diperlukan oleh SDK, tetapi llama.cpp tidak memberlakukan autentikasi, jadi nilai placeholder apa pun dapat digunakan.model="Qwen3.5" sesuai dengan alias yang kita tetapkan saat menjalankan server.Jika semuanya dikonfigurasi dengan benar, Anda akan mendapatkan respons yang cepat dan bersih dari model.
Ini mengonfirmasi bahwa:
Pada tahap ini, Anda dapat mengintegrasikan Qwen3.5 ke alat lokal, alur kerja agen, atau aplikasi apa pun yang sudah mendukung format API OpenAI.
llama.cpp menyertakan WebUI bawaan bergaya ChatGPT yang dapat Anda gunakan untuk mengobrol dengan model langsung di peramban. Ini berguna untuk pengujian cepat, iterasi prompt, dan menghasilkan kode tanpa perlu menulis skrip klien terlebih dahulu.
Karena kita sudah menyiapkan port forwarding SSH, Anda dapat membuka WebUI di mesin lokal, dan ia akan berperilaku seolah-olah server berjalan di laptop Anda.
Secara default, WebUI tersedia di:
http://127.0.0.1:8080Jika laman ini dimuat, itu mengonfirmasi dua hal. Terowongan SSH Anda berfungsi dengan benar, dan server Qwen3.5 dapat dijangkau secara lokal sambil tetap berjalan secara privat pada VM GPU.
Setelah berada di WebUI, tempelkan prompt ini. Tujuannya adalah agar model menghasilkan kode Python dan panduan penggunaan singkat.
Dalam beberapa detik, Qwen3.5 seharusnya menghasilkan berkas app.py dan biasanya penjelasan singkat cara menjalankannya.
Sekarang beralihlah ke terminal lokal Anda (laptop Anda). Pasang dependensi yang dibutuhkan aplikasi yang dihasilkan:
pip install rich yfinanceIni memasang:
rich untuk tata letak TUI, tabel, prompt, dan indikator progresyfinance untuk mengambil metrik saham publik gratisBuat berkas bernama app.py, tempelkan kode yang dihasilkan model, dan jalankan:
python3 app.pySetelah menjalankan skrip, Anda akan melihat TUI diluncurkan dengan benar di terminal. Aplikasi akan meminta Anda memasukkan ticker saham yang ingin dianalisis, beserta mode penyaringan dan tingkat risiko yang Anda pilih.
Sebagai contoh, kami mengujinya dengan tiga saham populer.
Setelah fase pemuatan singkat, alat ini mengembalikan tabel lengkap metrik saham, menyorot hasil berdasarkan aturan penilaian, dan menyimpan semuanya ke berkas results.csv.
Ini adalah contoh bagus bagaimana Qwen3.5 dapat menghasilkan aplikasi yang berfungsi penuh dalam satu kali proses, hanya dengan endpoint model terkuantisasi 4-bit dan sebuah prompt sederhana.
Menjalankan Qwen3.5 secara lokal adalah cara yang kuat untuk mengakses model berskala frontier sambil menjaga semuanya tetap privat dan sepenuhnya di bawah kendali Anda. Dalam tutorial ini, model di-host pada satu VM GPU H200, diakses dengan aman dari mesin lokal menggunakan port forwarding SSH, dan disajikan melalui endpoint llama.cpp yang dioptimalkan dan kompatibel dengan OpenAI.
Meski begitu, ada beberapa keterbatasan praktis yang perlu diingat. Karena semuanya bergantung pada terowongan SSH yang aktif, koneksi harus tetap stabil. Jika internet Anda terputus atau sesi terputus, Anda kehilangan akses ke port lokal dan sering kali perlu menyambung kembali serta memulai ulang sebagian alur kerja.
Masalah umum lainnya adalah membangun llama.cpp dengan benar. Jika Anda tidak menentukan flag arsitektur CUDA yang tepat untuk GPU, kompilasi dapat memakan waktu lebih lama dan mungkin tidak sepenuhnya dioptimalkan untuk perangkat keras. Menetapkan arsitektur yang benar sejak awal memberikan perbedaan nyata pada waktu build dan performa.
Terakhir, meskipun kuantisasi 4-bit MXFP4_MOE sangat baik untuk menjalankan model besar secara efisien, ini tidak selalu ideal untuk alur kerja pengkodean berbasis agen. Dalam pengujian dengan alat seperti Qwen Code CLI, Kilo Code CLI, dan OpenCode, model mengalami kesulitan dengan penalaran lebih dalam dan sering gagal selama loop generasi yang lebih panjang, terkadang bahkan memicu ketidakstabilan GPU.
Kuantisasi presisi lebih tinggi atau model yang lebih kecil berfokus pada penalaran mungkin bekerja lebih baik untuk pengkodean berbasis agen yang andal.
Untuk mempelajari lebih lanjut tentang pengkodean berbasis agen, lihat kursus AI-Assisted Coding for Developers kami. Saya juga merekomendasikan panduan kami tentang menjalankan GLM-5 secara lokal untuk pengkodean berbasis agen.
Kursus Terbaik DataCamp
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
