Cluster Analysis in Python
BasicSkill Level
4 Hr
65K learners

Model klasterisasi bertujuan mengelompokkan data ke dalam “cluster” atau grup yang berbeda. Ini bisa menjadi sudut pandang yang menarik dalam analisis, atau menjadi fitur dalam algoritma pembelajaran terawasi.
Bayangkan situasi sosial di mana ada kelompok orang yang berdiskusi dalam lingkaran berbeda di sekeliling ruangan. Saat pertama kali Anda melihat ruangan, Anda hanya melihat sekumpulan orang. Anda dapat mulai menempatkan titik secara mental di pusat setiap kelompok orang dan menamai titik itu sebagai pengenal unik. Anda kemudian dapat merujuk setiap kelompok dengan nama unik untuk mendeskripsikannya. Inilah pada dasarnya yang dilakukan k-means clustering terhadap data.
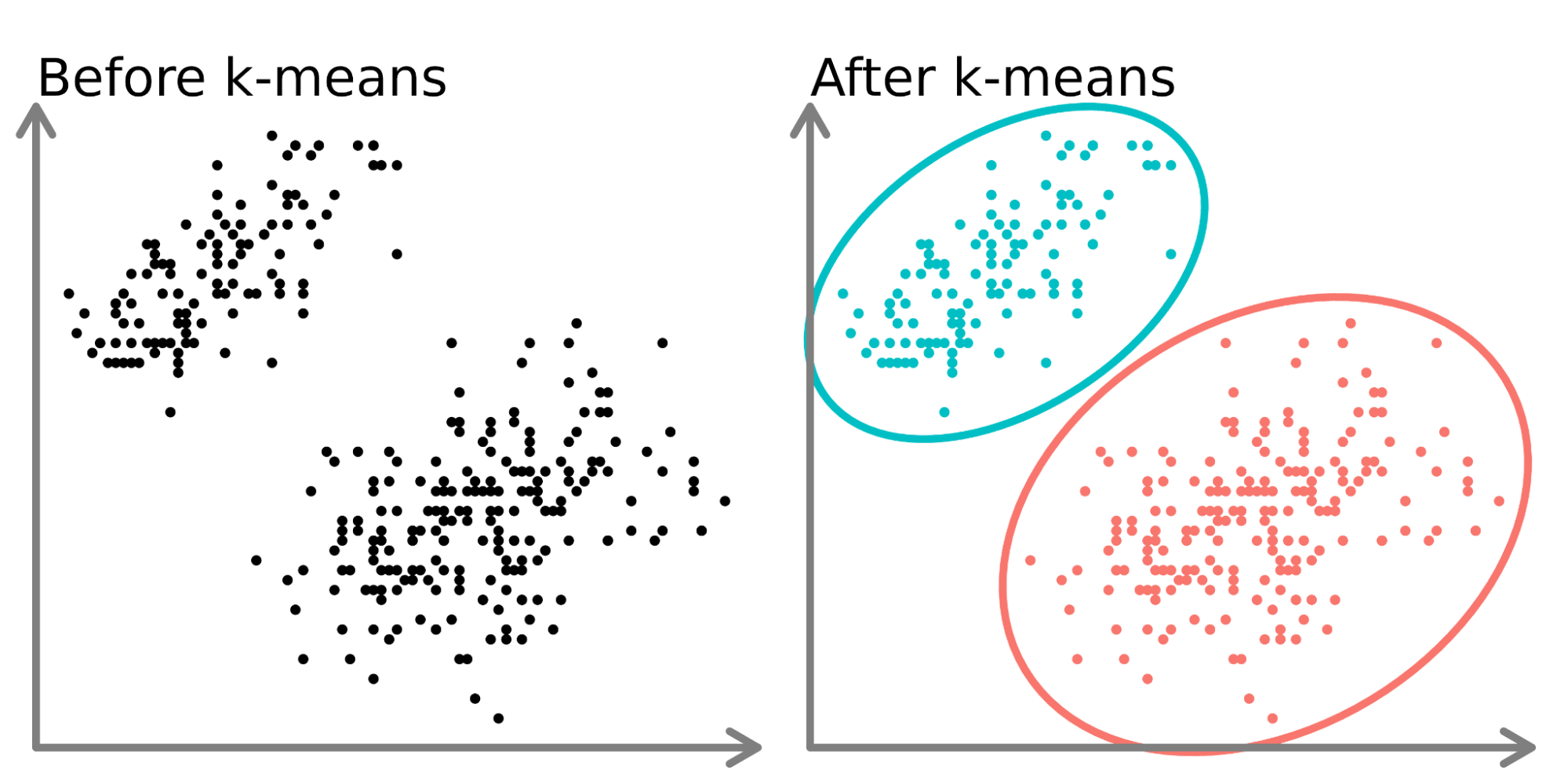
Di sisi kiri diagram di atas, kita dapat melihat dua set titik berbeda yang tidak berlabel dan diwarnai sebagai titik data serupa. Memasang model k-means pada data ini (sisi kanan) dapat mengungkap dua grup berbeda (ditunjukkan dengan lingkaran dan warna berbeda).
Dalam dua dimensi, manusia mudah membagi cluster ini, tetapi dengan lebih banyak dimensi, Anda perlu menggunakan model.
Dalam tutorial ini, kita akan menggunakan data perumahan California dari Kaggle (di sini). Kita akan menggunakan data lokasi (lintang dan bujur) serta nilai median rumah. Kita akan mengklaster rumah berdasarkan lokasi dan mengamati bagaimana harga rumah berfluktuasi di seluruh California. Kita menyimpan dataset sebagai file csv bernama ‘housing.csv’ di direktori kerja kita dan membacanya menggunakan pandas.
import pandas as pd
home_data = pd.read_csv('housing.csv', usecols = ['longitude', 'latitude', 'median_house_value'])
home_data.head()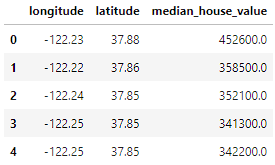
Data mencakup 3 variabel yang telah kita pilih menggunakan parameter usecols:
Seperti algoritma Machine Learning lainnya, k-Means Clustering memiliki alur kerja (lihat Panduan Pemula untuk Alur Kerja Machine Learning untuk penjabaran lebih mendalam tentang alur kerja Machine Learning).
Dalam tutorial ini, kita akan berfokus pada pengumpulan dan pembagian data (dalam persiapan data) serta penyetelan hiperparameter, pelatihan model, dan penilaian kinerja model (dalam pemodelan). Banyak pekerjaan dalam algoritma pembelajaran tanpa pengawasan terletak pada penyetelan hiperparameter dan penilaian kinerja untuk mendapatkan hasil terbaik dari model Anda.
Kita mulai dengan memvisualisasikan data perumahan kita. Kita melihat data lokasi dengan heatmap berdasarkan harga median dalam satu blok. Kita akan menggunakan Seaborn untuk dengan cepat membuat plot dalam tutorial ini (lihat kursus Pengantar Visualisasi Data dengan Seaborn untuk lebih memahami cara grafik ini dibuat).
import seaborn as sns
sns.scatterplot(data = home_data, x = 'longitude', y = 'latitude', hue = 'median_house_value')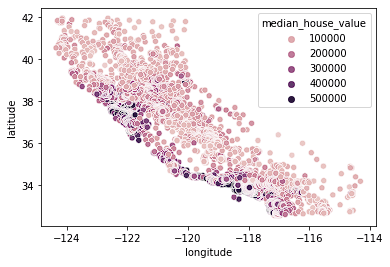
Kita melihat bahwa sebagian besar rumah mahal berada di pantai barat California dengan berbagai area yang memiliki cluster rumah berharga sedang. Ini sesuai ekspektasi karena properti tepi pantai biasanya bernilai lebih tinggi dibandingkan rumah yang tidak berada di pesisir.
Cluster sering kali mudah dikenali saat Anda hanya menggunakan 2 atau 3 fitur. Ini menjadi semakin sulit atau bahkan tidak mungkin ketika
Saat bekerja dengan algoritma berbasis jarak, seperti k-Means Clustering, kita harus menormalisasi data. Jika kita tidak menormalisasi data, variabel dengan skala berbeda akan diberi bobot berbeda dalam rumus jarak yang dioptimalkan selama pelatihan. Misalnya, jika kita menyertakan harga dalam klaster selain lintang dan bujur, harga akan memiliki dampak berlebihan pada optimasi karena skalanya jauh lebih besar dan lebih lebar dibandingkan variabel lokasi yang dibatasi.
Pertama, kita menyiapkan pembagian data pelatihan dan pengujian menggunakan train_test_split dari sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(home_data[['latitude', 'longitude']], home_data[['median_house_value']], test_size=0.33, random_state=0)Selanjutnya, kita menormalisasi data pelatihan dan pengujian menggunakan metode preprocessing.normalize() dari sklearn.
from sklearn import preprocessing
X_train_norm = preprocessing.normalize(X_train)
X_test_norm = preprocessing.normalize(X_test)Untuk iterasi pertama, kita akan secara arbitrer memilih jumlah cluster (disebut k) sebanyak 3. Membangun dan memasang model di sklearn sangat sederhana. Kita akan membuat instance KMeans, menentukan jumlah cluster menggunakan atribut n_clusters, mengatur n_init yang menentukan jumlah iterasi algoritme akan berjalan dengan benih centroid berbeda ke “auto,” dan kita akan mengatur random_state ke 0 agar mendapatkan hasil yang sama setiap kali kode dijalankan. Kita kemudian dapat memasang model ke data pelatihan yang telah dinormalisasi menggunakan metode fit().
from sklearn import KMeans
kmeans = KMeans(n_clusters = 3, random_state = 0, n_init='auto')
kmeans.fit(X_train_norm)Setelah data dipasang, kita dapat mengakses label dari atribut labels_. Di bawah ini, kita memvisualisasikan data yang baru saja kita pasang.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = kmeans.labels_)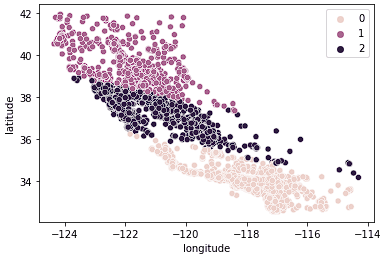
Kita melihat bahwa data kini jelas terbagi menjadi 3 grup berbeda (California Utara, California Tengah, dan California Selatan). Kita juga dapat melihat distribusi harga rumah median di 3 grup ini menggunakan boxplot.
sns.boxplot(x = kmeans.labels_, y = y_train['median_house_value'])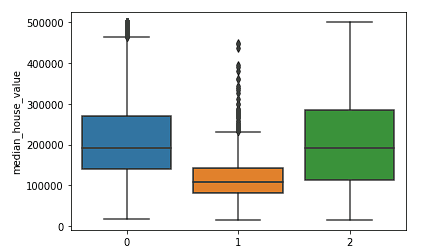
Kita jelas melihat bahwa cluster Utara dan Selatan memiliki distribusi nilai median rumah (cluster 0 dan 2) yang serupa dan lebih tinggi daripada harga di cluster tengah (cluster 1).
Kita dapat mengevaluasi kinerja algoritma klasterisasi menggunakan skor Silhouette yang merupakan bagian dari sklearn.metrics di mana skor yang lebih rendah merepresentasikan kecocokan yang lebih baik.
from sklearn.metrics import silhouette_score
silhouette_score(X_train_norm, kmeans.labels_, metric='euclidean')Karena kita belum melihat kekuatan berbagai jumlah cluster, kita tidak tahu seberapa baik kecocokan model k = 3. Pada bagian berikutnya, kita akan mengeksplorasi jumlah cluster berbeda dan membandingkan kinerjanya untuk memutuskan nilai hiperparameter terbaik bagi model kita.
Kelemahan klasterisasi k-means adalah kita tidak tahu berapa banyak cluster yang dibutuhkan hanya dengan menjalankan model. Kita perlu menguji rentang nilai dan memutuskan nilai k terbaik. Biasanya, kita membuat keputusan menggunakan metode Elbow untuk menentukan jumlah cluster optimal di mana kita tidak melakukan overfitting dengan terlalu banyak cluster, dan juga tidak underfitting dengan terlalu sedikit cluster.
Kita membuat loop di bawah ini untuk menguji dan menyimpan hasil model yang berbeda sehingga kita dapat memutuskan jumlah cluster terbaik.
K = range(2, 8)
fits = []
score = []
for k in K:
# train the model for current value of k on training data
model = KMeans(n_clusters = k, random_state = 0, n_init='auto').fit(X_train_norm)
# append the model to fits
fits.append(model)
# Append the silhouette score to scores
score.append(silhouette_score(X_train_norm, model.labels_, metric='euclidean'))Kemudian kita dapat terlebih dahulu melihat secara visual beberapa nilai k yang berbeda.
Pertama kita lihat k = 2.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[0].labels_)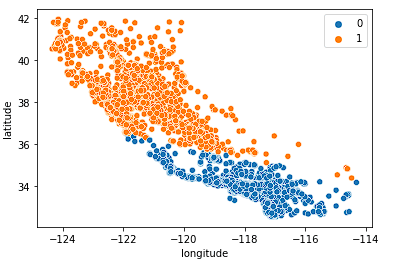
Model cukup baik membagi negara bagian menjadi dua bagian, tetapi kemungkinan belum menangkap cukup nuansa dalam pasar perumahan California.
Selanjutnya, kita lihat k = 4.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)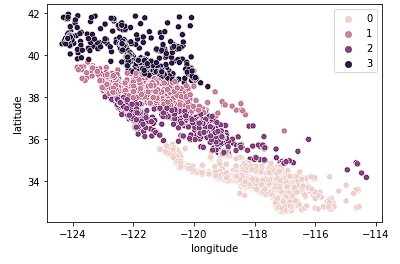
Kita melihat plot ini mengelompokkan California menjadi cluster yang lebih logis di seluruh negara bagian berdasarkan seberapa jauh ke Utara atau Selatan rumah-rumah tersebut. Model ini kemungkinan besar menangkap lebih banyak nuansa pasar perumahan saat kita bergerak melintasi negara bagian.
Terakhir, kita lihat k = 7.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)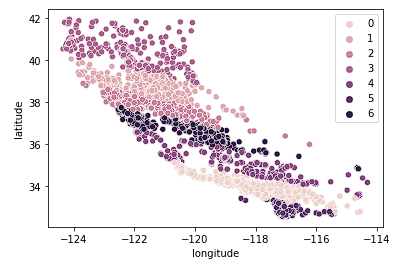
Grafik di atas tampak memiliki terlalu banyak cluster. Kita telah mengorbankan kemudahan interpretasi cluster demi hasil geo-klasterisasi yang “lebih akurat”.
Biasanya, saat kita meningkatkan nilai K, kita melihat peningkatan pada cluster dan representasinya hingga titik tertentu. Lalu kita mulai melihat hasil yang menurun atau bahkan kinerja yang lebih buruk. Kita dapat melihat ini secara visual untuk membantu memutuskan nilai k dengan menggunakan plot siku (elbow plot) di mana sumbu y adalah ukuran goodness of fit dan sumbu x adalah nilai k.
sns.lineplot(x = K, y = score)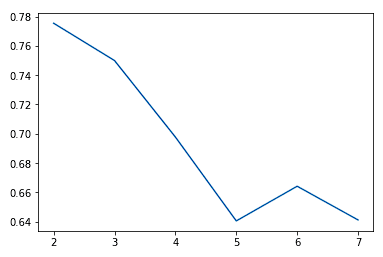
Kita biasanya memilih titik ketika peningkatan kinerja mulai mendatar atau memburuk. Kita melihat k = 5 mungkin merupakan hasil terbaik yang bisa kita dapatkan tanpa overfitting.
Kita juga dapat melihat bahwa cluster cukup baik membagi California menjadi cluster berbeda dan cluster tersebut cukup selaras dengan rentang harga yang berbeda seperti terlihat di bawah.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[3].labels_)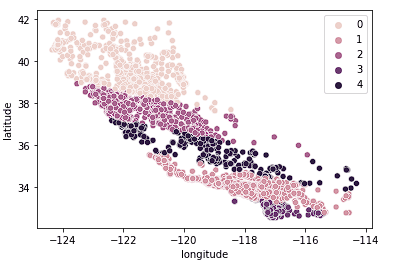
sns.boxplot(x = fits[3].labels_, y = y_train['median_house_value'])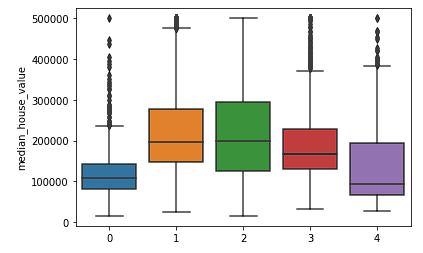
Klasterisasi k-means berkinerja terbaik pada data yang berbentuk bola. Data berbentuk bola adalah data yang mengelompok dalam ruang pada jarak yang berdekatan satu sama lain. Ini dapat divisualisasikan lebih mudah dalam ruang 2 atau 3 dimensi. Data yang tidak berbentuk bola atau memang tidak seharusnya berbentuk bola tidak bekerja dengan baik dengan klasterisasi k-means. Misalnya, klasterisasi k-means tidak akan bekerja dengan baik pada data di bawah ini karena kita tidak akan dapat menemukan centroid yang berbeda untuk mengklaster dua lingkaran atau busur secara berbeda, meskipun secara visual jelas ada dua lingkaran dan busur berbeda yang seharusnya diberi label demikian.
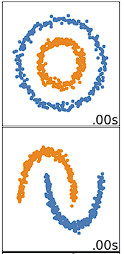
Ada banyak algoritma klasterisasi lain yang bagus untuk mengklaster data yang tidak berbentuk bola, dibahas dalam Clustering dalam Machine Learning: 5 Algoritma Klasterisasi Esensial.
Keputusan untuk membagi data bergantung pada tujuan Anda melakukan klasterisasi. Jika tujuannya adalah mengklaster data sebagai akhir dari analisis Anda, maka tidak perlu. Jika Anda menggunakan cluster sebagai fitur dalam model pembelajaran terawasi atau untuk prediksi (seperti yang kita lakukan dalam tutorial Tutorial Scikit-Learn: Analitik Baseball Bagian 1), maka Anda perlu membagi data sebelum klasterisasi untuk memastikan Anda mengikuti praktik terbaik alur kerja pembelajaran terawasi.
Sekarang kita telah membahas dasar-dasar klasterisasi k-means di Python, Anda dapat melihat kursus Unsupervised Learning in Python untuk pengantar yang baik tentang k-means dan algoritma pembelajaran tanpa pengawasan lainnya. Kursus kami yang lebih lanjut, Cluster Analysis in Python, memberikan tinjauan lebih mendalam tentang algoritma klasterisasi dan cara membangun serta menyetelnya di Python. Terakhir, Anda juga dapat melihat tutorial Pengantar Klasterisasi Hierarkis di Python sebagai pendekatan yang menggunakan algoritma alternatif untuk membuat hierarki dari data.
Pelajari lebih lanjut tentang Machine Learning
Kursus
Kursus
Kursus