Cluster Analysis in Python
BasicSkill Level
4 h
64.9K learners

I modelli di clustering mirano a raggruppare i dati in “cluster” o gruppi distinti. Questo può offrire una vista interessante in fase di analisi, oppure può diventare una feature in un algoritmo di apprendimento supervisionato.
Immagina un contesto sociale con gruppi di persone che chiacchierano in diversi cerchi in una stanza. A un primo sguardo vedi solo un insieme di persone. Potresti iniziare mentalmente a piazzare dei punti al centro di ogni gruppo e assegnare a ciascun punto un identificatore univoco. A quel punto potresti riferirti a ogni gruppo con un nome distinto per descriverlo. In sostanza, è ciò che fa k-means con i dati.
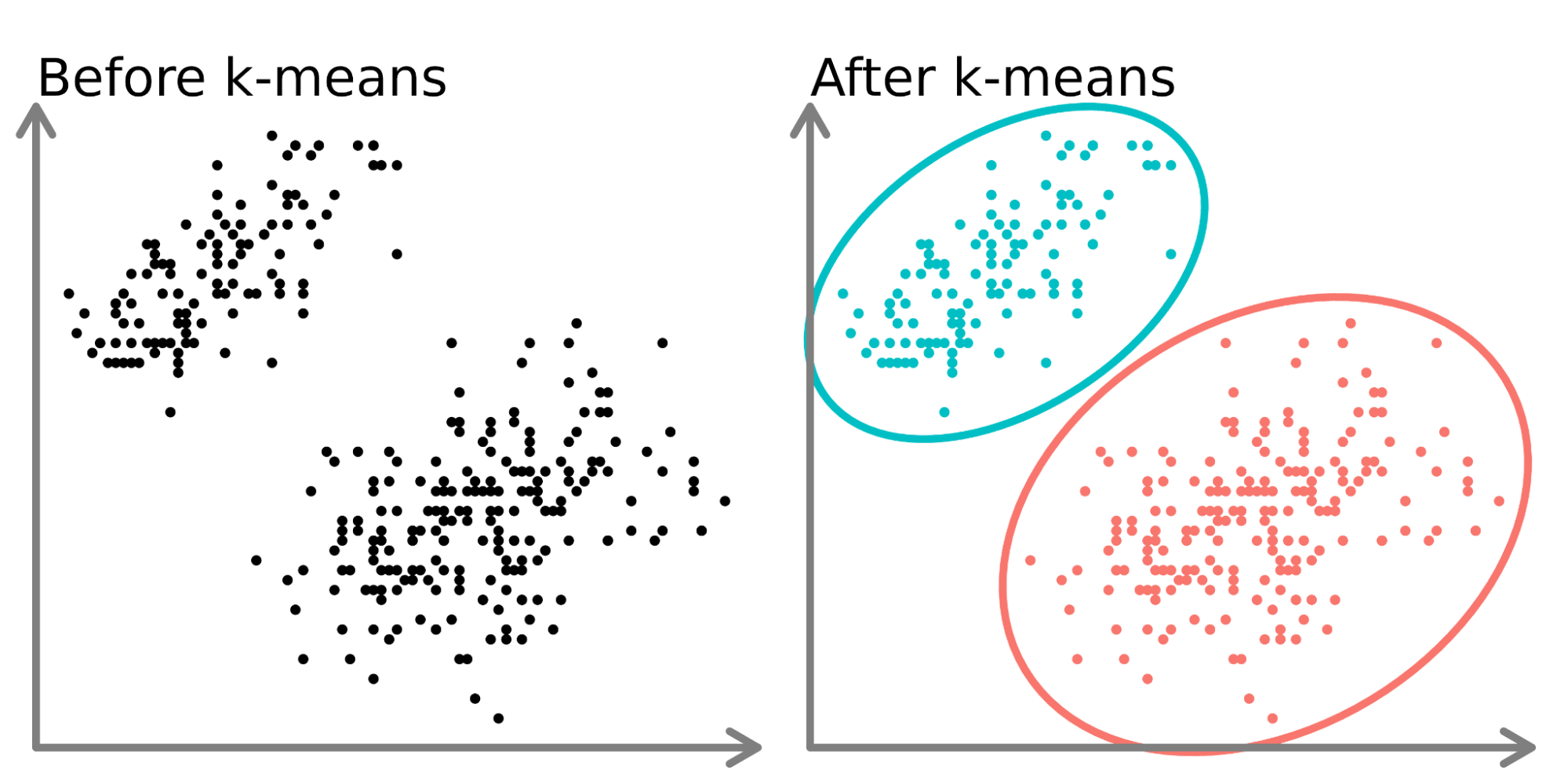
Nella parte sinistra del diagramma sopra, vediamo due insiemi distinti di punti non etichettati e colorati come punti dati simili. Addestrare un modello k-means su questi dati (parte destra) può rivelare 2 gruppi distinti (rappresentati sia da cerchi distinti sia da colori).
In due dimensioni, per gli esseri umani è facile separare questi cluster, ma con più dimensioni è necessario usare un modello.
In questo tutorial useremo dati immobiliari della California da Kaggle (qui). Useremo i dati di posizione (latitudine e longitudine) e il valore mediano delle case. Clusterizzeremo le case per posizione e osserveremo come i prezzi delle case variano in tutta la California. Salviamo il dataset come file csv chiamato ‘housing.csv’ nella nostra directory di lavoro e lo leggiamo con pandas.
import pandas as pd
home_data = pd.read_csv('housing.csv', usecols = ['longitude', 'latitude', 'median_house_value'])
home_data.head()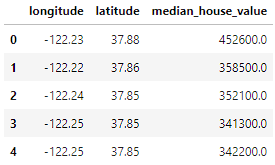
I dati includono 3 variabili che abbiamo selezionato usando il parametro usecols:
Come altri algoritmi di Machine Learning, il clustering k-means segue un workflow (consulta A Beginner's Guide to The Machine Learning Workflow per un'analisi più approfondita del workflow di Machine Learning).
In questo tutorial ci concentreremo sulla raccolta e lo split dei dati (nella preparazione dei dati) e sul tuning degli iperparametri, l'addestramento del modello e la valutazione delle prestazioni (nella fase di modellazione). Gran parte del lavoro negli algoritmi di apprendimento non supervisionato riguarda il tuning degli iperparametri e la valutazione delle performance per ottenere il meglio dal modello.
Iniziamo visualizzando i nostri dati immobiliari. Esaminiamo i dati di posizione con una mappa di dispersione colorata in base al prezzo mediano in un isolato. In questo tutorial useremo Seaborn per creare rapidamente i grafici (vedi il nostro corso Introduction to Data Visualization with Seaborn per capire meglio come vengono creati questi grafici).
import seaborn as sns
sns.scatterplot(data = home_data, x = 'longitude', y = 'latitude', hue = 'median_house_value')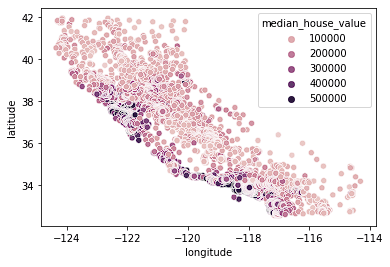
Vediamo che la maggior parte delle case costose si trova sulla costa ovest della California, con diverse aree che presentano cluster di case a prezzo medio. È prevedibile: in genere le proprietà sul lungomare valgono più delle case lontane dalla costa.
I cluster spesso sono facili da individuare quando usi solo 2 o 3 feature. Diventa sempre più difficile o impossibile quando il
Quando si lavora con algoritmi basati sulla distanza, come il clustering k-means, è necessario normalizzare i dati. Se non normalizziamo, variabili con scale diverse verranno pesate diversamente nella formula di distanza ottimizzata durante il training. Per esempio, se includessimo il prezzo nel cluster oltre a latitudine e longitudine, il prezzo avrebbe un impatto eccessivo sulle ottimizzazioni perché la sua scala è significativamente più ampia rispetto alle variabili di posizione che sono limitate.
Per prima cosa creiamo training e test split usando train_test_split da sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(home_data[['latitude', 'longitude']], home_data[['median_house_value']], test_size=0.33, random_state=0)Poi normalizziamo i dati di training e test usando il metodo preprocessing.normalize() di sklearn.
from sklearn import preprocessing
X_train_norm = preprocessing.normalize(X_train)
X_test_norm = preprocessing.normalize(X_test)Per la prima iterazione, scegliamo arbitrariamente un numero di cluster (indicato con k) pari a 3. Creare e addestrare modelli in sklearn è molto semplice. Creeremo un'istanza di KMeans, definiremo il numero di cluster con l'attributo n_clusters, imposteremo n_init (il numero di esecuzioni dell'algoritmo con seed dei centroidi diversi) su “auto” e imposteremo random_state a 0 per ottenere lo stesso risultato a ogni esecuzione. Possiamo quindi adattare il modello ai dati di training normalizzati con il metodo fit().
from sklearn import KMeans
kmeans = KMeans(n_clusters = 3, random_state = 0, n_init='auto')
kmeans.fit(X_train_norm)Una volta adattati i dati, possiamo accedere alle etichette dall'attributo labels_. Qui sotto visualizziamo i dati appena adattati.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = kmeans.labels_)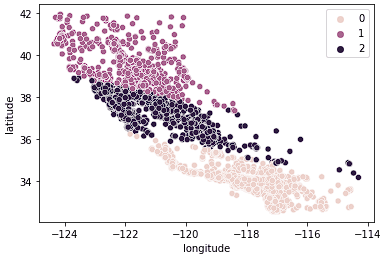
Vediamo che i dati sono ora nettamente suddivisi in 3 gruppi distinti (California del Nord, Centrale e del Sud). Possiamo anche osservare la distribuzione dei prezzi mediani in questi 3 gruppi con un boxplot.
sns.boxplot(x = kmeans.labels_, y = y_train['median_house_value'])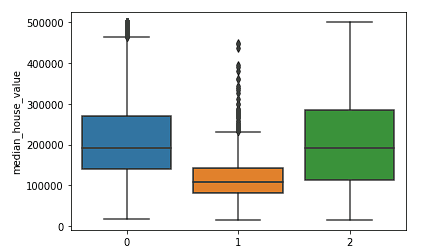
Si vede chiaramente che i cluster del Nord e del Sud hanno distribuzioni simili dei valori mediani delle case (cluster 0 e 2) che sono più alte rispetto ai prezzi del cluster centrale (cluster 1).
Possiamo valutare le prestazioni dell'algoritmo di clustering usando lo silhouette score, parte di sklearn.metrics, dove un punteggio più basso rappresenta un fit migliore.
from sklearn.metrics import silhouette_score
silhouette_score(X_train_norm, kmeans.labels_, metric='euclidean')Dato che non abbiamo ancora confrontato la bontà di diversi numeri di cluster, non sappiamo quanto sia valido il modello con k = 3. Nella sezione successiva esploreremo diversi cluster e confronteremo le performance per decidere i valori migliori degli iperparametri del nostro modello.
La debolezza del clustering k-means è che non sappiamo quanti cluster servano semplicemente eseguendo il modello. Dobbiamo testare intervalli di valori e scegliere il valore migliore di k. In genere si usa il metodo del gomito (Elbow) per determinare il numero ottimale di cluster, in modo da non sovra-adattare i dati con troppi cluster né sotto-adattarli con troppo pochi.
Creiamo il ciclo qui sotto per testare e memorizzare diversi risultati del modello, così da poter decidere il numero migliore di cluster.
K = range(2, 8)
fits = []
score = []
for k in K:
# train the model for current value of k on training data
model = KMeans(n_clusters = k, random_state = 0, n_init='auto').fit(X_train_norm)
# append the model to fits
fits.append(model)
# Append the silhouette score to scores
score.append(silhouette_score(X_train_norm, model.labels_, metric='euclidean'))Possiamo quindi osservare visivamente alcuni valori diversi di k.
Per prima cosa guardiamo k = 2.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[0].labels_)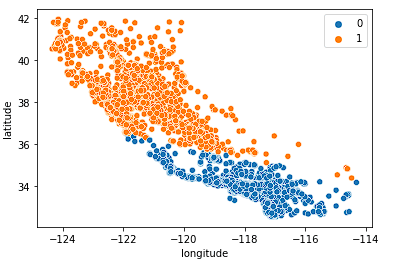
Il modello fa un lavoro discreto nel dividere lo stato in due metà, ma probabilmente non coglie abbastanza sfumature del mercato immobiliare californiano.
Poi guardiamo k = 4.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)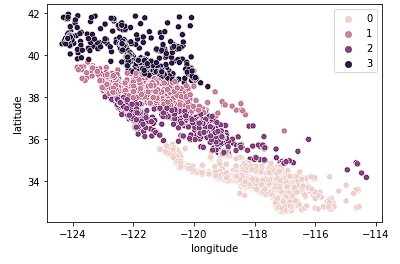
Vediamo che questo grafico raggruppa la California in cluster più logici in base a quanto a nord o a sud si trovano le case nello stato. Questo modello probabilmente cattura più sfumature del mercato man mano che ci si sposta.
Infine, guardiamo k = 7.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)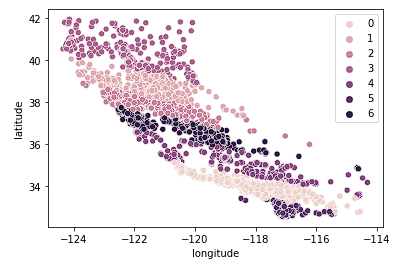
Il grafico sopra sembra avere troppi cluster. Abbiamo sacrificato la facilità d'interpretazione dei cluster per un risultato di geo-clustering apparentemente “più accurato”.
Di solito, aumentando K vediamo miglioramenti nei cluster e in ciò che rappresentano fino a un certo punto. Poi iniziamo ad avere rendimenti decrescenti o prestazioni peggiori. Possiamo visualizzarlo per aiutare la decisione sul valore di k con un elbow plot dove l'asse y è una misura della bontà di adattamento e l'asse x è il valore di k.
sns.lineplot(x = K, y = score)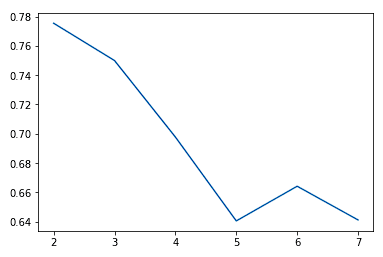
In genere scegliamo il punto in cui i miglioramenti nelle performance iniziano ad appiattirsi o a peggiorare. Vediamo che k = 5 è probabilmente il meglio che possiamo ottenere senza overfitting.
Possiamo anche vedere che i cluster suddividono abbastanza bene la California in gruppi distinti e che questi cluster si mappano in modo coerente a diverse fasce di prezzo, come si vede sotto.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[3].labels_)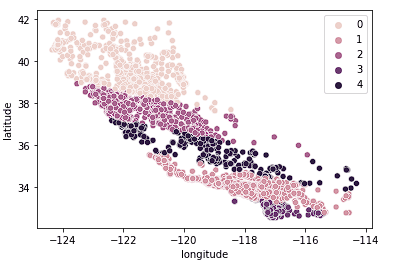
sns.boxplot(x = fits[3].labels_, y = y_train['median_house_value'])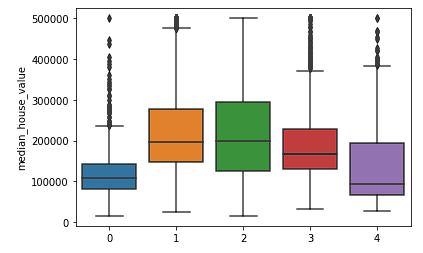
Il clustering k-means dà il meglio con dati sferici. Per dati sferici intendiamo dati che si raggruppano nello spazio in stretta prossimità tra loro. Questo è più facile da visualizzare in 2 o 3 dimensioni. Dati che non sono sferici, o non dovrebbero esserlo, non funzionano bene con k-means. Per esempio, k-means non funzionerebbe bene sui dati qui sotto: non riusciremmo a trovare centroidi distinti per clusterizzare in modo diverso i due cerchi o archi, nonostante siano chiaramente due forme distinte che andrebbero etichettate come tali.
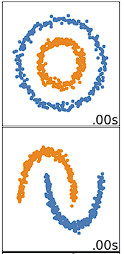
Esistono molti altri algoritmi di clustering che funzionano bene con dati non sferici, trattati in Clustering in Machine Learning: 5 Essential Clustering Algorithms.
La decisione di dividere i dati dipende dagli obiettivi del clustering. Se l'obiettivo è clusterizzare i dati come punto finale dell'analisi, non è necessario. Se invece userai i cluster come feature in un modello supervisionato o per la previsione (come facciamo nel tutorial Scikit-Learn Tutorial: Baseball Analytics Pt 1), allora dovrai dividere i dati prima del clustering per assicurarti di seguire le best practice del workflow di apprendimento supervisionato.
Ora che abbiamo coperto le basi del clustering k-means in Python, puoi dare un'occhiata al corso Unsupervised Learning in Python per una buona introduzione a k-means e ad altri algoritmi non supervisionati. Il nostro corso più avanzato, Cluster Analysis in Python, offre una panoramica più approfondita degli algoritmi di clustering e di come costruirli e affinarli in Python. Infine, puoi anche consultare il tutorial An Introduction to Hierarchical Clustering in Python per un approccio alternativo che crea gerarchie dai dati.
Approfondisci il Machine Learning
Corso
Corso
Corso