Cluster Analysis in Python
BasicSkill Level
4 giờ
65K learners

Các mô hình phân cụm nhằm mục tiêu gom dữ liệu thành các “cụm” hay nhóm riêng biệt. Điều này vừa có thể mang lại một góc nhìn thú vị trong phân tích, vừa có thể trở thành một đặc trưng trong thuật toán học có giám sát.
Hãy hình dung một bối cảnh xã hội nơi có các nhóm người đang trò chuyện theo những vòng tròn khác nhau trong một căn phòng. Lúc đầu nhìn vào, bạn chỉ thấy một đám người. Bạn có thể mentally đặt các điểm ở trung tâm mỗi nhóm và đặt tên điểm đó như một định danh duy nhất. Từ đó, bạn có thể gọi mỗi nhóm bằng một tên riêng để mô tả họ. Về bản chất, đó là điều k-means làm với dữ liệu.
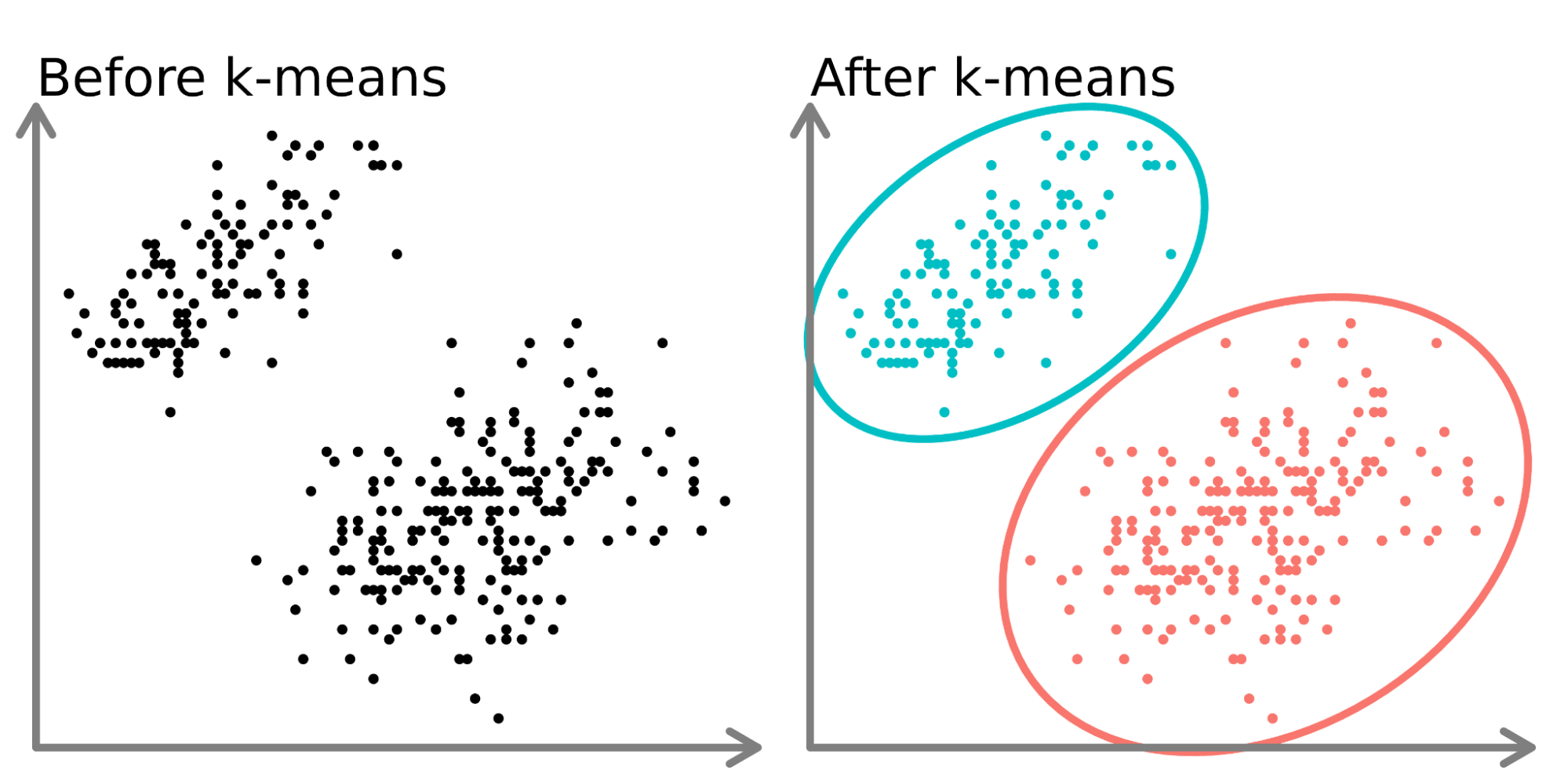
Ở phía bên trái của sơ đồ trên, ta thấy 2 tập điểm riêng biệt không có nhãn và được tô màu như các điểm dữ liệu tương tự nhau. Khớp một mô hình k-means với dữ liệu này (bên phải) có thể làm lộ ra 2 nhóm riêng (thể hiện bằng cả vòng tròn và màu sắc khác nhau).
Trong không gian hai chiều, con người dễ dàng tách các cụm này, nhưng với nhiều chiều hơn, bạn cần dùng mô hình.
Trong hướng dẫn này, chúng ta sẽ sử dụng dữ liệu nhà ở California từ Kaggle (tại đây). Chúng ta sẽ dùng dữ liệu vị trí (vĩ độ và kinh độ) cũng như giá trị trung vị của nhà. Chúng ta sẽ phân cụm các ngôi nhà theo vị trí và quan sát cách giá nhà dao động trên khắp California. Chúng ta lưu bộ dữ liệu dưới dạng tệp csv có tên ‘housing.csv’ trong thư mục làm việc và đọc bằng pandas.
import pandas as pd
home_data = pd.read_csv('housing.csv', usecols = ['longitude', 'latitude', 'median_house_value'])
home_data.head()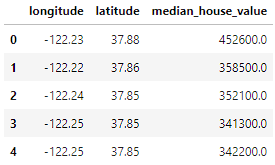
Dữ liệu gồm 3 biến mà chúng ta đã chọn bằng tham số usecols:
Giống như các thuật toán Học máy khác, k-means có một quy trình làm việc (xem Hướng dẫn cho người mới bắt đầu về quy trình làm việc của Machine Learning để hiểu sâu hơn).
Trong hướng dẫn này, chúng ta sẽ tập trung vào việc thu thập và chia tách dữ liệu (trong giai đoạn chuẩn bị dữ liệu) và tinh chỉnh siêu tham số, huấn luyện mô hình, cũng như đánh giá hiệu năng mô hình (trong giai đoạn mô hình hóa). Phần lớn công việc trong các thuật toán học không giám sát nằm ở tinh chỉnh siêu tham số và đánh giá hiệu năng để đạt kết quả tốt nhất.
Chúng ta bắt đầu bằng cách trực quan hóa dữ liệu nhà ở. Chúng ta quan sát dữ liệu vị trí bằng bản đồ nhiệt dựa trên giá trung vị trong một block. Trong hướng dẫn này, chúng ta sẽ dùng Seaborn để nhanh chóng tạo biểu đồ (xem khóa học Giới thiệu trực quan hóa dữ liệu với Seaborn để hiểu rõ cách tạo các biểu đồ này).
import seaborn as sns
sns.scatterplot(data = home_data, x = 'longitude', y = 'latitude', hue = 'median_house_value')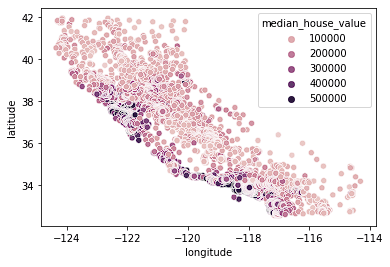
Ta thấy hầu hết các căn nhà đắt tiền nằm ở bờ tây California với những khu vực có các cụm nhà giá trung bình. Điều này hợp lý vì thường bất động sản ven biển có giá trị cao hơn nhà không nằm sát bờ biển.
Các cụm thường dễ nhận ra khi bạn chỉ dùng 2 hoặc 3 đặc trưng. Điều này trở nên khó, thậm chí không thể, khi
Khi làm việc với các thuật toán dựa trên khoảng cách, như k-means, chúng ta phải chuẩn hóa dữ liệu. Nếu không chuẩn hóa, các biến có thang đo khác nhau sẽ được gán trọng số khác nhau trong công thức khoảng cách được tối ưu trong quá trình huấn luyện. Ví dụ, nếu ta đưa cả giá vào cụm cùng với vĩ độ và kinh độ, giá sẽ tác động quá mức đến tối ưu hóa vì thang đo của nó lớn và rộng hơn đáng kể so với các biến vị trí có giới hạn.
Trước tiên, chúng ta thiết lập tập huấn luyện và kiểm tra bằng train_test_split từ sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(home_data[['latitude', 'longitude']], home_data[['median_house_value']], test_size=0.33, random_state=0)Tiếp theo, chúng ta chuẩn hóa dữ liệu huấn luyện và kiểm tra bằng phương thức preprocessing.normalize() của sklearn.
from sklearn import preprocessing
X_train_norm = preprocessing.normalize(X_train)
X_test_norm = preprocessing.normalize(X_test)Ở lần thử đầu, chúng ta sẽ tùy ý chọn số cụm (k) là 3. Việc xây dựng và khớp mô hình trong sklearn rất đơn giản. Chúng ta sẽ tạo một thể hiện của KMeans, xác định số cụm bằng thuộc tính n_clusters, đặt n_init (số lần thuật toán chạy với các khởi tạo tâm cụm khác nhau) là “auto”, và đặt random_state là 0 để mỗi lần chạy cho cùng một kết quả. Sau đó ta có thể khớp mô hình với dữ liệu huấn luyện đã chuẩn hóa bằng phương thức fit().
from sklearn import KMeans
kmeans = KMeans(n_clusters = 3, random_state = 0, n_init='auto')
kmeans.fit(X_train_norm)Sau khi dữ liệu đã được khớp, ta có thể truy cập nhãn từ thuộc tính labels_. Bên dưới, chúng ta trực quan hóa dữ liệu vừa khớp.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = kmeans.labels_)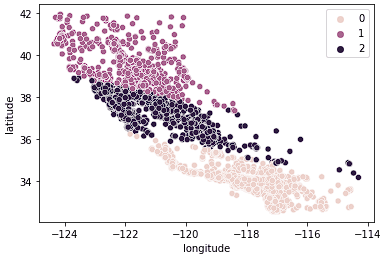
Ta thấy dữ liệu nay đã được chia rõ thành 3 nhóm riêng biệt (Bắc California, Trung California và Nam California). Ta cũng có thể xem phân phối giá nhà trung vị trong 3 nhóm này bằng biểu đồ hộp.
sns.boxplot(x = kmeans.labels_, y = y_train['median_house_value'])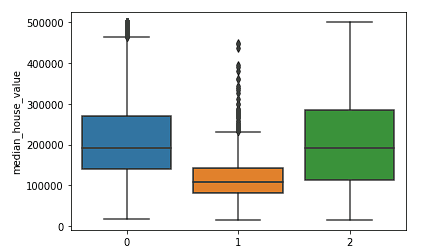
Rõ ràng các cụm phía Bắc và phía Nam (cụm 0 và 2) có phân phối giá nhà trung vị tương tự nhau và cao hơn so với cụm ở giữa (cụm 1).
Ta có thể đánh giá hiệu năng của thuật toán phân cụm bằng điểm Silhouette (thuộc sklearn.metrics), trong đó điểm cao hơn thể hiện mức độ phân cụm tốt hơn.
from sklearn.metrics import silhouette_score
silhouette_score(X_train_norm, kmeans.labels_, metric='euclidean')Vì chúng ta chưa xem xét sức mạnh của các số lượng cụm khác nhau, ta chưa biết mô hình k = 3 phù hợp đến mức nào. Ở phần tiếp theo, chúng ta sẽ thử các số cụm khác nhau và so sánh hiệu năng để quyết định giá trị siêu tham số tốt nhất cho mô hình.
Điểm yếu của k-means là ta không biết cần bao nhiêu cụm chỉ bằng cách chạy mô hình. Ta cần thử một dải giá trị và quyết định giá trị k tốt nhất. Thông thường, ta dùng phương pháp Elbow để xác định số cụm tối ưu, sao cho vừa không overfit dữ liệu với quá nhiều cụm, vừa không underfit với quá ít cụm.
Chúng ta tạo vòng lặp dưới đây để thử và lưu các kết quả mô hình khác nhau nhằm đưa ra quyết định về số cụm tối ưu.
K = range(2, 8)
fits = []
score = []
for k in K:
# train the model for current value of k on training data
model = KMeans(n_clusters = k, random_state = 0, n_init='auto').fit(X_train_norm)
# append the model to fits
fits.append(model)
# Append the silhouette score to scores
score.append(silhouette_score(X_train_norm, model.labels_, metric='euclidean'))Sau đó, chúng ta có thể quan sát trực quan một vài giá trị k khác nhau.
Đầu tiên, xem k = 2.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[0].labels_)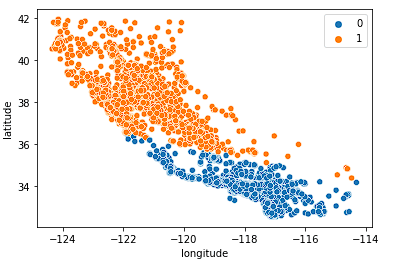
Mô hình chia bang thành hai nửa ở mức chấp nhận được, nhưng có lẽ chưa nắm bắt đủ sắc thái của thị trường nhà ở California.
Tiếp theo, xem k = 4.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)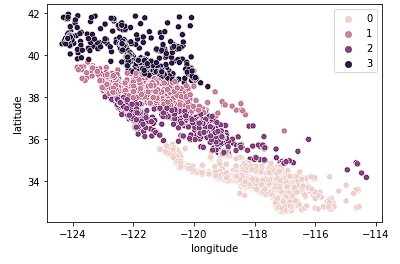
Biểu đồ này cho thấy California được gom thành các cụm hợp lý hơn trên toàn bang dựa trên mức độ ở phía Bắc hay phía Nam. Mô hình này nhiều khả năng nắm bắt được nhiều sắc thái hơn của thị trường nhà khi di chuyển dọc theo bang.
Cuối cùng, xem k = 7.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)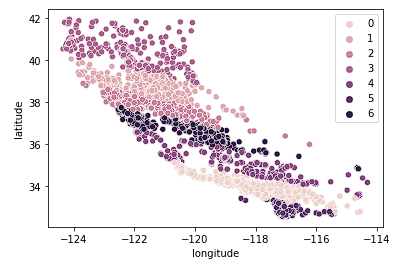
Biểu đồ trên có vẻ có quá nhiều cụm. Ta đã đánh đổi khả năng diễn giải dễ dàng các cụm để lấy một kết quả phân cụm địa lý “chính xác hơn”.
Thông thường, khi tăng giá trị K, ta thấy sự cải thiện trong các cụm và ý nghĩa của chúng đến một điểm nhất định. Sau đó, lợi ích giảm dần hoặc thậm chí hiệu năng tệ hơn. Ta có thể quan sát trực quan điều này để ra quyết định về giá trị k bằng biểu đồ khuỷu tay, trong đó trục y là thước đo độ phù hợp và trục x là giá trị k.
sns.lineplot(x = K, y = score)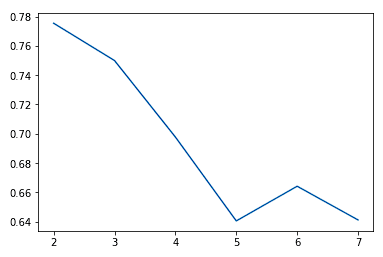
Ta thường chọn điểm mà cải thiện hiệu năng bắt đầu phẳng lại hoặc trở nên tệ hơn. Ta thấy k = 5 có lẽ là tốt nhất mà không dẫn đến overfit.
Ta cũng thấy các cụm làm khá tốt việc chia California thành những cụm riêng biệt, và các cụm này ánh xạ tương đối tốt tới các mức giá khác nhau như bên dưới.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[3].labels_)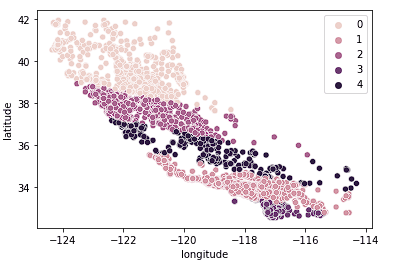
sns.boxplot(x = fits[3].labels_, y = y_train['median_house_value'])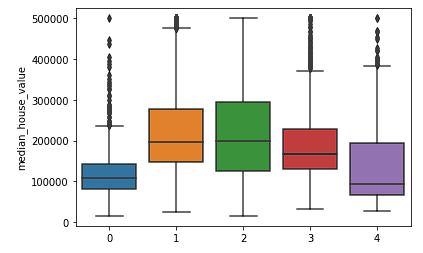
K-means hoạt động tốt nhất trên dữ liệu có dạng hình cầu. Dữ liệu hình cầu là dữ liệu tụ lại gần nhau trong không gian. Điều này có thể được trực quan hóa dễ hơn trong không gian 2 hoặc 3 chiều. Dữ liệu không hình cầu hoặc không nên hình cầu sẽ không phù hợp với k-means. Ví dụ, k-means sẽ không hoạt động tốt trên dữ liệu dưới đây vì ta không thể tìm các trọng tâm riêng biệt để phân cụm hai vòng tròn hay cung tròn khác nhau, dù trực quan rõ ràng đó là hai vòng/cung riêng và nên được gán nhãn như vậy.
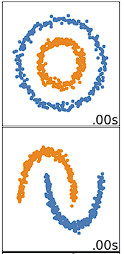
Có nhiều thuật toán phân cụm khác thực hiện tốt với dữ liệu phi hình cầu, được đề cập trong Clustering in Machine Learning: 5 Essential Clustering Algorithms.
Quyết định chia dữ liệu phụ thuộc vào mục tiêu phân cụm của bạn. Nếu mục tiêu là phân cụm dữ liệu như điểm kết thúc của phân tích, thì không cần thiết. Nếu bạn dùng các cụm như một đặc trưng trong mô hình học có giám sát hoặc cho dự đoán (như chúng tôi làm trong hướng dẫn Scikit-Learn Tutorial: Baseball Analytics Pt 1), thì bạn cần chia dữ liệu trước khi phân cụm để đảm bảo tuân theo thực hành tốt nhất cho quy trình học có giám sát.
Bây giờ bạn đã nắm các kiến thức cơ bản về k-means trong Python, bạn có thể xem khóa học Unsupervised Learning in Python để có phần giới thiệu tốt về k-means và các thuật toán học không giám sát khác. Khóa học nâng cao hơn, Cluster Analysis in Python, cung cấp cái nhìn chuyên sâu hơn về các thuật toán phân cụm và cách xây dựng, tinh chỉnh chúng trong Python. Cuối cùng, bạn cũng có thể xem hướng dẫn Giới thiệu về phân cụm phân cấp trong Python như một cách tiếp cận dùng thuật toán thay thế để tạo phân cấp từ dữ liệu.
Tìm hiểu thêm về Machine Learning
Courses
Courses
Courses