Cluster Analysis in Python
BeginnerSkill Level
4 h
57.6K learners

Neste tutorial, você aprenderá sobre o k-means clustering. Abordaremos o assunto:
Observe que isso não deve ser confundido com k-nearest neighbors (vizinhos mais próximos), e os leitores que desejarem isso devem acessar k-Nearest Neighbors (KNN) Classification with scikit-learn in Python.
É útil saber isso, pois o k-means clustering é um algoritmo de clustering popular que faz um bom trabalho de agrupamento de dados esféricos em grupos distintos. Isso é muito valioso como ferramenta de análise quando os agrupamentos de linhas de dados não são claros ou como uma etapa de engenharia de recursos para aprimorar os modelos de aprendizado supervisionado.
Para este tutorial, esperamos ter um conhecimento básico de Python e a capacidade de trabalhar com pandas Dataframes.
Os modelos de agrupamento têm como objetivo agrupar os dados em "clusters" ou grupos distintos. Isso pode servir como uma visão interessante em uma análise ou pode servir como um recurso em um algoritmo de aprendizado supervisionado.
Considere um ambiente social em que há grupos de pessoas discutindo em diferentes círculos ao redor de uma sala. Quando você olha para a sala pela primeira vez, vê apenas um grupo de pessoas. Você poderia começar mentalmente a colocar pontos no centro de cada grupo de pessoas e nomear esse ponto como um identificador exclusivo. Assim, você poderá se referir a cada grupo com um nome exclusivo para descrevê-los. Isso é basicamente o que o agrupamento k-means faz com os dados.
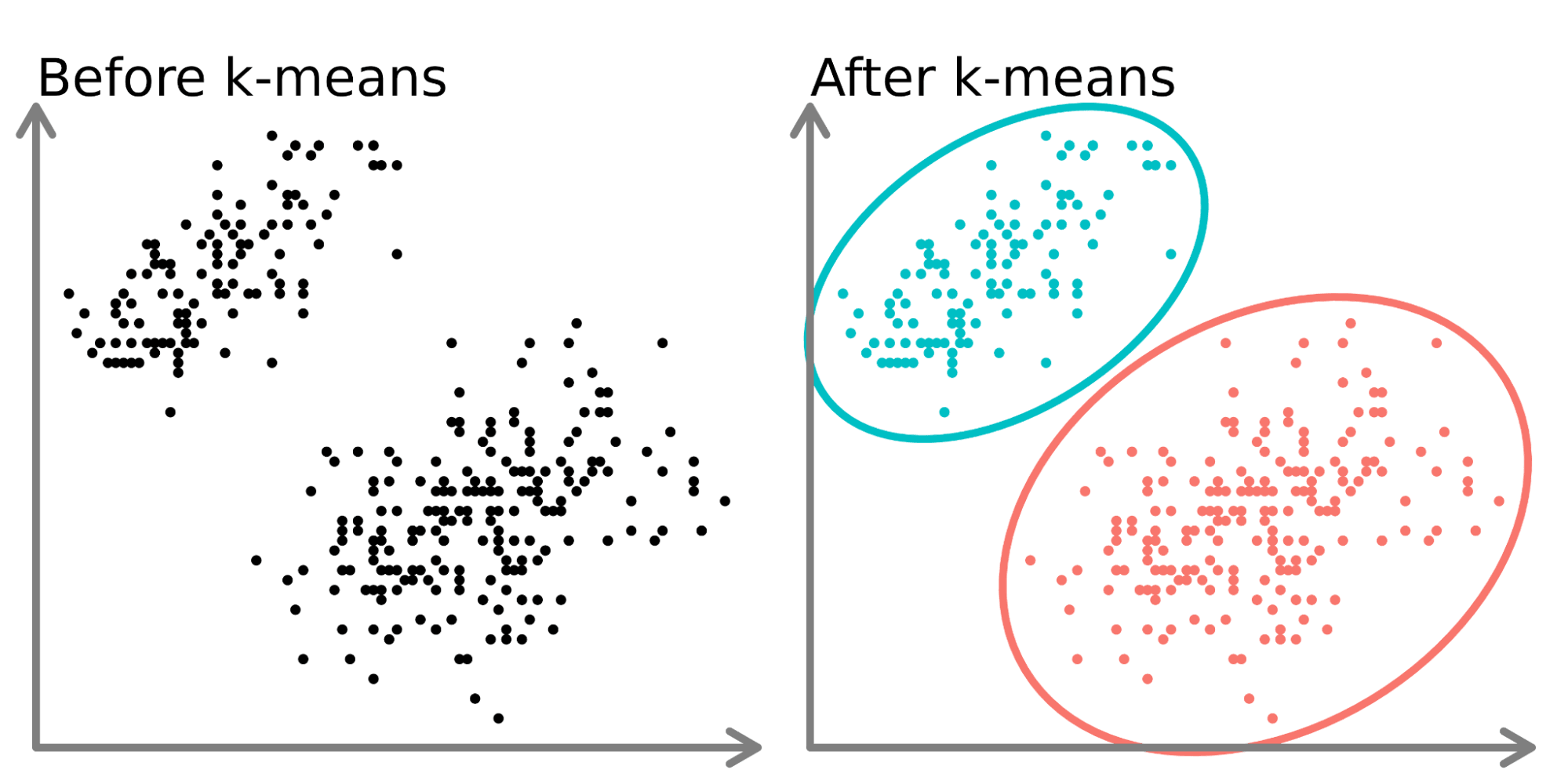
No lado esquerdo do diagrama acima, podemos ver dois conjuntos distintos de pontos que não são rotulados e são coloridos como pontos de dados semelhantes. O ajuste de um modelo k-means a esses dados (lado direito) pode revelar dois grupos distintos (mostrados em círculos e cores diferentes).
Em duas dimensões, é fácil para os humanos dividirem esses clusters, mas com mais dimensões, você precisa usar um modelo.
Neste tutorial, usaremos os dados de habitação da Califórnia do Kaggle(aqui). Usaremos dados de localização (latitude e longitude), bem como o valor médio da casa. Agruparemos as casas por local e observaremos como os preços das casas flutuam na Califórnia. Salvamos o conjunto de dados como um arquivo csv chamado ‘housing.csv’ em nosso diretório de trabalho e o lemos usando pandas.
import pandas as pd
home_data = pd.read_csv('housing.csv', usecols = ['longitude', 'latitude', 'median_house_value'])
home_data.head()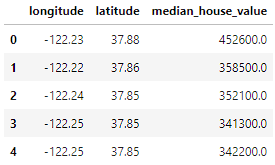
Os dados incluem 3 variáveis que selecionamos usando o parâmetro usecols:
Como outros algoritmos de aprendizado de máquina, o k-Means Clustering tem um fluxo de trabalho (consulte o Guia do iniciante para o fluxo de trabalho de aprendizado de máquina para obter uma análise mais detalhada do fluxo de trabalho de aprendizado de máquina).
Neste tutorial, vamos nos concentrar na coleta e na divisão dos dados (na preparação de dados) e no ajuste de hiperparâmetros, no treinamento do modelo e na avaliação do desempenho do modelo (na modelagem). Grande parte do trabalho envolvido nos algoritmos de aprendizado não supervisionado está no ajuste dos hiperparâmetros e na avaliação do desempenho para obter os melhores resultados do seu modelo.
Começamos visualizando nossos dados de habitação. Analisamos os dados de localização com um mapa de calor baseado no preço médio em um bloco. Usaremos o Seaborn para criar gráficos rapidamente neste tutorial (consulte nosso curso Introdução à visualização de dados com o Seaborn para entender melhor como esses gráficos estão sendo criados).
import seaborn as sns
sns.scatterplot(data = home_data, x = 'longitude', y = 'latitude', hue = 'median_house_value')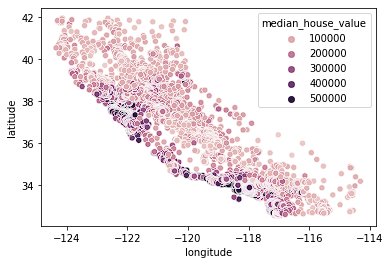
Vemos que a maioria das casas caras está na costa oeste da Califórnia, com diferentes áreas que têm grupos de casas com preços moderados. Isso é esperado, pois normalmente as propriedades à beira-mar valem mais do que as casas que não estão na costa.
Os clusters geralmente são fáceis de detectar quando você está usando apenas 2 ou 3 recursos. Isso se torna cada vez mais difícil ou impossível quando o
Ao trabalhar com algoritmos baseados em distância, como o k-Means Clustering, precisamos normalizar os dados. Se não normalizarmos os dados, as variáveis com escalas diferentes terão pesos diferentes na fórmula de distância que está sendo otimizada durante o treinamento. Por exemplo, se incluíssemos o preço no cluster, além da latitude e da longitude, o preço teria um impacto desproporcional nas otimizações porque sua escala é significativamente maior e mais ampla do que as variáveis de local delimitadas.
Primeiro, configuramos as divisões de treinamento e teste usando o site train_test_split de sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(home_data[['latitude', 'longitude']], home_data[['median_house_value']], test_size=0.33, random_state=0)Em seguida, normalizamos os dados de treinamento e teste usando o método preprocessing.normalize() de sklearn.
from sklearn import preprocessing
X_train_norm = preprocessing.normalize(X_train)
X_test_norm = preprocessing.normalize(X_test)Para a primeira iteração, escolheremos arbitrariamente um número de clusters (chamado de k) de 3. A criação e o ajuste de modelos no site sklearn são muito simples. Criaremos uma instância de KMeans, definiremos o número de clusters usando o atributo n_clusters, definiremos n_init, que define o número de iterações que o algoritmo executará com diferentes sementes de centroide, como "auto" e definiremos random_state como 0 para obtermos o mesmo resultado sempre que executarmos o código. Em seguida, podemos ajustar o modelo aos dados de treinamento normalizados usando o método fit().
from sklearn import KMeans
kmeans = KMeans(n_clusters = 3, random_state = 0, n_init='auto')
kmeans.fit(X_train_norm)Quando os dados estiverem ajustados, poderemos acessar os rótulos do atributo labels_. Abaixo, visualizamos os dados que acabamos de ajustar.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = kmeans.labels_)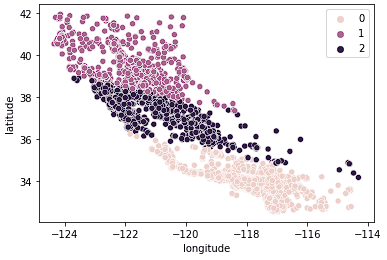
Vemos que os dados agora estão claramente divididos em três grupos distintos (norte da Califórnia, centro da Califórnia e sul da Califórnia). Também podemos observar a distribuição dos preços médios dos imóveis nesses três grupos usando um boxplot.
sns.boxplot(x = kmeans.labels_, y = y_train['median_house_value'])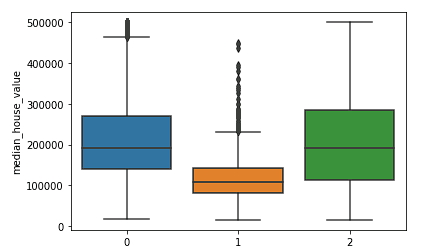
Vemos claramente que os clusters do norte e do sul têm distribuições semelhantes de valores médios de imóveis (clusters 0 e 2) que são mais altos do que os preços no cluster central (cluster 1).
Podemos avaliar o desempenho do algoritmo de agrupamento usando uma pontuação Silhouette, que é uma parte do site sklearn.metrics em que uma pontuação mais baixa representa um melhor ajuste.
from sklearn.metrics import silhouette_score
silhouette_score(X_train_norm, kmeans.labels_, metric='euclidean')Como não analisamos a força de diferentes números de clusters, não sabemos se o modelo k = 3 é adequado. Na próxima seção, exploraremos diferentes clusters e compararemos o desempenho para tomar uma decisão sobre os melhores valores de hiperparâmetro para o nosso modelo.
O ponto fraco do k-means clustering é que não sabemos de quantos clusters precisamos apenas executando o modelo. Precisamos testar faixas de valores e tomar uma decisão sobre o melhor valor de k. Normalmente, tomamos uma decisão usando o método Elbow para determinar o número ideal de clusters em que não estamos superajustando os dados com muitos clusters e também não estamos subajustando com poucos.
Criamos o loop abaixo para testar e armazenar diferentes resultados de modelos para que possamos tomar uma decisão sobre o melhor número de clusters.
K = range(2, 8)
fits = []
score = []
for k in K:
# train the model for current value of k on training data
model = KMeans(n_clusters = k, random_state = 0, n_init='auto').fit(X_train_norm)
# append the model to fits
fits.append(model)
# Append the silhouette score to scores
score.append(silhouette_score(X_train_norm, model.labels_, metric='euclidean'))Podemos, então, primeiro examinar visualmente alguns valores diferentes de k.
Primeiro, analisamos k = 2.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[0].labels_)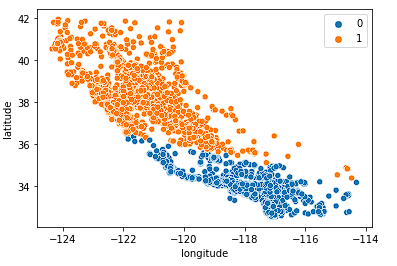
O modelo faz um bom trabalho ao dividir o estado em duas metades, mas provavelmente não capta nuances suficientes no mercado imobiliário da Califórnia.
Em seguida, analisamos k = 4.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)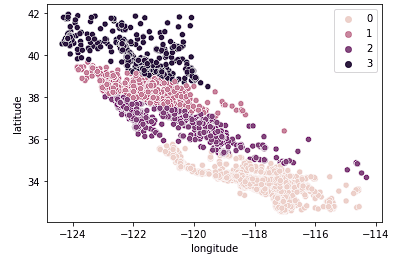
Vemos que esse gráfico agrupa a Califórnia em grupos mais lógicos em todo o estado com base na distância entre o norte e o sul das casas no estado. Esse modelo provavelmente capta mais nuances no mercado imobiliário à medida que avançamos pelo estado.
Por fim, analisamos k = 7.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)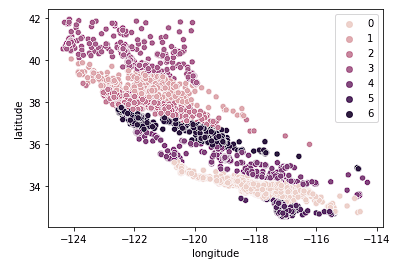
O gráfico acima parece ter muitos clusters. Sacrificamos a fácil interpretação dos agrupamentos para obter um resultado de agrupamento geográfico "mais preciso".
Normalmente, à medida que aumentamos o valor de K, observamos melhorias nos clusters e no que eles representam até um determinado ponto. Então, começamos a ver retornos decrescentes ou até mesmo um desempenho pior. Podemos ver isso visualmente para ajudar a tomar uma decisão sobre o valor de k usando um gráfico de cotovelo em que o eixo y é uma medida da qualidade do ajuste e o eixo x é o valor de k.
sns.lineplot(x = K, y = score)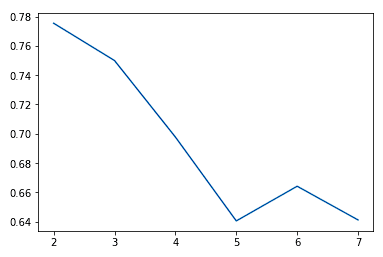
Normalmente, escolhemos o ponto em que as melhorias no desempenho começam a se estabilizar ou piorar. Vemos que k = 5 é provavelmente o melhor que podemos fazer sem excesso de ajuste.
Também podemos ver que os grupos fazem um trabalho relativamente bom ao dividir a Califórnia em grupos distintos, e esses grupos mapeiam relativamente bem as diferentes faixas de preço, conforme mostrado abaixo.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[3].labels_)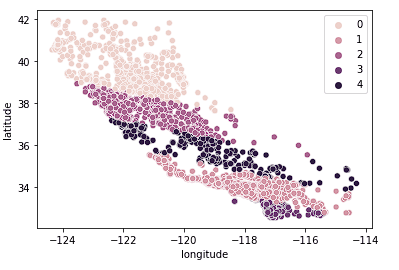
sns.boxplot(x = fits[3].labels_, y = y_train['median_house_value'])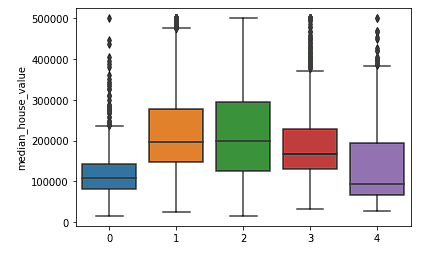
O agrupamento K-means tem melhor desempenho em dados esféricos. Os dados esféricos são dados que se agrupam no espaço e estão muito próximos uns dos outros. Isso pode ser visualizado mais facilmente em um espaço bidimensional ou tridimensional. Os dados que não são esféricos ou que não deveriam ser esféricos não funcionam bem com o k-means clustering. Por exemplo, o agrupamento k-means não funcionaria bem nos dados abaixo, pois não conseguiríamos encontrar centroides distintos para agrupar os dois círculos ou arcos de forma diferente, apesar de serem claramente dois círculos e arcos distintos que deveriam ser rotulados como tal.
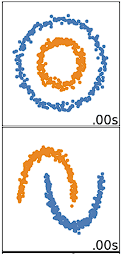
Há muitos outros algoritmos de agrupamento que fazem um bom trabalho de agrupamento de dados não esféricos, abordados em Clustering in Machine Learning: 5 Algoritmos essenciais de clusterização.
A decisão de dividir seus dados depende de quais são seus objetivos para o clustering. Se o objetivo for agrupar seus dados no final da análise, isso não será necessário. Se você estiver usando os clusters como um recurso em um modelo de aprendizado supervisionado ou para previsão (como fazemos no tutorial Scikit-Learn: Baseball Analytics Pt 1 tutorial), será necessário dividir os dados antes do agrupamento para garantir que você esteja seguindo as práticas recomendadas para o fluxo de trabalho de aprendizado supervisionado.
Agora que abordamos os conceitos básicos do k-means clustering em Python, você pode conferir este curso Aprendizado não supervisionado em Python para obter uma boa introdução ao k-means e a outros algoritmos de aprendizado não supervisionado. Nosso curso mais avançado, Cluster Analysis in Python, oferece uma visão mais aprofundada dos algoritmos de agrupamento e de como criá-los e ajustá-los em Python. Por fim, você também pode conferir o tutorial An Introduction to Hierarchical Clustering in Python como uma abordagem que usa um algoritmo alternativo para criar hierarquias a partir de dados.
Saiba mais sobre aprendizado de máquina
Curso
Curso
Curso
blog
Moez Ali
15 min
Tutorial
Eugenia Anello
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
