Cluster Analysis in Python
57.6K learners

Kümeleme modelleri verileri farklı “kümeler” veya gruplar halinde toplamayı amaçlar. Bu, bir analizde ilginç bir bakış sunabileceği gibi, bir denetimli öğrenme algoritmasında bir özellik olarak da kullanılabilir.
Bir odanın etrafında farklı halkalar halinde sohbet eden insan gruplarının olduğu sosyal bir ortamı düşünün. Odaya ilk baktığınızda yalnızca bir insan kalabalığı görürsünüz. Zihninizde her grubun merkezine birer nokta yerleştirip bu noktalara benzersiz birer ad verebilirsiniz. Böylece her gruba onları tanımlamak için benzersiz bir adla atıfta bulunabilirsiniz. K-means kümeleme verilerle temelde bunu yapar.
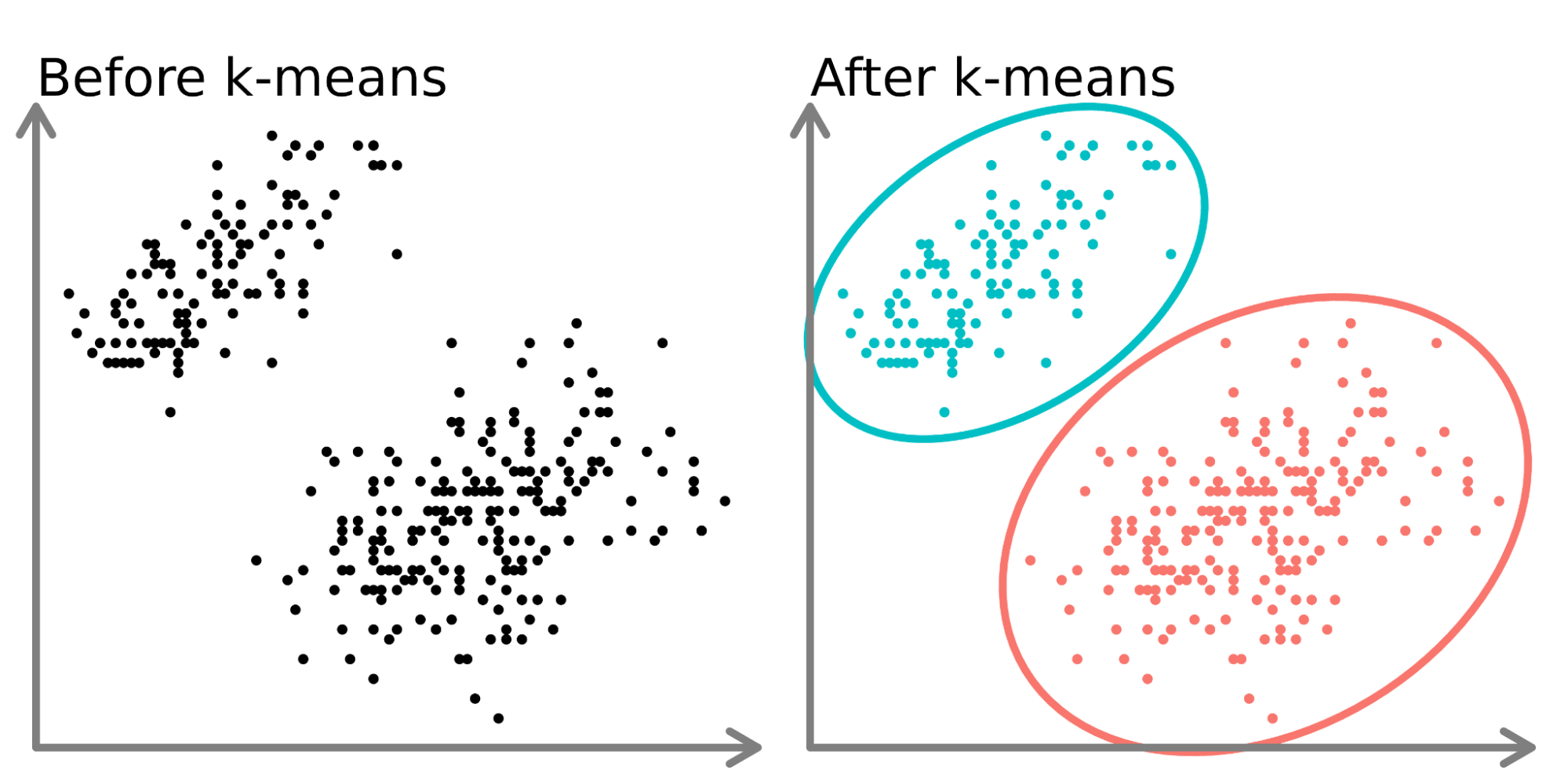
Yukarıdaki diyagramın sol tarafında, etiketlenmemiş ve benzer veri noktaları olarak renklendirilmiş 2 ayrı nokta kümesi görüyoruz. Bu verilere bir k-means modeli uydurmak (sağ taraf), 2 ayrı grubu (hem farklı çemberlerle hem de renklerle gösterilen) ortaya çıkarabilir.
İki boyutta insanlar bu kümeleri kolayca ayırabilir; ancak daha fazla boyutta bir modele ihtiyaç duyarsınız.
Bu eğitimde, Kaggle'dan Kaliforniya konut verilerini (buradan) kullanacağız. Konum verilerini (enlem ve boylam) ve ayrıca medyan konut değerini kullanacağız. Evleri konuma göre kümelendirip fiyatların Kaliforniya genelinde nasıl dalgalandığını gözlemleyeceğiz. Veri kümesini çalışma dizinimize ‘housing.csv’ adıyla csv dosyası olarak kaydedip pandas ile okuyacağız.
import pandas as pd
home_data = pd.read_csv('housing.csv', usecols = ['longitude', 'latitude', 'median_house_value'])
home_data.head()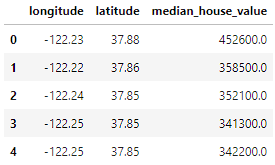
Veriler, usecols parametresiyle seçtiğimiz 3 değişken içeriyor:
Diğer Makine Öğrenmesi algoritmalarında olduğu gibi, k-Means Kümelemenin de bir iş akışı vardır (Makine öğrenmesi iş akışının daha ayrıntılı bir dökümü için A Beginner's Guide to The Machine Learning Workflow içeriğine bakın).
Bu eğitimde, veriyi toplama ve bölmeye (veri hazırlamada) ve hiperparametre ayarlama, modeli eğitme ve model performansını değerlendirmeye (modellemede) odaklanacağız. Denetimsiz öğrenme algoritmalarında işin büyük kısmı, modelinizden en iyi sonuçları almak için hiperparametre ayarlama ve performans değerlendirmesinde yatar.
Önce konut verilerimizi görselleştirerek başlıyoruz. Bir bloktaki medyan fiyata dayalı bir ısı haritasıyla konum verilerine bakıyoruz. Bu eğitimde hızlıca grafikler oluşturmak için Seaborn kullanacağız (bu grafiklerin nasıl oluşturulduğunu daha iyi anlamak için Introduction to Data Visualization with Seaborn kursumuza bakın).
import seaborn as sns
sns.scatterplot(data = home_data, x = 'longitude', y = 'latitude', hue = 'median_house_value')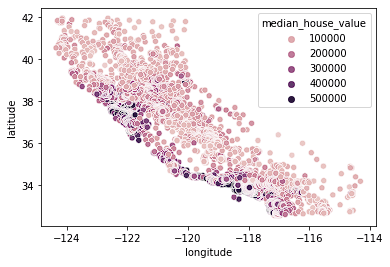
En pahalı evlerin çoğunun Kaliforniya'nın batı kıyısında olduğunu ve orta fiyatlı evlerin kümelendiği farklı bölgeler bulunduğunu görüyoruz. Bu beklenen bir durum; zira genellikle su kenarındaki mülkler, kıyıda olmayan evlere kıyasla daha değerlidir.
Yalnızca 2 veya 3 özellik kullanırken kümeleri fark etmek genellikle kolaydır. Özellik sayısı arttıkça bu giderek zorlaşır ya da imkânsız hale gelir
k-Means Kümeleme gibi mesafeye dayalı algoritmalarla çalışırken veriyi normalize etmeliyiz. Veriyi normalize etmezsek, farklı ölçeklere sahip değişkenler, eğitim sırasında optimize edilen mesafe formülünde farklı ağırlıklandırılır. Örneğin, kümeye enlem ve boylama ek olarak fiyatı da dahil etseydik, fiyatın ölçeği konum değişkenlerine göre çok daha büyük ve geniş olduğu için optimizasyonlar üzerinde orantısız bir etkiye sahip olurdu.
Önce sklearn içindeki train_test_split ile eğitim ve test bölmeleri oluşturuyoruz.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(home_data[['latitude', 'longitude']], home_data[['median_house_value']], test_size=0.33, random_state=0)Sonra, sklearn içindeki preprocessing.normalize() yöntemiyle eğitim ve test verilerini normalize ediyoruz.
from sklearn import preprocessing
X_train_norm = preprocessing.normalize(X_train)
X_test_norm = preprocessing.normalize(X_test)İlk yinelemede, küme sayısı (k) olarak keyfî bir şekilde 3 seçeceğiz. sklearn ile model kurmak ve uydurmak çok basittir. KMeans örneği oluşturup n_clusters özniteliğiyle küme sayısını tanımlayacağız, farklı merkez tohumlarıyla algoritmanın çalışacağı yineleme sayısını tanımlayan n_init değerini “auto” olarak ayarlayacağız ve her çalıştırmada aynı sonucu almak için random_state'i 0 yapacağız. Ardından modeli normalize edilmiş eğitim verilerine fit() yöntemiyle uydurabiliriz.
from sklearn import KMeans
kmeans = KMeans(n_clusters = 3, random_state = 0, n_init='auto')
kmeans.fit(X_train_norm)Veriler uydurulduktan sonra, etiketlere labels_ özniteliğinden erişebiliriz. Aşağıda, az önce uydurduğumuz verileri görselleştiriyoruz.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = kmeans.labels_)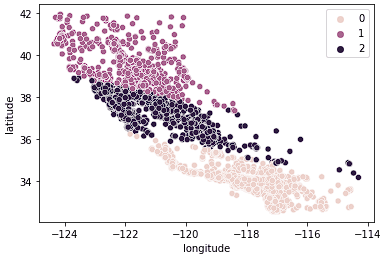
Verilerin artık açıkça 3 ayrı gruba (Kuzey Kaliforniya, Orta Kaliforniya ve Güney Kaliforniya) ayrıldığını görüyoruz. Bu 3 gruptaki medyan konut fiyatlarının dağılımına bir kutu grafiğiyle de bakabiliriz.
sns.boxplot(x = kmeans.labels_, y = y_train['median_house_value'])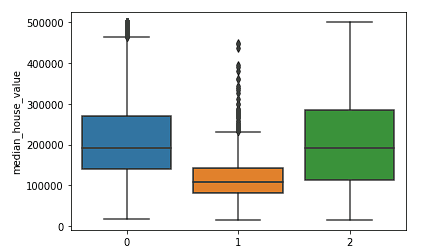
Kuzey ve Güney kümelerinin (kümeler 0 ve 2) medyan konut değerleri dağılımlarının birbirine benzer ve orta kümedeki (küme 1) fiyatlardan daha yüksek olduğunu net biçimde görüyoruz.
Kümeleme algoritmasının performansını, sklearn.metrics içinde yer alan ve daha düşük skorun daha iyi uyumu temsil ettiği Silhouette skoru ile değerlendirebiliriz.
from sklearn.metrics import silhouette_score
silhouette_score(X_train_norm, kmeans.labels_, metric='euclidean')Farklı küme sayılarının gücüne bakmadığımız için k = 3 modelinin ne kadar iyi uyduğunu bilmiyoruz. Bir sonraki bölümde, farklı kümeleri inceleyip performansı karşılaştırarak modelimiz için en iyi hiperparametre değerlerine karar vereceğiz.
k-means kümelemenin zayıf yanı, modeli yalnızca çalıştırarak kaç kümeye ihtiyacımız olduğunu bilemememizdir. Değer aralıklarını test edip k için en iyi değere karar vermemiz gerekir. Genellikle, hem çok fazla kümeyle aşırı uyumdan kaçınmak hem de çok az kümeyle yetersiz uyumdan kaçınmak için en uygun küme sayısını belirlemede Dirsek (Elbow) yöntemini kullanırız.
En iyi küme sayısına karar verebilmek için farklı model sonuçlarını test edip depolayacak aşağıdaki döngüyü oluşturuyoruz.
K = range(2, 8)
fits = []
score = []
for k in K:
# train the model for current value of k on training data
model = KMeans(n_clusters = k, random_state = 0, n_init='auto').fit(X_train_norm)
# append the model to fits
fits.append(model)
# Append the silhouette score to scores
score.append(silhouette_score(X_train_norm, model.labels_, metric='euclidean'))Ardından önce birkaç farklı k değeri için görsel olarak bakalım.
Önce k = 2'ye bakıyoruz.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[0].labels_)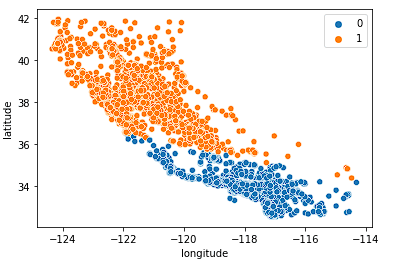
Model eyaleti iki yarıya bölme işini fena yapmıyor; ancak muhtemelen Kaliforniya konut piyasasındaki yeterli nüansı yakalamıyor.
Sonra k = 4'e bakıyoruz.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)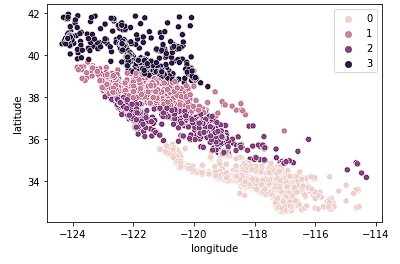
Bu grafiğin, evlerin eyalette ne kadar kuzeyde veya güneyde olduğuna göre Kaliforniya'yı daha mantıklı kümelere ayırdığını görüyoruz. Bu model, eyalet genelinde ilerledikçe konut piyasasındaki daha fazla nüansı büyük olasılıkla yakalıyor.
Son olarak k = 7'ye bakıyoruz.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)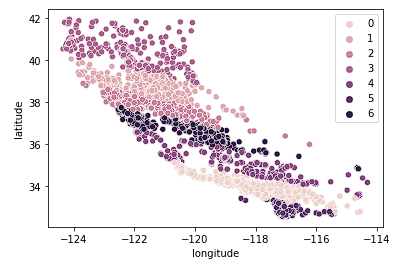
Yukarıdaki grafikte çok fazla küme var gibi görünüyor. “Daha doğru” bir coğrafi kümeleme sonucu uğruna kümelerin kolay yorumlanabilirliğinden ödün vermiş olduk.
Genellikle K değerini artırdıkça, belli bir noktaya kadar kümelerde ve temsil ettikleri yapılarda iyileşmeler görürüz. Sonrasında azalan getiriler hatta daha kötü performansla karşılaşmaya başlarız. k değerine karşı uyum iyiliği ölçütünün y-eksende, k değerinin x-eksende olduğu bir dirsek grafiği kullanarak bunu görsel olarak görüp karar verebiliriz.
sns.lineplot(x = K, y = score)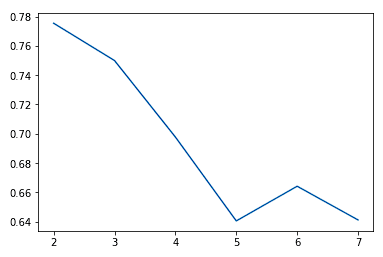
Genellikle performanstaki iyileşmelerin düzleşmeye başladığı veya kötüleştiği noktayı seçeriz. Aşırı uyuma gitmeden muhtemelen yapabileceğimizin en iyisi k = 5 gibi görünüyor.
Ayrıca, kümelerin Kaliforniya'yı farklı kümelere ayırmada nispeten iyi iş çıkardığını ve bu kümelerin aşağıda görüldüğü gibi farklı fiyat aralıklarıyla da nispeten iyi eşleştiğini görebiliyoruz.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[3].labels_)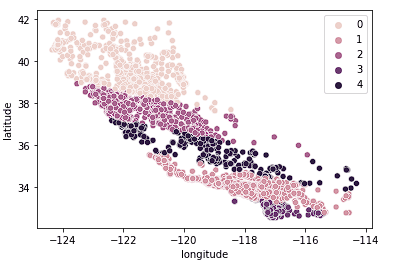
sns.boxplot(x = fits[3].labels_, y = y_train['median_house_value'])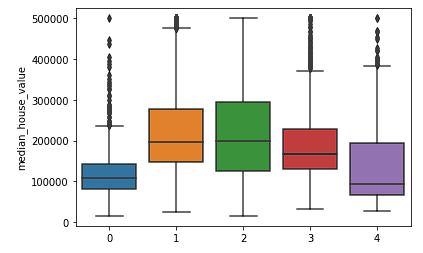
K-means kümeleme, küresel (spherical) veriler üzerinde en iyi performansı gösterir. Küresel veriler, uzayda birbirine yakın kümelenen verilerdir. Bu durum 2 ya da 3 boyutlu uzayda daha kolay görselleştirilebilir. Küresel olmayan ya da küresel olması gerekmeyen veriler, k-means küleme ile iyi çalışmaz. Örneğin, aşağıdaki verilerde k-means başarılı olmaz; çünkü iki çemberi veya yayı farklı şekilde kümelendirecek belirgin merkezler bulamayız; oysa görsel olarak açıkça iki farklı çember ve yay vardır ve öyle etiketlenmelidirler.
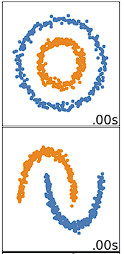
Küresel olmayan verileri iyi kümeleyen birçok başka kümeleme algoritması vardır; Clustering in Machine Learning: 5 Essential Clustering Algorithms içeriğinde ele alınmıştır.
Verinizi ayırma kararı, kümelemeden beklentilerinize bağlıdır. Eğer amacınız analizinizin sonunda veriyi kümelemekse, bu gerekli değildir. Kümeleri bir denetimli öğrenme modelinde özellik olarak veya tahmin amacıyla kullanıyorsanız (örneğin Scikit-Learn Tutorial: Baseball Analytics Pt 1 eğitiminde yaptığımız gibi), denetimli öğrenme iş akışındaki en iyi uygulamalara uyduğunuzdan emin olmak için kümeleme öncesinde verinizi ayırmanız gerekir.
Artık Python'da k-means kümelemenin temellerini ele aldığımıza göre, k-means ve diğer denetimsiz öğrenme algoritmalarına iyi bir giriş için bu Unsupervised Learning in Python kursuna göz atabilirsiniz. Daha ileri düzey kursumuz Cluster Analysis in Python, kümeleme algoritmalarını ve bunları Python'da nasıl kurup ayarlayacağınızı daha derinlemesine inceler. Son olarak, verilerden hiyerarşiler oluşturmak için alternatif bir algoritma kullanan An Introduction to Hierarchical Clustering in Python eğitimine de bakabilirsiniz.
Makine Öğrenmesi hakkında daha fazla bilgi edinin
Kurs
Kurs
Kurs