Clusteranalyse in Python
56.1K learners

Clustering-Modelle zielen darauf ab, Daten in verschiedene "Cluster" oder Gruppen einzuteilen. Dies kann sowohl als interessanter Blick in einer Analyse als auch als Merkmal in einem überwachten Lernalgorithmus dienen.
Stell dir ein soziales Umfeld vor, in dem Gruppen von Menschen in verschiedenen Kreisen in einem Raum diskutieren. Wenn du den Raum zum ersten Mal betrittst, siehst du nur eine Gruppe von Menschen. Du könntest gedanklich damit beginnen, Punkte in der Mitte jeder Gruppe von Menschen zu platzieren und diesen Punkt als eindeutigen Identifikator zu benennen. Dann kannst du jeder Gruppe einen eindeutigen Namen geben, um sie zu beschreiben. Das ist im Wesentlichen das, was das k-means Clustering mit Daten macht.
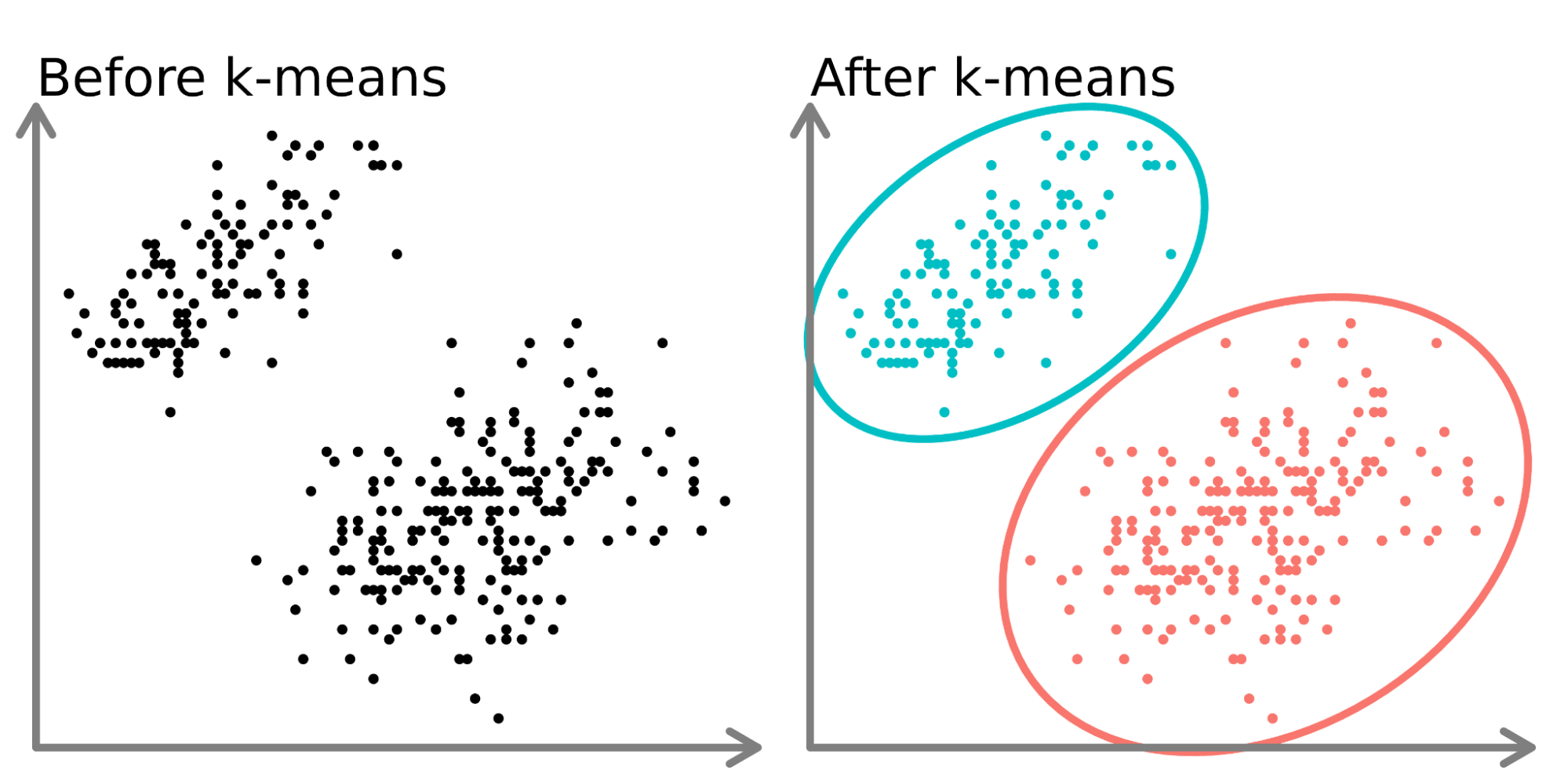
Auf der linken Seite des obigen Diagramms sehen wir 2 verschiedene Punktesätze, die nicht beschriftet und als ähnliche Datenpunkte eingefärbt sind. Wenn du ein K-Mittelwert-Modell auf diese Daten anpasst (rechte Seite), kannst du zwei verschiedene Gruppen erkennen (dargestellt durch unterschiedliche Kreise und Farben).
In zwei Dimensionen ist es für Menschen einfach, diese Cluster aufzuteilen, aber bei mehr Dimensionen musst du ein Modell verwenden.
In diesem Tutorial verwenden wir die Wohnungsdaten aus Kalifornien von Kaggle(hier). Wir verwenden Standortdaten (Breiten- und Längengrad) sowie den Medianwert des Hauses. Wir werden die Häuser nach Standort gruppieren und beobachten, wie die Hauspreise in Kalifornien schwanken. Wir speichern den Datensatz als csv-Datei namens ‘housing.csv’ in unserem Arbeitsverzeichnis und lesen ihn mit pandas.
import pandas as pd
home_data = pd.read_csv('housing.csv', usecols = ['longitude', 'latitude', 'median_house_value'])
home_data.head()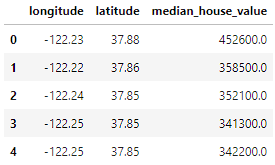
Die Daten enthalten 3 Variablen, die wir mit dem Parameter usecols ausgewählt haben:
Wie bei anderen Algorithmen des maschinellen Lernens gibt es auch beim k-Means-Clustering einen Arbeitsablauf (siehe A Beginner's Guide to The Machine Learning Workflow für eine genauere Beschreibung des Arbeitsablaufs beim maschinellen Lernen).
In diesem Lernprogramm konzentrieren wir uns auf das Sammeln und Aufteilen der Daten (in der Datenvorbereitung), das Abstimmen der Hyperparameter, das Trainieren deines Modells und das Bewerten der Modellleistung (in der Modellierung). Ein Großteil der Arbeit, die mit unüberwachten Lernalgorithmen verbunden ist, besteht in der Abstimmung der Hyperparameter und der Bewertung der Leistung, um die besten Ergebnisse aus deinem Modell zu erzielen.
Wir beginnen damit, unsere Wohnungsdaten zu visualisieren. Wir sehen uns die Standortdaten mit einer Heatmap an, die auf dem Medianpreis in einem Block basiert. In diesem Lernprogramm werden wir Seaborn verwenden, um schnell Diagramme zu erstellen (siehe unseren Kurs Einführung in die Datenvisualisierung mit Seaborn, um besser zu verstehen, wie diese Diagramme erstellt werden).
import seaborn as sns
sns.scatterplot(data = home_data, x = 'longitude', y = 'latitude', hue = 'median_house_value')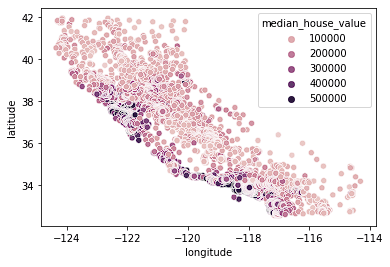
Wir sehen, dass sich die meisten teuren Häuser an der Westküste Kaliforniens befinden, aber es gibt auch Gegenden, in denen sich Häuser zu moderaten Preisen angesammelt haben. Das ist zu erwarten, denn normalerweise sind Grundstücke am Wasser mehr wert als Häuser, die nicht an der Küste liegen.
Cluster sind oft leicht zu erkennen, wenn du nur 2 oder 3 Merkmale verwendest. Es wird immer schwieriger oder unmöglich, wenn die
Wenn wir mit abstandsbasierten Algorithmen wie dem k-Means Clustering arbeiten, müssen wir die Daten normalisieren. Wenn wir die Daten nicht normalisieren, werden Variablen mit unterschiedlicher Skalierung in der Distanzformel, die beim Training optimiert wird, unterschiedlich gewichtet. Wenn wir zum Beispiel zusätzlich zu Längen- und Breitengrad auch den Preis in den Cluster aufnehmen würden, hätte dieser einen großen Einfluss auf die Optimierungen, da seine Skala deutlich größer und breiter ist als die der begrenzten Standortvariablen.
Wir haben zunächst Trainings- und Testsplits mit train_test_split von sklearn erstellt.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(home_data[['latitude', 'longitude']], home_data[['median_house_value']], test_size=0.33, random_state=0)Als nächstes normalisieren wir die Trainings- und Testdaten mit der Methode preprocessing.normalize() von sklearn.
from sklearn import preprocessing
X_train_norm = preprocessing.normalize(X_train)
X_test_norm = preprocessing.normalize(X_test)Für die erste Iteration wählen wir eine willkürliche Anzahl von Clustern (k) von 3. Das Erstellen und Anpassen von Modellen in sklearn ist sehr einfach. Wir erstellen eine Instanz von KMeans, legen die Anzahl der Cluster mit dem Attribut n_clusters fest, setzen n_init, das die Anzahl der Iterationen festlegt, die der Algorithmus mit verschiedenen Schwerpunktseeds durchläuft, auf "auto" und setzen random_state auf 0, damit wir jedes Mal, wenn wir den Code ausführen, das gleiche Ergebnis erhalten. Anschließend können wir das Modell mit der Methode fit() an die normalisierten Trainingsdaten anpassen.
from sklearn import KMeans
kmeans = KMeans(n_clusters = 3, random_state = 0, n_init='auto')
kmeans.fit(X_train_norm)Sobald die Daten angepasst sind, können wir über das Attribut labels_ auf die Labels zugreifen. Im Folgenden stellen wir die Daten dar, die wir gerade angepasst haben.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = kmeans.labels_)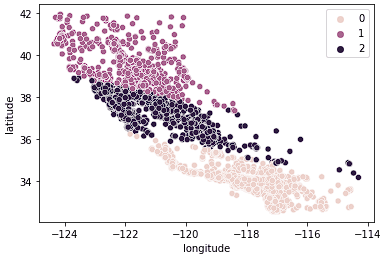
Wir sehen, dass die Daten jetzt eindeutig in drei verschiedene Gruppen aufgeteilt sind (Nordkalifornien, Mittelkalifornien und Südkalifornien). Wir können uns auch die Verteilung der mittleren Hauspreise in diesen 3 Gruppen mithilfe eines Boxplots ansehen.
sns.boxplot(x = kmeans.labels_, y = y_train['median_house_value'])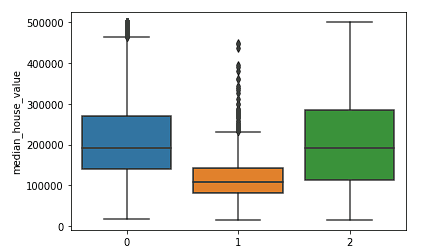
Wir sehen deutlich, dass die nördlichen und südlichen Cluster eine ähnliche Verteilung der mittleren Hauswerte aufweisen (Cluster 0 und 2), die höher sind als die Preise im zentralen Cluster (Cluster 1).
Wir können die Leistung des Clustering-Algorithmus mithilfe des Silhouette-Scores bewerten, der Teil von sklearn.metrics ist und bei dem ein niedrigerer Score für eine bessere Anpassung steht.
from sklearn.metrics import silhouette_score
silhouette_score(X_train_norm, kmeans.labels_, metric='euclidean')Da wir die Stärke der verschiedenen Clusterzahlen nicht untersucht haben, wissen wir nicht, wie gut das Modell k = 3 passt. Im nächsten Abschnitt werden wir verschiedene Cluster untersuchen und die Leistung vergleichen, um eine Entscheidung über die besten Hyperparameterwerte für unser Modell zu treffen.
Die Schwäche des k-means Clustering ist, dass wir nicht wissen, wie viele Cluster wir brauchen, wenn wir das Modell ausführen. Wir müssen verschiedene Wertebereiche testen und eine Entscheidung über den besten Wert von k treffen. In der Regel treffen wir eine Entscheidung mithilfe der Elbow-Methode, um die optimale Anzahl von Clustern zu bestimmen, bei der wir die Daten nicht mit zu vielen Clustern übererfüllen, aber auch nicht mit zu wenigen untererfüllen.
Wir erstellen die folgende Schleife, um verschiedene Modellergebnisse zu testen und zu speichern, damit wir eine Entscheidung über die beste Anzahl von Clustern treffen können.
K = range(2, 8)
fits = []
score = []
for k in K:
# train the model for current value of k on training data
model = KMeans(n_clusters = k, random_state = 0, n_init='auto').fit(X_train_norm)
# append the model to fits
fits.append(model)
# Append the silhouette score to scores
score.append(silhouette_score(X_train_norm, model.labels_, metric='euclidean'))Dann können wir zunächst einige verschiedene Werte von k visuell betrachten.
Zunächst betrachten wir k = 2.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[0].labels_)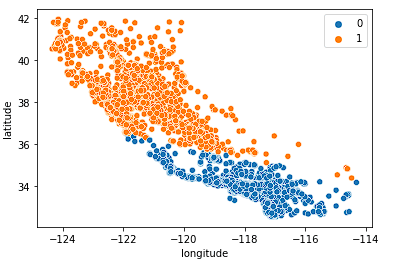
Das Modell leistet gute Arbeit bei der Aufteilung des Staates in zwei Hälften, erfasst aber wahrscheinlich nicht genug Nuancen des kalifornischen Wohnungsmarktes.
Als Nächstes betrachten wir k = 4.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)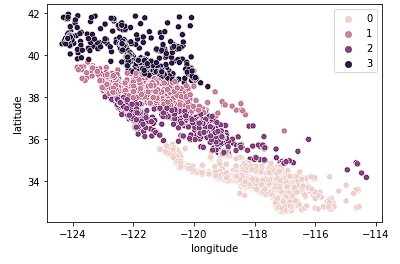
Wir sehen, dass diese Grafik Kalifornien in logischere Gruppen einteilt, je nachdem, wie weit nördlich oder südlich die Häuser im Bundesstaat liegen. Dieses Modell erfasst höchstwahrscheinlich mehr Nuancen auf dem Wohnungsmarkt, wenn wir uns durch den Staat bewegen.
Zum Schluss betrachten wir k = 7.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)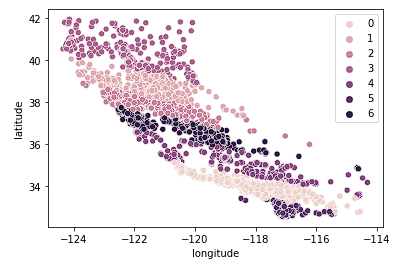
Das obige Diagramm scheint zu viele Cluster zu haben. Wir haben auf eine einfache Interpretation der Cluster verzichtet, um ein "genaueres" Geo-Clustering-Ergebnis zu erhalten.
Wenn wir den Wert von K erhöhen, sehen wir in der Regel Verbesserungen bei den Clustern und dem, was sie darstellen, bis zu einem bestimmten Punkt. Wir sehen dann, dass die Erträge abnehmen oder die Leistung sogar noch schlechter wird. Wir können dies visuell darstellen, um eine Entscheidung über den Wert von k zu treffen, indem wir ein Ellbogendiagramm verwenden, bei dem die y-Achse ein Maß für die Anpassungsgüte und die x-Achse der Wert von k ist.
sns.lineplot(x = K, y = score)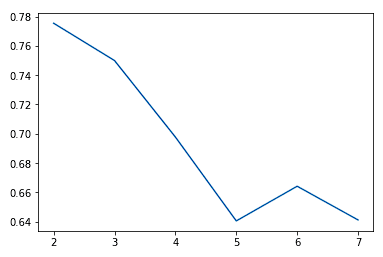
In der Regel wählen wir den Punkt, an dem die Leistungsverbesserung abflacht oder schlechter wird. Wir sehen, dass k = 5 wahrscheinlich das Beste ist, was wir tun können, ohne uns zu sehr anzupassen.
Wir können auch sehen, dass die Cluster Kalifornien relativ gut in verschiedene Cluster aufteilen und diese Cluster relativ gut den verschiedenen Preisklassen zugeordnet werden können (siehe unten).
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[3].labels_)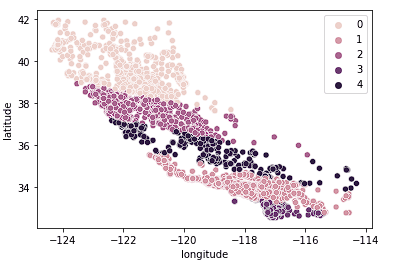
sns.boxplot(x = fits[3].labels_, y = y_train['median_house_value'])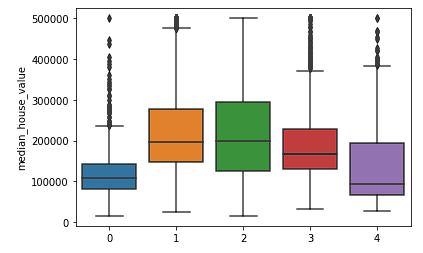
Das K-Means-Clustering funktioniert am besten bei Daten, die kugelförmig sind. Sphärische Daten sind Daten, die sich im Raum in unmittelbarer Nähe zueinander gruppieren. Das lässt sich im 2- oder 3-dimensionalen Raum leichter visualisieren. Daten, die nicht kugelförmig sind oder nicht kugelförmig sein sollten, funktionieren nicht gut mit dem k-means Clustering. Das k-means Clustering würde zum Beispiel bei den folgenden Daten nicht gut funktionieren, da wir keine eindeutigen Zentren finden könnten, um die beiden Kreise oder Bögen unterschiedlich zu clustern, obwohl es sich visuell eindeutig um zwei unterschiedliche Kreise und Bögen handelt, die als solche gekennzeichnet werden sollten.
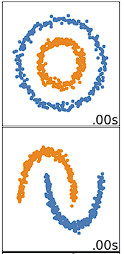
Es gibt viele andere Clustering-Algorithmen, die gute Arbeit beim Clustern von nicht-sphärischen Daten leisten. Diese werden in Clustering in Machine Learning behandelt: 5 Wesentliche Clustering-Algorithmen.
Die Entscheidung über die Aufteilung deiner Daten hängt davon ab, welche Ziele du mit dem Clustering verfolgst. Wenn das Ziel ist, deine Daten am Ende deiner Analyse zu clustern, ist das nicht notwendig. Wenn du die Cluster als Merkmal in einem überwachten Lernmodell oder für Vorhersagen verwendest (wie wir es im Scikit-Learn Tutorial tun): Baseball Analytics Pt 1 tutorial), dann musst du deine Daten vor dem Clustering aufteilen, um sicherzustellen, dass du die Best Practices für den Workflow des überwachten Lernens befolgst.
Nachdem wir nun die Grundlagen des k-means Clustering in Python behandelt haben, kannst du dir diesen Kurs über unüberwachtes Lernen in Python ansehen, um eine gute Einführung in k-means und andere unüberwachte Lernalgorithmen zu erhalten. Unser Kurs für Fortgeschrittene, Clusteranalyse in Python, gibt einen tieferen Einblick in Clustering-Algorithmen und wie man sie in Python erstellt und optimiert. Schließlich kannst du dir auch das Tutorial An Introduction to Hierarchical Clustering in Python ansehen, in dem ein alternativer Algorithmus verwendet wird, um Hierarchien aus Daten zu erstellen.
Erfahre mehr über Maschinelles Lernen
Kurs
Kurs
Kurs
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Aditya Sharma
Tutorial
Derrick Mwiti
