Cluster Analysis in Python
BasicSkill Level
4 Hr
64.9K learners

Clusteringmodellen proberen data in afzonderlijke “clusters” of groepen te verdelen. Dit kan zowel een interessante kijk geven in een analyse, als dienen als feature in een superviseerd leeralgoritme.
Denk aan een sociale setting waarin groepjes mensen in verschillende cirkels door de ruimte met elkaar praten. Als je de kamer binnenkomt, zie je gewoon een groep mensen. Je kunt mentaal punten plaatsen in het midden van elk groepje en dat punt een unieke naam geven. Vervolgens kun je naar elke groep verwijzen met een unieke naam om ze te beschrijven. Dit is in essentie wat k-means-clustering met data doet.
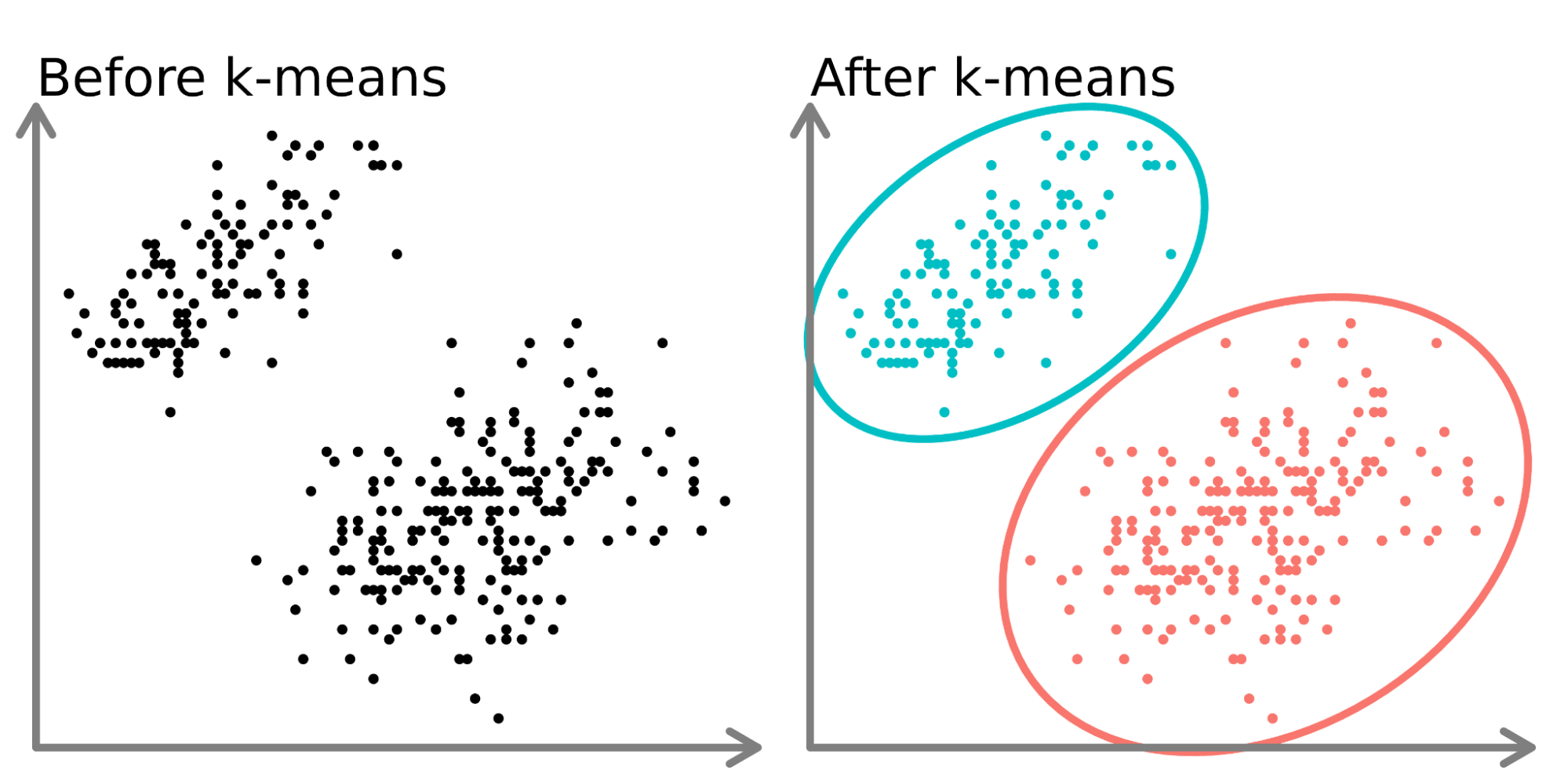
Links in het diagram hierboven zien we twee duidelijke verzamelingen punten die ongetagd zijn en dezelfde kleur hebben als soortgelijke datapunten. Door een k-means-model op deze data te fitten (rechts) komen er twee duidelijke groepen naar voren (weergegeven in verschillende cirkels en kleuren).
In twee dimensies is het voor mensen eenvoudig om deze clusters te scheiden, maar met meer dimensies heb je een model nodig.
In deze tutorial gebruiken we woningdata uit Californië van Kaggle (hier). We gebruiken locatiegegevens (breedte- en lengtegraad) en de mediane woningwaarde. We clusteren de huizen op locatie en bekijken hoe de huizenprijzen door Californië heen variëren. We slaan de dataset op als een csv-bestand met de naam ‘housing.csv’ in onze werkmap en lezen het in met pandas.
import pandas as pd
home_data = pd.read_csv('housing.csv', usecols = ['longitude', 'latitude', 'median_house_value'])
home_data.head()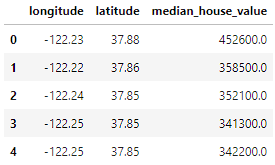
De data bevatten 3 variabelen die we hebben geselecteerd met de parameter usecols:
Net als andere machinelearningalgoritmen heeft k-means-clustering een workflow (zie A Beginner's Guide to The Machine Learning Workflow voor een uitgebreidere uitleg van de machinelearningworkflow).
In deze tutorial focussen we op het verzamelen en splitsen van de data (in datavoorbereiding) en op hyperparametertuning, het trainen van je model en het beoordelen van de modelprestatie (in modellering). Bij unsupervised learning zit veel werk in het tunen van hyperparameters en het beoordelen van de prestaties om het maximale uit je model te halen.
We beginnen met het visualiseren van onze woningdata. We bekijken de locatiegegevens met een heatmap op basis van de mediane prijs in een blok. We gebruiken Seaborn om snel grafieken te maken in deze tutorial (bekijk onze cursus Introduction to Data Visualization with Seaborn om beter te begrijpen hoe deze grafieken worden gemaakt).
import seaborn as sns
sns.scatterplot(data = home_data, x = 'longitude', y = 'latitude', hue = 'median_house_value')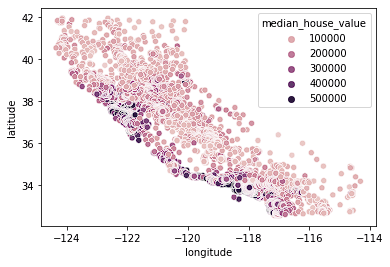
We zien dat de meeste dure huizen aan de westkust van Californië staan, met verschillende gebieden met clusters van huizen in de middenprijsklasse. Dat is te verwachten, omdat woningen aan het water doorgaans meer waard zijn dan huizen die niet aan de kust liggen.
Clusters zijn vaak makkelijk te herkennen wanneer je slechts 2 of 3 features gebruikt. Het wordt steeds moeilijker of zelfs onmogelijk wanneer de
Bij afstandsgebaseerde algoritmen, zoals k-means-clustering, moeten we de data normaliseren. Als we de data niet normaliseren, krijgen variabelen met een andere schaal een verschillend gewicht in de afstandsformule die tijdens het trainen wordt geoptimaliseerd. Als we bijvoorbeeld naast breedte- en lengtegraad ook prijs in de cluster zouden opnemen, zou prijs een onevenredig grote invloed hebben op de optimalisaties, omdat de schaal veel groter en breder is dan die van de begrensde locatievariabelen.
We maken eerst trainings- en testsplitsingen met train_test_split uit sklearn.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(home_data[['latitude', 'longitude']], home_data[['median_house_value']], test_size=0.33, random_state=0)Vervolgens normaliseren we de trainings- en testdata met de methode preprocessing.normalize() uit sklearn.
from sklearn import preprocessing
X_train_norm = preprocessing.normalize(X_train)
X_test_norm = preprocessing.normalize(X_test)Voor de eerste iteratie kiezen we willekeurig een aantal clusters (k) van 3. Modellen bouwen en fitten in sklearn is heel eenvoudig. We maken een instantie van KMeans, geven het aantal clusters op met het attribuut n_clusters, zetten n_init (het aantal iteraties dat het algoritme draait met verschillende centroid-seeds) op “auto”, en zetten random_state op 0 zodat we telkens hetzelfde resultaat krijgen. Daarna fitten we het model op de genormaliseerde trainingsdata met de methode fit().
from sklearn import KMeans
kmeans = KMeans(n_clusters = 3, random_state = 0, n_init='auto')
kmeans.fit(X_train_norm)Zodra de data zijn gefit, kunnen we de labels benaderen via het attribuut labels_. Hieronder visualiseren we de zojuist gefitte data.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = kmeans.labels_)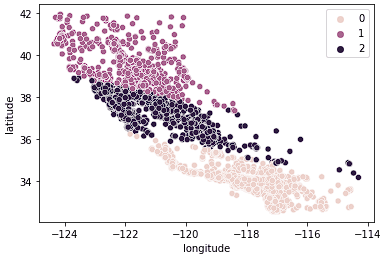
We zien dat de data nu duidelijk in 3 afzonderlijke groepen zijn opgesplitst (Noord-Californië, Centraal-Californië en Zuid-Californië). We kunnen ook de verdeling van mediane woningprijzen in deze 3 groepen bekijken met een boxplot.
sns.boxplot(x = kmeans.labels_, y = y_train['median_house_value'])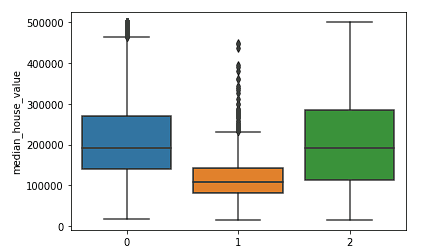
We zien duidelijk dat de noordelijke en zuidelijke clusters vergelijkbare verdelingen van mediane woningwaarden hebben (clusters 0 en 2) die hoger liggen dan de prijzen in het centrale cluster (cluster 1).
We kunnen de prestaties van het clusteringsalgoritme evalueren met een Silhouette-score, onderdeel van sklearn.metrics, waarbij een lagere score een betere fit vertegenwoordigt.
from sklearn.metrics import silhouette_score
silhouette_score(X_train_norm, kmeans.labels_, metric='euclidean')Omdat we nog niet hebben gekeken naar de sterkte van verschillende aantallen clusters, weten we niet hoe goed de fit van het model met k = 3 is. In de volgende sectie verkennen we verschillende aantallen clusters en vergelijken we de prestaties om te beslissen over de beste hyperparametervalue(s) voor ons model.
De zwakte van k-means-clustering is dat we niet weten hoeveel clusters we nodig hebben door het model simpelweg te draaien. We moeten een reeks waarden testen en beslissen over de beste waarde voor k. Meestal gebruiken we de elbow-methode om het optimale aantal clusters te bepalen, waarbij we zowel overfitting met te veel clusters als underfitting met te weinig vermijden.
We maken onderstaande lus om verschillende modelresultaten te testen en op te slaan, zodat we een beslissing kunnen nemen over het beste aantal clusters.
K = range(2, 8)
fits = []
score = []
for k in K:
# train the model for current value of k on training data
model = KMeans(n_clusters = k, random_state = 0, n_init='auto').fit(X_train_norm)
# append the model to fits
fits.append(model)
# Append the silhouette score to scores
score.append(silhouette_score(X_train_norm, model.labels_, metric='euclidean'))We kunnen dan eerst visueel naar een paar verschillende waarden van k kijken.
Eerst kijken we naar k = 2.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[0].labels_)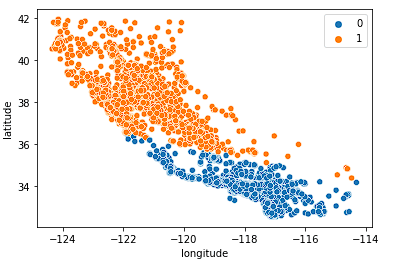
Het model doet een redelijke poging om de staat in twee helften te splitsen, maar vangt waarschijnlijk niet genoeg nuance in de woningmarkt van Californië.
Vervolgens kijken we naar k = 4.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)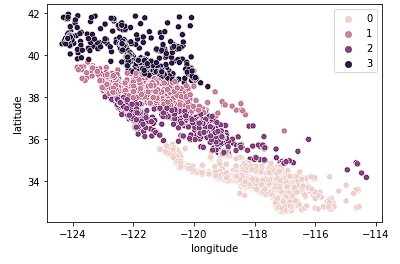
We zien dat deze plot Californië in logischere clusters groepeert op basis van hoe ver naar het noorden of zuiden de huizen in de staat liggen. Dit model vangt waarschijnlijk meer nuance in de woningmarkt naarmate we door de staat bewegen.
Tot slot kijken we naar k = 7.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[2].labels_)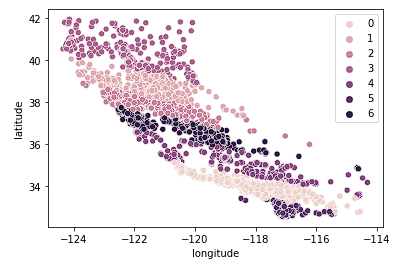
De bovenstaande grafiek lijkt te veel clusters te hebben. We hebben de eenvoudige interpretatie van de clusters opgeofferd voor een “nauwkeuriger” geo-clusteringresultaat.
Meestal zien we, naarmate we de waarde van K verhogen, verbeteringen in clusters en wat ze representeren tot op zekere hoogte. Daarna treden afnemende meeropbrengsten of zelfs slechtere prestaties op. We kunnen dit visueel inzichtelijk maken om een beslissing over de waarde van k te nemen met een elbow-plot, waarbij de y-as een maat is voor goodness of fit en de x-as de waarde van k.
sns.lineplot(x = K, y = score)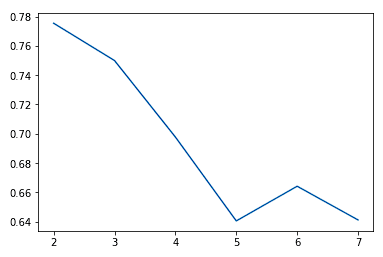
We kiezen doorgaans het punt waar de prestatieverbeteringen beginnen af te vlakken of slechter worden. We zien dat k = 5 waarschijnlijk het beste is wat we kunnen doen zonder te overfitten.
We zien ook dat de clusters het redelijk goed doen in het opdelen van Californië in duidelijke clusters en dat deze clusters redelijk goed overeenkomen met verschillende prijsklassen, zoals hieronder te zien is.
sns.scatterplot(data = X_train, x = 'longitude', y = 'latitude', hue = fits[3].labels_)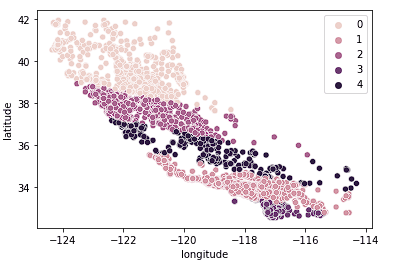
sns.boxplot(x = fits[3].labels_, y = y_train['median_house_value'])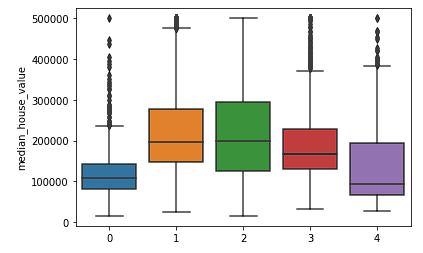
K-means-clustering presteert het best op data die sferisch zijn. Sferische data zijn data die in de ruimte dicht bij elkaar groeperen. Dit is in 2 of 3 dimensies eenvoudiger te visualiseren. Data die niet sferisch zijn of niet sferisch zouden moeten zijn, werken minder goed met k-means-clustering. K-means-clustering zou bijvoorbeeld niet goed werken op onderstaande data, omdat we geen duidelijke centroiden kunnen vinden om de twee cirkels of bogen verschillend te clusteren, hoewel het visueel duidelijk twee verschillende cirkels en bogen zijn die ook zo gelabeld zouden moeten worden.
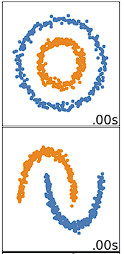
Er zijn veel andere clusteringsalgoritmen die niet-sferische data goed clusteren, behandeld in Clustering in Machine Learning: 5 Essential Clustering Algorithms.
De beslissing om je data te splitsen hangt af van je doelen voor clustering. Als het doel is om je data te clusteren als eindpunt van je analyse, dan is het niet nodig. Als je de clusters gebruikt als feature in een superviseerd leermodel of voor voorspellingen (zoals we doen in de tutorial Scikit-Learn Tutorial: Baseball Analytics Pt 1), dan moet je je data voorafgaand aan het clusteren splitsen om best practices voor de superviseerde leerworkflow te volgen.
Nu we de basis van k-means-clustering in Python hebben behandeld, kun je deze cursus Unsupervised Learning in Python bekijken voor een goede introductie tot k-means en andere unsupervised leeralgoritmen. Onze meer geavanceerde cursus Cluster Analysis in Python gaat dieper in op clusteringsalgoritmen en hoe je ze in Python bouwt en finetunet. Bekijk tenslotte ook de tutorial An Introduction to Hierarchical Clustering in Python als een aanpak die een alternatief algoritme gebruikt om hiërarchieën uit data te maken.
Meer leren over machine learning
Cursus
Cursus
Cursus