
Kursus
Machine Learning untuk Bisnis
2 Hr
46.7K
Jaringan saraf atau jaringan saraf tiruan adalah alat fundamental dalam machine learning, menggerakkan banyak algoritme dan aplikasi mutakhir di berbagai domain, termasuk visi komputer, pemrosesan bahasa alami, robotika, dan lainnya.
Sebuah jaringan saraf terdiri dari node-node yang saling terhubung, disebut neuron, yang disusun dalam lapisan. Setiap neuron menerima sinyal masukan, melakukan komputasi atasnya menggunakan fungsi aktivasi, dan menghasilkan sinyal keluaran yang dapat diteruskan ke neuron lain dalam jaringan. Sebuah fungsi aktivasi menentukan keluaran sebuah neuron berdasarkan masukannya. Fungsi-fungsi ini memperkenalkan nonlinieritas ke dalam jaringan, memungkinkannya mempelajari pola kompleks dalam data.
Jaringan biasanya disusun dalam lapisan, dimulai dengan lapisan input, tempat data dimasukkan. Dilanjutkan dengan hidden layer tempat komputasi dilakukan dan akhirnya lapisan output tempat prediksi atau keputusan dibuat.
Neuron pada lapisan yang berdekatan dihubungkan oleh koneksi berbobot, yang mentransmisikan sinyal dari satu lapisan ke lapisan berikutnya. Kekuatan koneksi ini, yang direpresentasikan oleh bobot, menentukan seberapa besar pengaruh keluaran satu neuron terhadap masukan neuron lainnya. Selama proses pelatihan, jaringan belajar menyesuaikan bobotnya berdasarkan contoh yang disediakan dalam dataset pelatihan. Selain itu, setiap neuron biasanya memiliki bias terkait, yang memungkinkan neuron menyesuaikan ambang keluarannya.
Jaringan saraf dilatih menggunakan teknik yang disebut propagasi maju (feedforward) dan backpropagation. Selama feedforward, data masukan dilewatkan melalui jaringan lapis demi lapis, dengan setiap lapisan melakukan komputasi berdasarkan masukan yang diterimanya dan meneruskan hasilnya ke lapisan berikutnya.
Backpropagation adalah algoritme yang digunakan untuk melatih jaringan saraf dengan menyesuaikan bobot dan bias jaringan secara iteratif guna meminimalkan fungsi loss. Fungsi loss (juga dikenal sebagai cost function atau objective function) adalah ukuran seberapa baik prediksi model sesuai dengan nilai target sebenarnya dalam data pelatihan. Fungsi loss mengkuantifikasi perbedaan antara keluaran yang diprediksi model dan keluaran aktual, memberikan sinyal yang memandu proses optimisasi selama pelatihan.
Tujuan pelatihan jaringan saraf adalah meminimalkan fungsi loss ini dengan menyesuaikan bobot dan bias. Penyesuaian dipandu oleh algoritme optimisasi, seperti gradient descent. Kita akan meninjau kembali beberapa topik ini secara lebih rinci nanti dalam tutorial ini.
Neuron biologis vs. jaringan saraf tiruan (Sumber: ResearchGate)
ANN yang ditampilkan di sebelah kanan gambar adalah jaringan saraf sederhana yang disebut ‘perceptron’. Ia terdiri dari satu lapisan, yaitu lapisan input, dengan banyak neuron yang memiliki bobot masing-masing; tidak ada hidden layer. Algoritme perceptron mempelajari bobot untuk sinyal input guna menggambar batas keputusan linear.
Namun, untuk menyelesaikan masalah yang lebih rumit dan nonlinier terkait pemrosesan citra, visi komputer, dan tugas pemrosesan bahasa alami, kita menggunakan deep neural networks.
Lihat tutorial Introduction to Deep Neural Networks kami untuk mempelajari lebih lanjut tentang deep neural networks dan cara membangunnya dari awal, menggunakan TensorFlow dan Keras di Python. Jika Anda lebih memilih menggunakan bahasa R, panduan kami Building Neural Network (NN) Models in R siap membantu.
Ada beberapa jenis ANN, masing-masing dirancang untuk tugas dan kebutuhan arsitektur tertentu. Mari kita bahas secara singkat beberapa jenis yang paling umum sebelum mendalami MLP berikutnya.
Ini adalah bentuk ANN yang paling sederhana, di mana informasi mengalir satu arah, dari input ke output. Tidak ada siklus atau loop dalam arsitektur jaringan. Multilayer perceptron (MLP) adalah jenis jaringan saraf feedforward.
Dalam RNN, koneksi antar node membentuk siklus terarah, memungkinkan informasi bertahan seiring waktu. Ini membuatnya cocok untuk tugas yang melibatkan data berurutan, seperti prediksi deret waktu, pemrosesan bahasa alami, dan pengenalan suara.
CNN dirancang untuk memroses data yang berbentuk grid secara efektif, seperti gambar. CNN terdiri dari lapisan filter konvolusi yang mempelajari representasi hierarkis fitur dalam data masukan. CNN banyak digunakan pada tugas seperti klasifikasi gambar, deteksi objek, dan segmentasi gambar.
Ini adalah jenis jaringan saraf rekuren khusus yang dirancang untuk mengatasi masalah vanishing gradient pada RNN tradisional. LSTM dan GRU menggabungkan mekanisme gerbang untuk menangkap dependensi jarak jauh dalam data berurutan dengan lebih baik, sehingga sangat efektif untuk tugas seperti pengenalan suara, penerjemahan mesin, dan analisis sentimen.
Model ini dirancang untuk pembelajaran tanpa pengawasan dan terdiri dari jaringan encoder yang memampatkan data masukan ke ruang laten berdimensi lebih rendah, serta jaringan decoder yang merekonstruksi masukan asli dari representasi laten tersebut. Autoencoder sering digunakan untuk reduksi dimensi, pembersihan noise data, dan pemodelan generatif.
GAN terdiri dari dua jaringan saraf, generator dan discriminator, yang dilatih secara bersamaan dalam pengaturan kompetitif. Generator belajar menghasilkan sampel data sintetis yang tak terbedakan dari data nyata, sementara discriminator belajar membedakan antara sampel asli dan palsu. GAN banyak digunakan untuk menghasilkan gambar, video, dan jenis data lain yang realistis.
Multilayer perceptron adalah jenis jaringan saraf feedforward yang terdiri dari neuron-neuron yang sepenuhnya terhubung dengan fungsi aktivasi nonlinier. Model ini banyak digunakan untuk membedakan data yang tidak dapat dipisahkan secara linear.
MLP telah banyak digunakan di berbagai bidang, termasuk pengenalan gambar, pemrosesan bahasa alami, dan pengenalan suara, di antaranya. Fleksibilitas arsitektur dan kemampuannya untuk mengaproksimasi fungsi apa pun di bawah kondisi tertentu menjadikannya blok bangunan fundamental dalam riset deep learning dan jaringan saraf. Mari kita telusuri lebih dalam beberapa konsep kuncinya.
Lapisan input terdiri atas node atau neuron yang menerima data masukan awal. Setiap neuron mewakili fitur atau dimensi data masukan. Jumlah neuron pada lapisan input ditentukan oleh dimensi data masukan.
Di antara lapisan input dan output, dapat terdapat satu atau lebih lapisan neuron. Setiap neuron pada hidden layer menerima masukan dari semua neuron di lapisan sebelumnya (baik lapisan input atau hidden layer lainnya) dan menghasilkan keluaran yang diteruskan ke lapisan berikutnya. Jumlah hidden layer dan jumlah neuron pada setiap hidden layer adalah hiperparameter yang perlu ditentukan pada tahap perancangan model.
Lapisan ini terdiri dari neuron-neuron yang menghasilkan keluaran akhir jaringan. Jumlah neuron pada lapisan output bergantung pada sifat tugasnya. Pada klasifikasi biner, dapat ada satu atau dua neuron bergantung pada fungsi aktivasi dan mewakili probabilitas milik salah satu kelas; sedangkan pada tugas klasifikasi multikelas, dapat ada beberapa neuron pada lapisan output.
Neuron pada lapisan yang berdekatan terhubung penuh satu sama lain. Setiap koneksi memiliki bobot terkait, yang menentukan kekuatan koneksi. Bobot-bobot ini dipelajari selama proses pelatihan.
Selain neuron input dan hidden, setiap lapisan (kecuali lapisan input) biasanya menyertakan neuron bias yang memberikan masukan konstan ke neuron di lapisan berikutnya. Neuron bias memiliki bobotnya sendiri pada setiap koneksi, yang juga dipelajari selama pelatihan.
Neuron bias secara efektif menggeser fungsi aktivasi neuron pada lapisan berikutnya, memungkinkan jaringan mempelajari offset atau bias pada batas keputusan. Dengan menyesuaikan bobot yang terhubung ke neuron bias, MLP dapat mempelajari cara mengendalikan ambang aktivasi dan menyesuaikan data pelatihan dengan lebih baik.
Catatan: Penting untuk dicatat bahwa dalam konteks MLP, bias dapat merujuk pada dua konsep yang terkait namun berbeda: bias sebagai istilah umum dalam machine learning dan neuron bias (didefinisikan di atas). Dalam machine learning secara umum, bias merujuk pada kesalahan yang diperkenalkan saat mendekati masalah dunia nyata dengan model yang disederhanakan. Bias mengukur seberapa baik model dapat menangkap pola yang mendasari dalam data. Bias yang tinggi menunjukkan bahwa model terlalu sederhana dan mungkin underfit terhadap data, sementara bias yang rendah menunjukkan bahwa model menangkap pola yang mendasari dengan baik.
Biasanya, setiap neuron pada hidden layer dan lapisan output menerapkan fungsi aktivasi pada jumlah berbobot dari masukannya. Fungsi aktivasi yang umum termasuk sigmoid, tanh, ReLU (Rectified Linear Unit), dan softmax. Fungsi-fungsi ini memperkenalkan nonlinieritas ke dalam jaringan, memungkinkannya mempelajari pola yang kompleks dalam data.
MLP dilatih menggunakan algoritme backpropagation, yang menghitung gradien dari fungsi loss terhadap parameter model dan memperbarui parameter secara iteratif untuk meminimalkan loss.
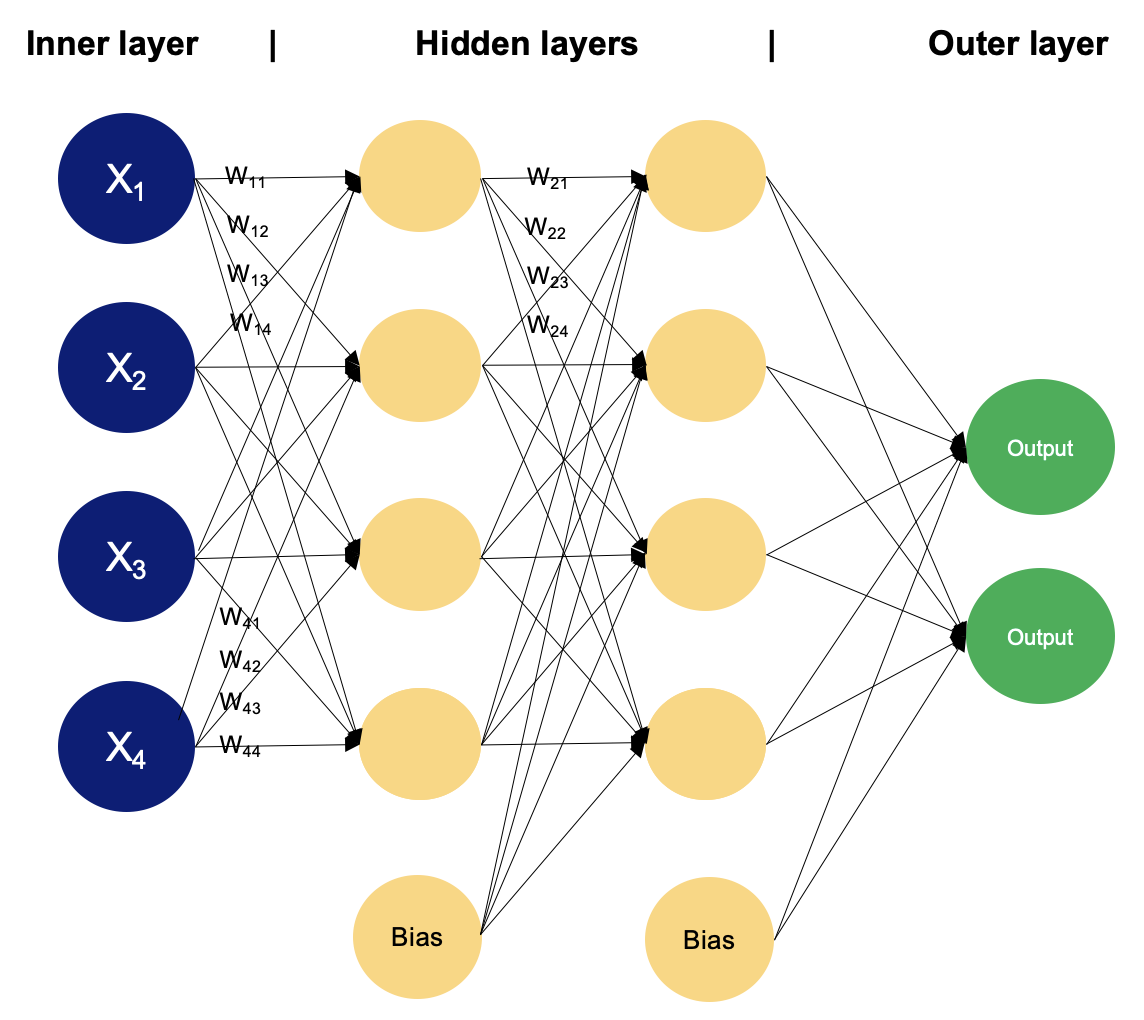
Contoh MLP dengan dua hidden layer. Gambar oleh Penulis
Dalam multilayer perceptron, neuron memproses informasi secara bertahap, melakukan komputasi yang melibatkan jumlah berbobot dan transformasi nonlinier. Mari kita telusuri lapis demi lapis untuk melihat apa yang terjadi di dalamnya.
w. Bobot menentukan seberapa besar pengaruh masukan dari satu neuron terhadap keluaran neuron lainnya.b. Bias memberikan masukan tambahan ke neuron, memungkinkan neuron menyesuaikan ambang keluarannya. Seperti halnya bobot, bias dipelajari selama pelatihan.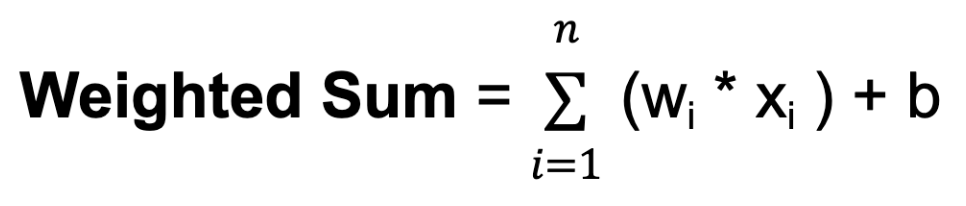
Di mana n adalah jumlah total koneksi masukan, wi adalah bobot untuk masukan ke-i, dan xi adalah nilai masukan ke-i.
f. Fungsi aktivasi memperkenalkan nonlinieritas ke dalam jaringan, memungkinkannya mempelajari dan merepresentasikan hubungan kompleks dalam data. Fungsi aktivasi menentukan rentang keluaran neuron dan perilakunya terhadap berbagai nilai masukan. Pemilihan fungsi aktivasi bergantung pada sifat tugas dan karakteristik yang diinginkan dari jaringan.Selama proses pelatihan, jaringan belajar menyesuaikan bobot yang terkait dengan masukan tiap neuron untuk meminimalkan perbedaan antara keluaran yang diprediksi dan nilai target sebenarnya dalam data pelatihan. Dengan menyesuaikan bobot dan mempelajari fungsi aktivasi yang tepat, jaringan belajar mengaproksimasi pola dan hubungan kompleks dalam data, memungkinkannya membuat prediksi akurat pada sampel baru yang belum pernah dilihat.
Penyesuaian ini dipandu oleh algoritme optimisasi, seperti stochastic gradient descent (SGD), yang menghitung gradien dari fungsi loss terhadap bobot dan memperbarui bobot secara iteratif.
Mari kita lihat lebih dekat bagaimana SGD bekerja.
θₜ₊₁ = θₜ − η ∇J(θₜ)Di mana:
θₜ merepresentasikan parameter model (misalnya, bobot dan bias) pada iterasi t
∇J(θₜ) adalah gradien dari fungsi loss J terhadap parameter pada iterasi t
η (eta) adalah laju pembelajaran, yang mengendalikan ukuran langkah selama optimisasi
n. Parameter ini mengendalikan besar langkah menuju minimum. Jika laju pembelajaran terlalu kecil, konvergensi mungkin lambat; jika terlalu besar, algoritme dapat berosilasi atau divergen.Stochastic gradient descent memperbarui parameter model lebih sering menggunakan subset data yang lebih kecil, menjadikannya efisien secara komputasi, terutama untuk dataset besar. Keacakan yang diperkenalkan oleh SGD dapat memiliki efek regularisasi, mencegah model overfit terhadap data pelatihan. Metode ini juga sangat cocok untuk skenario pembelajaran daring (online learning) di mana data baru tersedia secara bertahap, karena model dapat diperbarui dengan cepat untuk setiap titik data atau mini-batch baru.
Namun, SGD juga memiliki beberapa tantangan, seperti meningkatnya noise karena sifat stokastik dari estimasi gradien dan perlunya menyetel hiperparameter seperti laju pembelajaran. Berbagai ekstensi dan adaptasi SGD, seperti mini-batch stochastic gradient descent, momentum, dan metode laju pembelajaran adaptif seperti AdaGrad, RMSProp, dan Adam, telah dikembangkan untuk mengatasi tantangan ini dan meningkatkan konvergensi serta kinerja.
Anda telah melihat cara kerja lapisan multilayer perceptron dan mempelajari stochastic gradient descent; untuk menyatukan semuanya, masih ada satu topik terakhir untuk dibahas: backpropagation.
Backpropagation adalah kependekan dari “backward propagation of errors.” Dalam konteks backpropagation, SGD melibatkan pembaruan parameter jaringan secara iteratif berdasarkan gradien yang dihitung selama setiap batch data pelatihan. Alih-alih menghitung gradien menggunakan seluruh dataset pelatihan (yang bisa sangat mahal secara komputasi untuk dataset besar), SGD menghitung gradien menggunakan subset kecil acak dari data yang disebut mini-batch. Berikut gambaran umum cara kerja algoritme backpropagation:
Menyiapkan data untuk melatih MLP melibatkan pembersihan, prapemrosesan, penskalaan, pembagian, pemformatan, dan mungkin juga augmentasi data. Berdasarkan fungsi aktivasi yang digunakan dan skala fitur masukan, data mungkin perlu distandardisasi atau dinormalisasi. Mencoba berbagai teknik prapemrosesan dan mengevaluasi dampaknya terhadap kinerja model sering kali diperlukan untuk menentukan pendekatan yang paling sesuai untuk dataset dan tugas tertentu.
Untuk mempelajari lebih lanjut tentang penskalaan fitur, lihat kursus Datacamp Feature Engineering for Machine Learning in Python.
Mengimplementasikan MLP melibatkan beberapa langkah, mulai dari prapemrosesan data hingga pelatihan dan evaluasi model. Memilih jumlah lapisan dan neuron untuk MLP melibatkan penyeimbangan antara kompleksitas model, waktu pelatihan, dan performa generalisasi. Tidak ada satu jawaban yang cocok untuk semua, karena arsitektur optimal bergantung pada faktor seperti kompleksitas tugas, jumlah data yang tersedia, dan sumber daya komputasi. Namun, berikut beberapa panduan umum yang perlu dipertimbangkan saat mengimplementasikan MLP:
Sebelum memilih MLP untuk proyek Anda, ada baiknya memahami di mana model ini unggul dan kapan arsitektur lain mungkin lebih cocok.
Multilayer perceptron merepresentasikan kelas jaringan saraf tiruan yang fundamental dan serbaguna yang telah berkontribusi signifikan pada kemajuan machine learning dan kecerdasan buatan. Melalui lapisan-lapisan neuron yang saling terhubung dan fungsi aktivasi nonlinier, MLP mampu mempelajari pola dan hubungan yang kompleks dalam data, sehingga cocok untuk berbagai tugas. Sejarah MLP mencerminkan perjalanan eksplorasi, penemuan, dan inovasi, dari model perceptron awal hingga arsitektur deep learning modern yang menggerakkan banyak sistem mutakhir saat ini.
Dalam artikel ini, Anda telah mempelajari dasar-dasar jaringan saraf tiruan, berfokus pada multilayer perceptron, mempelajari stochastic gradient descent dan backpropagation. Jika Anda tertarik untuk mendapatkan pengalaman langsung dan menggunakan teknik deep learning untuk menyelesaikan tantangan dunia nyata, seperti memprediksi harga rumah, membangun jaringan saraf untuk memodelkan gambar dan teks - kami sangat merekomendasikan mengikuti Keras toolbox track dari Datacamp.
Bekerja dengan Keras, Anda akan mempelajari tentang jaringan saraf, alur kerja model deep learning, dan cara mengoptimalkan model Anda. Datacamp juga memiliki lembar contekan Keras yang bisa sangat berguna!
Mulai Perjalanan Machine Learning Anda Hari Ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
