
Cursus
Machine Learning voor Business
2 Hr
46.7K
Neurale netwerken of kunstmatige neurale netwerken zijn fundamentele tools in machine learning. Ze drijven veel state-of-the-art algoritmen en toepassingen in uiteenlopende domeinen, waaronder computervisie, natuurlijke taalverwerking, robotica en meer.
Een neuraal netwerk bestaat uit onderling verbonden knooppunten, neuronen genoemd, georganiseerd in lagen. Elke neuron ontvangt invoersignalen, voert er een berekening op uit met een activatiefunctie en produceert een uitvoersignaal dat kan worden doorgegeven aan andere neuronen in het netwerk. Een activatiefunctie bepaalt de output van een neuron gegeven zijn input. Deze functies introduceren niet-lineariteit in het netwerk, waardoor het complexe patronen in data kan leren.
Het netwerk is doorgaans georganiseerd in lagen, te beginnen met de invoerlaag, waar data wordt ingevoerd. Gevolgd door verborgen lagen waar berekeningen plaatsvinden en tot slot de uitvoerlaag waar voorspellingen of beslissingen worden gemaakt.
Neuronen in aangrenzende lagen zijn verbonden door gewogen verbindingen, die signalen van de ene naar de andere laag doorgeven. De sterkte van deze verbindingen, weergegeven door gewichten, bepaalt hoeveel invloed de output van de ene neuron heeft op de input van een andere. Tijdens het trainingsproces leert het netwerk zijn gewichten aan te passen op basis van voorbeelden in een trainingsdataset. Daarnaast heeft elke neuron meestal een bijbehorende bias, waarmee de neuron zijn outputdrempel kan aanpassen.
Neurale netwerken worden getraind met technieken die feedforward-propagatie en backpropagation worden genoemd. Tijdens feedforward-propagatie wordt invoerdata laag voor laag door het netwerk geleid, waarbij elke laag een berekening uitvoert op basis van de inputs die het ontvangt en het resultaat doorgeeft aan de volgende laag.
Backpropagation is een algoritme om neurale netwerken te trainen door iteratief de gewichten en biases van het netwerk aan te passen om de verliesfunctie te minimaliseren. Een verliesfunctie (ook wel kostenfunctie of doelfunctie) is een maat voor hoe goed de voorspellingen van het model overeenkomen met de echte doelwaarden in de trainingsdata. De verliesfunctie kwantificeert het verschil tussen de voorspelde output van het model en de werkelijke output en biedt zo een signaal dat het optimalisatieproces tijdens training aanstuurt.
Het doel van het trainen van een neuraal netwerk is deze verliesfunctie te minimaliseren door de gewichten en biases aan te passen. De aanpassingen worden geleid door een optimalisatie-algoritme, zoals gradient descent. We komen later in deze tutorial op enkele van deze onderwerpen terug in meer detail.
Biologische neuron vs. kunstmatig neuraal netwerk (Bron: ResearchGate)
De ANN rechts op de afbeelding is een eenvoudig neuraal netwerk, een ‘perceptron’ genoemd. Het bestaat uit één laag, de invoerlaag, met meerdere neuronen met hun eigen gewichten; er zijn geen verborgen lagen. Het perceptron-algoritme leert de gewichten voor de invoersignalen om een lineaire beslissingsgrens te trekken.
Voor het oplossen van meer ingewikkelde, niet-lineaire problemen rond beeldverwerking, computervisie en taken voor natuurlijke taalverwerking werken we echter met diepe neurale netwerken.
Bekijk onze Introduction to Deep Neural Networks-tutorial om meer te leren over diepe neurale netwerken en hoe je er zelf een vanaf nul opbouwt met TensorFlow en Keras in Python. Werk je liever met R, dan is onze Building Neural Network (NN) Models in R wat je zoekt.
Er zijn verschillende typen ANN, elk ontworpen voor specifieke taken en architecturale vereisten. Laten we kort enkele van de meest voorkomende typen bespreken voordat we straks dieper ingaan op MLP’s.
Dit zijn de eenvoudigste vormen van ANN’s, waarbij informatie in één richting stroomt, van input naar output. Er zijn geen cycli of lussen in de netwerkarchitectuur. Multilayer perceptrons (MLP) zijn een type feedforward neuraal netwerk.
In RNN’s vormen verbindingen tussen knooppunten gerichte cycli, waardoor informatie in de tijd kan blijven bestaan. Dit maakt ze geschikt voor taken met sequentiële data, zoals tijdreeksvoorspelling, natuurlijke taalverwerking en spraakherkenning.
CNN’s zijn ontworpen om roosterachtige data, zoals afbeeldingen, effectief te verwerken. Ze bestaan uit lagen van convolutiefilters die hiërarchische representaties van kenmerken binnen de invoerdata leren. CNN’s worden veel gebruikt voor taken als beeldclassificatie, objectdetectie en segmentatie.
Dit zijn gespecialiseerde typen recurrente neurale netwerken die het verdwijnende-gradiëntprobleem in traditionele RNN’s aanpakken. LSTM’s en GRU’s bevatten poortmechanismen om langeafstandsafhankelijkheden in sequentiële data beter vast te leggen, wat ze bijzonder effectief maakt voor taken zoals spraakherkenning, machinevertaling en sentimentanalyse.
Dit type is ontworpen voor unsupervised learning en bestaat uit een encodernetwerk dat de invoerdata comprimeert naar een lager-dimensionale latente ruimte, en een decodernetwerk dat de oorspronkelijke invoer reconstrueert uit de latente representatie. Autoencoders worden vaak gebruikt voor dimensionaliteitsreductie, ruisonderdrukking in data en generatieve modellering.
GAN’s bestaan uit twee neurale netwerken, een generator en een discriminator, die gelijktijdig in een competitieve setting worden getraind. De generator leert synthetische datamonsters te genereren die niet te onderscheiden zijn van echte data, terwijl de discriminator leert echte en nepvoorbeelden te onderscheiden. GAN’s worden veel gebruikt voor het genereren van realistische afbeeldingen, video’s en andere datatypen.
Een multilayer perceptron is een type feedforward neuraal netwerk dat bestaat uit volledig verbonden neuronen met een niet-lineaire activatiefunctie. Het wordt veel gebruikt om data te onderscheiden die niet lineair scheidbaar is.
MLP’s zijn op grote schaal gebruikt in diverse gebieden, waaronder beeldherkenning, natuurlijke taalverwerking en spraakherkenning. Hun flexibiliteit in architectuur en het vermogen om onder bepaalde voorwaarden elke functie te benaderen maken ze tot een fundamenteel bouwblok in deep learning en onderzoek naar neurale netwerken. Laten we dieper ingaan op enkele van de belangrijkste concepten.
De invoerlaag bestaat uit knooppunten of neuronen die de initiële invoerdata ontvangen. Elke neuron vertegenwoordigt een kenmerk of dimensie van de invoerdata. Het aantal neuronen in de invoerlaag wordt bepaald door de dimensionaliteit van de invoerdata.
Tussen de invoer- en uitvoerlaag kunnen één of meer lagen met neuronen zitten. Elke neuron in een verborgen laag ontvangt input van alle neuronen in de vorige laag (ofwel de invoerlaag of een andere verborgen laag) en produceert een output die wordt doorgegeven aan de volgende laag. Het aantal verborgen lagen en het aantal neuronen per verborgen laag zijn hyperparameters die tijdens het ontwerpproces van het model moeten worden bepaald.
Deze laag bestaat uit neuronen die de uiteindelijke output van het netwerk produceren. Het aantal neuronen in de uitvoerlaag hangt af van de aard van de taak. Bij binaire classificatie kan er één of twee neuronen zijn, afhankelijk van de activatiefunctie en de representatie van de kans op behoren tot een klasse; bij multiclass-classificatietaken kunnen er meerdere neuronen in de uitvoerlaag zitten.
Neuronen in aangrenzende lagen zijn volledig met elkaar verbonden. Elke verbinding heeft een bijbehorend gewicht, dat de sterkte van de verbinding bepaalt. Deze gewichten worden tijdens het trainingsproces geleerd.
Naast de invoer- en verborgen neuronen bevat elke laag (behalve de invoerlaag) meestal een bias-neuron dat een constante input levert aan de neuronen in de volgende laag. Bias-neuronen hebben hun eigen gewicht per verbinding, dat ook tijdens de training wordt geleerd.
Het bias-neuron verschuift effectief de activatiefunctie van de neuronen in de daaropvolgende laag, waardoor het netwerk een offset of bias in de beslissingsgrens kan leren. Door de gewichten die met het bias-neuron verbonden zijn aan te passen, kan de MLP de activatiedrempel regelen en de trainingsdata beter fitten.
Let op: In de context van MLP’s kan bias verwijzen naar twee gerelateerde maar verschillende concepten: bias als algemene term in machine learning en het bias-neuron (hierboven gedefinieerd). In algemene machine learning verwijst bias naar de fout die wordt geïntroduceerd door een reëel wereldprobleem te benaderen met een vereenvoudigd model. Bias meet in hoeverre het model de onderliggende patronen in de data kan vastleggen. Een hoge bias geeft aan dat het model te simpel is en mogelijk underfit; een lage bias suggereert dat het model de onderliggende patronen goed vastlegt.
Meestal past elke neuron in de verborgen lagen en de uitvoerlaag een activatiefunctie toe op zijn gewogen som van inputs. Veelgebruikte activatiefuncties zijn sigmoid, tanh, ReLU (Rectified Linear Unit) en softmax. Deze functies introduceren niet-lineariteit in het netwerk, waardoor het complexe patronen in de data kan leren.
MLP’s worden getraind met het backpropagation-algoritme, dat gradiënten van een verliesfunctie ten opzichte van de parameters van het model berekent en de parameters iteratief bijwerkt om het verlies te minimaliseren.
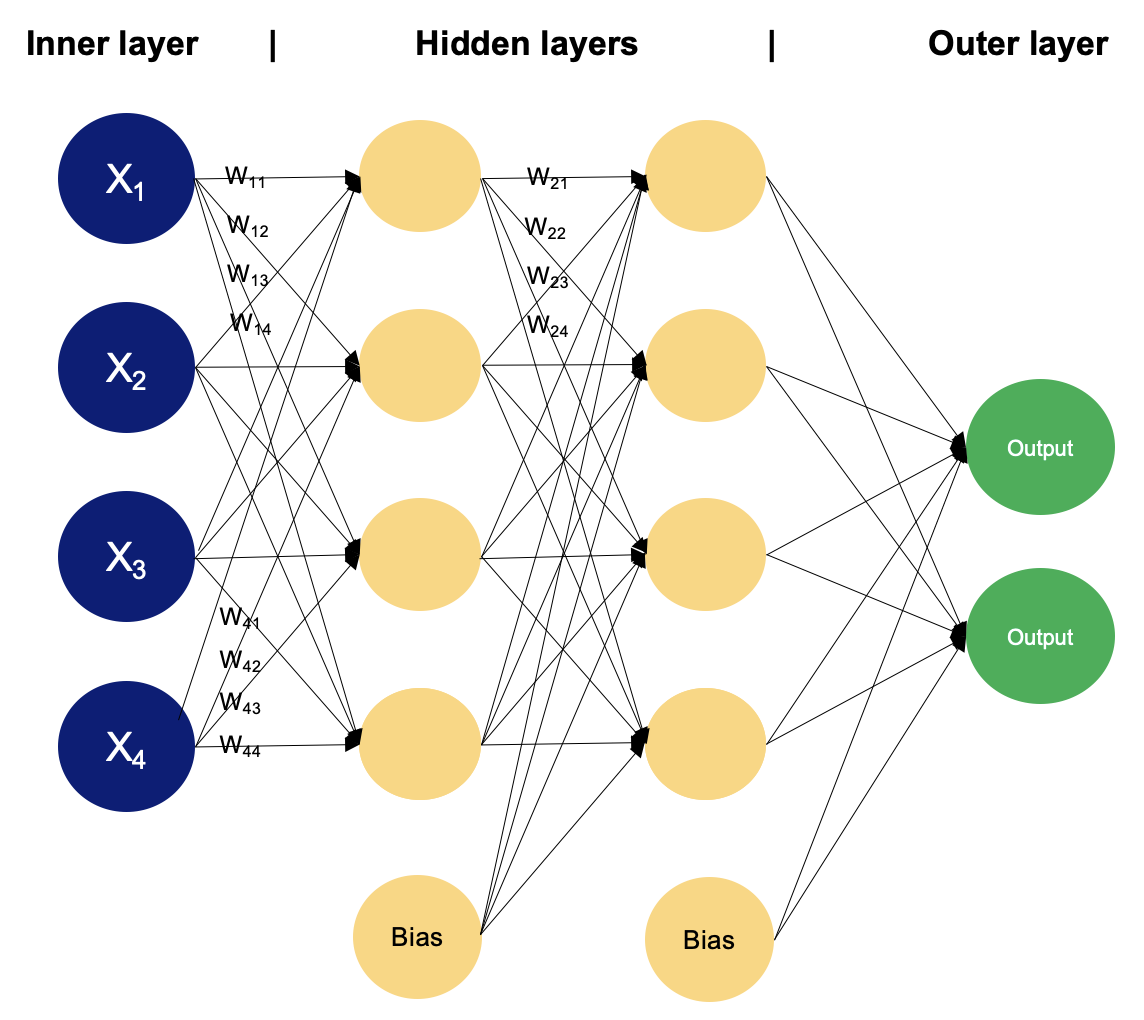
Voorbeeld van een MLP met twee verborgen lagen. Afbeelding door de auteur
In een multilayer perceptron verwerken neuronen informatie stap voor stap en doen berekeningen met gewogen sommen en niet-lineaire transformaties. Laten we laag voor laag doorlopen om te zien wat er onder de motorkap gebeurt.
w. De gewichten bepalen hoeveel invloed de input van de ene neuron heeft op de output van een andere.b. De bias levert een extra input aan de neuron, waardoor deze zijn outputdrempel kan aanpassen. Net als gewichten worden biases tijdens training geleerd.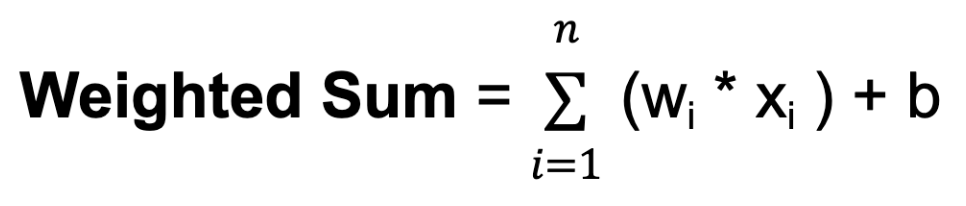
Waarbij n het totale aantal inputverbindingen is, wi het gewicht voor de i-de input is en xi de i-de inputwaarde is.
f. De activatiefunctie introduceert niet-lineariteit in het netwerk, waardoor het complexe relaties in de data kan leren en representeren. De activatiefunctie bepaalt het outputbereik van de neuron en zijn gedrag in reactie op verschillende inputwaarden. De keuze van de activatiefunctie hangt af van de aard van de taak en de gewenste eigenschappen van het netwerk.Tijdens het trainingsproces leert het netwerk de gewichten die horen bij de inputs van elke neuron aan te passen om de discrepantie tussen de voorspelde outputs en de echte doelwaarden in de trainingsdata te minimaliseren. Door de gewichten aan te passen en de juiste activatiefuncties te leren, leert het netwerk complexe patronen en relaties in de data te benaderen, waardoor het nauwkeurige voorspellingen kan doen op nieuwe, ongeziene voorbeelden.
Deze aanpassing wordt gestuurd door een optimalisatie-algoritme, zoals stochastic gradient descent (SGD), dat de gradiënten van een verliesfunctie ten opzichte van de gewichten berekent en de gewichten iteratief bijwerkt.
Laten we eens nader bekijken hoe SGD werkt.
θₜ₊₁ = θₜ − η ∇J(θₜ)Waar:
θₜ staat voor de modelparameters (bijv. gewichten en biases) bij iteratie t
∇J(θₜ) is de gradiënt van de verliesfunctie J ten opzichte van de parameters bij iteratie t
η (eta) is de leersnelheid, die de stapgrootte tijdens de optimalisatie bepaalt
n. Deze parameter bepaalt de grootte van de stappen richting het minimum. Als de leersnelheid te klein is, kan de convergentie traag zijn; is deze te groot, dan kan het algoritme oscilleren of divergeren.Stochastic gradient descent werkt de modelparameters vaker bij met kleinere subsets van data, wat het computationeel efficiënt maakt, vooral voor grote datasets. De willekeur die door SGD wordt geïntroduceerd kan een regulariserend effect hebben en voorkomt dat het model overfit op de trainingsdata. Het is ook geschikt voor online-leerscenario’s waarin nieuwe data stapsgewijs beschikbaar komt, omdat het model snel kan worden bijgewerkt met elk nieuw datapunt of mini-batch.
SGD kent echter ook uitdagingen, zoals meer ruis door het stochastische karakter van de gradiëntschatting en de noodzaak om hyperparameters zoals de leersnelheid af te stemmen. Diverse uitbreidingen en aanpassingen van SGD, zoals mini-batch stochastic gradient descent, momentum en adaptieve leersnelheden zoals AdaGrad, RMSProp en Adam, zijn ontwikkeld om deze uitdagingen aan te pakken en convergentie en prestaties te verbeteren.
Je hebt nu gezien hoe de lagen van een multilayer perceptron werken en geleerd over stochastic gradient descent; om alles samen te brengen, is er nog één onderwerp om in te duiken: backpropagation.
Backpropagation is een afkorting voor “backward propagation of errors”. In de context van backpropagation omvat SGD het iteratief bijwerken van de parameters van het netwerk op basis van de gradiënten die tijdens elke batch trainingsdata zijn berekend. In plaats van de gradiënten met de volledige trainingsdataset te berekenen (wat computationeel duur kan zijn voor grote datasets), berekent SGD de gradiënten met kleine willekeurige subsets van de data, mini-batches genoemd. Hier volgt een overzicht van hoe het backpropagation-algoritme werkt:
Het voorbereiden van data voor het trainen van een MLP omvat het opschonen, preprocessen, schalen, splitsen, formatteren en eventueel zelfs vergroten (augmentatie) van de data. Afhankelijk van de gebruikte activatiefuncties en de schaal van de invoerkenmerken moet de data mogelijk worden gestandaardiseerd of genormaliseerd. Experimenteren met verschillende preprocessingtechnieken en het evalueren van hun impact op de modelprestaties is vaak nodig om de meest geschikte aanpak voor een bepaalde dataset en taak te bepalen.
Wil je meer leren over het schalen van features, bekijk dan Datacamp’s Feature Engineering for Machine Learning in Python-cursus.
Het implementeren van een MLP omvat meerdere stappen, van datapreprocessing tot modeltraining en -evaluatie. Het kiezen van het aantal lagen en neuronen voor een MLP betekent balanceren tussen modelcomplexiteit, trainingstijd en generalisatieprestaties. Er is geen one-size-fits-all antwoord, omdat de optimale architectuur afhangt van factoren zoals de complexiteit van de taak, de hoeveelheid beschikbare data en rekenbronnen. Hier zijn echter enkele algemene richtlijnen om te overwegen bij het implementeren van een MLP:
Voordat je voor je project een MLP kiest, is het handig te begrijpen waar ze in uitblinken en waar andere architecturen mogelijk beter passen.
Multilayer perceptrons vormen een fundamentele en veelzijdige klasse van kunstmatige neurale netwerken die aanzienlijk hebben bijgedragen aan de vooruitgang van machine learning en kunstmatige intelligentie. Door hun onderling verbonden lagen van neuronen en niet-lineaire activatiefuncties zijn MLP’s in staat complexe patronen en relaties in data te leren, waardoor ze goed geschikt zijn voor een breed scala aan taken. De geschiedenis van MLP’s weerspiegelt een reis van verkenning, ontdekking en innovatie, van de vroege perceptronmodellen tot de moderne deep-learningarchitecturen die veel van de huidige state-of-the-art systemen aandrijven.
In dit artikel heb je de basis van kunstmatige neurale netwerken geleerd, je gefocust op multilayer perceptrons en geleerd over stochastic gradient descent en backpropagation. Als je graag hands-on aan de slag wilt en deep-learningtechnieken wilt gebruiken om echte uitdagingen op te lossen, zoals het voorspellen van huizenprijzen of het bouwen van neurale netwerken om beelden en tekst te modelleren, raden we je sterk aan om Datacamp’s Keras toolbox track te volgen.
Met Keras leer je over neurale netwerken, workflows voor deep-learningmodellen en hoe je je modellen optimaliseert. Datacamp heeft ook een Keras-cheatsheet die van pas kan komen!
Begin vandaag nog aan je machine learning-reis!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
