Curso
Machine Learning para negocios
2 h
46.2K
Las redes neuronales o redes neuronales artificiales son herramientas fundamentales en el aprendizaje automático, que impulsan muchos algoritmos y aplicaciones de vanguardia en diversos ámbitos, como la visión por ordenador, el procesamiento del lenguaje natural, la robótica y otros.
Una red neuronal está formada por nodos interconectados, llamados neuronas, organizados en capas. Cada neurona recibe señales de entrada, realiza un cálculo sobre ellas mediante una función de activación y produce una señal de salida que puede transmitirse a otras neuronas de la red. Una función de activación determina la salida de una neurona dada su entrada. Estas funciones introducen la no linealidad en la red, permitiéndole aprender patrones complejos en los datos.
La red suele organizarse en capas, empezando por la capa de entrada, donde se introducen los datos. Le siguen las capas ocultas, donde se realizan los cálculos y, por último, la capa de salida, donde se hacen las predicciones o se toman las decisiones.
Las neuronas de capas adyacentes están conectadas mediante conexiones ponderadas, que transmiten señales de una capa a la siguiente. La fuerza de estas conexiones, representada por los pesos, determina cuánta influencia tiene la salida de una neurona sobre la entrada de otra. Durante el proceso de entrenamiento, la red aprende a ajustar sus pesos basándose en los ejemplos proporcionados en un conjunto de datos de entrenamiento. Además, cada neurona suele tener un sesgo asociado, que le permite ajustar su umbral de salida.
Las redes neuronales se entrenan mediante técnicas denominadas propagación directa y retropropagación. Durante la propagación directa, los datos de entrada pasan por la red capa por capa, y cada capa realiza un cálculo basado en las entradas que recibe y pasa el resultado a la capa siguiente.
La retropropagación es un algoritmo utilizado para entrenar redes neuronales ajustando iterativamente los pesos y sesgos de la red para minimizar la función de pérdida. Una función de pérdida (también conocida como función de coste o función objetivo) es una medida de lo bien que coinciden las predicciones del modelo con los verdaderos valores objetivo de los datos de entrenamiento. La función de pérdida cuantifica la diferencia entre la salida prevista del modelo y la salida real, proporcionando una señal que guía el proceso de optimización durante el entrenamiento.
El objetivo del entrenamiento de una red neuronal es minimizar esta función de pérdida ajustando los pesos y los sesgos. Los ajustes se guían por un algoritmo de optimización, como el descenso gradiente. Volveremos sobre algunos de estos temas con más detalle más adelante en este tutorial.
Neurona biológica vs. Red neuronal artificial Fuente: ResearchGate
La RNA representada a la derecha de la imagen es una red neuronal simple llamada "perceptrón". Consta de una sola capa, que es la capa de entrada, con múltiples neuronas con sus propios pesos; no hay capas ocultas. El algoritmo del perceptrón aprende los pesos de las señales de entrada para trazar un límite de decisión lineal.
Sin embargo, para resolver problemas más complicados y no lineales relacionados con tareas de procesamiento de imágenes, visión por ordenador y procesamiento del lenguaje natural, trabajamos con redes neuronales profundas.
Consulta el tutorial Introducción a las redes neur onales profundas de Datacamp para aprender más sobre las redes neuronales profundas y cómo construir una desde cero utilizando TensorFlow y Keras en Python. Si prefieres utilizar el lenguaje R, el curso de Datacamp Construir modelos de redes neuronales (NN) en R te ayudará.
Existen varios tipos de RNA, cada una diseñada para tareas y requisitos arquitectónicos específicos. Analicemos brevemente algunos de los tipos más comunes antes de profundizar a continuación en los MLP.
Son la forma más sencilla de RNA, en las que la información fluye en una dirección, de la entrada a la salida. No hay ciclos ni bucles en la arquitectura de la red. Los perceptrones multicapa (MLP) son un tipo de red neuronal de avance.
En las RNN, las conexiones entre nodos forman ciclos dirigidos, lo que permite que la información persista en el tiempo. Esto los hace adecuados para tareas que implican datos secuenciales, como la predicción de series temporales, el procesamiento del lenguaje natural y el reconocimiento del habla.
Las CNN están diseñadas para procesar eficazmente datos en forma de cuadrícula, como las imágenes. Constan de capas de filtros convolucionales que aprenden representaciones jerárquicas de características dentro de los datos de entrada. Las CNN se utilizan ampliamente en tareas como la clasificación de imágenes, la detección de objetos y la segmentación de imágenes.
Son tipos especializados de redes neuronales recurrentes diseñadas para resolver el problema del gradiente evanescente en las RNN tradicionales. Las LSTM y las GRU incorporan mecanismos de compuerta para captar mejor las dependencias de largo alcance en los datos secuenciales, lo que las hace especialmente eficaces para tareas como el reconocimiento del habla, la traducción automática y el análisis de sentimientos.
Está diseñado para el aprendizaje no supervisado y consta de una red codificadora que comprime los datos de entrada en un espacio latente de menor dimensión, y una red decodificadora que reconstruye la entrada original a partir de la representación latente. Los autocodificadores se utilizan a menudo para la reducción de la dimensionalidad, la eliminación de ruido de los datos y el modelado generativo.
Las GAN constan de dos redes neuronales, una generadora y otra discriminadora, entrenadas simultáneamente en un entorno competitivo. El generador aprende a generar muestras de datos sintéticos que no se distinguen de los datos reales, mientras que el discriminador aprende a distinguir entre muestras reales y falsas. Los GAN se han utilizado ampliamente para generar imágenes realistas, vídeos y otros tipos de datos.
Un perceptrón multicapa es un tipo de red neuronal feedforward formada por neuronas totalmente conectadas con un tipo de función de activación no lineal. Se utiliza mucho para distinguir datos que no son linealmente separables.
Los MLP se han utilizado ampliamente en diversos campos, como el reconocimiento de imágenes, el procesamiento del lenguaje natural y el reconocimiento del habla, entre otros. Su flexibilidad en la arquitectura y su capacidad para aproximarse a cualquier función en determinadas condiciones los convierten en un elemento fundamental en la investigación sobre el aprendizaje profundo y las redes neuronales. Profundicemos en algunos de sus conceptos clave.
La capa de entrada está formada por nodos o neuronas que reciben los datos de entrada iniciales. Cada neurona representa una característica o dimensión de los datos de entrada. El número de neuronas de la capa de entrada viene determinado por la dimensionalidad de los datos de entrada.
Entre las capas de entrada y salida puede haber una o varias capas de neuronas. Cada neurona de una capa oculta recibe entradas de todas las neuronas de la capa anterior (ya sea la capa de entrada u otra capa oculta) y produce una salida que pasa a la capa siguiente. El número de capas ocultas y el número de neuronas de cada capa oculta son hiperparámetros que deben determinarse durante la fase de diseño del modelo.
Esta capa está formada por neuronas que producen la salida final de la red. El número de neuronas de la capa de salida depende de la naturaleza de la tarea. En la clasificación binaria, puede haber una o dos neuronas dependiendo de la función de activación y representando la probabilidad de pertenecer a una clase; mientras que en las tareas de clasificación multiclase, puede haber varias neuronas en la capa de salida.
Las neuronas de capas adyacentes están totalmente conectadas entre sí. Cada conexión tiene un peso asociado, que determina la fuerza de la conexión. Estos pesos se aprenden durante el proceso de entrenamiento.
Además de las neuronas de entrada y ocultas, cada capa (excepto la de entrada) suele incluir una neurona de polarización que proporciona una entrada constante a las neuronas de la capa siguiente. Las neuronas de sesgo tienen su propio peso asociado a cada conexión, que también se aprende durante el entrenamiento.
La neurona de sesgo desplaza efectivamente la función de activación de las neuronas de la capa siguiente, permitiendo que la red aprenda un desplazamiento o sesgo en el límite de decisión. Ajustando los pesos conectados a la neurona de polarización, la MLP puede aprender a controlar el umbral de activación y ajustarse mejor a los datos de entrenamiento.
Nota: Es importante señalar que, en el contexto de los MLP, el sesgo puede referirse a dos conceptos relacionados pero distintos: el sesgo como término general en el aprendizaje automático y la neurona sesgada (definida anteriormente). En el aprendizaje automático general, el sesgo se refiere al error introducido al aproximar un problema del mundo real con un modelo simplificado. El sesgo mide lo bien que el modelo puede captar los patrones subyacentes en los datos. Un sesgo alto indica que el modelo es demasiado simplista y puede ajustarse mal a los datos, mientras que un sesgo bajo sugiere que el modelo capta bien los patrones subyacentes.
Normalmente, cada neurona de las capas ocultas y de la capa de salida aplica una función de activación a su suma ponderada de entradas. Las funciones de activación habituales son sigmoide, tanh, ReLU (Unidad Lineal Rectificada) y softmax. Estas funciones introducen la no linealidad en la red, permitiéndole aprender patrones complejos en los datos.
Los MLP se entrenan mediante el algoritmo de retropropagación, que calcula los gradientes de una función de pérdida con respecto a los parámetros del modelo y actualiza los parámetros iterativamente para minimizar la pérdida.
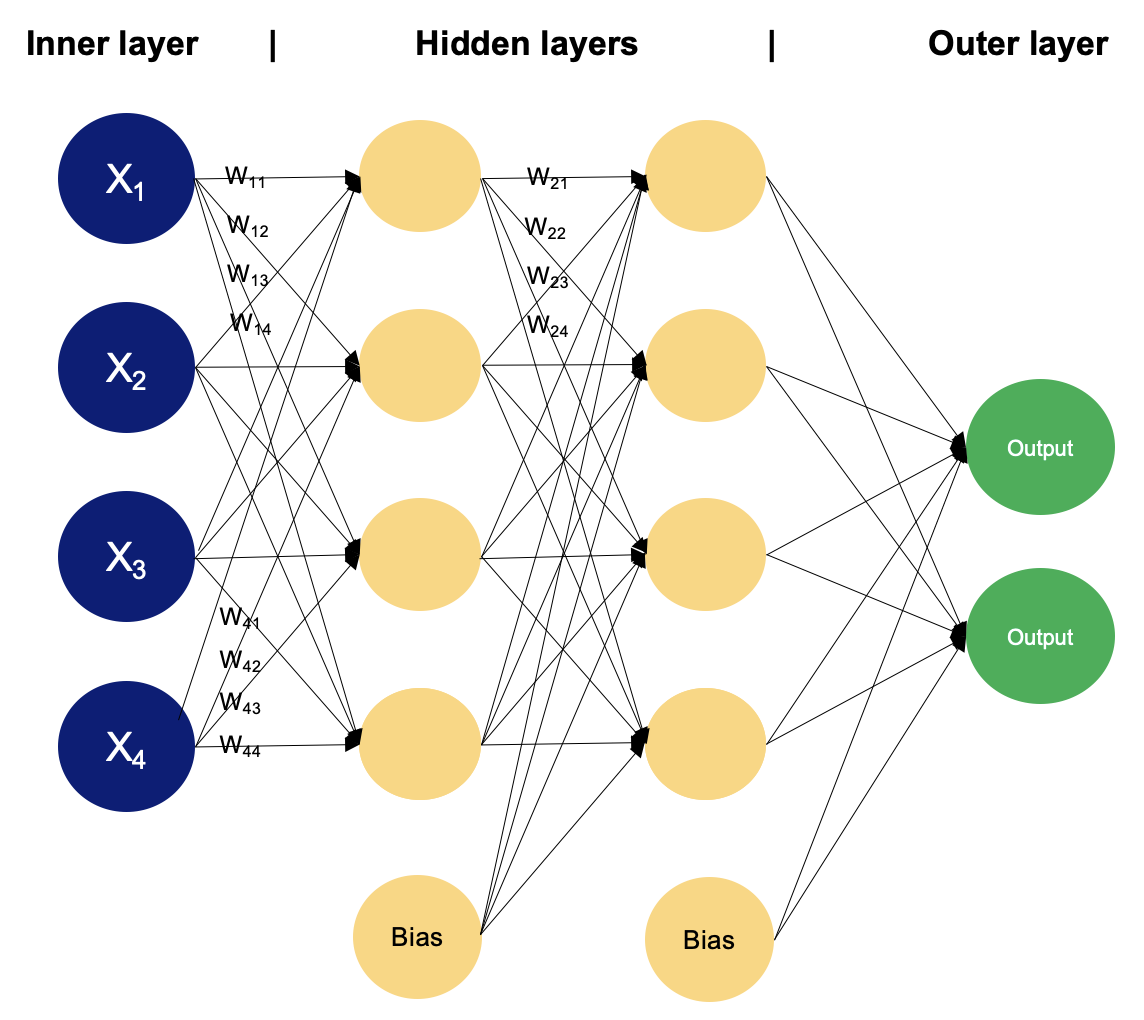
Ejemplo de MLP con dos capas ocultas. Imagen del autor
En un perceptrón multicapa, las neuronas procesan la información paso a paso, realizando cálculos que implican sumas ponderadas y transformaciones no lineales. Caminemos capa por capa para ver la magia que encierra.
w. Los pesos determinan cuánta influencia tiene la entrada de una neurona en la salida de otra.b. El sesgo proporciona una entrada adicional a la neurona, permitiéndole ajustar su umbral de salida. Al igual que los pesos, los sesgos se aprenden durante el entrenamiento.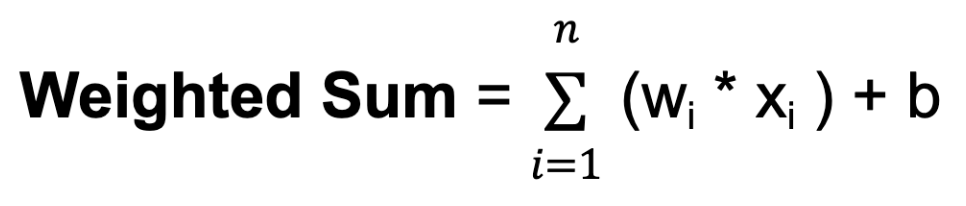
Donde n es el número total de conexiones de entrada, wi es el peso de la entrada i-ésima y xi es el valor de la entrada i-ésima.
f. La función de activación introduce la no linealidad en la red, lo que le permite aprender y representar relaciones complejas en los datos. La función de activación determina el rango de salida de la neurona y su comportamiento en respuesta a distintos valores de entrada. La elección de la función de activación depende de la naturaleza de la tarea y de las propiedades deseadas de la red.Durante el proceso de entrenamiento, la red aprende a ajustar los pesos asociados a las entradas de cada neurona para minimizar la discrepancia entre las salidas previstas y los verdaderos valores objetivo de los datos de entrenamiento. Ajustando los pesos y aprendiendo las funciones de activación adecuadas, la red aprende a aproximarse a patrones y relaciones complejas en los datos, lo que le permite hacer predicciones precisas sobre muestras nuevas no vistas.
Este ajuste está guiado por un algoritmo de optimización, como el descenso de gradiente estocástico (SGD), que calcula los gradientes de una función de pérdida con respecto a los pesos y actualiza los pesos de forma iterativa.
Veamos más de cerca cómo funciona el SGD.
Para cada iteración (o época) de entrenamiento:
θt representa los parámetros del modelo en la iteración t. Este parámetro puede ser el peso⛛ J (θt) es el gradiente de la función de pérdida J con respecto a los parámetros θtn es la tasa de aprendizaje, que controla el tamaño de los pasos dados durante la optimizaciónn. Este parámetro controla el tamaño de los pasos dados hacia el mínimo. Si la tasa de aprendizaje es demasiado pequeña, la convergencia puede ser lenta; si es demasiado grande, el algoritmo puede oscilar o divergir.El descenso de gradiente estocástico actualiza los parámetros del modelo con mayor frecuencia utilizando subconjuntos más pequeños de datos, lo que lo hace eficiente desde el punto de vista informático, especialmente para grandes conjuntos de datos. La aleatoriedad introducida por el SGD puede tener un efecto de regularización, evitando que el modelo se ajuste en exceso a los datos de entrenamiento. También es adecuado para escenarios de aprendizaje en línea en los que se dispone de nuevos datos de forma incremental, ya que puede actualizar el modelo rápidamente con cada nuevo punto de datos o minilotes.
Sin embargo, el SGD también puede presentar algunos retos, como el aumento del ruido debido a la naturaleza estocástica de la estimación del gradiente y la necesidad de ajustar hiperparámetros como la tasa de aprendizaje. Se han desarrollado varias extensiones y adaptaciones del SGD, como el descenso de gradiente estocástico por mini lotes, el impulso y los métodos de tasa de aprendizaje adaptativa como AdaGrad, RMSProp y Adam, para abordar estos retos y mejorar la convergencia y el rendimiento.
Has visto el funcionamiento de las capas del perceptrón multicapa y has aprendido sobre el descenso en gradiente estocástico; para ponerlo todo junto, hay un último tema en el que sumergirse: la retropropagación.
Retropropagación es la abreviatura de "propagación de errores hacia atrás". En el contexto de la retropropagación, la SGD consiste en actualizar los parámetros de la red de forma iterativa basándose en los gradientes calculados durante cada lote de datos de entrenamiento. En lugar de calcular los gradientes utilizando todo el conjunto de datos de entrenamiento (lo que puede ser costoso desde el punto de vista informático para grandes conjuntos de datos), el SGD calcula los gradientes utilizando pequeños subconjuntos aleatorios de los datos llamados minilotes. Aquí tienes un resumen de cómo funciona el algoritmo de retropropagación:
Preparar los datos para entrenar un MLP implica limpiarlos, preprocesarlos, escalarlos, dividirlos, formatearlos y quizá incluso aumentarlos. Según las funciones de activación utilizadas y la escala de las características de entrada, puede ser necesario normalizar o estandarizar los datos. Experimentar con diferentes técnicas de preprocesamiento y evaluar su impacto en el rendimiento del modelo suele ser necesario para determinar el enfoque más adecuado para un conjunto de datos y una tarea concretos.
Para aprender más sobre el escalado de características, consulta el curso de Datacamp Ingeniería de Características para el Aprendizaje Automático en Python.
Implementar un MLP implica varios pasos, desde el preprocesamiento de los datos hasta el entrenamiento y la evaluación del modelo. Seleccionar el número de capas y neuronas para un MLP implica equilibrar la complejidad del modelo, el tiempo de entrenamiento y el rendimiento de generalización. No existe una respuesta única, ya que la arquitectura óptima depende de factores como la complejidad de la tarea, la cantidad de datos disponibles y los recursos informáticos. Sin embargo, aquí tienes algunas directrices generales que debes tener en cuenta al poner en práctica la MLP:
Los perceptrones multicapa representan una clase fundamental y versátil de redes neuronales artificiales que han contribuido significativamente al avance del aprendizaje automático y la inteligencia artificial. A través de sus capas interconectadas de neuronas y funciones de activación no lineales, los MLP son capaces de aprender patrones y relaciones complejas en los datos, lo que los hace muy adecuados para una amplia gama de tareas. La historia de los MLP refleja un viaje de exploración, descubrimiento e innovación, desde los primeros modelos de perceptrón hasta las modernas arquitecturas de aprendizaje profundo que impulsan muchos sistemas de última generación en la actualidad.
En este artículo, has aprendido los fundamentos de las redes neuronales artificiales, te has centrado en los perceptrones multicapa, has conocido el descenso de gradiente estocástico y la retropropagación. Si estás interesado en adquirir experiencia práctica y utilizar técnicas de aprendizaje profundo para resolver retos del mundo real, como predecir el precio de la vivienda o crear redes neuronales para modelar imágenes y texto, te recomendamos encarecidamente que sigas el curso sobre la caja de herramientas Keras de Datacamp.
Trabajando con Keras, aprenderás sobre redes neuronales, flujos de trabajo de modelos de aprendizaje profundo y cómo optimizar tus modelos. Datacamp también tiene una hoja de trucos de Keras que puede ser muy útil.
¡Comienza hoy tu viaje de aprendizaje automático!
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
7 min
blog
Natassha Selvaraj
15 min
Tutorial
Joanne Xiong
Tutorial
Zoumana Keita
Tutorial
Bharath K