
Courses
Machine Learning cho Kinh doanh
2 giờ
46.7K
Mạng nơ-ron hay mạng nơ-ron nhân tạo là công cụ nền tảng trong machine learning, cung cấp sức mạnh cho nhiều thuật toán và ứng dụng hiện đại trên nhiều lĩnh vực, gồm thị giác máy tính, xử lý ngôn ngữ tự nhiên, robot, v.v.
Một mạng nơ-ron gồm các nút liên kết, gọi là nơ-ron, được tổ chức theo các tầng. Mỗi nơ-ron nhận các tín hiệu đầu vào, thực hiện tính toán trên chúng bằng một hàm kích hoạt và tạo ra tín hiệu đầu ra có thể được truyền tới các nơ-ron khác trong mạng. Một hàm kích hoạt xác định đầu ra của một nơ-ron dựa trên đầu vào của nó. Những hàm này đưa tính phi tuyến vào mạng, giúp nó học được các mẫu phức tạp trong dữ liệu.
Mạng thường được tổ chức theo các tầng, bắt đầu với tầng đầu vào, nơi dữ liệu được đưa vào. Tiếp theo là các tầng ẩn nơi diễn ra các phép tính, và cuối cùng là tầng đầu ra nơi đưa ra dự đoán hay quyết định.
Các nơ-ron ở các tầng kề nhau được nối với nhau bằng các kết nối có trọng số, truyền tín hiệu từ tầng này sang tầng tiếp theo. Độ mạnh của các kết nối này, được biểu diễn bằng trọng số, quyết định mức độ ảnh hưởng của đầu ra một nơ-ron lên đầu vào của nơ-ron khác. Trong quá trình huấn luyện, mạng học cách điều chỉnh các trọng số dựa trên các ví dụ trong bộ dữ liệu huấn luyện. Ngoài ra, mỗi nơ-ron thường có một hệ số bias đi kèm, cho phép nơ-ron điều chỉnh ngưỡng đầu ra của mình.
Mạng nơ-ron được huấn luyện bằng các kỹ thuật gọi là lan truyền xuôi (feedforward) và lan truyền ngược. Trong lan truyền xuôi, dữ liệu đầu vào được truyền qua mạng theo từng tầng, mỗi tầng thực hiện tính toán dựa trên đầu vào nhận được và chuyển kết quả cho tầng tiếp theo.
Lan truyền ngược là một thuật toán dùng để huấn luyện mạng nơ-ron bằng cách lặp lại việc điều chỉnh các trọng số và bias của mạng nhằm tối thiểu hoá hàm mất mát. Một hàm mất mát (còn gọi là hàm chi phí hay hàm mục tiêu) là thước đo mức độ phù hợp giữa dự đoán của mô hình và giá trị mục tiêu thật trong dữ liệu huấn luyện. Hàm mất mát định lượng chênh lệch giữa đầu ra dự đoán và đầu ra thực, cung cấp tín hiệu định hướng quá trình tối ưu trong huấn luyện.
Mục tiêu của việc huấn luyện mạng nơ-ron là tối thiểu hoá hàm mất mát này bằng cách điều chỉnh các trọng số và bias. Việc điều chỉnh được dẫn dắt bởi một thuật toán tối ưu hoá, như hạ dốc (gradient descent). Chúng ta sẽ xem lại một số chủ đề này chi tiết hơn ở phần sau của hướng dẫn.
Nơ-ron sinh học so với mạng nơ-ron nhân tạo (Nguồn: ResearchGate)
ANN được minh hoạ bên phải là một mạng nơ-ron đơn giản gọi là ‘perceptron’. Nó gồm một tầng duy nhất là tầng đầu vào, với nhiều nơ-ron có trọng số riêng; không có tầng ẩn. Thuật toán perceptron học các trọng số cho các tín hiệu đầu vào để vẽ một ranh giới quyết định tuyến tính.
Tuy nhiên, để giải các bài toán phức tạp và phi tuyến hơn liên quan đến xử lý ảnh, thị giác máy tính và xử lý ngôn ngữ tự nhiên, chúng ta làm việc với các mạng nơ-ron sâu.
Xem thêm hướng dẫn Giới thiệu về Mạng Nơ-ron Sâu để tìm hiểu thêm về mạng nơ-ron sâu và cách xây dựng từ đầu bằng TensorFlow và Keras trong Python. Nếu bạn muốn dùng ngôn ngữ R, tài liệu Xây dựng Mô hình Mạng Nơ-ron (NN) trong R sẽ hỗ trợ bạn.
Có nhiều loại ANN, mỗi loại được thiết kế cho các tác vụ và yêu cầu kiến trúc cụ thể. Hãy điểm qua một số loại phổ biến trước khi đi sâu vào MLP ở phần tiếp theo.
Đây là dạng đơn giản nhất của ANN, nơi thông tin chảy theo một hướng từ đầu vào đến đầu ra. Không có chu kỳ hay vòng lặp trong kiến trúc. Perceptron nhiều lớp (MLP) là một loại mạng lan truyền xuôi.
Trong RNN, các kết nối giữa các nút tạo thành các chu kỳ có hướng, cho phép thông tin tồn tại theo thời gian. Điều này giúp chúng phù hợp cho dữ liệu tuần tự, như dự báo chuỗi thời gian, xử lý ngôn ngữ tự nhiên và nhận dạng giọng nói.
CNN được thiết kế để xử lý hiệu quả dữ liệu dạng lưới, như ảnh. Chúng gồm các tầng bộ lọc tích chập học các biểu diễn phân cấp của đặc trưng trong dữ liệu đầu vào. CNN được dùng rộng rãi trong các tác vụ như phân loại ảnh, phát hiện đối tượng và phân đoạn ảnh.
Đây là các biến thể chuyên biệt của RNN nhằm giải quyết vấn đề tiêu biến gradient trong RNN truyền thống. LSTM và GRU tích hợp cơ chế cổng để nắm bắt tốt hơn các phụ thuộc dài hạn trong dữ liệu tuần tự, đặc biệt hiệu quả cho các tác vụ như nhận dạng giọng nói, dịch máy và phân tích cảm xúc.
Được thiết kế cho học không giám sát, gồm một mạng mã hoá nén dữ liệu đầu vào vào không gian tiềm ẩn có chiều thấp hơn, và một mạng giải mã tái tạo lại đầu vào ban đầu từ biểu diễn tiềm ẩn. Autoencoder thường được dùng để giảm chiều dữ liệu, khử nhiễu dữ liệu và mô hình sinh.
GAN gồm hai mạng nơ-ron, một bộ sinh và một bộ phân biệt, được huấn luyện đồng thời trong môi trường đối kháng. Bộ sinh học tạo ra mẫu dữ liệu tổng hợp không phân biệt được với dữ liệu thật, trong khi bộ phân biệt học cách phân biệt dữ liệu thật và giả. GAN được dùng rộng rãi để tạo ảnh, video và các loại dữ liệu khác chân thực.
Perceptron nhiều lớp là một loại mạng nơ-ron lan truyền xuôi gồm các nơ-ron kết nối đầy đủ với các hàm kích hoạt phi tuyến. Nó được dùng rộng rãi để phân biệt dữ liệu không thể tách tuyến tính.
MLP đã được sử dụng rộng rãi trong nhiều lĩnh vực, bao gồm nhận dạng hình ảnh, xử lý ngôn ngữ tự nhiên và nhận dạng giọng nói, v.v. Tính linh hoạt về kiến trúc và khả năng xấp xỉ bất kỳ hàm nào dưới một số điều kiện khiến chúng trở thành khối xây dựng cơ bản trong học sâu và nghiên cứu mạng nơ-ron. Hãy đi sâu vào một số khái niệm chủ chốt.
Tầng đầu vào gồm các nút hoặc nơ-ron nhận dữ liệu đầu vào ban đầu. Mỗi nơ-ron đại diện cho một đặc trưng hay chiều của dữ liệu đầu vào. Số lượng nơ-ron ở tầng đầu vào được quyết định bởi số chiều của dữ liệu đầu vào.
Giữa tầng đầu vào và đầu ra có thể có một hoặc nhiều tầng nơ-ron. Mỗi nơ-ron ở tầng ẩn nhận đầu vào từ tất cả nơ-ron ở tầng trước (hoặc tầng đầu vào hoặc một tầng ẩn khác) và tạo ra đầu ra truyền sang tầng kế tiếp. Số lượng tầng ẩn và số nơ-ron ở mỗi tầng ẩn là các siêu tham số cần xác định ở giai đoạn thiết kế mô hình.
Tầng này gồm các nơ-ron tạo ra đầu ra cuối cùng của mạng. Số nơ-ron ở tầng đầu ra phụ thuộc vào bản chất của tác vụ. Trong phân loại nhị phân, có thể có một hoặc hai nơ-ron tuỳ theo hàm kích hoạt và biểu diễn xác suất thuộc về một lớp; còn với phân loại đa lớp, có thể có nhiều nơ-ron ở tầng đầu ra.
Các nơ-ron ở các tầng kề nhau được kết nối đầy đủ với nhau. Mỗi kết nối có một trọng số đi kèm, xác định độ mạnh của kết nối. Những trọng số này được học trong quá trình huấn luyện.
Ngoài các nơ-ron đầu vào và ẩn, mỗi tầng (trừ tầng đầu vào) thường có một nơ-ron bias cung cấp đầu vào hằng cho các nơ-ron ở tầng tiếp theo. Nơ-ron bias có trọng số riêng cho mỗi kết nối, cũng được học trong quá trình huấn luyện.
Nơ-ron bias thực chất dịch chuyển hàm kích hoạt của các nơ-ron ở tầng sau, cho phép mạng học một độ lệch trong ranh giới quyết định. Bằng cách điều chỉnh các trọng số nối với nơ-ron bias, MLP có thể học cách kiểm soát ngưỡng kích hoạt và khớp dữ liệu huấn luyện tốt hơn.
Lưu ý: Cần lưu ý rằng trong ngữ cảnh MLP, bias có thể chỉ hai khái niệm liên quan nhưng khác nhau: bias như một thuật ngữ chung trong machine learning và nơ-ron bias (định nghĩa ở trên). Trong machine learning nói chung, bias chỉ sai số phát sinh khi xấp xỉ một vấn đề thế giới thực bằng một mô hình đơn giản hơn. Bias đo mức độ mô hình nắm bắt các mẫu cơ bản trong dữ liệu. Bias cao cho thấy mô hình quá đơn giản và có thể underfit dữ liệu, trong khi bias thấp gợi ý mô hình nắm bắt tốt các mẫu cơ bản.
Thông thường, mỗi nơ-ron ở các tầng ẩn và tầng đầu ra áp dụng một hàm kích hoạt lên tổng có trọng số của các đầu vào. Các hàm kích hoạt phổ biến gồm sigmoid, tanh, ReLU (Rectified Linear Unit) và softmax. Những hàm này đưa tính phi tuyến vào mạng, cho phép nó học các mẫu phức tạp trong dữ liệu.
MLP được huấn luyện bằng thuật toán lan truyền ngược, thuật toán này tính gradient của một hàm mất mát theo các tham số của mô hình và cập nhật tham số lặp đi lặp lại để tối thiểu hoá mất mát.
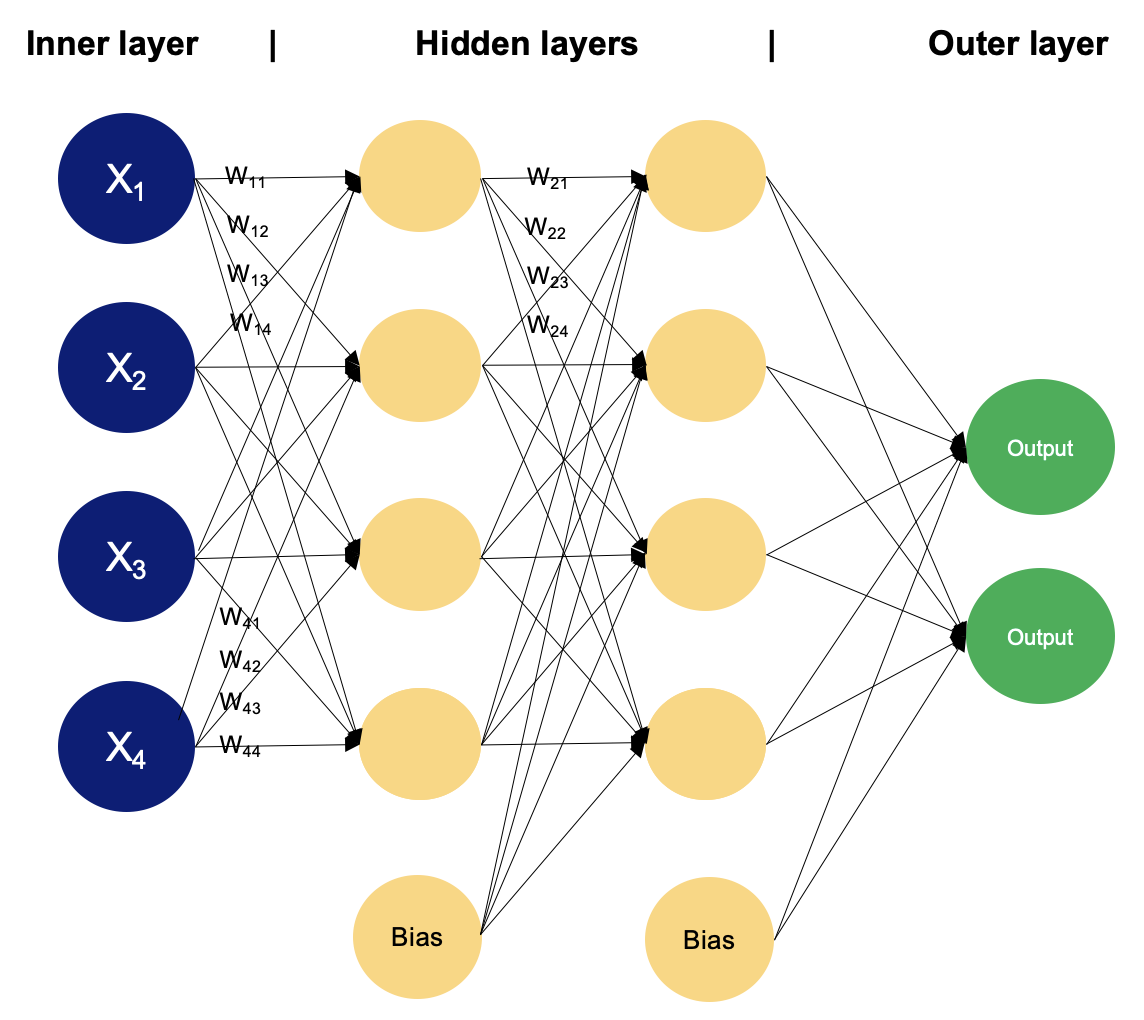
Ví dụ về một MLP với hai tầng ẩn. Ảnh: Tác giả
Trong perceptron nhiều lớp, các nơ-ron xử lý thông tin theo từng bước, thực hiện các phép tính gồm tổng có trọng số và biến đổi phi tuyến. Hãy đi qua từng tầng để xem điều kỳ diệu bên trong.
w. Trọng số quyết định mức độ ảnh hưởng của đầu vào từ một nơ-ron lên đầu ra của nơ-ron khác.b. Bias cung cấp một đầu vào bổ sung cho nơ-ron, cho phép nó điều chỉnh ngưỡng đầu ra. Giống trọng số, bias được học trong quá trình huấn luyện.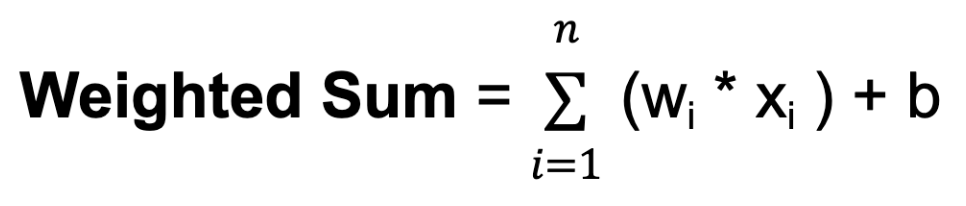
Trong đó n là tổng số kết nối đầu vào, wi là trọng số cho đầu vào thứ i, và xi là giá trị đầu vào thứ i.
f. Hàm kích hoạt đưa phi tuyến vào mạng, cho phép nó học và biểu diễn các quan hệ phức tạp trong dữ liệu. Hàm kích hoạt xác định miền đầu ra của nơ-ron và hành vi của nó trước các giá trị đầu vào khác nhau. Việc chọn hàm kích hoạt phụ thuộc vào bản chất tác vụ và các thuộc tính mong muốn của mạng.Trong quá trình huấn luyện, mạng học cách điều chỉnh các trọng số gắn với đầu vào của mỗi nơ-ron để tối thiểu hoá sai lệch giữa đầu ra dự đoán và giá trị mục tiêu thật trong dữ liệu huấn luyện. Bằng cách điều chỉnh trọng số và học các hàm kích hoạt phù hợp, mạng học cách xấp xỉ các mẫu và quan hệ phức tạp trong dữ liệu, cho phép đưa ra dự đoán chính xác trên các mẫu mới, chưa thấy.
Sự điều chỉnh này được dẫn dắt bởi một thuật toán tối ưu hoá, như hạ dốc ngẫu nhiên (SGD), thuật toán tính gradient của một hàm mất mát theo các trọng số và cập nhật trọng số theo từng vòng lặp.
Hãy xem kỹ hơn cách SGD hoạt động.
θₜ₊₁ = θₜ − η ∇J(θₜ)Trong đó:
θₜ biểu diễn các tham số mô hình (ví dụ: trọng số và bias) tại vòng lặp t
∇J(θₜ) là gradient của hàm mất mát J theo các tham số tại vòng lặp t
η (eta) là tốc độ học (learning rate), điều khiển độ dài bước trong quá trình tối ưu
n. Tham số này điều khiển kích thước bước tiến về cực tiểu. Nếu tốc độ học quá nhỏ, việc hội tụ có thể chậm; nếu quá lớn, thuật toán có thể dao động hoặc phân kỳ.Hạ dốc ngẫu nhiên cập nhật các tham số mô hình thường xuyên hơn bằng cách dùng các tập con dữ liệu nhỏ, giúp hiệu quả tính toán, đặc biệt với các tập dữ liệu lớn. Tính ngẫu nhiên của SGD có thể mang lại hiệu ứng regularization, ngăn mô hình overfit dữ liệu huấn luyện. Nó cũng phù hợp với các kịch bản học trực tuyến nơi dữ liệu mới xuất hiện dần dần, vì có thể cập nhật mô hình nhanh với mỗi điểm dữ liệu hay mini-batch mới.
Tuy nhiên, SGD cũng có một số thách thức, như nhiễu tăng do tính ngẫu nhiên của ước lượng gradient và nhu cầu tinh chỉnh các siêu tham số như tốc độ học. Nhiều biến thể và điều chỉnh của SGD, như hạ dốc ngẫu nhiên theo mini-batch, momentum, và các phương pháp tốc độ học thích nghi như AdaGrad, RMSProp và Adam, đã được phát triển để giải quyết các thách thức này và cải thiện hội tụ cũng như hiệu năng.
Bạn đã thấy cách các tầng của perceptron nhiều lớp hoạt động và tìm hiểu về hạ dốc ngẫu nhiên; để tổng hợp lại, còn một chủ đề cuối cùng cần đi sâu: lan truyền ngược.
Lan truyền ngược là viết tắt của “lan truyền ngược sai số”. Trong ngữ cảnh lan truyền ngược, SGD liên quan đến việc cập nhật tham số mạng lặp đi lặp lại dựa trên các gradient được tính ở mỗi batch dữ liệu huấn luyện. Thay vì tính gradient bằng toàn bộ tập dữ liệu huấn luyện (có thể tốn kém tính toán với các tập lớn), SGD tính gradient bằng các tập con nhỏ ngẫu nhiên gọi là mini-batch. Dưới đây là tổng quan về cách thuật toán lan truyền ngược hoạt động:
Chuẩn bị dữ liệu để huấn luyện MLP bao gồm làm sạch, tiền xử lý, tỷ lệ hoá/chuẩn hoá, chia tách, định dạng và thậm chí tăng cường dữ liệu. Dựa trên các hàm kích hoạt sử dụng và thang đo của các đặc trưng đầu vào, dữ liệu có thể cần được chuẩn hoá (standardize) hoặc bình thường hoá (normalize). Thử nghiệm các kỹ thuật tiền xử lý khác nhau và đánh giá tác động của chúng lên hiệu năng mô hình thường là cần thiết để xác định cách tiếp cận phù hợp nhất cho từng tập dữ liệu và tác vụ cụ thể.
Để tìm hiểu thêm về tỷ lệ hoá đặc trưng, xem khoá học Kỹ thuật Đặc trưng cho Machine Learning bằng Python của Datacamp.
Triển khai một MLP bao gồm nhiều bước, từ tiền xử lý dữ liệu đến huấn luyện và đánh giá mô hình. Việc chọn số lượng tầng và nơ-ron cho MLP đòi hỏi cân bằng giữa độ phức tạp mô hình, thời gian huấn luyện và khả năng khái quát. Không có đáp án chung cho mọi trường hợp, vì kiến trúc tối ưu phụ thuộc vào độ phức tạp của tác vụ, lượng dữ liệu và tài nguyên tính toán. Tuy nhiên, dưới đây là một số hướng dẫn chung khi triển khai MLP:
Trước khi chọn MLP cho dự án, bạn nên hiểu nơi chúng vượt trội và nơi các kiến trúc khác có thể phù hợp hơn.
Perceptron nhiều lớp là một lớp mạng nơ-ron nhân tạo nền tảng và đa dụng, đã đóng góp đáng kể cho sự phát triển của machine learning và trí tuệ nhân tạo. Thông qua các tầng nơ-ron liên kết và các hàm kích hoạt phi tuyến, MLP có khả năng học các mẫu và quan hệ phức tạp trong dữ liệu, khiến chúng phù hợp với nhiều tác vụ. Lịch sử của MLP phản ánh một hành trình khám phá, phát hiện và đổi mới, từ các mô hình perceptron ban đầu đến các kiến trúc học sâu hiện đại vận hành nhiều hệ thống tiên tiến ngày nay.
Trong bài viết này, bạn đã học những điều cơ bản về mạng nơ-ron nhân tạo, tập trung vào perceptron nhiều lớp, tìm hiểu về hạ dốc ngẫu nhiên và lan truyền ngược. Nếu bạn muốn trải nghiệm thực hành và dùng kỹ thuật học sâu để giải quyết các thách thức thực tế, như dự đoán giá nhà, xây dựng mạng nơ-ron để mô hình hoá ảnh và văn bản - chúng tôi khuyến nghị theo dõi lộ trình công cụ Keras của Datacamp.
Làm việc với Keras, bạn sẽ học về mạng nơ-ron, quy trình làm việc với mô hình học sâu và cách tối ưu mô hình của mình. Datacamp cũng có cheat sheet Keras rất hữu ích!
Bắt đầu Hành trình Machine Learning của bạn ngay hôm nay!
Courses
Courses
Courses