
Cours
Machine Learning pour le business
2 h
46.2K
Les réseaux neuronaux ou réseaux neuronaux artificiels sont des outils fondamentaux de l'apprentissage automatique, qui alimentent de nombreux algorithmes et applications de pointe dans divers domaines, notamment la vision par ordinateur, le traitement du langage naturel, la robotique, etc.
Un réseau neuronal se compose de nœuds interconnectés, appelés neurones, organisés en couches. Chaque neurone reçoit des signaux d'entrée, effectue un calcul sur ces signaux à l'aide d'une fonction d'activation et produit un signal de sortie qui peut être transmis à d'autres neurones du réseau. Une fonction d'activation détermine la sortie d'un neurone en fonction de son entrée. Ces fonctions introduisent une non-linéarité dans le réseau, ce qui lui permet d'apprendre des schémas complexes dans les données.
Le réseau est généralement organisé en couches, en commençant par la couche d'entrée, où les données sont introduites. Viennent ensuite les couches cachées où les calculs sont effectués et, enfin, la couche de sortie où les prédictions ou les décisions sont prises.
Les neurones des couches adjacentes sont reliés par des connexions pondérées, qui transmettent les signaux d'une couche à l'autre. La force de ces connexions, représentée par les poids, détermine l'influence de la sortie d'un neurone sur l'entrée d'un autre neurone. Au cours du processus de formation, le réseau apprend à ajuster ses poids sur la base d'exemples fournis dans un ensemble de données de formation. En outre, chaque neurone a généralement un biais associé, qui lui permet d'ajuster son seuil de sortie.
Les réseaux neuronaux sont formés à l'aide de techniques appelées propagation ascendante et rétropropagation. Lors de la propagation ascendante, les données d'entrée sont transmises au réseau couche par couche, chaque couche effectuant un calcul sur la base des données d'entrée qu'elle reçoit et transmettant le résultat à la couche suivante.
La rétropropagation est un algorithme utilisé pour former des réseaux neuronaux en ajustant de manière itérative les poids et les biais du réseau afin de minimiser la fonction de perte. Une fonction de perte (également appelée fonction de coût ou fonction objective) est une mesure de l'adéquation entre les prédictions du modèle et les vraies valeurs cibles dans les données d'apprentissage. La fonction de perte quantifie la différence entre la sortie prédite du modèle et la sortie réelle, fournissant un signal qui guide le processus d'optimisation pendant la formation.
L'objectif de la formation d'un réseau neuronal est de minimiser cette fonction de perte en ajustant les poids et les biais. Les ajustements sont guidés par un algorithme d'optimisation, tel que la descente de gradient. Nous reviendrons sur certains de ces sujets plus en détail dans la suite de ce tutoriel.
Neurone biologique vs. Réseau neuronal artificiel Source : ResearchGate
L'ANN représenté à droite de l'image est un réseau neuronal simple appelé "perceptron". Il se compose d'une seule couche, qui est la couche d'entrée, avec plusieurs neurones dotés de leurs propres poids ; il n'y a pas de couches cachées. L'algorithme du perceptron apprend les poids des signaux d'entrée afin de tracer une frontière de décision linéaire.
Cependant, pour résoudre des problèmes non linéaires plus complexes liés au traitement d'images, à la vision par ordinateur et aux tâches de traitement du langage naturel, nous travaillons avec des réseaux neuronaux profonds.
Consultez le tutoriel Introduction aux réseaux neuronaux profonds de DataCamp pour en savoir plus sur les réseaux neuronaux profonds et comment en construire un à partir de zéro en utilisant TensorFlow et Keras en Python. Si vous préférez utiliser le langage R à la place, le cours Building Neural Network (NN) Models in R de DataCamp vous couvre.
Il existe plusieurs types d'ANN, chacun étant conçu pour des tâches et des exigences architecturales spécifiques. Examinons brièvement quelques-uns des types les plus courants avant de nous pencher plus avant sur les MLP.
Il s'agit de la forme la plus simple d'ANN, dans laquelle les informations circulent dans une seule direction, de l'entrée à la sortie. Il n'y a pas de cycles ou de boucles dans l'architecture du réseau. Les perceptrons multicouches (MLP) sont un type de réseau neuronal de type feedforward.
Dans les RNN, les connexions entre les nœuds forment des cycles dirigés, ce qui permet à l'information de persister dans le temps. Ils conviennent donc aux tâches impliquant des données séquentielles, telles que la prédiction de séries temporelles, le traitement du langage naturel et la reconnaissance vocale.
Les CNN sont conçus pour traiter efficacement des données en forme de grille, telles que des images. Ils se composent de couches de filtres convolutifs qui apprennent les représentations hiérarchiques des caractéristiques des données d'entrée. Les CNN sont largement utilisés dans des tâches telles que la classification d'images, la détection d'objets et la segmentation d'images.
Il s'agit de types spécialisés de réseaux neuronaux récurrents conçus pour résoudre le problème de l'évanouissement du gradient dans les réseaux neuronaux récurrents traditionnels. Les LSTM et les GRU intègrent des mécanismes à portes pour mieux capturer les dépendances à long terme dans les données séquentielles, ce qui les rend particulièrement efficaces pour des tâches telles que la reconnaissance vocale, la traduction automatique et l'analyse des sentiments.
Il est conçu pour l'apprentissage non supervisé et se compose d'un réseau d'encodage qui comprime les données d'entrée dans un espace latent de dimension inférieure, et d'un réseau de décodage qui reconstruit l'entrée originale à partir de la représentation latente. Les autoencodeurs sont souvent utilisés pour la réduction de la dimensionnalité, le débruitage des données et la modélisation générative.
Les GAN sont constitués de deux réseaux neuronaux, un générateur et un discriminateur, entraînés simultanément dans un cadre compétitif. Le générateur apprend à générer des échantillons de données synthétiques qui ne se distinguent pas des données réelles, tandis que le discriminateur apprend à distinguer les échantillons réels des échantillons fictifs. Les GAN ont été largement utilisés pour générer des images, des vidéos et d'autres types de données réalistes.
Un perceptron multicouche est un type de réseau neuronal feedforward composé de neurones entièrement connectés avec une fonction d'activation de type non linéaire. Il est largement utilisé pour distinguer les données qui ne sont pas linéairement séparables.
Les MLP ont été largement utilisés dans divers domaines, notamment la reconnaissance d'images, le traitement du langage naturel et la reconnaissance vocale. La flexibilité de leur architecture et leur capacité à approximer n'importe quelle fonction sous certaines conditions en font un élément fondamental de la recherche sur l'apprentissage profond et les réseaux neuronaux. Nous allons nous pencher plus en détail sur certains de ses concepts clés.
La couche d'entrée se compose de nœuds ou de neurones qui reçoivent les données d'entrée initiales. Chaque neurone représente une caractéristique ou une dimension des données d'entrée. Le nombre de neurones dans la couche d'entrée est déterminé par la dimensionnalité des données d'entrée.
Entre les couches d'entrée et de sortie, il peut y avoir une ou plusieurs couches de neurones. Chaque neurone d'une couche cachée reçoit des entrées de tous les neurones de la couche précédente (soit la couche d'entrée, soit une autre couche cachée) et produit une sortie qui est transmise à la couche suivante. Le nombre de couches cachées et le nombre de neurones dans chaque couche cachée sont des hyperparamètres qui doivent être déterminés pendant la phase de conception du modèle.
Cette couche est constituée de neurones qui produisent la sortie finale du réseau. Le nombre de neurones dans la couche de sortie dépend de la nature de la tâche. Dans la classification binaire, il peut y avoir un ou deux neurones en fonction de la fonction d'activation et représentant la probabilité d'appartenir à une classe, tandis que dans les tâches de classification multi-classes, il peut y avoir plusieurs neurones dans la couche de sortie.
Les neurones des couches adjacentes sont entièrement connectés les uns aux autres. Chaque connexion a un poids associé, qui détermine la force de la connexion. Ces poids sont appris au cours du processus de formation.
Outre les neurones d'entrée et les neurones cachés, chaque couche (à l'exception de la couche d'entrée) comprend généralement un neurone de biais qui fournit une entrée constante aux neurones de la couche suivante. Les neurones à biais ont leur propre poids associé à chaque connexion, qui est également appris au cours de la formation.
Le neurone de biais déplace effectivement la fonction d'activation des neurones de la couche suivante, ce qui permet au réseau d'apprendre un décalage ou un biais dans la limite de décision. En ajustant les poids connectés au neurone de biais, le MLP peut apprendre à contrôler le seuil d'activation et à mieux s'adapter aux données d'apprentissage.
Note : Il est important de noter que dans le contexte des MLP, le biais peut se référer à deux concepts liés mais distincts : le biais en tant que terme général dans l'apprentissage automatique et le neurone biaisé (défini ci-dessus). Dans l'apprentissage automatique général, le biais fait référence à l'erreur introduite par l'approximation d'un problème réel à l'aide d'un modèle simplifié. Le biais mesure la capacité du modèle à capturer les schémas sous-jacents des données. Un biais élevé indique que le modèle est trop simpliste et risque de ne pas correspondre aux données, tandis qu'un biais faible indique que le modèle capture bien les modèles sous-jacents.
En règle générale, chaque neurone des couches cachées et de la couche de sortie applique une fonction d'activation à la somme pondérée de ses entrées. Les fonctions d'activation les plus courantes sont la sigmoïde, le tanh, la ReLU (Rectified Linear Unit) et la softmax. Ces fonctions introduisent une non-linéarité dans le réseau, ce qui lui permet d'apprendre des schémas complexes dans les données.
Les MLP sont formés à l'aide de l'algorithme de rétropropagation, qui calcule les gradients d'une fonction de perte par rapport aux paramètres du modèle et met à jour les paramètres de manière itérative afin de minimiser la perte.
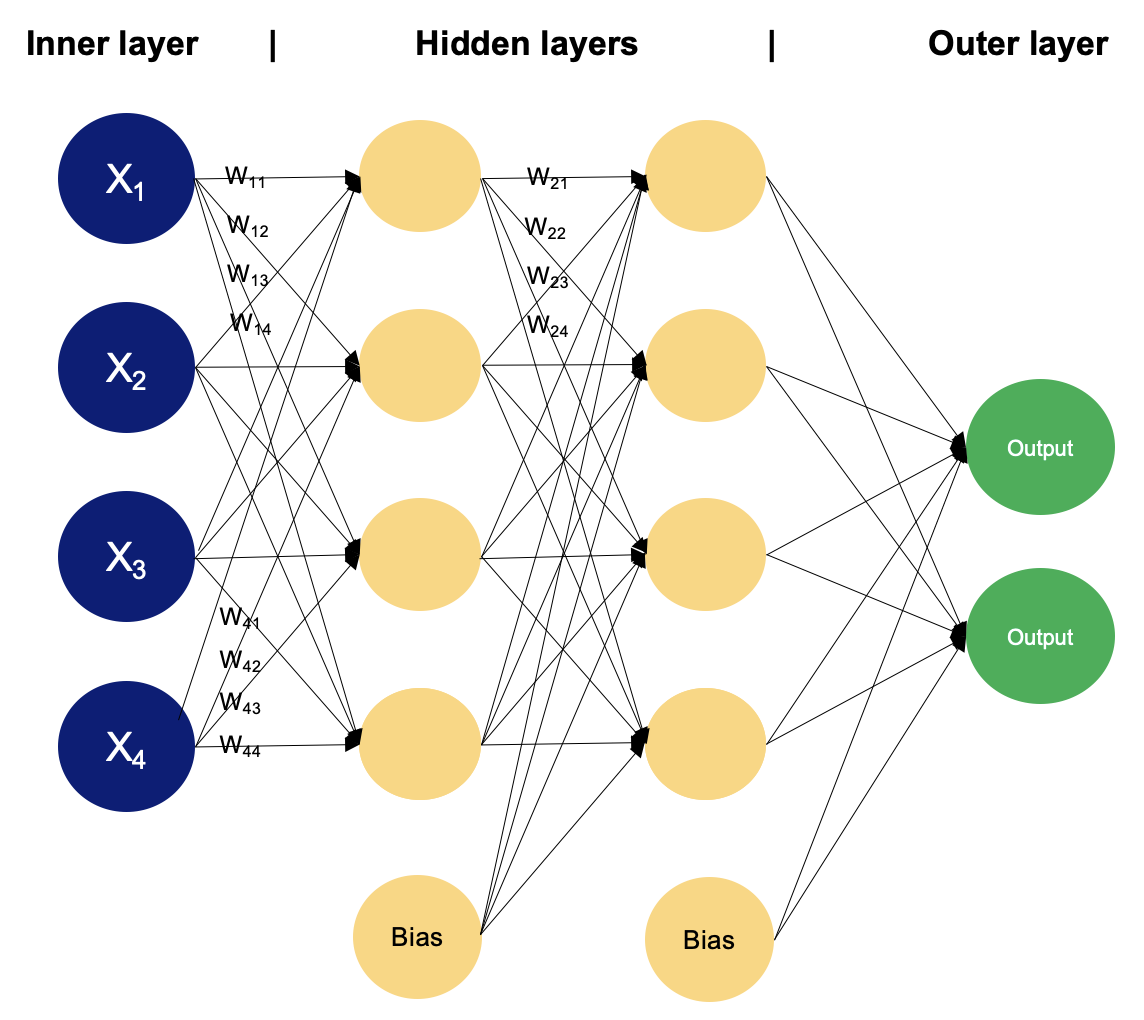
Exemple de MLP à deux couches cachées. Image par l'auteur
Dans un perceptron multicouche, les neurones traitent les informations étape par étape, en effectuant des calculs qui impliquent des sommes pondérées et des transformations non linéaires. Nous allons passer d'une couche à l'autre pour découvrir la magie qui s'y cache.
w. Les poids déterminent l'influence de l'entrée d'un neurone sur la sortie d'un autre.b. Le biais fournit une entrée supplémentaire au neurone, lui permettant d'ajuster son seuil de sortie. Comme les poids, les biais sont appris au cours de la formation.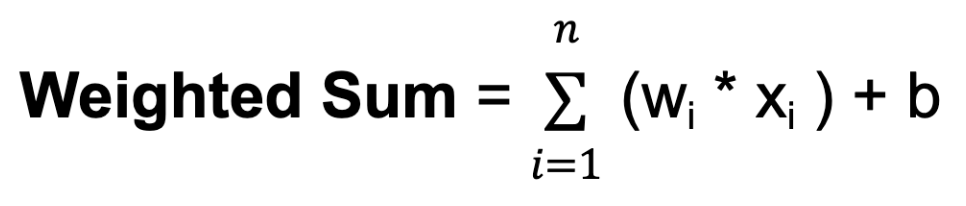
Où n est le nombre total de connexions d'entrée, wi est le poids de la i-ième entrée et xi est la i-ième valeur d'entrée.
f. La fonction d'activation introduit une non-linéarité dans le réseau, ce qui lui permet d'apprendre et de représenter des relations complexes dans les données. La fonction d'activation détermine la plage de sortie du neurone et son comportement en réponse à différentes valeurs d'entrée. Le choix de la fonction d'activation dépend de la nature de la tâche et des propriétés souhaitées du réseau.Au cours du processus de formation, le réseau apprend à ajuster les poids associés aux entrées de chaque neurone afin de minimiser l'écart entre les sorties prédites et les vraies valeurs cibles dans les données de formation. En ajustant les poids et en apprenant les fonctions d'activation appropriées, le réseau apprend à approximer des modèles et des relations complexes dans les données, ce qui lui permet de faire des prédictions précises sur de nouveaux échantillons non vus.
Cet ajustement est guidé par un algorithme d'optimisation, tel que la descente stochastique de gradient (SGD), qui calcule les gradients d'une fonction de perte par rapport aux poids et met à jour les poids de manière itérative.
Examinons de plus près le fonctionnement du SGD.
Pour chaque itération (ou époque) de l'apprentissage :
θt représente les paramètres du modèle à l'itération t. Ce paramètre peut être le poids⛛ J (θt) est le gradient de la fonction de perte J par rapport aux paramètres θtn est le taux d'apprentissage, qui contrôle la taille des pas effectués pendant l'optimisationn. Ce paramètre contrôle la taille des pas effectués vers le minimum. Si le taux d'apprentissage est trop faible, la convergence peut être lente ; s'il est trop élevé, l'algorithme peut osciller ou diverger.La descente de gradient stochastique met à jour les paramètres du modèle plus fréquemment en utilisant des sous-ensembles de données plus petits, ce qui la rend efficace sur le plan informatique, en particulier pour les grands ensembles de données. Le caractère aléatoire introduit par SGD peut avoir un effet de régularisation, empêchant le modèle de s'adapter de manière excessive aux données d'apprentissage. Il est également bien adapté aux scénarios d'apprentissage en ligne dans lesquels de nouvelles données sont disponibles de manière incrémentielle, car il peut mettre à jour le modèle rapidement avec chaque nouveau point de données ou mini-lot.
Cependant, le SGD peut également présenter certains défis, tels que l'augmentation du bruit due à la nature stochastique de l'estimation du gradient et la nécessité de régler les hyperparamètres tels que le taux d'apprentissage. Diverses extensions et adaptations de la SGD, telles que la descente stochastique du gradient en mini-lots, le momentum et les méthodes de taux d'apprentissage adaptatif comme AdaGrad, RMSProp et Adam, ont été développées pour relever ces défis et améliorer la convergence et les performances.
Vous avez vu le fonctionnement des couches du perceptron multicouche et appris ce qu'est la descente de gradient stochastique ; pour terminer, il reste un dernier sujet à aborder : la rétropropagation.
La rétropropagation est l'abréviation de "rétropropagation des erreurs". Dans le contexte de la rétropropagation, le SGD implique la mise à jour itérative des paramètres du réseau sur la base des gradients calculés lors de chaque lot de données d'apprentissage. Au lieu de calculer les gradients à partir de l'ensemble des données d'apprentissage (ce qui peut s'avérer coûteux en termes de calcul pour les grands ensembles de données), SGD calcule les gradients à partir de petits sous-ensembles aléatoires de données appelés mini-batchs. Voici un aperçu du fonctionnement de l'algorithme de rétropropagation :
La préparation des données pour l'entraînement d'un MLP implique le nettoyage, le prétraitement, la mise à l'échelle, la division, le formatage et peut-être même l'augmentation des données. En fonction des fonctions d'activation utilisées et de l'échelle des caractéristiques d'entrée, il peut être nécessaire de standardiser ou de normaliser les données. Il est souvent nécessaire d'expérimenter différentes techniques de prétraitement et d'évaluer leur impact sur les performances du modèle afin de déterminer l'approche la plus adaptée à un ensemble de données et à une tâche particuliers.
Pour en savoir plus sur la mise à l'échelle des fonctionnalités, consultez le cours Feature Engineering for Machine Learning in Python de DataCamp.
La mise en œuvre d'un MLP comporte plusieurs étapes, depuis le prétraitement des données jusqu'à l'entraînement et l'évaluation du modèle. La sélection du nombre de couches et de neurones pour un MLP implique de trouver un équilibre entre la complexité du modèle, le temps d'apprentissage et les performances de généralisation. Il n'existe pas de réponse unique, car l'architecture optimale dépend de facteurs tels que la complexité de la tâche, la quantité de données disponibles et les ressources informatiques. Cependant, voici quelques lignes directrices générales à prendre en compte lors de la mise en œuvre de la MLP :
Les perceptrons multicouches représentent une classe fondamentale et polyvalente de réseaux neuronaux artificiels qui ont contribué de manière significative à l'avancement de l'apprentissage automatique et de l'intelligence artificielle. Grâce à leurs couches interconnectées de neurones et à leurs fonctions d'activation non linéaires, les MLP sont capables d'apprendre des modèles et des relations complexes dans les données, ce qui les rend bien adaptés à un large éventail de tâches. L'histoire des MLP reflète un voyage d'exploration, de découverte et d'innovation, depuis les premiers modèles de perceptron jusqu'aux architectures modernes d'apprentissage profond qui alimentent aujourd'hui de nombreux systèmes de pointe.
Dans cet article, vous avez appris les bases des réseaux neuronaux artificiels, vous vous êtes concentré sur les perceptrons multicouches et vous avez découvert la descente de gradient stochastique et la rétropropagation. Si vous souhaitez acquérir une expérience pratique et utiliser des techniques d'apprentissage profond pour résoudre des défis du monde réel, tels que la prédiction des prix des logements, la construction de réseaux neuronaux pour modéliser des images et du texte - nous vous recommandons vivement de suivre le cursus de la boîte à outils Keras de DataCamp.
En travaillant avec Keras, vous découvrirez les réseaux neuronaux, les flux de travail des modèles d'apprentissage profond et la manière d'optimiser vos modèles. DataCamp propose également une antisèche Keras qui peut s'avérer très pratique !
Commencez dès aujourd'hui votre voyage dans le domaine de l'apprentissage automatique !
Cours
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Matt Crabtree
Tutoriel
Samuel Shaibu

