
Kurs
İş Dünyası için Machine Learning
2 sa
46.7K
Sinir ağları veya yapay sinir ağları, makine öğreniminde temel araçlardır ve bilgisayarlı görü, doğal dil işleme, robotik ve daha birçok alanda en ileri düzey algoritma ve uygulamalara güç verir.
Bir sinir ağı, katmanlar hâlinde düzenlenmiş, nöron adı verilen birbirine bağlı düğümlerden oluşur. Her nöron giriş sinyallerini alır, bunları bir aktivasyon fonksiyonu kullanarak hesaplar ve sonucu ağdaki diğer nöronlara aktarılabilecek bir çıkış sinyaline dönüştürür. Bir aktivasyon fonksiyonu, bir nöronun belirli bir girdi karşısında üreteceği çıktıyı belirler. Bu fonksiyonlar ağa doğrusal olmayanlık katar; böylece ağ, verideki karmaşık örüntüleri öğrenebilir.
Ağ genellikle, verinin sunulduğu giriş katmanıyla başlar; ardından hesaplamaların yapıldığı gizli katmanlar gelir ve son olarak tahminlerin veya kararların üretildiği çıkış katmanı yer alır.
Komşu katmanlardaki nöronlar, sinyalleri bir katmandan diğerine ileten ağırlıklı bağlantılarla birbirine bağlanır. Bu bağlantıların gücü, ağırlıklarla temsil edilir ve bir nöronun çıktısının diğer bir nöronun girdisini ne ölçüde etkilediğini belirler. Eğitim sürecinde, ağ eğitim veri kümesindeki örneklere dayanarak bu ağırlıkları ayarlamayı öğrenir. Ayrıca her nöronun, çıktısının eşik değerini ayarlamasına olanak tanıyan bir yanlılık (bias) terimi bulunur.
Sinir ağları, ileri besleme yayılımı ve geri yayılım adı verilen tekniklerle eğitilir. İleri besleme sırasında, girdi verisi katman katman ağdan geçirilir; her katman aldığı girdilere dayalı bir hesaplama yapar ve sonucu bir sonraki katmana iletir.
Geri yayılım, kayıp fonksiyonunu en aza indirmek amacıyla ağın ağırlık ve yanlılıklarını yinelemeli olarak ayarlayan bir algoritmadır. Bir kayıp fonksiyonu (maliyet fonksiyonu veya amaç fonksiyonu olarak da bilinir), modelin tahminlerinin eğitim verisindeki gerçek hedef değerlerle ne kadar örtüştüğünü ölçer. Kayıp fonksiyonu, modelin tahmini ile gerçek çıktı arasındaki farkı niceliksel olarak ifade ederek eğitim sırasında optimizasyonu yönlendiren bir sinyal sağlar.
Bir sinir ağını eğitmenin amacı, ağırlıkları ve yanlılıkları ayarlayarak bu kayıp fonksiyonunu en aza indirmektir. Bu ayarlamalar, gradyan inişi gibi bir optimizasyon algoritmasıyla yönlendirilir. Bu konuların bazılarına, bu eğitimde ilerleyen bölümlerde yeniden değineceğiz.
Biyolojik nöron vs. yapay sinir ağı (Kaynak: ResearchGate)
Görselin sağ tarafında gösterilen ANN, ‘algılayıcı’ adı verilen basit bir sinir ağıdır. Yalnızca giriş katmanından oluşur; her biri kendi ağırlıklarına sahip birden fazla nöron bulunur ve gizli katman yoktur. Algılayıcı algoritması, giriş sinyalleri için ağırlıkları öğrenerek doğrusal bir karar sınırı çizer.
Buna karşılık, görüntü işleme, bilgisayarlı görü ve doğal dil işleme gibi daha karmaşık, doğrusal olmayan sorunları çözmek için derin sinir ağlarıyla çalışırız.
Derin sinir ağları hakkında daha fazla bilgi edinmek ve Python’da TensorFlow ile Keras kullanarak sıfırdan bir ağ kurmayı öğrenmek için Derin Sinir Ağlarına Giriş eğitimimize göz atın. R dilini tercih ederseniz, R ile Sinir Ağı (NN) Modelleri Kurma yazımız da işinize yarayacaktır.
Belirli görevler ve mimari gereksinimler için tasarlanmış çeşitli ANN türleri vardır. MLP’lere geçmeden önce en yaygın türlerden bazılarını kısaca ele alalım.
Bunlar, bilginin girişten çıkışa tek yönde aktığı en basit ANN biçimleridir. Ağ mimarisinde döngü veya çevrim yoktur. Çok katmanlı algılayıcılar (MLP), ileri beslemeli sinir ağlarının bir türüdür.
RNN’lerde, düğümler arasındaki bağlantılar yönlendirilmiş döngüler oluşturur; bu da bilginin zaman içinde kalmasını sağlar. Bu özellik, zaman serisi tahmini, doğal dil işleme ve konuşma tanıma gibi sıralı veri içeren görevler için onları uygun kılar.
CNN’ler, görüntüler gibi ızgara biçimli verileri etkili şekilde işlemek üzere tasarlanmıştır. Girdi verisi içindeki özelliklerin hiyerarşik temsillerini öğrenen evrişim filtreleri katmanlarından oluşurlar. CNN’ler, görüntü sınıflandırma, nesne tespiti ve görüntü segmentasyonu gibi görevlerde yaygın olarak kullanılır.
Bunlar, geleneksel RNN’lerdeki sönümlenen gradyan sorununu ele almak üzere tasarlanmış özel yinelemeli sinir ağı türleridir. LSTM ve GRU’lar, sıralı veride uzun menzilli bağımlılıkları daha iyi yakalamak için kapılı mekanizmalar içerir ve konuşma tanıma, makine çevirisi ve duygu analizi gibi görevlerde özellikle etkilidir.
Gözetimsiz öğrenme için tasarlanmıştır ve girdiyi daha düşük boyutlu bir örtük uzaya sıkıştıran bir kodlayıcı ağ ile örtük temsilden özgün girdiyi yeniden oluşturan bir kodçözücü ağdan oluşur. Otoenkoderler sıklıkla boyut indirgeme, veri gürültü giderme ve üretici modellemede kullanılır.
GAN’ler, rekabetçi bir düzende eşzamanlı olarak eğitilen bir üretici ve bir ayırt edici olmak üzere iki sinir ağından oluşur. Üretici, gerçek veriden ayırt edilemeyen sentetik örnekler üretmeyi öğrenirken; ayırt edici, gerçek ve sahte örnekleri ayırt etmeyi öğrenir. GAN’ler, gerçekçi görüntüler, videolar ve diğer veri türlerini üretmede yaygın olarak kullanılmaktadır.
Çok katmanlı algılayıcı, doğrusal olmayan türde aktivasyon fonksiyonuna sahip, tamamen bağlı nöronlardan oluşan bir ileri beslemeli sinir ağı türüdür. Doğrusal olarak ayrıştırılamayan verileri ayırt etmek için yaygın şekilde kullanılır.
MLP’ler; görüntü tanıma, doğal dil işleme ve konuşma tanıma dâhil birçok alanda yaygın şekilde kullanılmıştır. Mimari esneklikleri ve belirli koşullar altında herhangi bir fonksiyonu yaklaşıklayabilme yetenekleri, onları derin öğrenme ve sinir ağı araştırmalarında temel bir yapı taşı yapar. Şimdi bazı kilit kavramlarına daha yakından bakalım.
Giriş katmanı, ilk girdi verisini alan düğüm veya nöronlardan oluşur. Her nöron, girdi verisinin bir özelliğini veya boyutunu temsil eder. Giriş katmanındaki nöron sayısı, girdi verisinin boyutuna göre belirlenir.
Giriş ve çıkış katmanları arasında bir veya daha fazla nöron katmanı bulunabilir. Gizli bir katmandaki her nöron, önceki katmandaki tüm nöronlardan (giriş katmanı veya başka bir gizli katman) girdi alır ve çıktısını bir sonraki katmana iletir. Gizli katman sayısı ve her gizli katmandaki nöron sayısı, model tasarım aşamasında belirlenmesi gereken hiperparametrelerdir.
Bu katman, ağın nihai çıktısını üreten nöronlardan oluşur. Çıkış katmanındaki nöron sayısı, görevin niteliğine bağlıdır. İkili sınıflandırmada, aktivasyon fonksiyonuna bağlı olarak bir sınıfa ait olma olasılığını temsil edecek şekilde bir veya iki nöron olabilir; çok sınıflı sınıflandırma görevlerinde ise çıkış katmanında birden fazla nöron bulunabilir.
Komşu katmanlardaki nöronlar tamamen bağlıdır. Her bağlantının, bağlantının gücünü belirleyen bir ağırlığı vardır. Bu ağırlıklar eğitim sürecinde öğrenilir.
Giriş ve gizli nöronlara ek olarak, her katman (giriş katmanı hariç) genellikle bir sonraki katmandaki nöronlara sabit bir giriş sağlayan bir bias nöronu içerir. Bias nöronlarının, eğitim sırasında öğrenilen kendi bağlantı ağırlıkları bulunur.
Bias nöronu, sonraki katmandaki nöronların aktivasyon fonksiyonunu fiilen kaydırarak ağın karar sınırında bir ofset veya yanlılık öğrenmesini sağlar. Bias nöronuna bağlı ağırlıklar ayarlanarak, MLP aktivasyon eşiğini denetlemeyi öğrenebilir ve eğitim verisine daha iyi uyum sağlayabilir.
Not: MLP bağlamında bias, birbiriyle ilişkili ancak farklı iki kavrama karşılık gelebilir: genel makine öğrenimi bağlamındaki önyargı (bias) ve yukarıda tanımlanan bias nöronu. Genel makine öğreniminde bias, gerçek bir dünyasal problemi basitleştirilmiş bir modelle yaklaştırmanın getirdiği hatayı ifade eder. Bias, modelin verideki temel örüntüleri ne kadar iyi yakalayabildiğini ölçer. Yüksek bias, modelin fazla basit olduğunu ve veriyi eksik öğrendiğini (underfit) gösterirken; düşük bias, modelin temel örüntüleri iyi yakaladığını gösterir.
Genellikle gizli katmanlardaki ve çıkış katmanındaki her nöron, ağırlıklı girdi toplamına bir aktivasyon fonksiyonu uygular. Yaygın aktivasyon fonksiyonları arasında sigmoid, tanh, ReLU (Düzeltilmiş Doğrusal Birim) ve softmax bulunur. Bu fonksiyonlar ağa doğrusal olmayanlık katarak, verideki karmaşık örüntülerin öğrenilmesini sağlar.
MLP’ler, bir kayıp fonksiyonunun model parametrelerine göre gradyanlarını hesaplayan ve kaybı en aza indirmek için parametreleri yinelemeli olarak güncelleyen geri yayılım algoritmasıyla eğitilir.
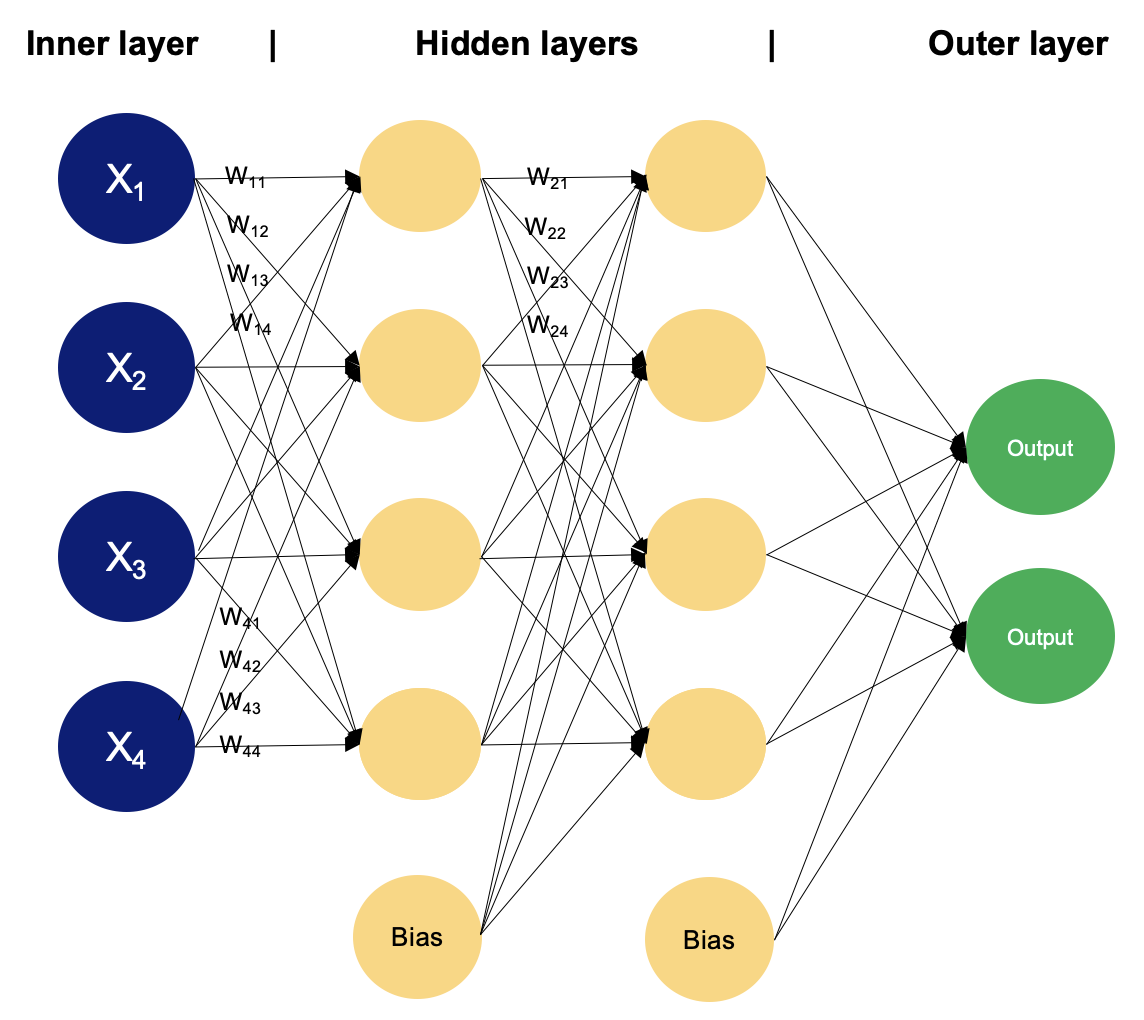
İki gizli katmanlı bir MLP örneği. Görsel: Yazar
Bir çok katmanlı algılayıcıda, nöronlar bilgiyi adım adım işler; bu süreç, ağırlıklı toplamları ve doğrusal olmayan dönüşümleri içeren hesaplamaları kapsar. İçeride neler olup bittiğini katman katman inceleyelim.
w ile gösterilen karşılık gelen ağırlıklarla çarpılır. Ağırlıklar, bir nörondan gelen girdinin diğer nöronun çıktısını ne ölçüde etkilediğini belirler.b ile gösterilen bir bias terimi vardır. Bias, nörona ek bir girdi sağlar ve çıktısının eşiğini ayarlamasına olanak tanır. Ağırlıklar gibi bias terimleri de eğitim sırasında öğrenilir.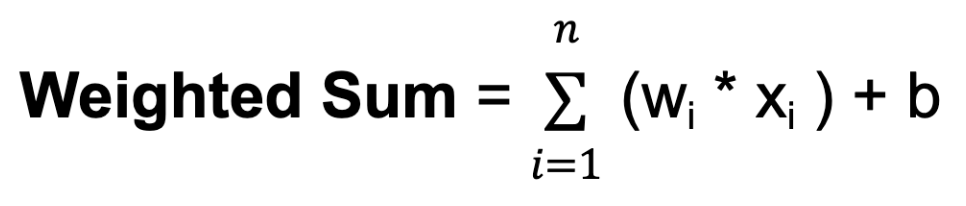
Burada n, toplam girdi bağlantısı sayısını; wi, i’nci girdi için ağırlığı ve xi ise i’nci girdi değerini ifade eder.
f ile gösterilen bir aktivasyon fonksiyonundan geçirilir. Aktivasyon fonksiyonu ağa doğrusal olmayanlık katarak, verideki karmaşık ilişkilerin öğrenilmesini ve temsil edilmesini sağlar. Aktivasyon fonksiyonu, nöronun çıktı aralığını ve farklı giriş değerlerine verdiği tepkiyi belirler. Hangi aktivasyon fonksiyonunun seçileceği, görevin niteliğine ve ağın istenen özelliklerine bağlıdır.Eğitim sürecinde, ağ; tahmin edilen çıktılar ile eğitim verisindeki gerçek hedef değerler arasındaki farkı en aza indirmek için her nöronun girdilerine ilişkin ağırlıkları ayarlamayı öğrenir. Ağırlıkları ayarlayarak ve uygun aktivasyon fonksiyonlarını öğrenerek ağ, verideki karmaşık örüntüleri ve ilişkileri yaklaşıklamayı öğrenir ve böylece yeni, görülmemiş örneklerde isabetli tahminler yapabilir.
Bu ayarlamalar, ağırlıklara göre bir kayıp fonksiyonunun gradyanlarını hesaplayan ve ağırlıkları yinelemeli olarak güncelleyen stokastik gradyan inişi (SGD) gibi bir optimizasyon algoritmasıyla yönlendirilir.
Şimdi SGD’nin nasıl çalıştığına daha yakından bakalım.
θₜ₊₁ = θₜ − η ∇J(θₜ)Burada:
θₜ, t yinelemesindeki model parametrelerini (ör. ağırlıklar ve bias’lar) temsil eder
∇J(θₜ), t yinelemesindeki parametrelere göre J kayıp fonksiyonunun gradyanıdır
η (eta), optimizasyon sırasında adım boyutunu kontrol eden öğrenme oranıdır
n olarak belirtilen öğrenme oranı parametresiyle belirlenir. Bu parametre, minimuma doğru atılan adımların büyüklüğünü kontrol eder. Öğrenme oranı çok küçükse yakınsama yavaş olabilir; çok büyükse algoritma salınım yapabilir veya ıraksayabilir.Stokastik gradyan inişi, model parametrelerini daha küçük veri altkümeleriyle daha sık güncellediği için özellikle büyük veri kümelerinde hesaplama açısından verimlidir. SGD’nin getirdiği rastgelelik, modele düzenlileştirici bir etki yaparak eğitim verisine aşırı uyum sağlamasını (overfitting) engelleyebilir. Ayrıca, yeni verinin kademeli olarak geldiği çevrimiçi öğrenme senaryoları için de uygundur; çünkü her yeni veri noktası veya mini yığınla modeli hızla güncelleyebilir.
Bununla birlikte, SGD; gradyan kestiriminin stokastik doğası nedeniyle artan gürültü ve öğrenme oranı gibi hiperparametreleri ayarlama gereksinimi gibi bazı zorluklara sahiptir. Mini yığınlı stokastik gradyan inişi, momentum ve AdaGrad, RMSProp, Adam gibi uyarlamalı öğrenme oranı yöntemleri gibi çeşitli uzantılar ve uyarlamalar; bu zorlukları ele almak ve yakınsama ile performansı iyileştirmek için geliştirilmiştir.
Çok katmanlı algılayıcının katmanlarının çalışma prensibini ve stokastik gradyan inişini gördünüz; tüm parçaları birleştirmek için son bir konuya daha girmek gerekiyor: geri yayılım.
Geri yayılım, “hataların geriye doğru yayılımı” ifadesinin kısaltmasıdır. Geri yayılım bağlamında SGD, her eğitim veri yığını sırasında hesaplanan gradyanlara dayanarak ağın parametrelerini yinelemeli olarak güncellemeyi içerir. Tüm eğitim veri kümesini kullanarak gradyanları hesaplamak (büyük veri kümeleri için hesaplama açısından pahalı olabileceğinden) yerine, SGD; mini yığın adı verilen küçük, rastgele altkümeler kullanır. İşte geri yayılım algoritmasının nasıl çalıştığına genel bir bakış:
Bir MLP’yi eğitmek için veri hazırlama; temizleme, ön işleme, ölçekleme, ayırma, biçimlendirme ve hatta gerekirse veriyi çoğaltmayı kapsar. Kullanılan aktivasyon fonksiyonlarına ve girdi özelliklerinin ölçeğine bağlı olarak verinin standartlaştırılması veya normalleştirilmesi gerekebilir. Belirli bir veri kümesi ve görev için en uygun yaklaşımı belirlemek amacıyla farklı ön işleme tekniklerini denemek ve bunların model performansına etkisini değerlendirmek çoğu zaman gereklidir.
Özellik ölçekleme hakkında daha fazla bilgi için Datacamp’in Python ile Makine Öğrenimi için Özellik Mühendisliği kursuna göz atın.
Bir MLP’yi uygulamak; veri ön işlemden model eğitimine ve değerlendirmeye uzanan çeşitli adımlar içerir. Bir MLP için katman ve nöron sayısını seçmek, model karmaşıklığı, eğitim süresi ve genelleme performansı arasında denge kurmayı gerektirir. Herkese uyan tek bir yanıt yoktur; en iyi mimari, görevin karmaşıklığı, mevcut veri miktarı ve hesaplama kaynakları gibi etkenlere bağlıdır. Ancak MLP uygularken göz önünde bulundurulabilecek bazı genel ilkeler şunlardır:
Projeniz için bir MLP seçmeden önce, nerede güçlü olduklarını ve nerede diğer mimarilerin daha uygun olabileceğini anlamak faydalıdır.
Çok katmanlı algılayıcılar, makine öğrenimi ve yapay zekânın gelişimine önemli katkıda bulunmuş, temel ve çok yönlü bir yapay sinir ağı sınıfını temsil eder. Birbirine bağlı nöron katmanları ve doğrusal olmayan aktivasyon fonksiyonları sayesinde MLP’ler, verideki karmaşık örüntüleri ve ilişkileri öğrenebilir; bu da onları geniş bir görev yelpazesi için uygun kılar. MLP’lerin tarihi, erken dönem algılayıcı modellerinden bugün birçok en ileri sistemin temelini oluşturan modern derin öğrenme mimarilerine uzanan bir keşif ve yenilik yolculuğunu yansıtır.
Bu yazıda yapay sinir ağlarının temellerini öğrendiniz; çok katmanlı algılayıcılara odaklandınız; stokastik gradyan inişi ve geri yayılımı incelediniz. Konut fiyatlarını tahmin etmek, görüntü ve metinleri modelleyen sinir ağları kurmak gibi gerçek dünya problemlerini çözmek üzere derin öğrenme tekniklerini uygulamalı olarak deneyimlemek istiyorsanız, Datacamp’in Keras araç kutusu öğrenim yolunu takip etmenizi şiddetle öneririz.
Keras ile çalışırken sinir ağlarını, derin öğrenme model iş akışlarını ve modellerinizi nasıl optimize edeceğinizi öğreneceksiniz. Ayrıca Datacamp’in işinize yarayabilecek bir Keras kopya kâğıdı da var!
Makine Öğrenimi Yolculuğunuza Bugün Başlayın!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
