
Corso
Machine Learning per il business
2 h
46.7K
Le reti neurali o reti neurali artificiali sono strumenti fondamentali nel machine learning, alla base di molti algoritmi e applicazioni allo stato dell’arte in vari ambiti, tra cui computer vision, elaborazione del linguaggio naturale, robotica e altro.
Una rete neurale è composta da nodi interconnessi, chiamati neuroni, organizzati in layer. Ogni neurone riceve segnali in ingresso, esegue un calcolo su di essi usando una funzione di attivazione e produce un segnale in uscita che può essere passato ad altri neuroni nella rete. Una funzione di attivazione determina l’output di un neurone dato il suo input. Queste funzioni introducono non linearità nella rete, permettendole di apprendere pattern complessi nei dati.
La rete è tipicamente organizzata in layer, a partire dal layer di input, dove vengono introdotti i dati. Seguono i layer nascosti, dove si effettuano i calcoli, e infine il layer di output, dove si formulano previsioni o decisioni.
I neuroni in layer adiacenti sono collegati da connessioni pesate, che trasmettono segnali da un layer al successivo. L’intensità di queste connessioni, rappresentata dai pesi, determina quanto l’output di un neurone influenzi l’input di un altro. Durante il processo di training, la rete impara ad adattare i pesi in base agli esempi forniti in un dataset di addestramento. Inoltre, ogni neurone ha tipicamente un bias associato, che consente di regolare la soglia di attivazione del neurone.
Le reti neurali vengono addestrate usando tecniche chiamate propagazione feedforward e backpropagation. Durante la propagazione feedforward, i dati in input vengono passati attraverso la rete layer per layer, con ogni layer che esegue un calcolo basato sugli input ricevuti e passa il risultato al successivo.
La backpropagation è un algoritmo usato per addestrare le reti neurali regolando iterativamente i pesi e i bias della rete per minimizzare la funzione di perdita. Una funzione di perdita (nota anche come funzione di costo o obiettivo) misura quanto bene le previsioni del modello corrispondono ai veri valori target nei dati di training. La funzione di perdita quantifica la differenza tra l’output previsto del modello e l’output reale, fornendo un segnale che guida il processo di ottimizzazione durante il training.
L’obiettivo dell’addestramento di una rete neurale è minimizzare questa funzione di perdita adattando pesi e bias. Gli aggiustamenti sono guidati da un algoritmo di ottimizzazione, come il gradient descent. Torneremo su alcuni di questi argomenti più avanti nel tutorial.
Neurone biologico vs. rete neurale artificiale (Fonte: ResearchGate)
L’ANN raffigurata a destra dell’immagine è una semplice rete neurale chiamata “perceptron”. È composta da un singolo layer, quello di input, con più neuroni dotati di propri pesi; non ci sono layer nascosti. L’algoritmo del perceptron apprende i pesi dei segnali in ingresso per tracciare un confine decisionale lineare.
Tuttavia, per risolvere problemi più complessi e non lineari legati a elaborazione delle immagini, computer vision e NLP, si utilizzano reti neurali profonde.
Dai un’occhiata al nostro tutorial Introduzione alle reti neurali profonde per saperne di più sulle deep neural network e su come costruirne una da zero con TensorFlow e Keras in Python. Se preferisci usare il linguaggio R, la nostra guida Costruire modelli di reti neurali (NN) in R fa al caso tuo.
Esistono diversi tipi di ANN, ciascuno progettato per compiti specifici e requisiti architetturali. Prima di approfondire gli MLP, vediamo brevemente alcuni dei tipi più comuni.
Sono la forma più semplice di ANN, dove l’informazione scorre in un’unica direzione, dall’input all’output. Non ci sono cicli o loop nell’architettura. I perceptroni multistrato (MLP) sono un tipo di rete neurale feedforward.
Nelle RNN, le connessioni tra nodi formano cicli direzionati, consentendo alle informazioni di persistere nel tempo. Questo le rende adatte a compiti che coinvolgono dati sequenziali, come previsione di serie temporali, NLP e riconoscimento vocale.
Le CNN sono progettate per elaborare efficacemente dati a griglia, come le immagini. Sono composte da layer di filtri convoluzionali che apprendono rappresentazioni gerarchiche delle caratteristiche nei dati di input. Le CNN sono ampiamente usate in compiti come classificazione di immagini, rilevamento di oggetti e segmentazione.
Sono tipi specializzati di reti neurali ricorrenti progettati per affrontare il problema del gradiente che svanisce nelle RNN tradizionali. LSTM e GRU incorporano meccanismi a porte per catturare meglio dipendenze di lungo raggio nei dati sequenziali, risultando particolarmente efficaci in compiti come riconoscimento vocale, traduzione automatica e analisi del sentiment.
È progettato per l’apprendimento non supervisionato e consiste in una rete encoder che comprime i dati di input in uno spazio latente a bassa dimensionalità e in una rete decoder che ricostruisce l’input originale dalla rappresentazione latente. Gli autoencoder sono spesso usati per riduzione della dimensionalità, denoising dei dati e modellazione generativa.
Le GAN sono composte da due reti neurali, un generatore e un discriminatore, addestrate simultaneamente in un contesto competitivo. Il generatore impara a creare campioni sintetici indistinguibili dai dati reali, mentre il discriminatore impara a distinguere tra campioni reali e falsi. Le GAN sono state ampiamente utilizzate per generare immagini, video e altri tipi di dati realistici.
Un perceptron multistrato è un tipo di rete neurale feedforward composto da neuroni completamente connessi con una funzione di attivazione di tipo non lineare. È ampiamente usato per distinguere dati che non sono linearmente separabili.
Gli MLP sono stati ampiamente utilizzati in vari campi, tra cui riconoscimento di immagini, elaborazione del linguaggio naturale e riconoscimento vocale, tra gli altri. La loro flessibilità architetturale e la capacità di approssimare qualsiasi funzione in determinate condizioni li rendono un blocco fondamentale nel deep learning e nella ricerca sulle reti neurali. Approfondiamo alcuni concetti chiave.
Il layer di input è composto da nodi o neuroni che ricevono i dati iniziali in ingresso. Ogni neurone rappresenta una caratteristica o dimensione dei dati di input. Il numero di neuroni nel layer di input è determinato dalla dimensionalità dei dati di ingresso.
Tra i layer di input e di output possono esserci uno o più layer di neuroni. Ogni neurone in un layer nascosto riceve input da tutti i neuroni del layer precedente (sia esso il layer di input o un altro layer nascosto) e produce un output che viene passato al layer successivo. Il numero di layer nascosti e il numero di neuroni in ciascun layer nascosto sono iperparametri da definire in fase di progettazione del modello.
Questo layer è composto da neuroni che producono l’output finale della rete. Il numero di neuroni nel layer di output dipende dalla natura del compito. Nella classificazione binaria, possono esserci uno o due neuroni a seconda della funzione di attivazione e rappresentano la probabilità di appartenenza a una classe; mentre nei compiti di classificazione multiclasse, nel layer di output possono esserci più neuroni.
I neuroni in layer adiacenti sono completamente connessi tra loro. Ogni connessione ha un peso associato, che determina la forza della connessione. Questi pesi vengono appresi durante il training.
Oltre ai neuroni di input e nascosti, ogni layer (tranne quello di input) include di solito un neurone di bias che fornisce un input costante ai neuroni del layer successivo. I neuroni di bias hanno un proprio peso associato a ciascuna connessione, che viene anch’esso appreso durante il training.
Il neurone di bias di fatto trasla la funzione di attivazione dei neuroni nel layer successivo, consentendo alla rete di apprendere un offset o bias nel confine decisionale. Regolando i pesi collegati al neurone di bias, l’MLP può controllare la soglia di attivazione e adattarsi meglio ai dati di training.
Nota: È importante notare che nel contesto degli MLP, il termine bias può riferirsi a due concetti correlati ma distinti: bias come termine generale nel machine learning e neurone di bias (definito sopra). Nel machine learning in generale, il bias si riferisce all’errore introdotto dall’approssimare un problema reale con un modello semplificato. Il bias misura quanto bene il modello riesca a catturare i pattern sottostanti nei dati. Un alto bias indica che il modello è troppo semplice e può sottostimare i dati, mentre un basso bias suggerisce che il modello sta catturando bene i pattern sottostanti.
In genere, ogni neurone nei layer nascosti e nel layer di output applica una funzione di attivazione alla somma pesata degli input. Tra le funzioni di attivazione comuni troviamo sigmoid, tanh, ReLU (Rectified Linear Unit) e softmax. Queste funzioni introducono non linearità nella rete, consentendole di apprendere pattern complessi nei dati.
Gli MLP vengono addestrati utilizzando l’algoritmo di backpropagation, che calcola i gradienti di una funzione di perdita rispetto ai parametri del modello e aggiorna i parametri in modo iterativo per minimizzare la perdita.
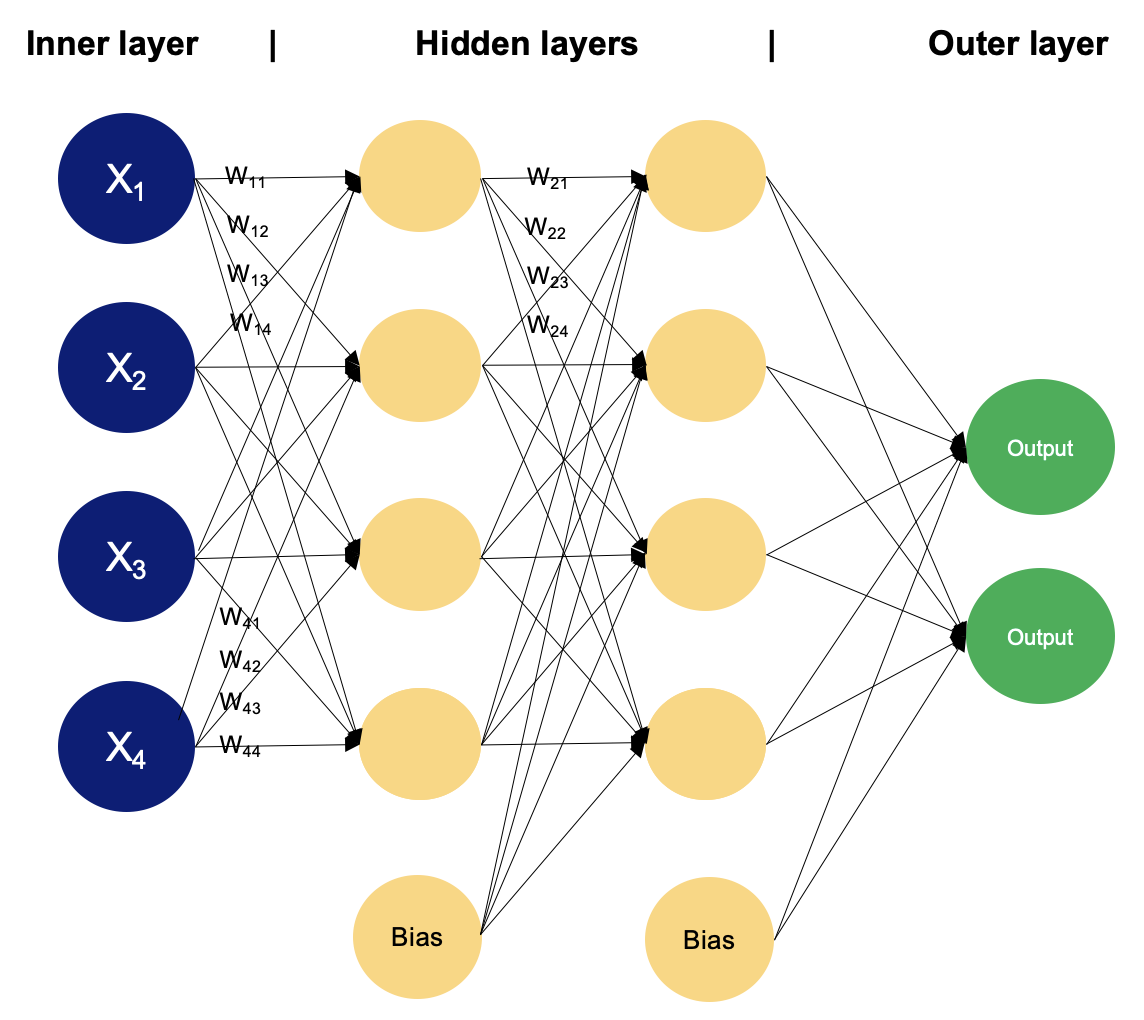
Esempio di MLP con due layer nascosti. Immagine dell’autore
In un perceptron multistrato, i neuroni elaborano le informazioni in modo graduale, eseguendo calcoli che coinvolgono somme pesate e trasformazioni non lineari. Vediamo layer per layer cosa succede “dietro le quinte”.
w. I pesi determinano quanto l’input di un neurone influenzi l’output di un altro.b. Il bias fornisce un input aggiuntivo al neurone, consentendogli di regolare la soglia di output. Come i pesi, anche i bias vengono appresi durante il training.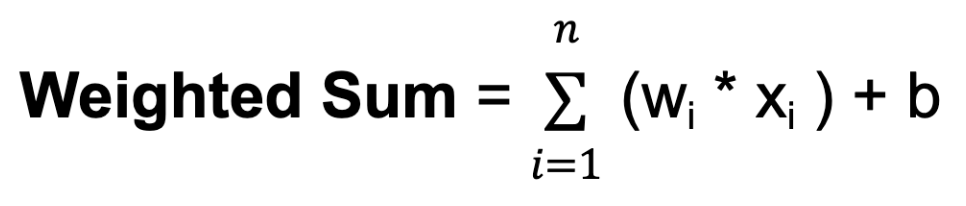
Dove n è il numero totale di connessioni in ingresso, wi è il peso per il i-esimo input e xi è il valore del i-esimo input.
f. La funzione di attivazione introduce non linearità nella rete, consentendole di apprendere e rappresentare relazioni complesse nei dati. La funzione di attivazione determina l’intervallo di output del neurone e il suo comportamento in risposta a diversi valori di input. La scelta della funzione di attivazione dipende dalla natura del compito e dalle proprietà desiderate della rete.Durante il training, la rete impara ad adattare i pesi associati agli input di ciascun neurone per minimizzare la discrepanza tra gli output previsti e i veri valori target nei dati di addestramento. Regolando i pesi e imparando le funzioni di attivazione appropriate, la rete apprende ad approssimare pattern e relazioni complesse nei dati, consentendole di fare previsioni accurate su nuovi campioni mai visti.
Questo adattamento è guidato da un algoritmo di ottimizzazione, come lo stochastic gradient descent (SGD), che calcola i gradienti di una funzione di perdita rispetto ai pesi e aggiorna i pesi in modo iterativo.
Vediamo più da vicino come funziona l’SGD.
θₜ₊₁ = θₜ − η ∇J(θₜ)Dove:
θₜ rappresenta i parametri del modello (ad es., pesi e bias) all’iterazione t
∇J(θₜ) è il gradiente della funzione di perdita J rispetto ai parametri all’iterazione t
η (eta) è il learning rate, che controlla l’ampiezza del passo durante l’ottimizzazione
n. Questo parametro controlla la dimensione dei passi verso il minimo. Se è troppo piccolo, la convergenza può essere lenta; se è troppo grande, l’algoritmo può oscillare o divergere.Lo stochastic gradient descent aggiorna i parametri del modello più frequentemente usando sottoinsiemi di dati più piccoli, rendendolo computazionalmente efficiente, specialmente con dataset di grandi dimensioni. La casualità introdotta dall’SGD può avere un effetto di regolarizzazione, impedendo al modello di overfittare i dati di training. È anche adatto a scenari di apprendimento online in cui nuovi dati sono disponibili in modo incrementale, poiché può aggiornare rapidamente il modello con ogni nuovo dato o mini-batch.
Tuttavia, l’SGD presenta anche alcune sfide, come un aumento del rumore dovuto alla natura stocastica della stima del gradiente e la necessità di mettere a punto iperparametri come il learning rate. Sono state sviluppate varie estensioni e adattamenti dell’SGD, come mini-batch stochastic gradient descent, momentum e metodi a learning rate adattivo come AdaGrad, RMSProp e Adam, per affrontare queste sfide e migliorare convergenza e prestazioni.
Hai visto il funzionamento dei layer del perceptron multistrato e hai imparato lo stochastic gradient descent; per completare il quadro, manca un ultimo argomento da approfondire: la backpropagation.
Backpropagation è l’abbreviazione di “propagazione all’indietro degli errori”. Nel contesto della backpropagation, l’SGD comporta l’aggiornamento iterativo dei parametri della rete in base ai gradienti calcolati in ciascun batch di dati di training. Invece di calcolare i gradienti usando l’intero dataset di training (operazione che può essere costosa per dataset di grandi dimensioni), l’SGD calcola i gradienti usando piccoli sottoinsiemi casuali dei dati chiamati mini-batch. Ecco una panoramica di come funziona l’algoritmo di backpropagation:
Preparare i dati per addestrare un MLP comporta pulizia, pre-elaborazione, scaling, suddivisione, formattazione e talvolta anche aumento dei dati. In base alle funzioni di attivazione utilizzate e alla scala delle feature di input, i dati potrebbero dover essere standardizzati o normalizzati. Sperimentare diverse tecniche di preprocessing e valutarne l’impatto sulle prestazioni del modello è spesso necessario per determinare l’approccio più adatto a un dato dataset e compito.
Per saperne di più sul feature scaling, dai un’occhiata al corso di Datacamp Feature Engineering for Machine Learning in Python.
Implementare un MLP comporta diversi passaggi, dal preprocessing dei dati al training e alla valutazione del modello. La scelta del numero di layer e neuroni per un MLP richiede di bilanciare complessità del modello, tempi di training e capacità di generalizzazione. Non esiste una soluzione valida per tutti: l’architettura ottimale dipende dalla complessità del compito, dalla quantità di dati disponibili e dalle risorse computazionali. Ecco comunque alcune linee guida generali da considerare quando implementi un MLP:
Prima di scegliere un MLP per il tuo progetto, è utile capire dove eccellono e dove altre architetture potrebbero essere più adatte.
I perceptroni multistrato rappresentano una classe fondamentale e versatile di reti neurali artificiali che ha contribuito in modo significativo all’avanzamento del machine learning e dell’intelligenza artificiale. Grazie ai loro layer interconnessi di neuroni e alle funzioni di attivazione non lineari, gli MLP sono in grado di apprendere pattern e relazioni complesse nei dati, rendendoli adatti a un’ampia gamma di compiti. La storia degli MLP riflette un percorso di esplorazione, scoperta e innovazione, dai primi modelli di perceptron alle moderne architetture di deep learning che alimentano molti sistemi allo stato dell’arte di oggi.
In questo articolo hai appreso le basi delle reti neurali artificiali, ti sei concentrato sui perceptroni multistrato e hai imparato lo stochastic gradient descent e la backpropagation. Se vuoi fare pratica e usare tecniche di deep learning per affrontare sfide reali, come prevedere i prezzi delle case o costruire reti neurali per modellare immagini e testi, ti consigliamo vivamente il percorso Keras toolbox di Datacamp.
Lavorando con Keras, imparerai le reti neurali, i workflow dei modelli di deep learning e come ottimizzare i tuoi modelli. Datacamp ha anche una cheat sheet di Keras molto utile!
Inizia oggi il tuo percorso nel Machine Learning!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

