
Kursus
Pemasukan Data yang Efisien dengan pandas
4 Hr
63.2K
Saat bekerja dengan sebuah dataset, misalnya yang memiliki 10.000 baris dan 50 kolom, mendapatkan gambaran cepat atas dataset tersebut bisa menjadi tantangan. Di sinilah pandas Profiling sangat berguna. Alat ini menyederhanakan proses dengan menghasilkan laporan komprehensif atas dataset Anda, sehingga meminimalkan waktu untuk menjelajahi dataset berukuran besar.
Dalam artikel ini, Anda akan mempelajari cara memulai dengan alat yang sebelumnya dikenal sebagai pandas Profiling. Nama paket pandas-profiling baru-baru ini diubah menjadi ydata-profiling. Dalam tutorial ini, Anda akan mempelajari cara menghasilkan laporan profil dari dataset, apa saja isi laporan profil, cara membacanya, dan akhirnya, cara menyimpan laporan tersebut untuk penggunaan lebih lanjut.
Pandas Profiling digunakan untuk menghasilkan laporan yang lengkap dan menyeluruh untuk sebuah dataset, dengan banyak fitur dan kustomisasi di dalam laporan yang dihasilkan. Laporan ini mencakup berbagai informasi seperti statistik dataset, distribusi nilai, nilai yang hilang, penggunaan memori, dan lain-lain, yang sangat berguna untuk menjelajah dan menganalisis data secara efisien.
Pandas Profiling juga sangat membantu dalam Exploratory Data Analysis (EDA). EDA digunakan untuk memahami struktur dasar data, mendeteksi pola, dan menghasilkan wawasan dalam format visual.
Untuk EDA, kita biasanya harus menulis banyak baris kode, yang terkadang dapat menjadi kompleks dan memakan waktu, namun hal ini dapat diotomatisasi menggunakan Pandas Profiling hanya dengan beberapa baris kode.
Jika Anda butuh pengingat tentang EDA, baca Python Exploratory Data Analysis.
Berikut contoh laporan profil:
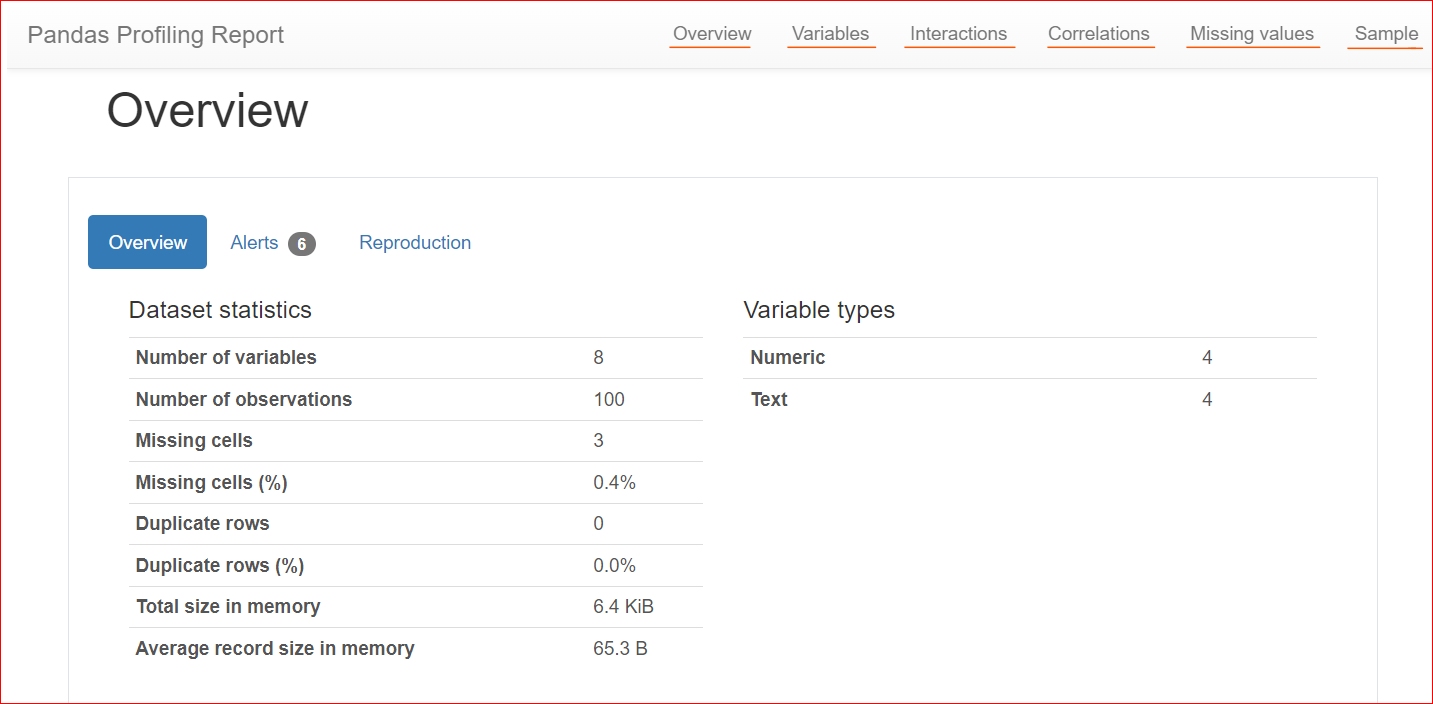
Gambar oleh Penulis
Pandas profiling banyak digunakan dalam EDA karena kemudahan penggunaan, efisiensi waktu, dan laporan HTML yang interaktif. Namun, ada beberapa potensi kekurangan saat menggunakannya pada dataset besar.
Untuk menginstal pandas Profiling, Anda dapat menggunakan pip atau conda, sesuai preferensi dan lingkungan Anda.
Menggunakan Pip:
Buka command prompt atau terminal dan jalankan perintah berikut:
pip install ydata-profilingMenggunakan Conda:
Buka Anaconda PowerShell Prompt dan jalankan perintah berikut:
conda install -c conda-forge ydata-profilingSetelah instalasi selesai, impor ydata-profiling menggunakan pernyataan berikut.
from ydata_profiling import ProfileReportIni akan mengimpor kelas ProfileReport dari pustaka ydata_profiling. Anda dapat menggunakan kelas ini untuk menghasilkan laporan profil untuk DataFrame Anda.
Untuk membuat laporan profil, ikuti langkah-langkah berikut:
ydata_profiling.ProfileReport() dan oper DataFrame tersebut.Berikut kode sederhana yang mengikuti langkah-langkah di atas. Pertama, kita mengimpor pustaka yang diperlukan lalu membaca file CSV menggunakan fungsi read_csv(). Dalam contoh ini, kita menggunakan file CSV Ulasan 100 Buku Terlaris Teratas. Selanjutnya, kita menggunakan kelas ProfileReport dan mengoper DataFrame kita ke dalamnya.
Selain itu, kita menetapkan judul baru, "Trending Books". Secara default, judulnya berbeda, tetapi jika Anda ingin menyesuaikannya, gunakan variabel title di dalam kelas. Terakhir, untuk membuat dan menampilkan laporan, Anda dapat menggunakan profile atau profile.to_notebook_iframe().
Laporan akan dibuat dalam urutan berikut: Pertama, seluruh dataset akan diringkas. Lalu, struktur laporan akan dibuat. Terakhir, laporan akan ditampilkan, yang dapat Anda simpan sebagai file HTML dan gunakan untuk analisis lebih lanjut.

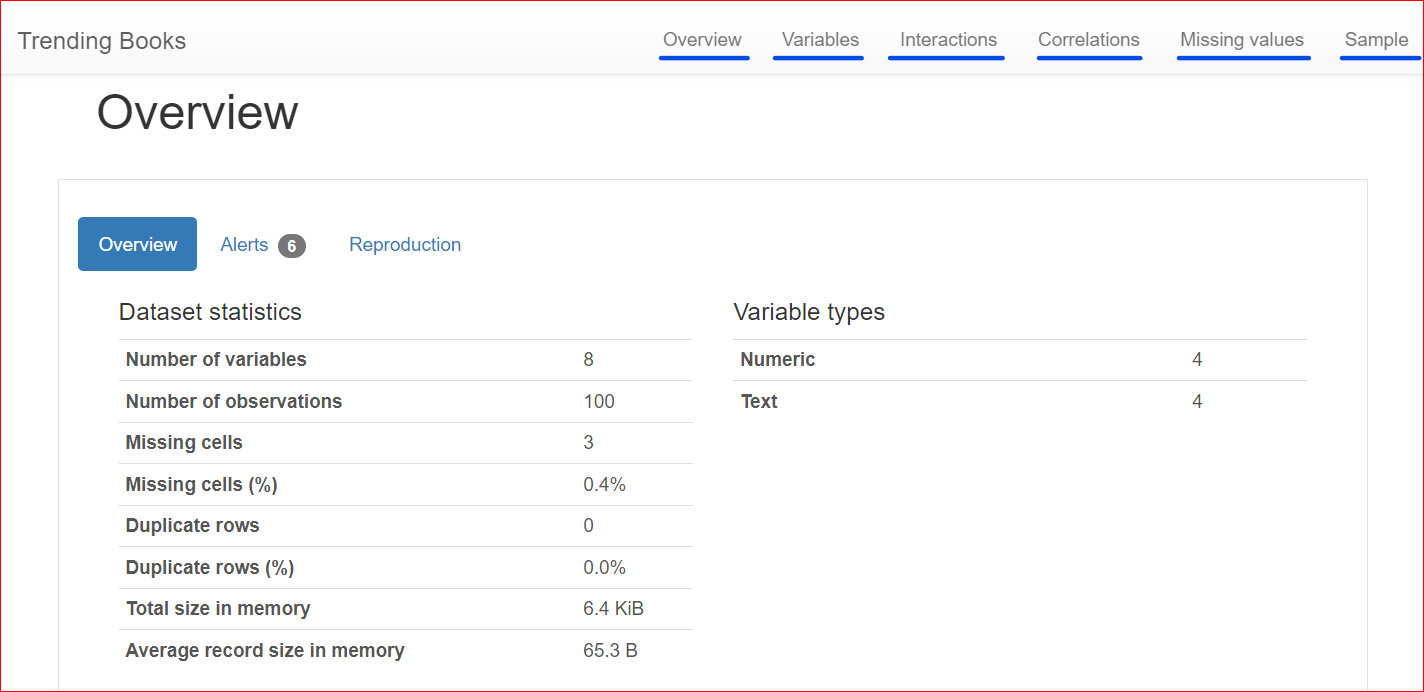
Berikut adalah laporan yang dihasilkan, yang mencakup berbagai bagian seperti Overview, Variables, Interactions, Correlations, Missing Values, dan Sample.
Jika Anda baru dalam EDA dan khususnya data profiling, baca Exploratory Data Analysis of Craft Beers: Data Profiling.
Laporan dibuat dalam banyak bagian, mari kita jelajahi semua bagiannya satu per satu.
Bagian ini terdiri dari 3 tab: Overview, Alerts, dan Reproduction.
Tab Overview mencakup statistik dataset, seperti jumlah variabel (atau jumlah kolom berbeda), jumlah sel yang memiliki nilai hilang, baris duplikat, dan ukuran dataset di memori.
Dalam dataset kita, terdapat total 8 variabel atau kolom. Di antara variabel tersebut, empat bersifat numerik (peringkat, harga buku, rating, dan tahun terbit), sementara empat lainnya berbasis teks (judul buku, penulis, genre, dan URL). Tidak ada baris duplikat, ditunjukkan oleh hitungan 0 untuk duplikat. Selain itu, kolom 'rating' memiliki tiga nilai yang hilang.
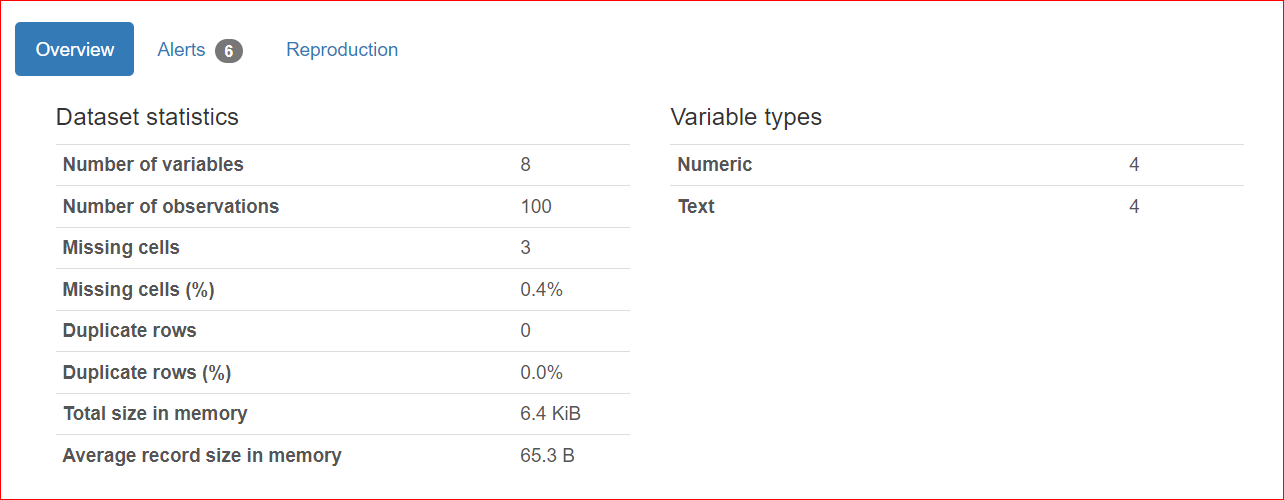
Tab Alerts berisi peringatan terkait korelasi dengan variabel lain, nilai hilang, nilai unik, nilai nol, dan sebagainya.
Dalam kasus kita, kolom URL dan Rank memiliki nilai unik, dan kolom rating memiliki tiga nilai yang hilang.
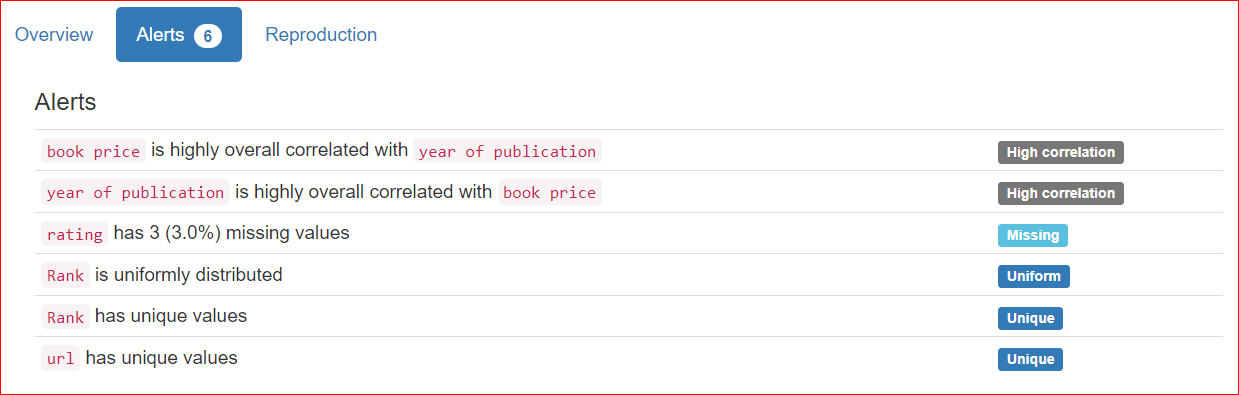
Tab Reproduction menunjukkan kapan analisis dimulai dan kapan berakhir. Tab ini menampilkan durasi analisis, termasuk versi perangkat lunak yang Anda gunakan (dalam kasus saya, ydata-profiling v4.6.1).
Bagian Variables mencakup semua kolom dalam dataset Anda. Anda dapat mengeklik panah toggle dan memilih kolom apa pun.
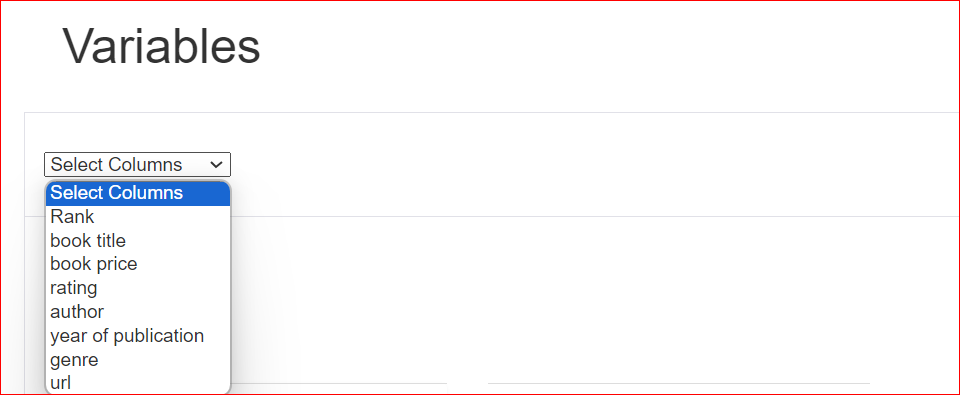
Misalkan Anda memilih kolom rating, laporan menunjukkan bahwa kolom ini berisi 10 nilai unik yang terdistribusi di 100 baris. Selain itu, ada tiga sel yang tidak memiliki nilai. Nilai minimum adalah 4,1, sedangkan maksimum adalah 5. Rata-rata semua rating juga ditampilkan.
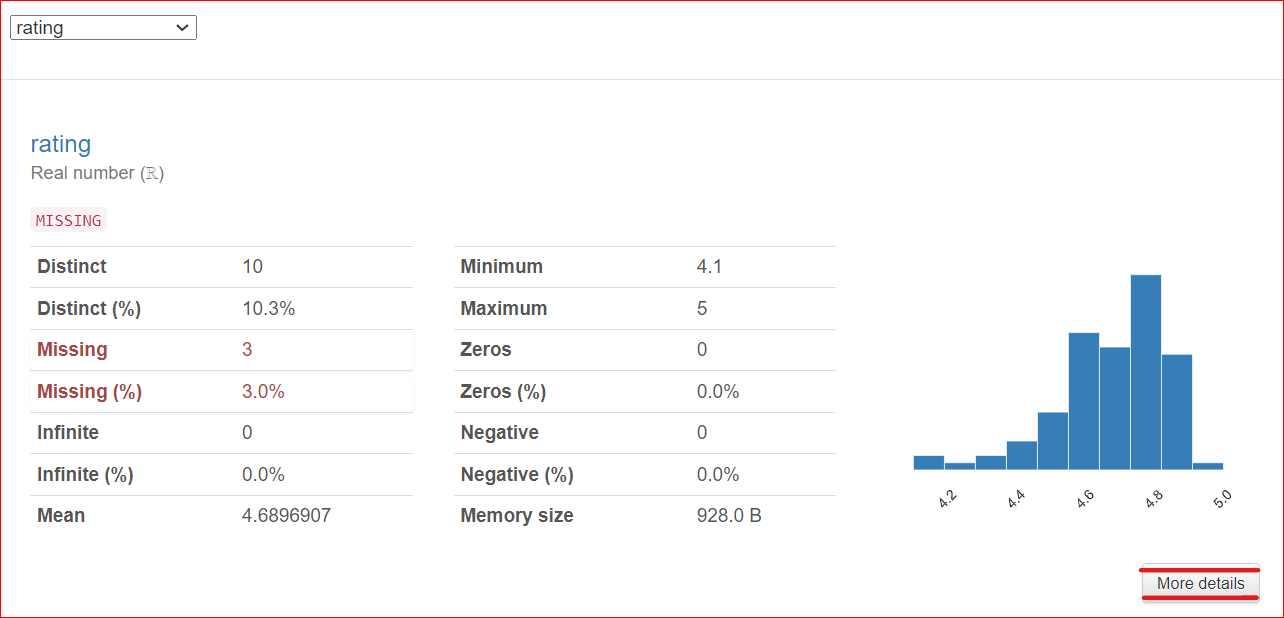
Catatan penting: terdapat tombol More Details di pojok kanan bawah. Mengeklik tombol ini memberikan akses ke informasi lebih lanjut tentang kolom rating, seperti median, standar deviasi, koefisien variasi, dan berbagai karakteristik lainnya yang terkait dengan kolom tersebut.
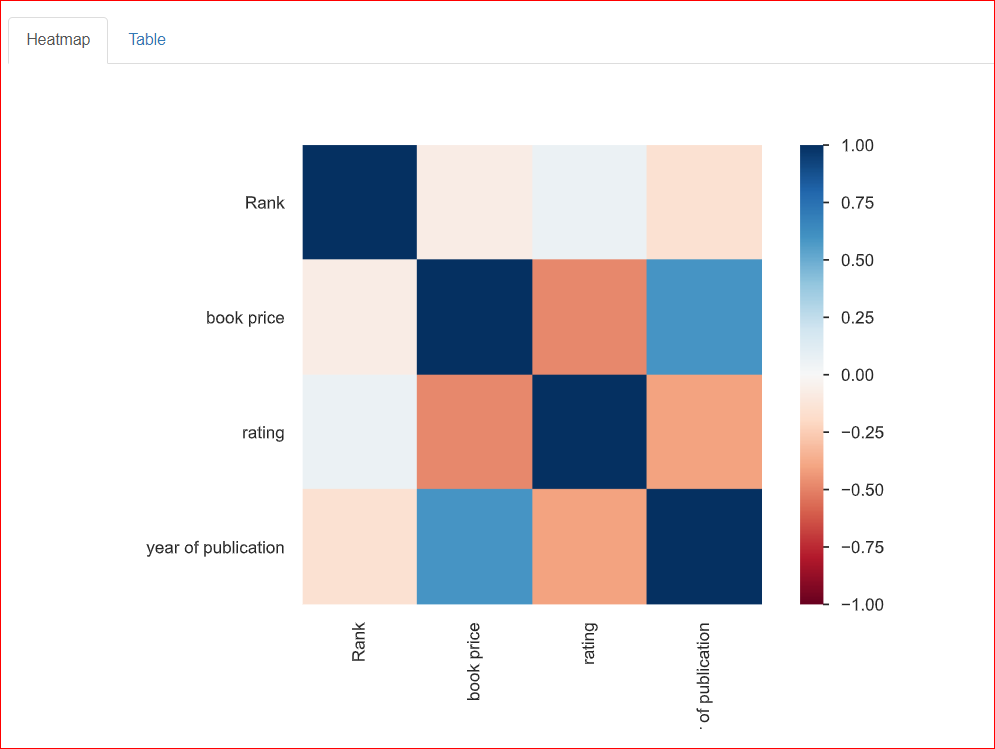
Bagian ini membantu mempelajari hubungan antara dua variabel, yang dikenal sebagai korelasi. Heatmap di bawah menunjukkan hubungan antar semua variabel satu sama lain. Rank berhubungan 100% dengan Rank, sehingga direpresentasikan oleh kotak biru tua di kiri atas.
Tahun terbit memiliki hubungan sedang dengan harga buku (sekitar 0,75), yang direpresentasikan oleh warna biru muda karena keduanya tidak sepenuhnya berkorelasi. Misalnya, harga buku 20,93 dan tahun terbit 2023, sehingga angka-angka ini agak saling berkaitan.
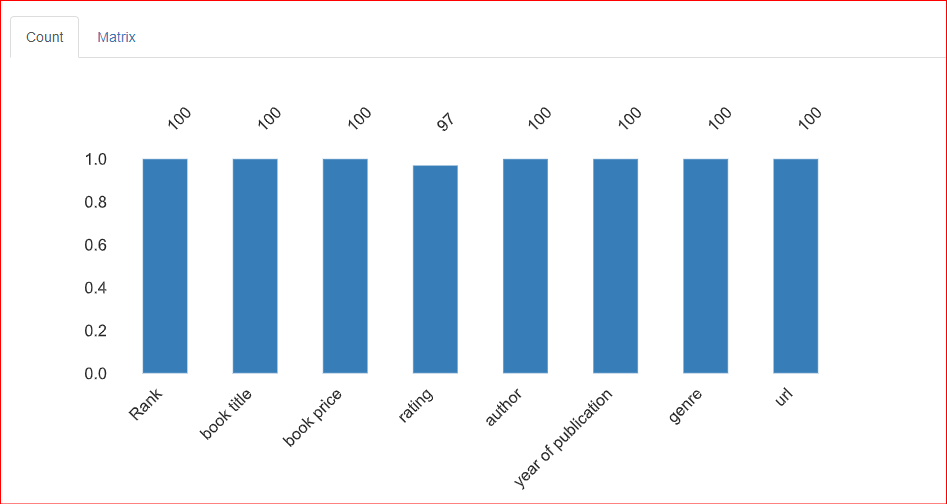
Bagian ini memberikan informasi tentang nilai yang hilang dalam dataset. Tab Count pada bagian ini menunjukkan bahwa ada 3 nilai yang hilang di kolom rating.
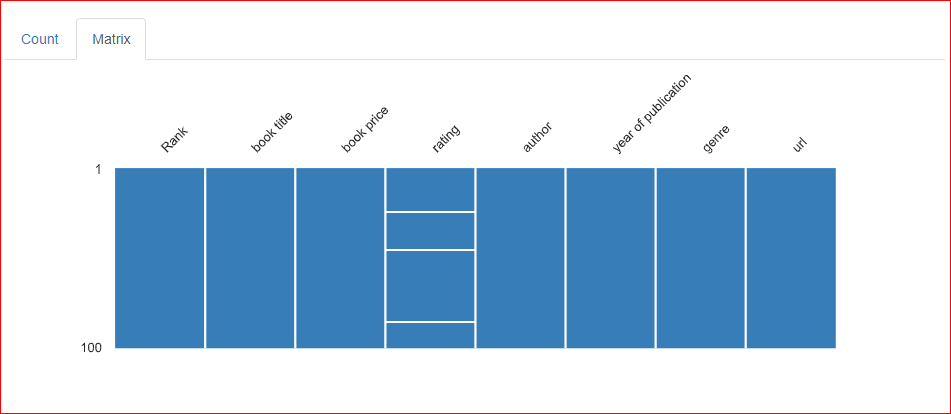
Pada tab Matrix dari bagian nilai hilang, terdapat tiga garis horizontal pada kolom Rating, yang menunjukkan bahwa ada tiga nilai yang hilang di kolom tersebut.
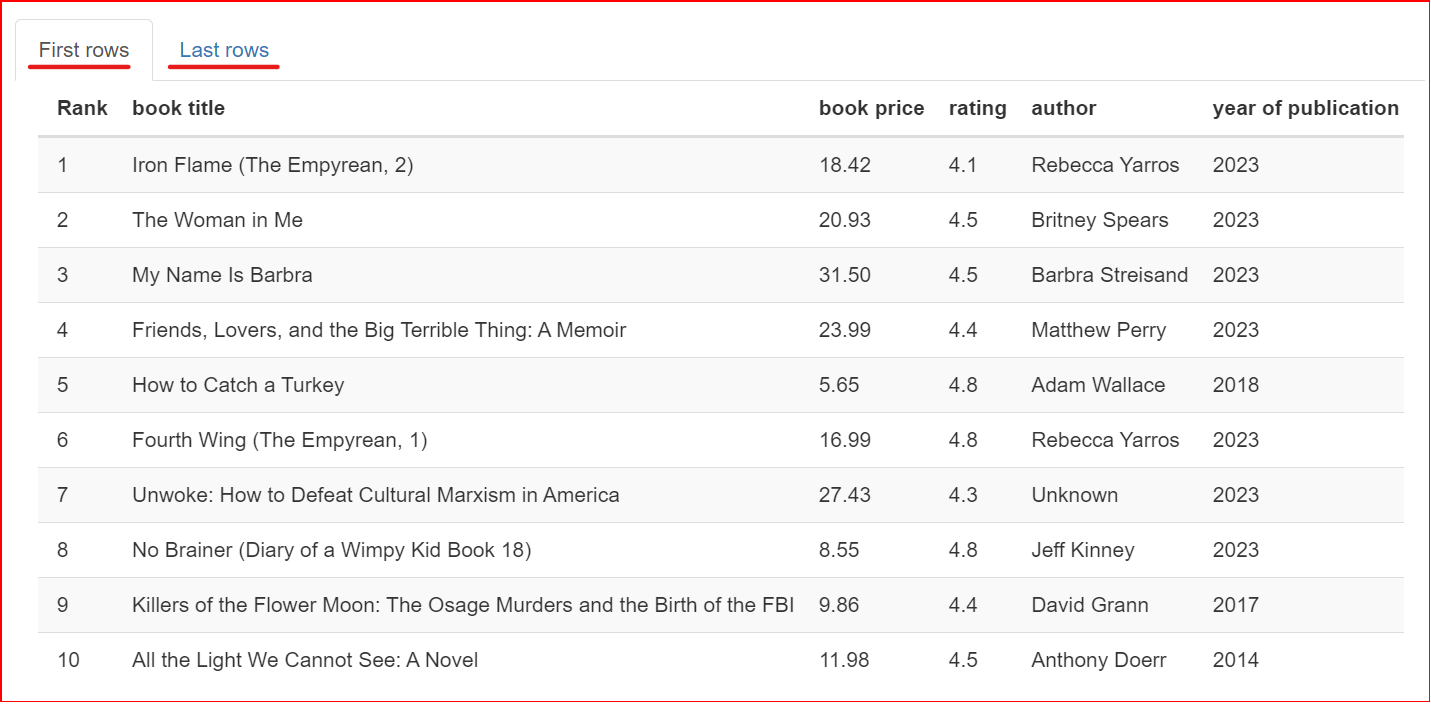
Bagian ini berisi sampel dataset. Bagian ini menampilkan 10 baris pertama dan terakhir dari dataset.
Laporan profil Anda telah dibuat, dan Anda mungkin ingin menyimpannya untuk penggunaan lebih lanjut, seperti mengekstrak data berguna dari laporan profil atau mengintegrasikannya dengan aplikasi lain. Anda dapat menyimpan laporan dalam format HTML dan JSON. Metode to_file() akan menyimpan laporan di luar Jupyter Notebook.
Berikut kode lengkap untuk pandas profiling:
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Untuk membuat laporan, kita cukup mengoper file CSV dan tidak ada yang lain. Kita tidak menyertakan elemen tambahan; hanya nilai default yang digunakan dalam tindakannya.
Namun, mungkin ada bagian yang ingin Anda hilangkan atau sertakan informasi tambahan. Di sinilah penggunaan lanjutan Pandas Profiling berperan. Anda dapat mengendalikan berbagai aspek laporan dengan mengubah konfigurasi default.
Jika Anda tertarik mempelajari lebih lanjut tentang alat analisis dan visualisasi data, baca 21 Essential Python Tools.
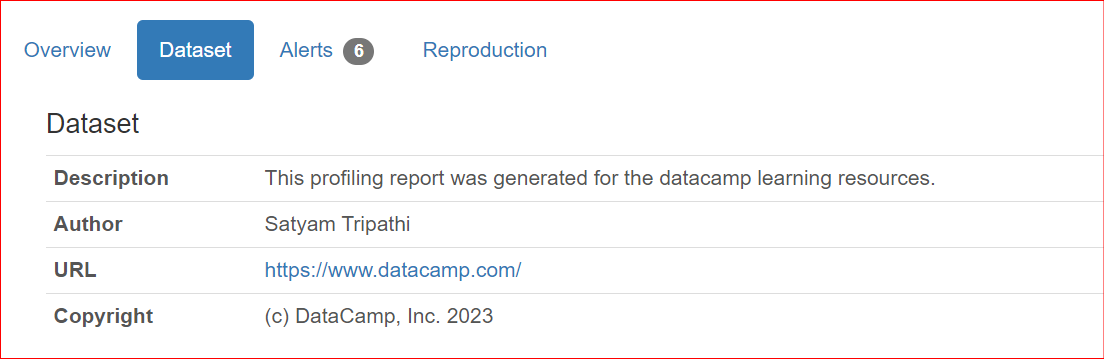
Saat berbagi laporan dengan rekan kerja atau memublikasikannya secara daring, mungkin penting untuk menyertakan metadata dataset, seperti penulis, pemegang hak cipta, atau deskripsi. ydata-profiling memungkinkan Anda melengkapi laporan dengan informasi tersebut.
Properti yang saat ini didukung adalah description, creator, author, url, copyright_year, dan copyright_holder. Secara default, dataset tersebut ditampilkan di bagian Overview dari laporan.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()Berikut keluaran kodenya:
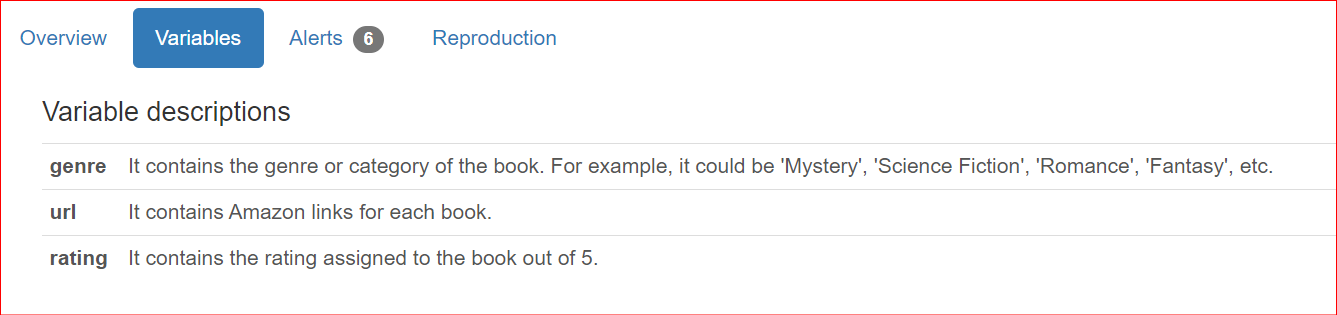
Selain menawarkan detail dataset, pengguna sering ingin menyertakan deskripsi spesifik kolom saat berbagi laporan dengan anggota tim dan pemangku kepentingan. Secara default, deskripsi ini ditampilkan di bagian Overview dari laporan.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()Berikut keluaran kodenya:
Secara default, ydata-profiling merangkum dataset masukan secara komprehensif untuk memberikan wawasan terbanyak bagi analisis data. Untuk dataset kecil, perhitungan ini dapat dilakukan dengan cepat. Namun, untuk dataset yang lebih besar, hal ini bisa menjadi terlalu berat.
ydata-profiling menyertakan berkas konfigurasi minimal di mana perhitungan yang paling mahal dimatikan secara default. Konfigurasi ini mengecualikan bagian yang memakan waktu seperti korelasi, interaksi, dan sebagainya.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling juga menyediakan beberapa alternatif untuk mengatasi tantangan penanganan dataset besar. Jelajahi alternatif tersebut di sini.
Dalam artikel ini, Anda mempelajari pustaka unik, ydata-profiling, sebelumnya dikenal sebagai "Pandas Profiling," untuk membuat laporan hanya dengan beberapa baris kode. Anda mempelajari cara menghasilkan laporan profil dan menelusuri semua bagian serta tab yang ada di dalamnya. Yang terpenting, Anda mempelajari penggunaan lanjutan pustaka ini, yang akan membawa Anda selangkah lebih maju dalam perjalanan data science Anda.
Pandas adalah pustaka Python paling populer di dunia, digunakan untuk segala hal mulai dari manipulasi data hingga analisis data. Untuk mempelajari cara memanipulasi DataFrame saat Anda mengekstrak, memfilter, dan mentransformasi dataset dunia nyata untuk analisis, lihat kursus kami tentang Data Manipulation with pandas.
Jelajahi Lebih Banyak Penggunaan pandas
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
