
Cursus
Gestroomlijnde data-inname met pandas
4 Hr
63.2K
Als je met een dataset werkt, bijvoorbeeld met 10.000 rijen en 50 kolommen, is het best een uitdaging om daar snel een goed overzicht van te krijgen. Daar komt pandas Profiling goed van pas. Het automatiseert het proces door een uitgebreid rapport van je dataset te genereren, zodat je minder tijd kwijt bent aan het verkennen van grote datasets.
In dit artikel leer je hoe je aan de slag gaat met wat voorheen bekendstond als pandas Profiling. De pakketnaam pandas-profiling is recent gewijzigd in ydata-profiling. In deze tutorial leer je hoe je een profilerapport uit de dataset genereert, wat er in het rapport staat, hoe je het leest en tot slot hoe je het opslaat voor later gebruik.
Pandas Profiling wordt gebruikt om een volledig en gedetailleerd rapport van de dataset te genereren, met veel mogelijkheden en aanpassingen in het rapport. Dit rapport bevat allerlei informatie, zoals datasetstatistieken, de verdeling van waarden, ontbrekende waarden, geheugengebruik, enzovoort, wat erg handig is om data efficiënt te verkennen en te analyseren.
Pandas Profiling helpt ook veel bij Exploratory Data Analysis (EDA). EDA wordt gebruikt om de onderliggende structuur van data te begrijpen, patronen te detecteren en inzichten te genereren in een visueel formaat.
Voor EDA moeten we vaak veel regels code schrijven, wat soms complex en tijdrovend kan zijn, maar met Pandas Profiling kun je dat automatiseren met slechts een paar regels code.
Heb je een opfrisser nodig voor EDA? Lees dan Python Exploratory Data Analysis.
Hier is een voorbeeld van een profilerapport:
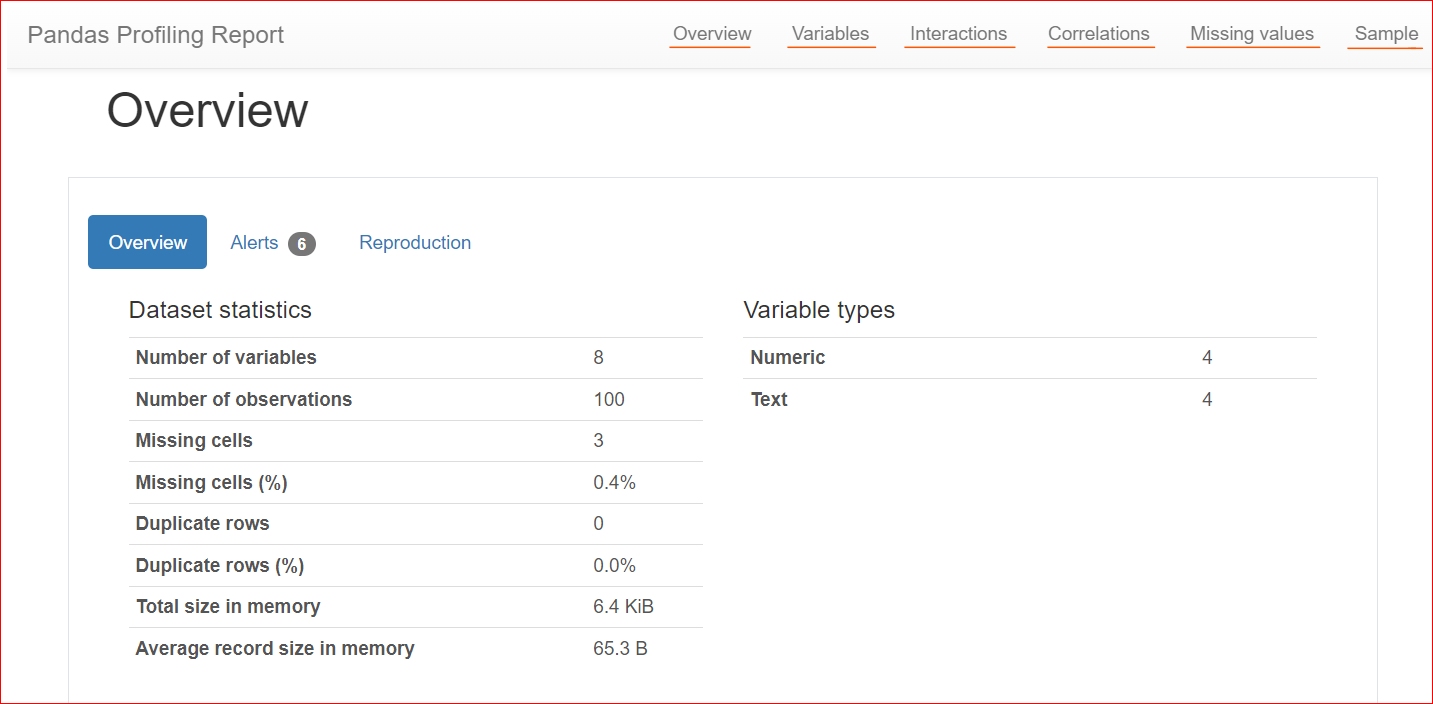
Afbeelding door de auteur
Pandas profiling wordt veel gebruikt in EDA vanwege het gebruiksgemak, de tijdswinst en de interactieve HTML-rapporten. Er zijn echter ook enkele mogelijke nadelen bij het gebruik van pandas profiling met grote datasets.
Om pandas Profiling te installeren, kun je afhankelijk van je voorkeur en omgeving pip of conda gebruiken.
Met Pip:
Open een opdrachtprompt of terminal en voer de volgende opdracht uit:
pip install ydata-profilingMet Conda:
Open de Anaconda PowerShell Prompt en voer de volgende opdracht uit:
conda install -c conda-forge ydata-profilingImporteer na een succesvolle installatie ydata-profiling met de volgende regel.
from ydata_profiling import ProfileReportDit importeert de klasse ProfileReport uit de bibliotheek ydata_profiling. Met deze klasse kun je profilerapporten genereren voor je DataFrames.
Volg de onderstaande stappen om een profilerapport te genereren:
ydata_profiling.ProfileReport() en geef het DataFrame door.Hier is de eenvoudige code die de bovenstaande stappen volgt. Eerst importeren we de benodigde bibliotheken en lezen we vervolgens het CSV-bestand in met de functie read_csv(). In dit geval gebruiken we het CSV-bestand van de Top 100 Bestselling Book Reviews. Daarna gebruiken we de klasse ProfileReport en geven ons DataFrame door.
Daarnaast stellen we een nieuwe titel in, "Trending Books". Standaard is de titel iets anders, maar als je deze wilt aanpassen, gebruik dan de variabele title binnen de klasse. Tot slot kun je om het rapport te genereren en weer te geven profile of profile.to_notebook_iframe() gebruiken.
Het rapport wordt in de volgende volgorde gegenereerd: eerst wordt de volledige dataset samengevat. Daarna wordt de rapportstructuur opgebouwd. Tot slot wordt het rapport getoond, dat je als HTML-bestand kunt opslaan en gebruiken voor verdere analyse.

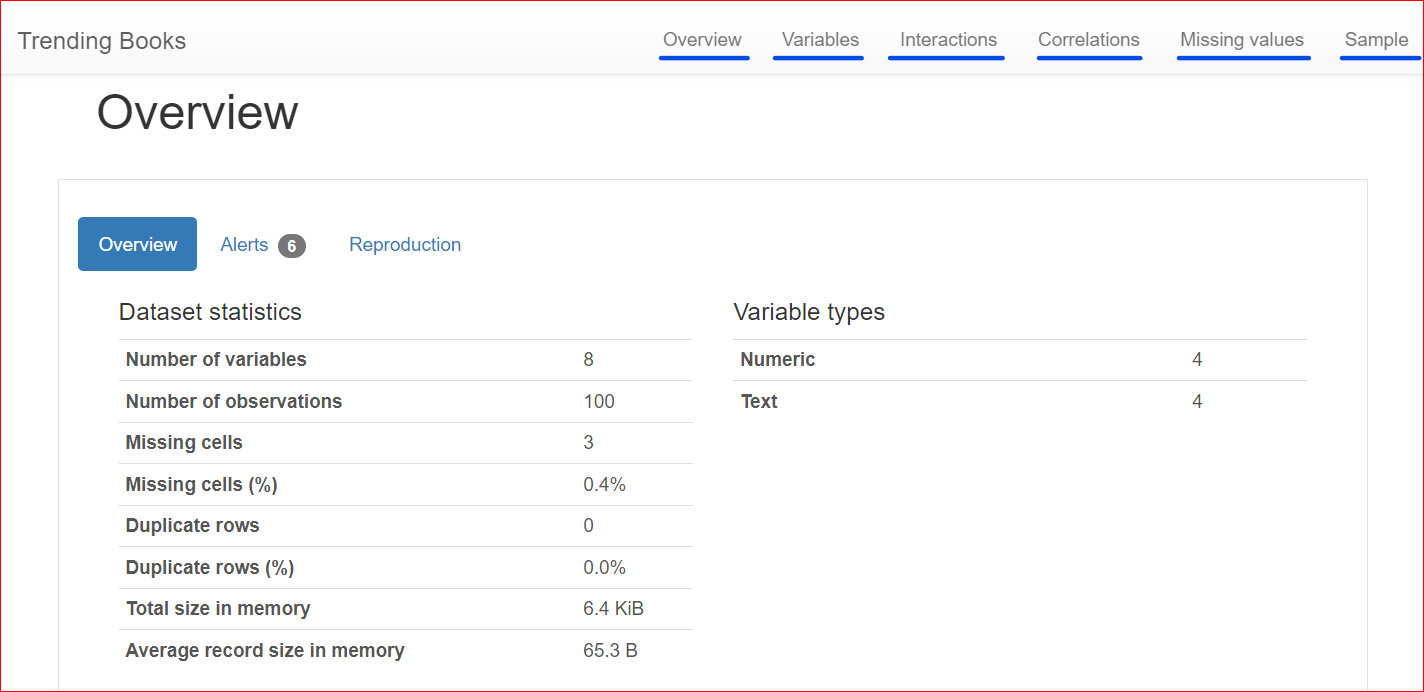
Hier is het gegenereerde rapport, met verschillende secties zoals Overzicht, Variabelen, Interacties, Correlaties, Ontbrekende waarden en Voorbeeld.
Ben je nieuw met EDA en specifieker met dataprofiling? Lees dan Exploratory Data Analysis of Craft Beers: Data Profiling.
Het rapport is opgedeeld in meerdere secties; laten we ze één voor één verkennen.
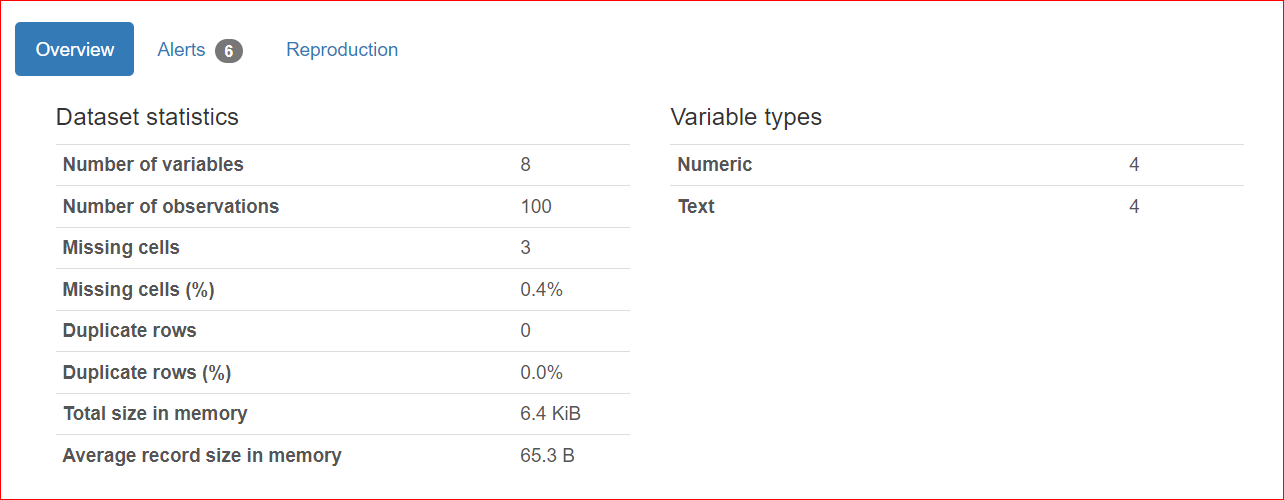
Deze sectie bestaat uit 3 tabbladen: Overzicht, Waarschuwingen en Reproductie.
Het tabblad Overzicht bevat datasetstatistieken, zoals het aantal variabelen (of het aantal verschillende kolommen), het aantal cellen met ontbrekende waarden, dubbele rijen en de grootte van de dataset in het geheugen.
In onze dataset zijn in totaal 8 variabelen of kolommen. Daarvan zijn er vier numeriek (rang, boekprijs, beoordeling en publicatiejaar), terwijl de overige vier tekstgebaseerd zijn (boektitel, auteur, genre en URL). Er zijn geen dubbele rijen, wat blijkt uit een telling van 0 voor duplicaten. Ook bevat de kolom 'rating' drie ontbrekende waarden.
Het tabblad Waarschuwingen bevat meldingen over correlaties met andere variabelen, ontbrekende waarden, unieke waarden, nullen, enz.
In ons geval hebben de kolommen URL en Rank unieke waarden, en de kolom rating heeft drie ontbrekende waarden.
Het tabblad Reproductie toont wanneer de analyse is gestart en wanneer deze is geëindigd. Het geeft de duur van de analyse weer, inclusief de softwareversie die je gebruikt (in mijn geval is dat ydata-profiling v4.6.1).
De sectie Variabelen bevat alle kolommen van je dataset. Je kunt op de pijl klikken en elke kolom selecteren.
Stel dat je de kolom rating hebt geselecteerd; het rapport laat zien dat deze kolom 10 unieke waarden bevat die verdeeld zijn over 100 rijen. Daarnaast ontbreken in drie cellen waarden. De minimumwaarde is 4,1 en de maximumwaarde is 5. Het gemiddelde van alle beoordelingen wordt ook weergegeven.
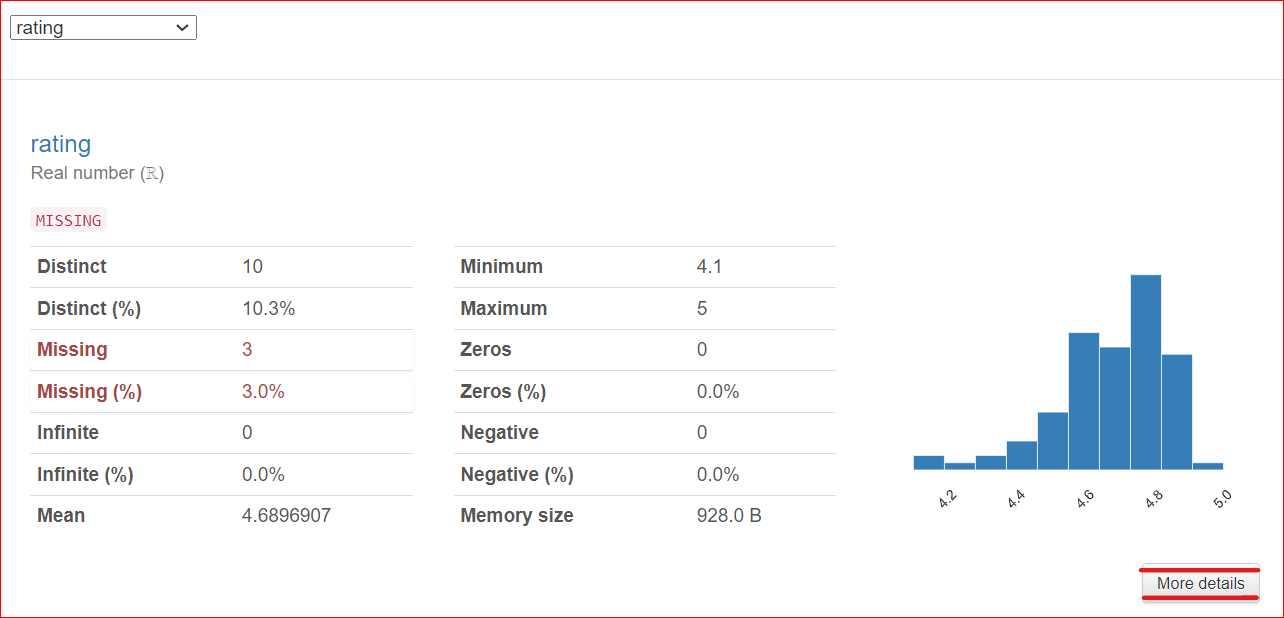
Een belangrijke opmerking: rechtsonder staat een knop More Details. Als je op deze knop klikt, krijg je meer informatie over de kolom rating, zoals de mediaan, standaarddeviatie, variatiecoëfficiënt en diverse andere kenmerken van de kolom.
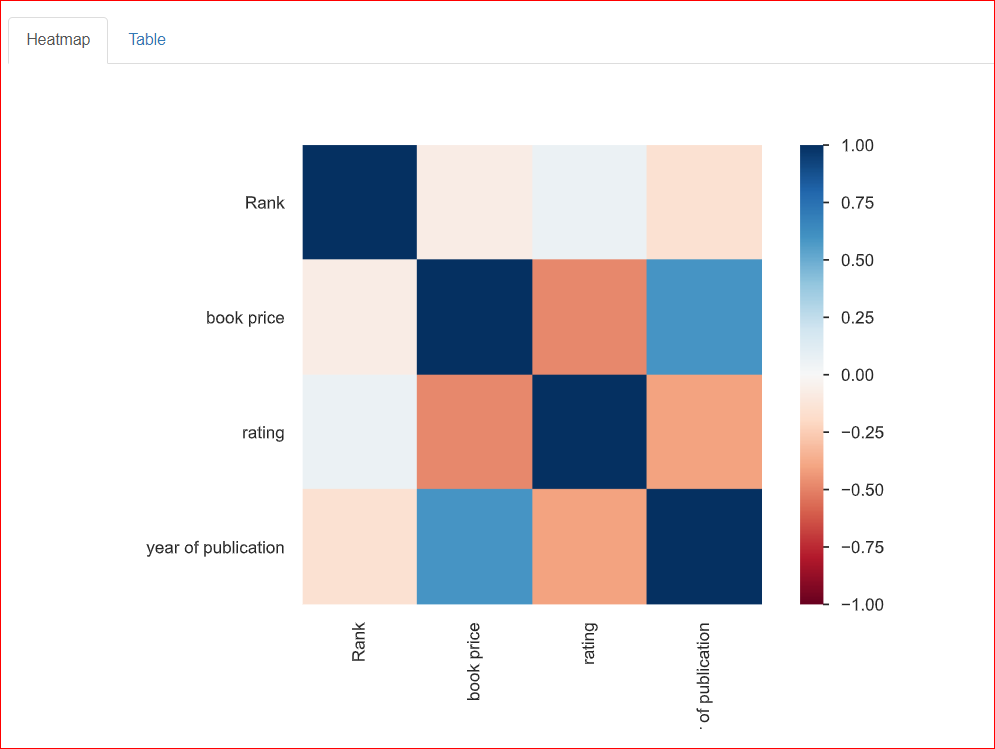
Dit helpt bij het bestuderen van de relatie tussen twee variabelen, oftewel de correlatie. De heatmap hieronder toont de onderlinge relaties tussen alle variabelen. Rank is 100% gerelateerd aan Rank, en daarom wordt dit weergegeven door het donkerblauwe vierkant linksboven.
Het publicatiejaar hangt matig samen met de boekprijs (ongeveer 0,75), wat wordt weergegeven door de lichtblauwe kleur omdat ze niet volledig gerelateerd zijn. Bijvoorbeeld: de boekprijs is 20,93 en het publicatiejaar is 2023; deze getallen houden in zekere mate verband met elkaar.
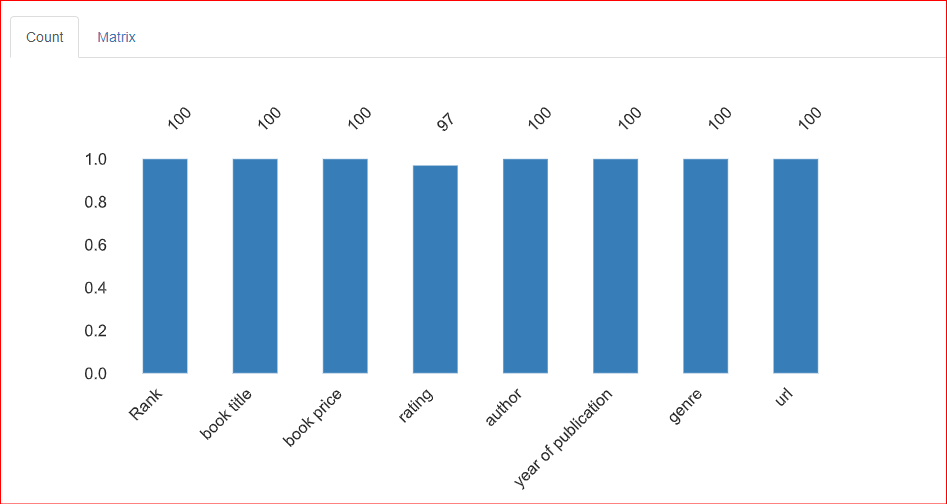
Deze sectie geeft informatie over de ontbrekende waarden in de dataset. Het tabblad Count van deze sectie geeft aan dat er 3 ontbrekende waarden zijn in de kolom rating.
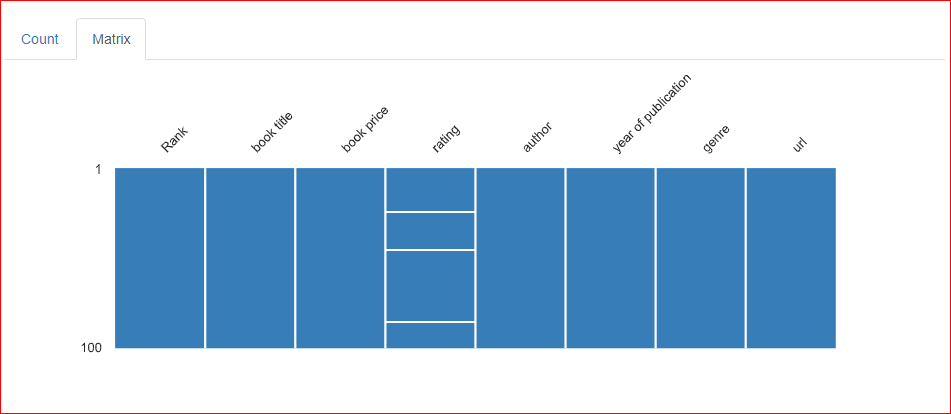
In het tabblad Matrix van de sectie ontbrekende waarden zijn drie horizontale lijnen te zien in de kolom Rating, wat aangeeft dat er drie waarden in die kolom ontbreken.
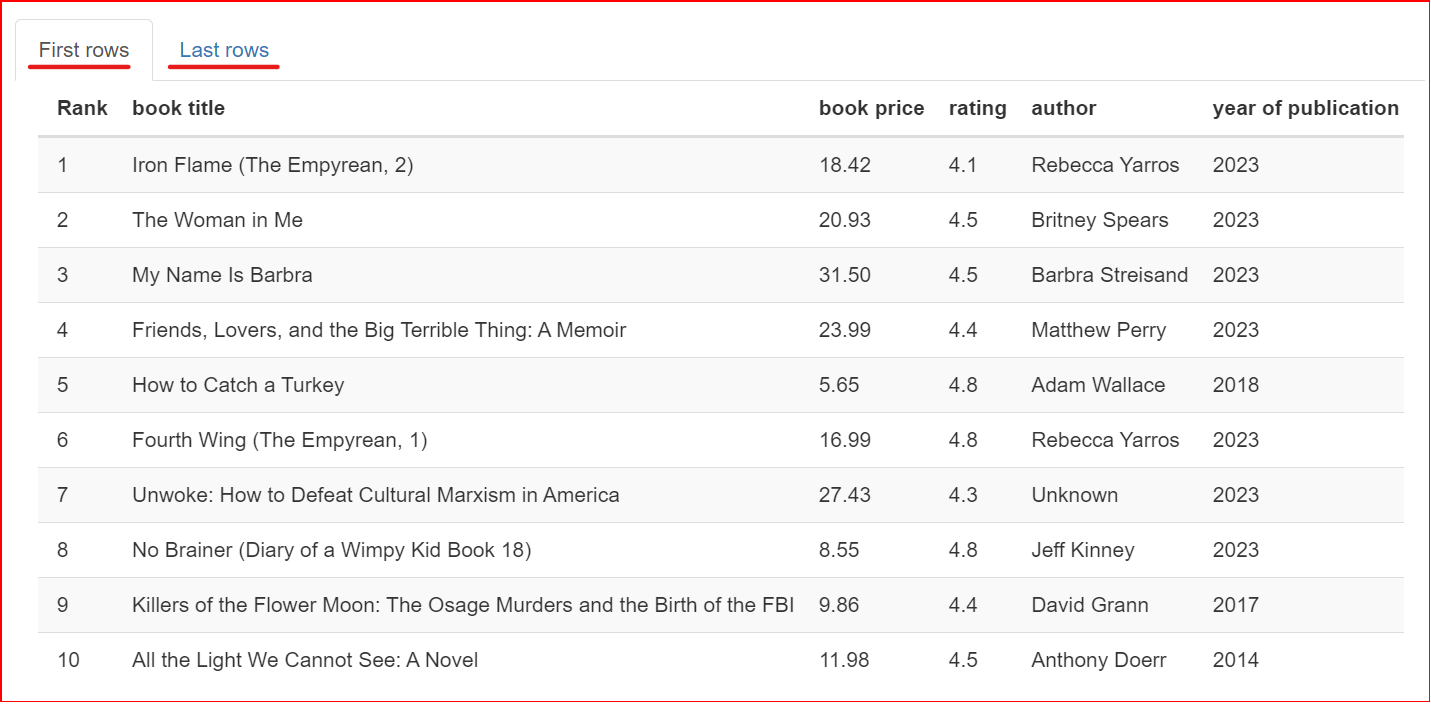
Deze sectie bevat een steekproef van de dataset. Hij toont de eerste en laatste 10 rijen van de dataset.
Je profilerapport is gegenereerd en je wilt het misschien opslaan voor later gebruik, bijvoorbeeld om nuttige data uit het rapport te halen of het te integreren met andere applicaties. Je kunt het rapport opslaan in HTML- en JSON-indelingen. De methode to_file() slaat het rapport buiten de Jupyter Notebook op.
Hier is de volledige code voor de pandas-profiling:
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Voor het genereren van het rapport geven we simpelweg het CSV-bestand door en verder niets. We voegen geen extra elementen toe; alleen standaardwaarden worden gebruikt.
Toch zijn er misschien secties die je wilt weglaten of extra informatie die je wilt toevoegen. Daar komen de geavanceerde toepassingen van Pandas Profiling om de hoek kijken. Je kunt verschillende aspecten van het rapport sturen door de standaardconfiguratie te wijzigen.
Als je meer wilt leren over tools voor data-analyse en visualisatie, lees dan 21 Essential Python Tools.
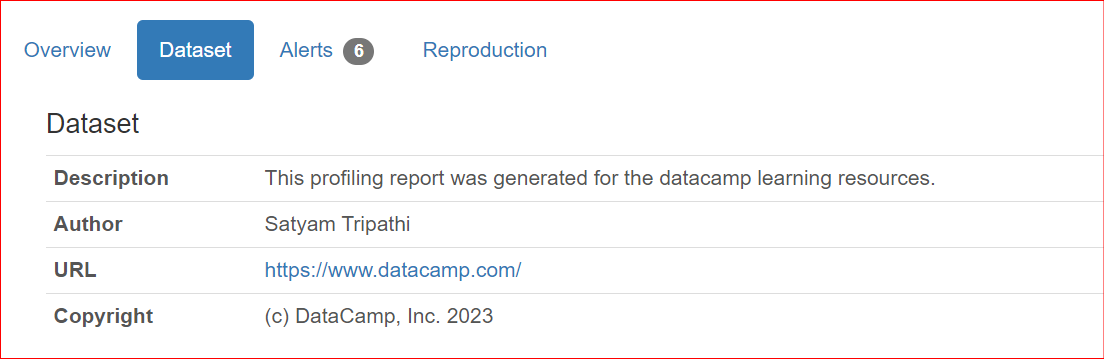
Bij het delen van rapporten met collega’s of bij online publicatie kan het belangrijk zijn om metadata van de dataset op te nemen, zoals de auteur, de rechthebbende of beschrijvingen. Met ydata-profiling kun je een rapport met die informatie aanvullen.
De momenteel ondersteunde eigenschappen zijn description, creator, author, url, copyright_year en copyright_holder. Standaard worden de datasets weergegeven in de sectie Overzicht van het rapport.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()Hier is de code-uitvoer:
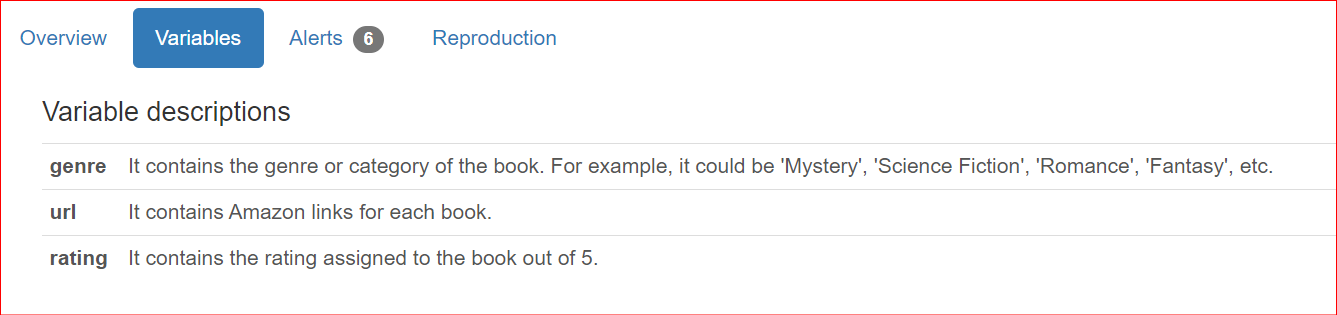
Naast informatie over de dataset willen gebruikers bij het delen van rapporten met teamleden en stakeholders vaak ook kolomspecifieke beschrijvingen opnemen. Standaard worden deze beschrijvingen weergegeven in de sectie Overzicht van het rapport.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()Hier is de code-uitvoer:
Standaard vat ydata-profiling de invoerdataset uitgebreid samen om zoveel mogelijk inzichten te bieden voor data-analyse. Voor kleine datasets kunnen deze berekeningen snel worden uitgevoerd. Bij grotere datasets kan dit echter te omslachtig worden.
ydata-profiling bevat een minimale configuratie waarin de meest kostbare berekeningen standaard zijn uitgeschakeld. Deze configuratie sluit tijdrovende secties uit, zoals correlaties, interacties, enz.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling biedt ook verschillende alternatieven om de uitdaging van het omgaan met grote datasets te overwinnen. Ontdek ze hier.
In dit artikel heb je kennisgemaakt met de unieke bibliotheek ydata-profiling, voorheen bekend als "Pandas Profiling", waarmee je met slechts een paar regels code rapporten kunt maken. Je leerde hoe je het profilerapport genereert en alle secties en tabbladen in het rapport verkent. Het belangrijkste is dat je de geavanceerde toepassingen van deze bibliotheek hebt gezien, die je een stap verder brengen in je data science-reis.
Pandas is ’s werelds populairste Python-bibliotheek, gebruikt voor alles van datamanipulatie tot data-analyse. Wil je leren hoe je DataFrames manipuleert terwijl je echte datasets extraheert, filtert en transformeert voor analyse? Bekijk dan onze cursus Data Manipulation with pandas.
Ontdek meer toepassingen van pandas
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
