
Kurs
Vereinfachte Datenaufnahme mit pandas
4 Std.
62.7K
Bei Datensätzen mit beispielsweise 10.000 Zeilen und 50 Spalten ist es nicht leicht, sich schnell einen Überblick zu verschaffen. Genau hier hilft pandas Profiling. Das Tool erstellt einen umfassenden Report zu deinem Datensatz und verkürzt so die Zeit, die du für die Erkundung großer Datenmengen brauchst.
In diesem Artikel lernst du, wie du mit dem ehemals als pandas Profiling bekannten Tool startest. Der Paketname pandas-profiling wurde kürzlich in ydata-profiling geändert. In diesem Tutorial erfährst du, wie du einen Profilreport aus deinem Datensatz erzeugst, was der Report enthält, wie du ihn liest und schließlich, wie du ihn zur weiteren Verwendung speicherst.
Pandas Profiling generiert einen vollständigen, sehr detaillierten Report für deinen Datensatz – mit zahlreichen Funktionen und Anpassungsmöglichkeiten. Der Report enthält unter anderem Datensatzstatistiken, Wertverteilungen, fehlende Werte, Speicherverbrauch usw. – alles, was dir eine effiziente Datenexploration und -analyse erleichtert.
Pandas Profiling ist auch für Exploratory Data Analysis (EDA) äußerst hilfreich. Mit EDA verstehst du die Struktur deiner Daten, erkennst Muster und gewinnst visuelle Einblicke.
Für EDA müssen wir oft viele, teils komplexe und zeitaufwändige Codezeilen schreiben. Mit pandas Profiling lässt sich das mit nur wenigen Zeilen automatisieren.
Braucht dein EDA-Wissen ein Update? Lies unseren Guide zu Exploratory Data Analysis mit Python.
Hier ein Beispiel für einen Profilreport:
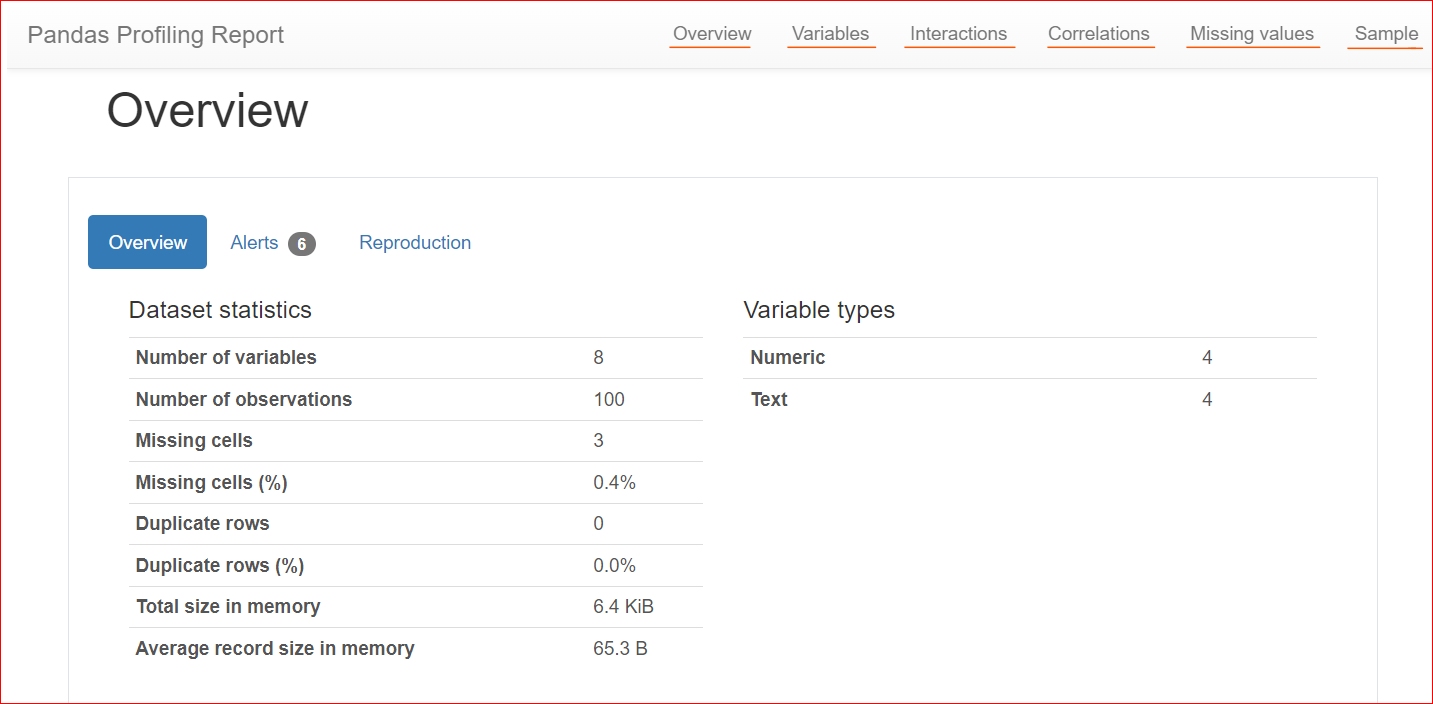
Bild: Autor
Pandas Profiling ist in der EDA weit verbreitet: Es ist einfach zu bedienen, spart Zeit und erzeugt interaktive HTML-Reports. Bei sehr großen Datensätzen gibt es jedoch potenzielle Einschränkungen.
Zur Installation von pandas Profiling nutzt du je nach Umgebung pip oder conda.
Mit Pip:
Öffne die Eingabeaufforderung oder ein Terminal und führe folgenden Befehl aus:
pip install ydata-profilingMit Conda:
Öffne die Anaconda PowerShell Prompt und führe folgenden Befehl aus:
conda install -c conda-forge ydata-profilingNach erfolgreicher Installation importierst du ydata-profiling mit folgendem Statement.
from ydata_profiling import ProfileReportDamit importierst du die Klasse ProfileReport aus der Bibliothek ydata_profiling. Mit dieser Klasse erzeugst du Profilreports für deine DataFrames.
So erzeugst du einen Profilreport:
ydata_profiling.ProfileReport() und übergib das DataFrame.Hier ist der einfache Code entsprechend der obigen Schritte. Zuerst importieren wir die benötigten Bibliotheken und lesen dann die CSV-Datei mit read_csv() ein. In diesem Beispiel verwenden wir die CSV-Datei der Top 100 Bestselling Book Reviews. Danach nutzen wir die Klasse ProfileReport und übergeben unser DataFrame.
Zusätzlich setzen wir einen neuen Titel, „Trending Books“. Standardmäßig ist der Titel ein anderer. Wenn du ihn anpassen willst, nutze die Variable title innerhalb der Klasse. Um den Report zu erzeugen und anzuzeigen, verwendest du anschließend profile oder profile.to_notebook_iframe().
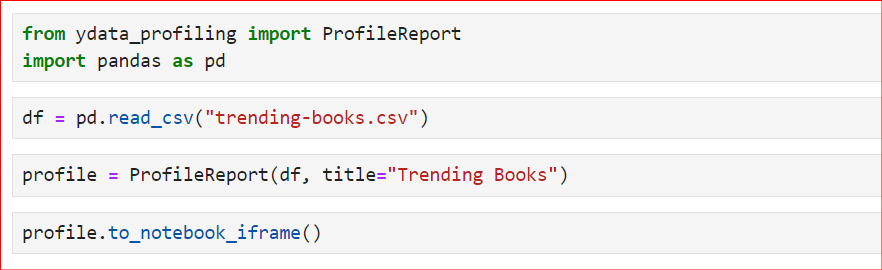
Der Report wird in folgender Reihenfolge erzeugt: Zunächst wird der gesamte Datensatz zusammengefasst. Dann wird die Reportstruktur aufgebaut. Anschließend wird der Report angezeigt, den du als HTML-Datei speichern und für weitere Analysen verwenden kannst.

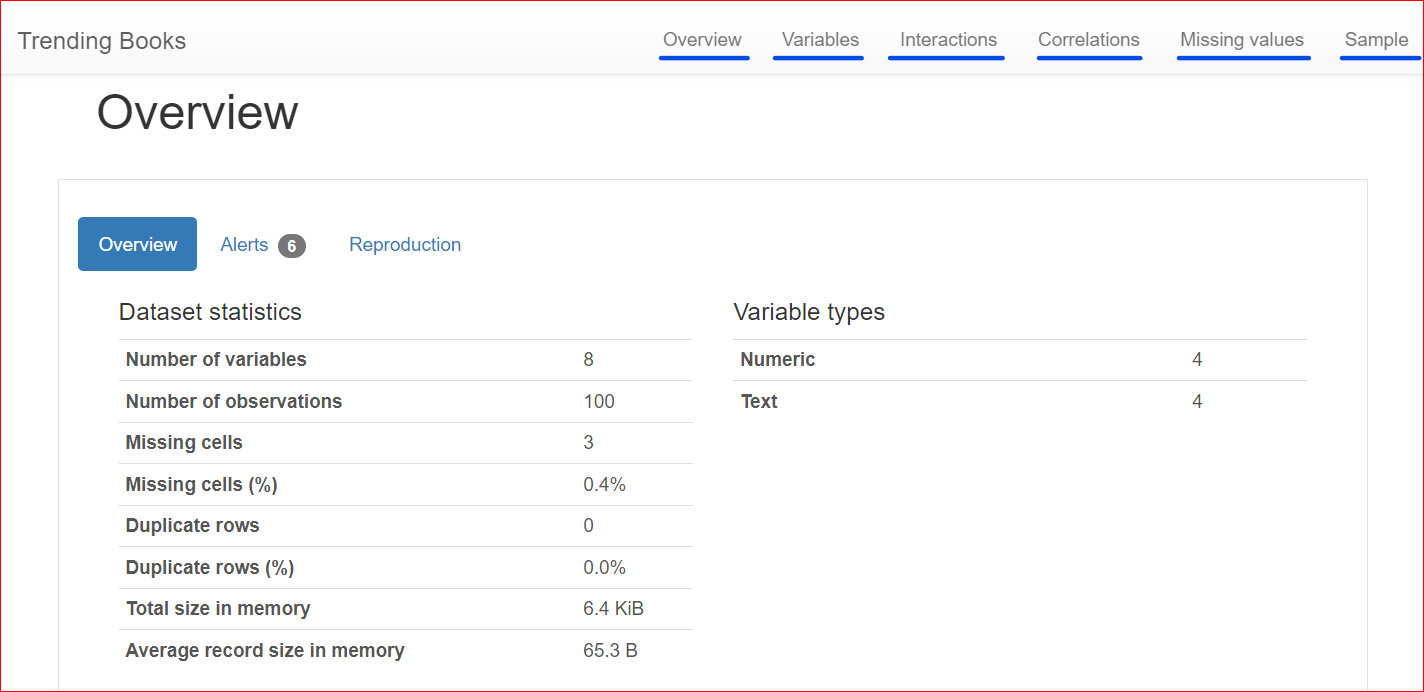
Hier siehst du den erzeugten Report mit verschiedenen Bereichen wie Overview, Variables, Interactions, Correlations, Missing Values und Sample.
Wenn du neu bei EDA und speziell beim Datenprofiling bist, lies Exploratory Data Analysis von Craft Beers: Data Profiling.
Der Report ist in mehrere Bereiche gegliedert. Schauen wir sie uns nacheinander an.
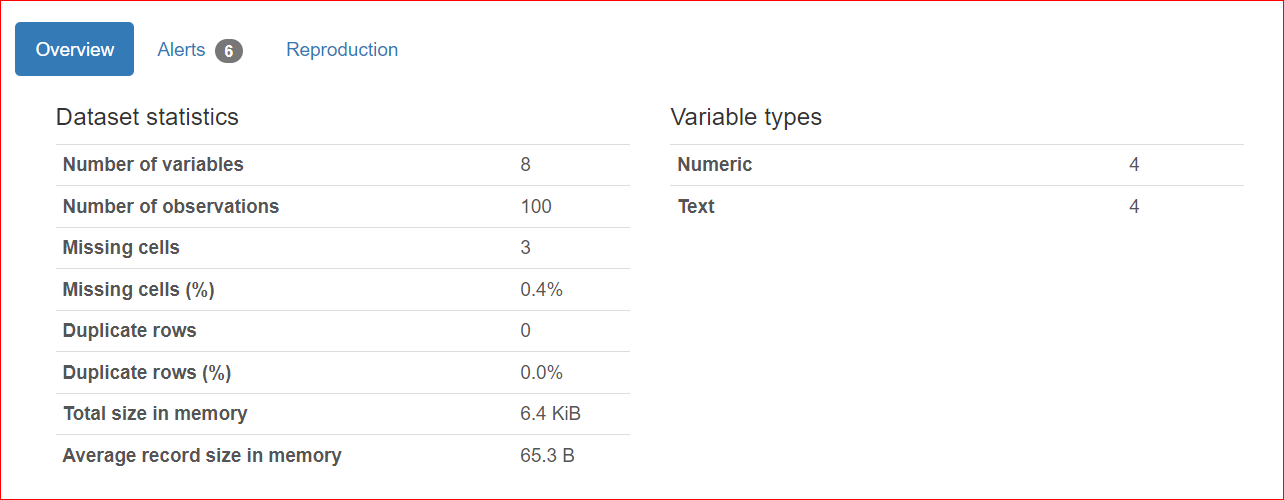
Dieser Bereich besteht aus drei Tabs: Overview, Alerts und Reproduction.
Der Tab Overview enthält Datensatzstatistiken wie die Anzahl der Variablen (also Spalten), die Anzahl der Zellen mit fehlenden Werten, Duplikate und die Größe des Datensatzes im Speicher.
In unserem Datensatz gibt es insgesamt 8 Variablen bzw. Spalten. Davon sind vier numerisch (Rang, Buchpreis, Bewertung und Erscheinungsjahr), die übrigen vier sind Textspalten (Buchtitel, Autor, Genre und URL). Es gibt keine doppelten Zeilen (Anzahl Duplikate: 0). In der Spalte „rating“ fehlen drei Werte.
Der Tab Alerts enthält Hinweise zu Korrelationen zwischen Variablen, fehlenden Werten, eindeutigen Werten, Nullen usw.
In unserem Fall haben die Spalten URL und Rank eindeutige Werte, und in der Spalte rating fehlen drei Werte.
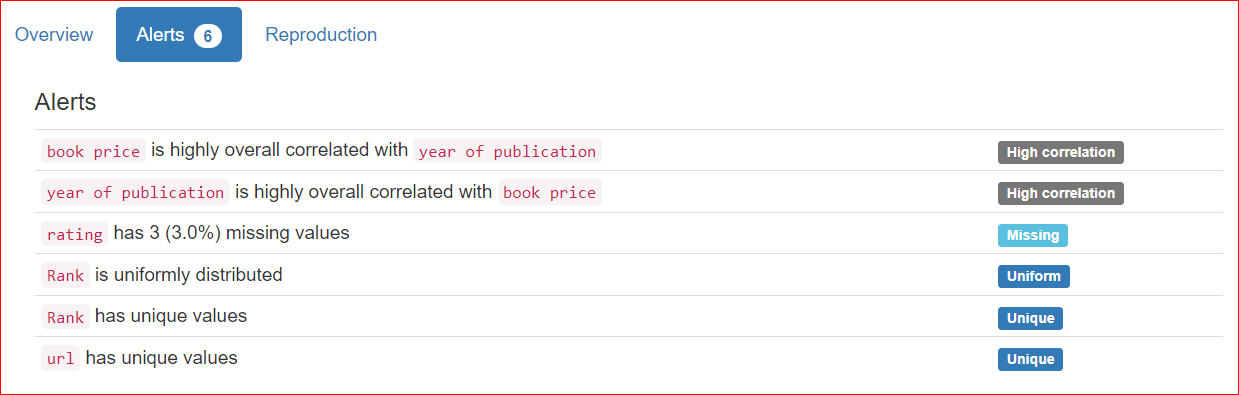
Der Tab Reproduction zeigt, wann die Analyse gestartet und beendet wurde, ihre Gesamtdauer sowie die verwendete Softwareversion (hier: ydata-profiling v4.6.1).
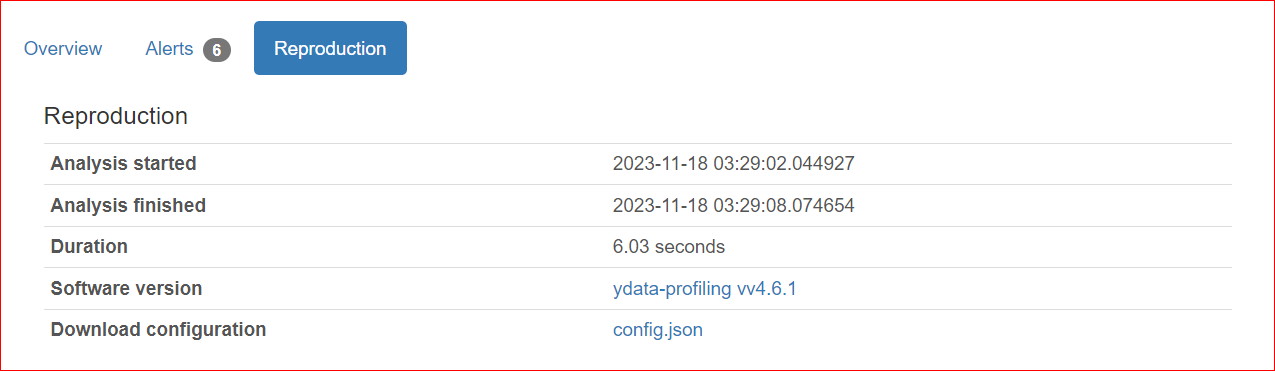
Im Bereich Variables findest du alle Spalten deines Datensatzes. Über den Aufklapp-Pfeil kannst du jede gewünschte Spalte auswählen.
Wenn du beispielsweise die Spalte rating auswählst, zeigt der Report, dass diese Spalte 10 eindeutige Werte enthält, verteilt über 100 Zeilen. Außerdem fehlen in drei Zellen Werte. Der Mindestwert beträgt 4,1, der Höchstwert 5. Auch der Mittelwert aller Bewertungen wird angezeigt.
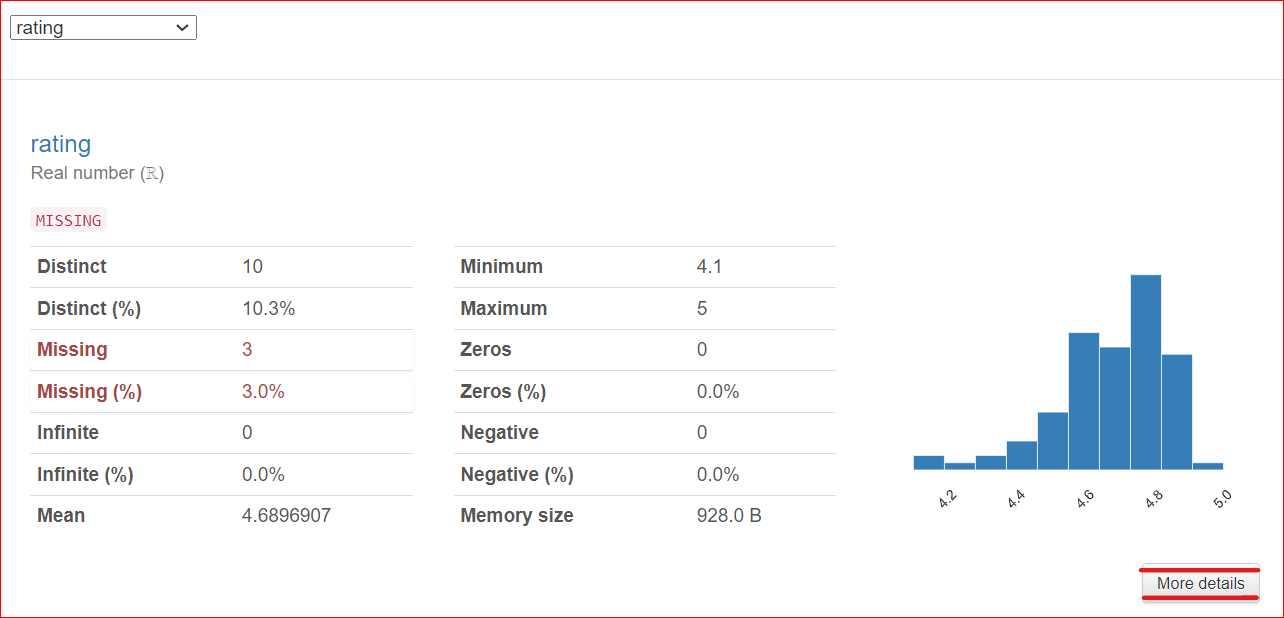
Wichtig: Unten rechts findest du die Schaltfläche More Details. Ein Klick darauf öffnet weitere Informationen zur Spalte rating, etwa Median, Standardabweichung, Variationskoeffizient und weitere Kennzahlen.
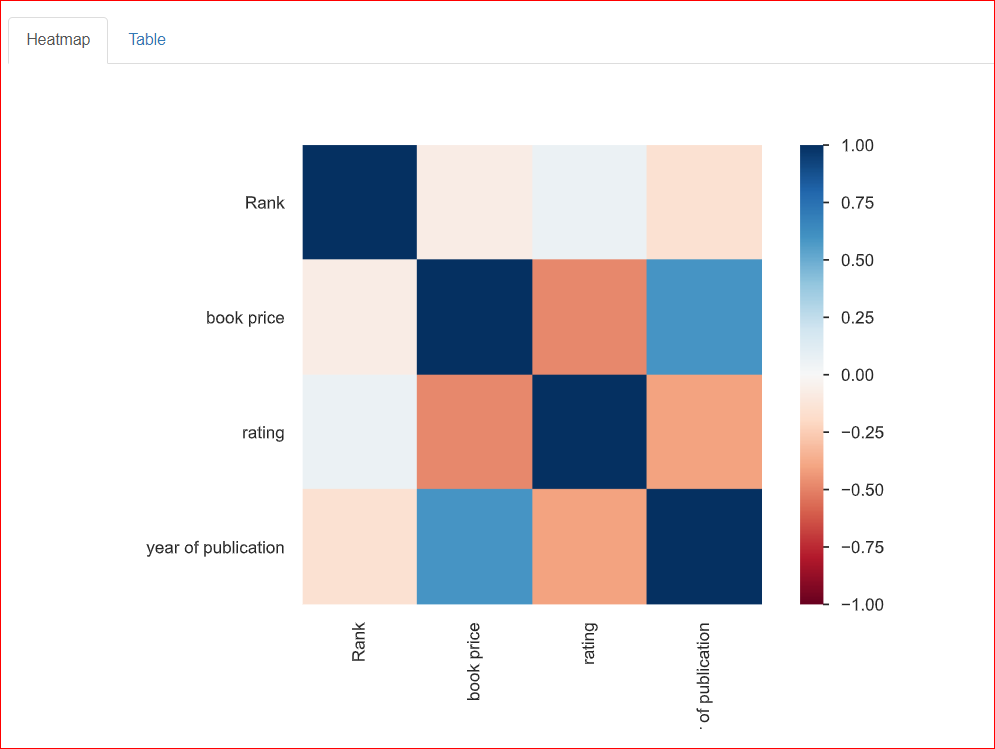
Hier untersuchst du die Beziehungen zwischen zwei Variablen, also Korrelationen. Die Heatmap unten zeigt die Zusammenhänge zwischen allen Variablen. Rank korreliert zu 100 % mit Rank – daher das dunkelblaue Quadrat oben links.
Das Erscheinungsjahr korreliert moderat mit dem Buchpreis (ca. 0,75), dargestellt in Hellblau, da keine vollständige Korrelation vorliegt. Beispiel: Der Buchpreis ist 20,93 und das Erscheinungsjahr 2023 – diese Zahlen hängen in gewissem Maß zusammen.
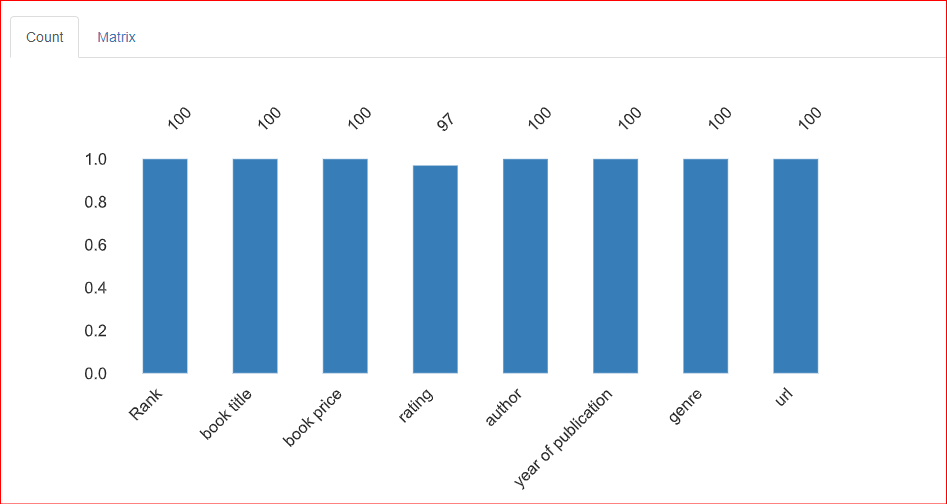
Dieser Bereich informiert über fehlende Werte im Datensatz. Der Tab Count zeigt, dass in der Spalte rating 3 Werte fehlen.
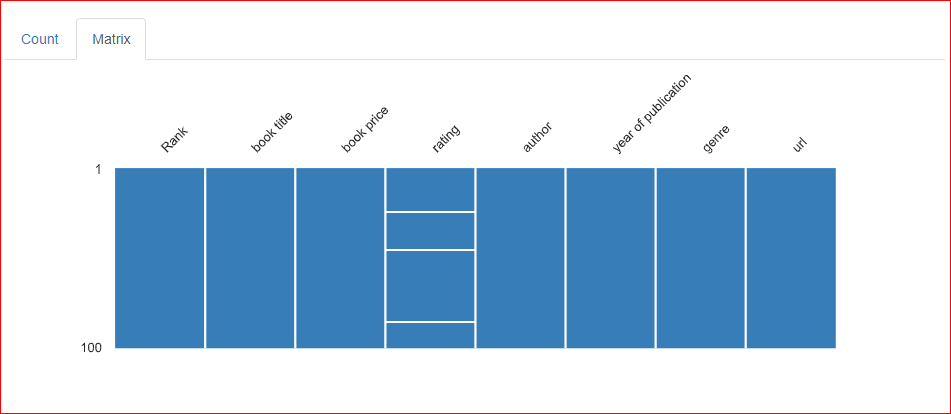
Im Tab Matrix des Bereichs Missing Values zeigen drei horizontale Linien in der Spalte Rating, dass dort drei Werte fehlen.
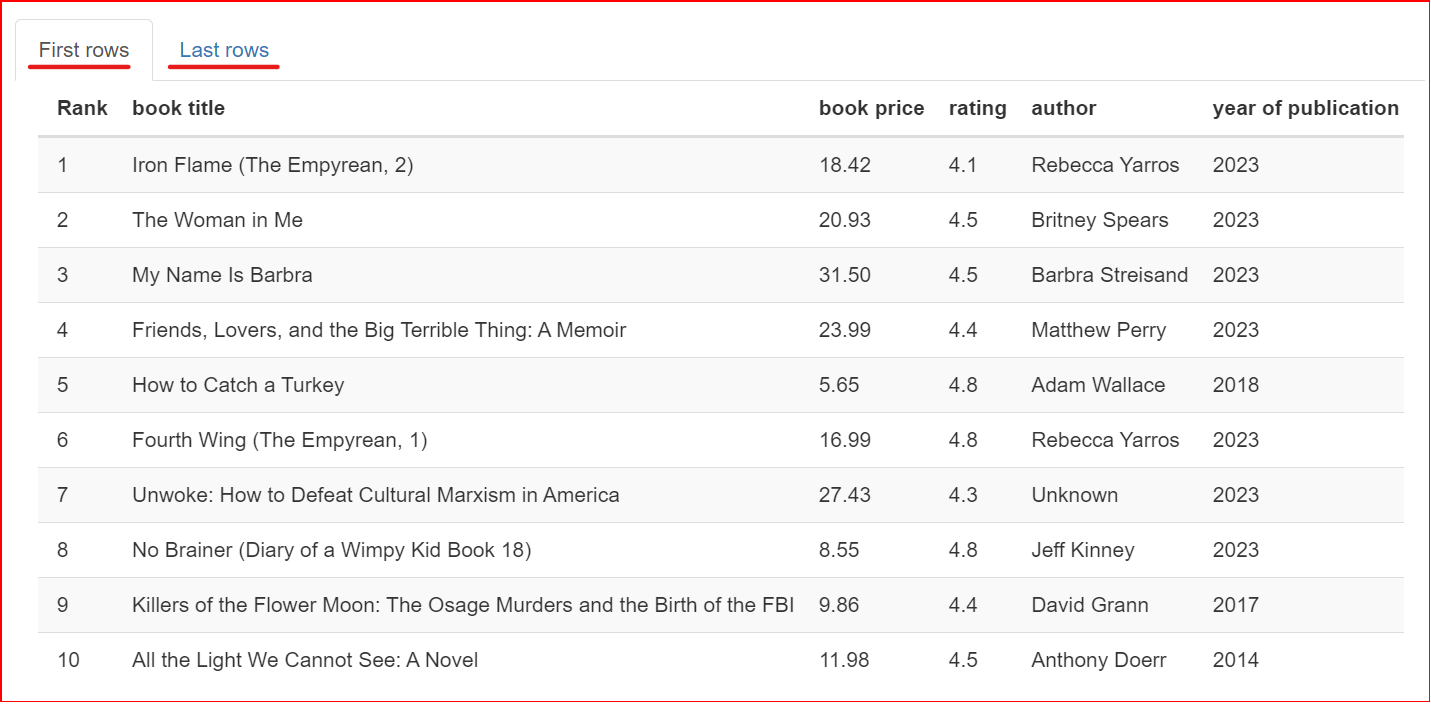
Dieser Bereich zeigt eine Stichprobe des Datensatzes – die ersten und letzten 10 Zeilen.
Dein Profilreport ist erstellt und du möchtest ihn vielleicht weiterverwenden – etwa, um Daten daraus zu extrahieren oder ihn in andere Anwendungen zu integrieren. Du kannst den Report als HTML- und JSON-Datei speichern. Die Methode to_file() speichert den Report außerhalb des Jupyter Notebooks.
Hier ist der komplette Code für pandas Profiling:
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Für den Report haben wir bisher einfach die CSV-Datei übergeben – ohne weitere Anpassungen, nur mit den Standardwerten.
Vielleicht möchtest du jedoch bestimmte Bereiche weglassen oder zusätzliche Informationen einbinden. Hier kommen die erweiterten Möglichkeiten von pandas Profiling ins Spiel. Über die Standardkonfiguration steuerst du viele Aspekte des Reports.
Wenn du mehr über Tools für Datenanalyse und -visualisierung lernen willst, lies 21 Essential Python Tools.
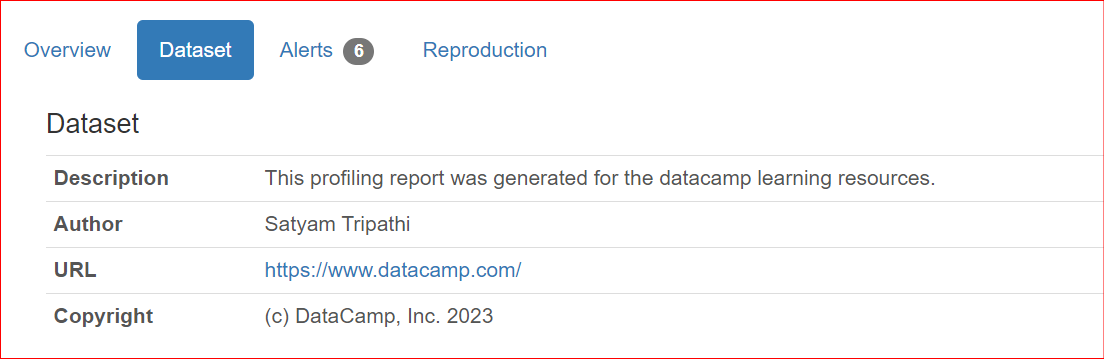
Wenn du Reports im Team teilst oder online veröffentlichst, sind Metadaten wie Autor, Rechteinhaber oder Beschreibungen oft wichtig. ydata-profiling erlaubt es, einen Report damit anzureichern.
Aktuell werden die Eigenschaften description, creator, author, url, copyright_year und copyright_holder unterstützt. Standardmäßig erscheinen diese Angaben im Bereich Overview des Reports.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()So sieht die Ausgabe aus:
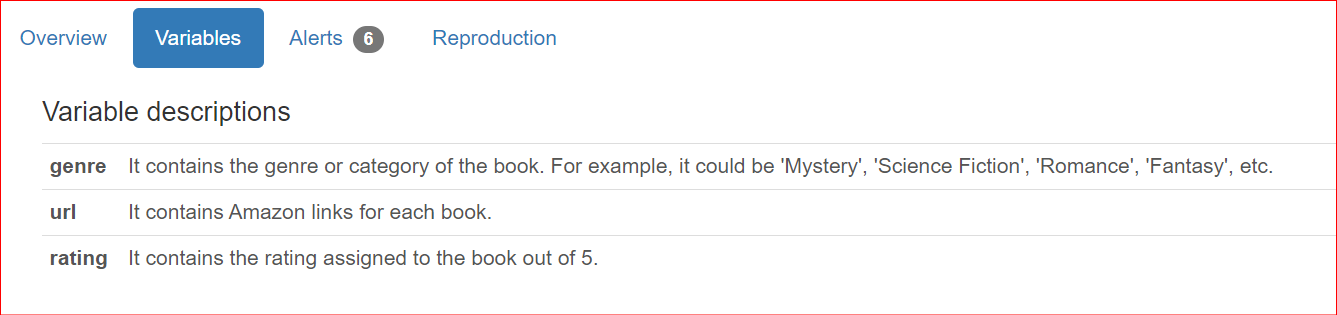
Neben allgemeinen Datensatzdetails möchten Teams häufig auch spaltenspezifische Beschreibungen hinterlegen. Standardmäßig werden diese Beschreibungen im Bereich Overview angezeigt.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()So sieht die Ausgabe aus:
Standardmäßig fasst ydata-profiling den Eingabedatensatz sehr umfassend zusammen, um möglichst viele Einblicke zu liefern. Bei kleinen Datensätzen geht das schnell, bei großen kann es jedoch zu schwerfällig werden.
ydata-profiling bietet eine Minimal-Konfiguration, in der die rechenintensivsten Schritte standardmäßig deaktiviert sind. Dabei werden zeitaufwändige Bereiche wie Correlations, Interactions usw. ausgelassen.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling stellt außerdem mehrere Alternativen bereit, um große Datensätze effizient zu handhaben. Entdecke sie hier.
In diesem Artikel hast du die besondere Bibliothek ydata-profiling kennengelernt, ehemals „Pandas Profiling“, mit der du mit wenigen Codezeilen Reports erstellst. Du weißt jetzt, wie du den Profilreport generierst, die Bereiche und Tabs erkundest und – besonders wichtig – wie du die erweiterten Funktionen nutzt, um in deiner Data-Science-Reise den nächsten Schritt zu gehen.
Pandas ist die weltweit beliebteste Python-Bibliothek – von Datenmanipulation bis Datenanalyse. Wenn du lernen willst, wie du DataFrames manipulierst und reale Datensätze extrahierst, filterst und transformierst, schau dir unseren Kurs Data Manipulation with pandas an.
Entdecke weitere Einsatzmöglichkeiten von pandas
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Moez Ali
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Mark Pedigo
