
Courses
Nạp dữ liệu gọn nhẹ với pandas
4 giờ
63.2K
Khi làm việc với một tập dữ liệu, chẳng hạn như tập có 10.000 dòng và 50 cột, việc nắm bắt nhanh tổng quan có thể là một thách thức. Đây là lúc pandas Profiling phát huy tác dụng. Công cụ này giúp tự động tạo báo cáo toàn diện về tập dữ liệu của bạn, rút ngắn thời gian khám phá các tập dữ liệu lớn.
Trong bài viết này, bạn sẽ học cách bắt đầu với công cụ trước đây được gọi là pandas Profiling. Tên gói pandas-profiling gần đây đã được đổi thành ydata-profiling. Trong hướng dẫn này, bạn sẽ học cách tạo báo cáo hồ sơ từ tập dữ liệu, những nội dung bên trong báo cáo, cách đọc báo cáo này và cuối cùng là cách lưu báo cáo để sử dụng tiếp.
Pandas Profiling được dùng để tạo một báo cáo đầy đủ và chi tiết cho tập dữ liệu, với nhiều tính năng và tuỳ biến trong báo cáo được tạo. Báo cáo bao gồm nhiều thông tin như thống kê tập dữ liệu, phân phối giá trị, giá trị thiếu, mức sử dụng bộ nhớ, v.v., rất hữu ích để khám phá và phân tích dữ liệu hiệu quả.
Pandas Profiling cũng hỗ trợ rất nhiều cho Phân tích Dữ liệu Khám phá (EDA). EDA được dùng để hiểu cấu trúc nền tảng của dữ liệu, phát hiện mẫu và rút ra insight dưới dạng trực quan.
Với EDA, thường chúng ta phải viết nhiều dòng mã, đôi khi phức tạp và tốn thời gian, nhưng có thể tự động hoá bằng Pandas Profiling chỉ với vài dòng mã.
Nếu bạn cần ôn lại EDA, hãy đọc Phân tích Dữ liệu Khám phá với Python.
Dưới đây là ví dụ về một báo cáo hồ sơ:
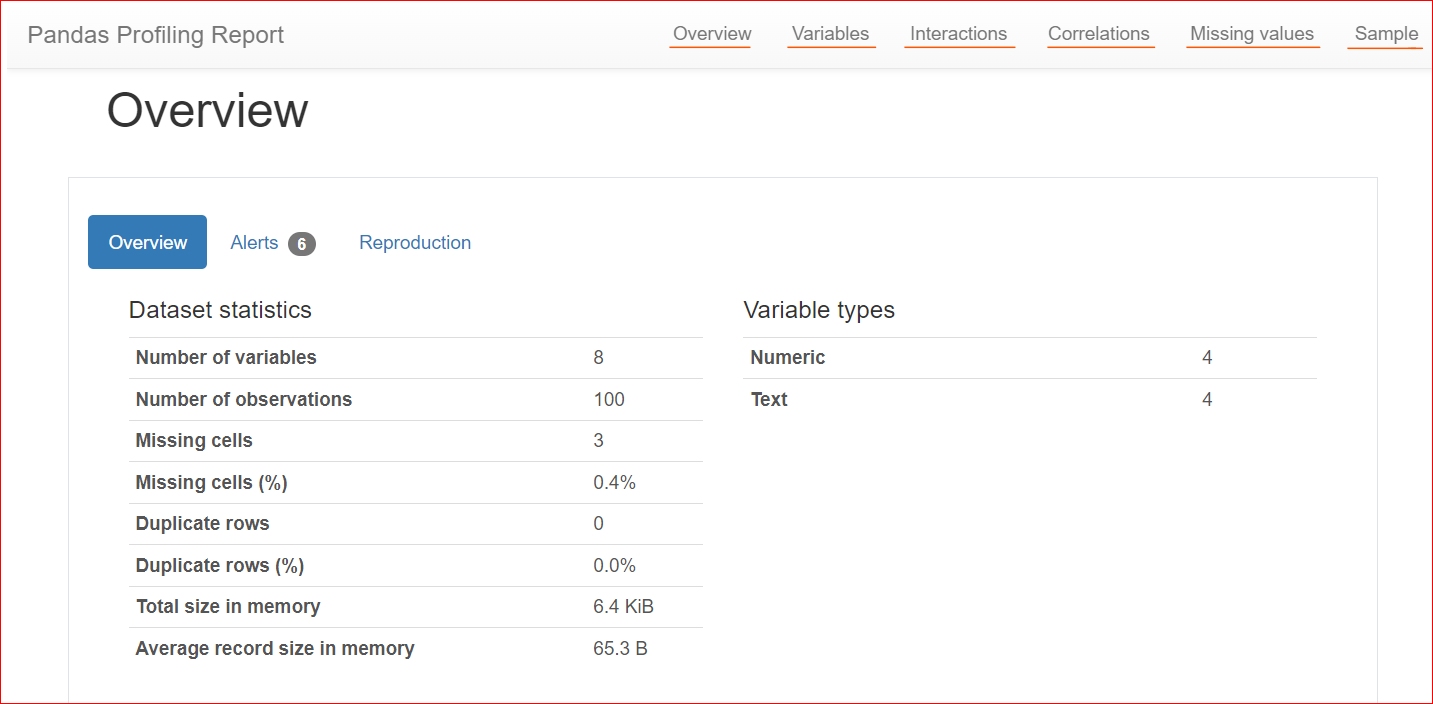
Hình ảnh do Tác giả cung cấp
Pandas profiling được dùng rộng rãi trong EDA nhờ dễ sử dụng, tiết kiệm thời gian và tạo báo cáo HTML tương tác. Tuy nhiên, khi áp dụng với các tập dữ liệu lớn, cũng có một số hạn chế tiềm ẩn.
Để cài đặt pandas Profiling, bạn có thể dùng pip hoặc conda, tuỳ theo sở thích và môi trường của bạn.
Sử dụng Pip:
Mở command prompt hoặc terminal và chạy lệnh sau:
pip install ydata-profilingSử dụng Conda:
Mở Anaconda PowerShell Prompt và chạy lệnh sau:
conda install -c conda-forge ydata-profilingSau khi cài đặt thành công, hãy import ydata-profiling bằng câu lệnh sau.
from ydata_profiling import ProfileReportLệnh này sẽ import lớp ProfileReport từ thư viện ydata_profiling. Bạn có thể dùng lớp này để tạo các báo cáo hồ sơ cho DataFrame.
Để tạo một báo cáo hồ sơ, hãy làm theo các bước dưới đây:
ydata_profiling.ProfileReport() và truyền vào DataFrame.Dưới đây là đoạn mã đơn giản theo các bước trên. Đầu tiên, chúng ta import các thư viện cần thiết rồi đọc tệp CSV bằng hàm read_csv(). Ở đây, chúng ta dùng tệp CSV về Top 100 bài đánh giá sách bán chạy nhất. Tiếp theo, chúng ta dùng lớp ProfileReport và truyền DataFrame của mình vào.
Ngoài ra, chúng ta đặt tiêu đề mới là "Trending Books". Mặc định tiêu đề sẽ khác, nhưng nếu muốn tuỳ chỉnh, bạn dùng biến title trong lớp. Cuối cùng, để tạo và hiển thị báo cáo, bạn có thể dùng profile hoặc profile.to_notebook_iframe().
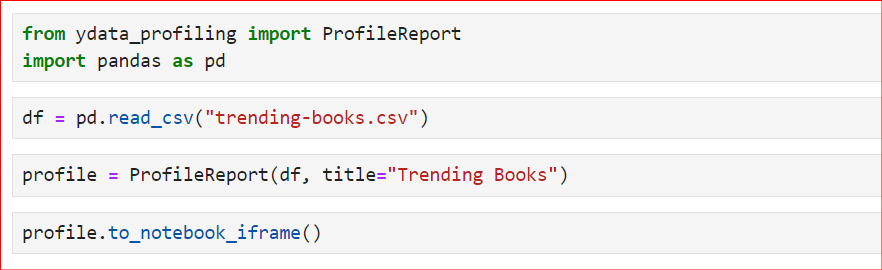
Báo cáo sẽ được tạo theo trình tự sau: Trước hết, toàn bộ tập dữ liệu sẽ được tóm tắt. Sau đó, cấu trúc báo cáo được tạo. Cuối cùng, báo cáo sẽ được hiển thị; bạn có thể lưu dưới dạng tệp HTML và dùng cho phân tích tiếp theo.

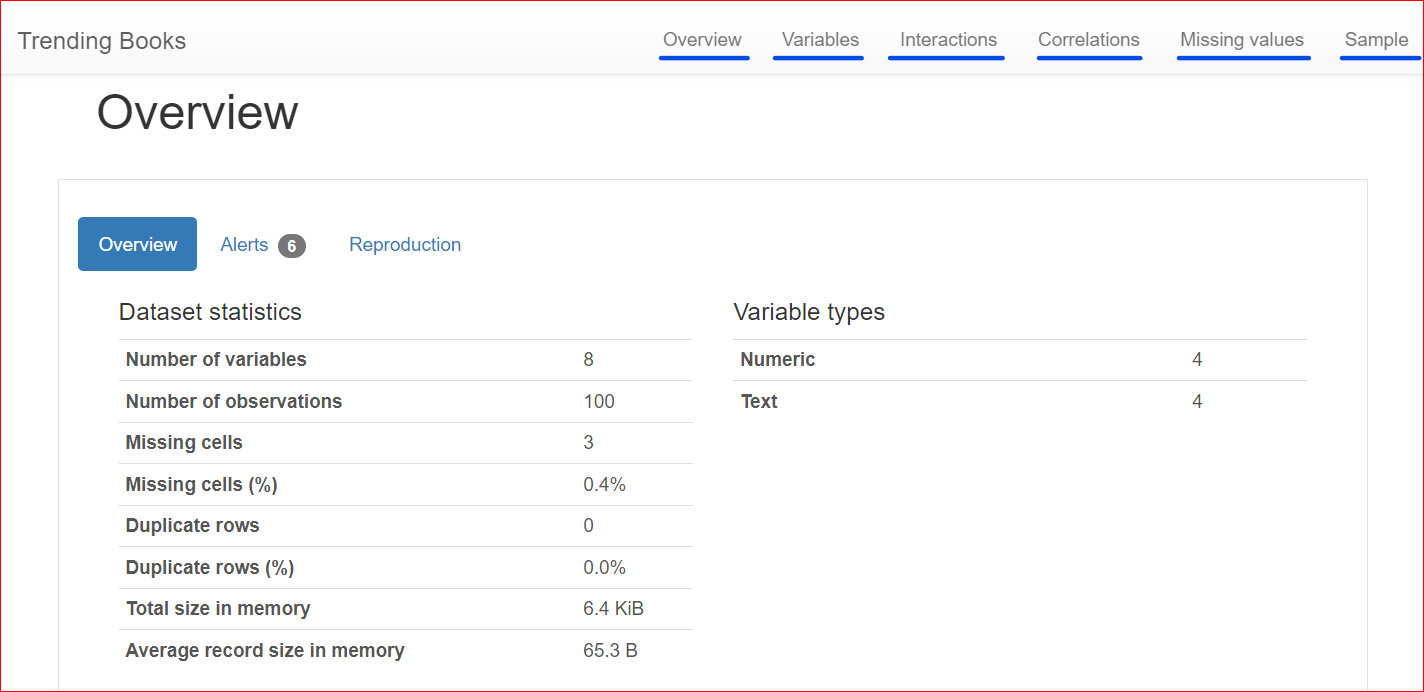
Dưới đây là báo cáo đã tạo, gồm các phần như Tổng quan, Biến, Tương tác, Tương quan, Giá trị thiếu và Mẫu.
Nếu bạn mới làm quen với EDA và đặc biệt là data profiling, hãy đọc Phân tích Dữ liệu Khám phá về Bia Thủ công: Data Profiling.
Báo cáo được chia thành nhiều phần, hãy cùng khám phá từng phần một.
Phần này gồm 3 thẻ: Tổng quan, Cảnh báo và Tái lập.
Thẻ Tổng quan bao gồm thống kê tập dữ liệu, như số biến (hay số cột khác nhau), số ô có giá trị thiếu, hàng trùng lặp và kích thước tập dữ liệu trong bộ nhớ.
Trong tập dữ liệu của chúng ta có tổng cộng 8 biến hay cột. Trong đó có bốn biến số (thứ hạng, giá sách, điểm đánh giá và năm xuất bản), bốn biến còn lại là dạng văn bản (tiêu đề sách, tác giả, thể loại và URL). Không có hàng trùng lặp, thể hiện qua số lượng trùng lặp bằng 0. Ngoài ra, cột 'rating' có ba giá trị thiếu.
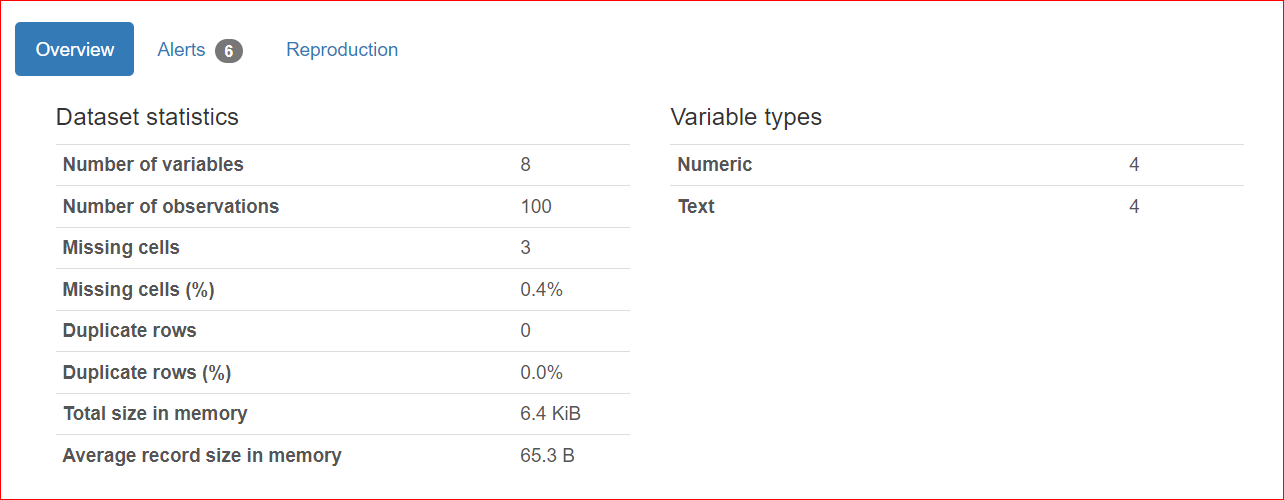
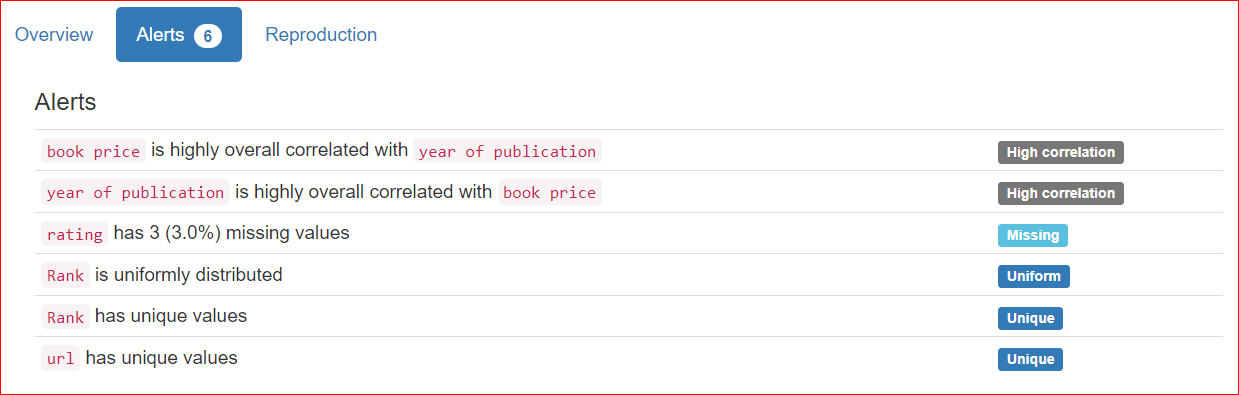
Thẻ Cảnh báo bao gồm các cảnh báo liên quan đến tương quan với biến khác, giá trị thiếu, giá trị duy nhất, số không, v.v.
Trong trường hợp của chúng ta, các cột URL và Rank có giá trị duy nhất, và cột rating có ba giá trị thiếu.
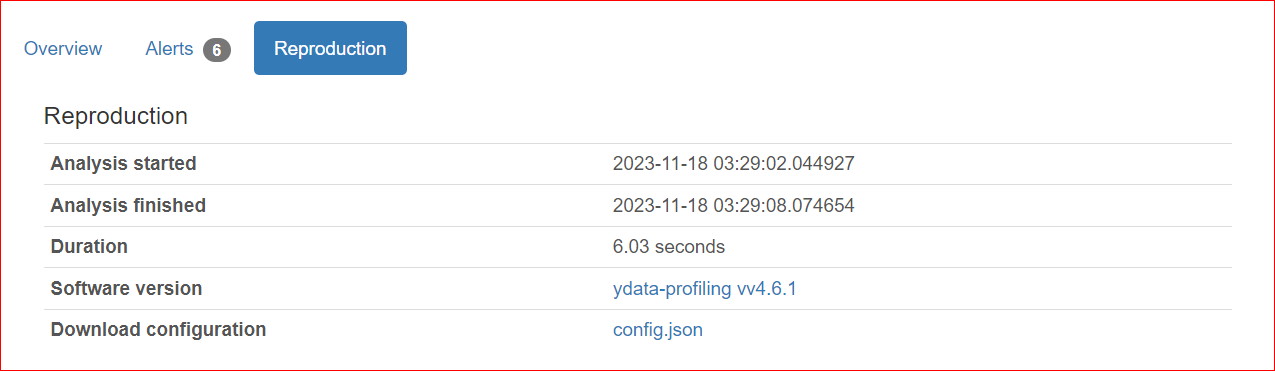
Thẻ Tái lập hiển thị thời điểm bắt đầu và kết thúc phân tích. Nó thể hiện thời lượng phân tích, bao gồm phiên bản phần mềm bạn đang dùng (trong trường hợp của tôi là ydata-profiling v4.6.1).
Phần Biến bao gồm tất cả các cột trong tập dữ liệu của bạn. Bạn có thể nhấp vào mũi tên bật/tắt và chọn bất kỳ cột nào.
Giả sử bạn đã chọn cột rating, báo cáo cho thấy cột này có 10 giá trị duy nhất được phân bố trên 100 hàng. Ngoài ra, có ba ô không có giá trị. Giá trị nhỏ nhất là 4,1, lớn nhất là 5. Giá trị trung bình của tất cả điểm đánh giá cũng được hiển thị.
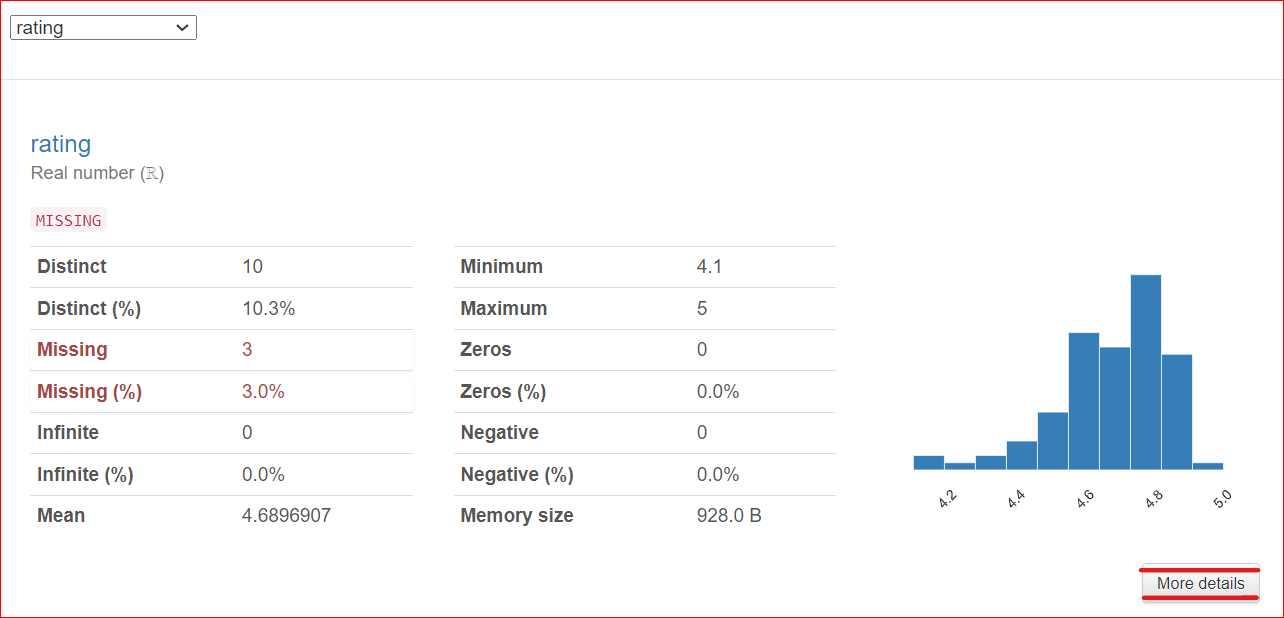
Một lưu ý quan trọng: có nút Chi tiết hơn ở góc dưới bên phải. Nhấp vào nút này để xem thêm thông tin về cột rating, như trung vị, độ lệch chuẩn, hệ số biến thiên và nhiều đặc trưng khác liên quan đến cột.
Phần này hỗ trợ nghiên cứu mối quan hệ giữa hai biến, tức là tương quan. Bản đồ nhiệt dưới đây hiển thị mối quan hệ giữa tất cả các biến với nhau. Rank liên hệ 100% với chính nó, vì vậy được thể hiện bằng ô vuông màu xanh đậm ở góc trên bên trái.
Năm xuất bản có mức tương quan trung bình với giá sách (khoảng 0,75), được biểu thị bằng màu xanh nhạt vì chúng không hoàn toàn liên hệ. Ví dụ, giá sách là 20,93 và năm xuất bản là 2023, nên các con số này có phần liên quan đến nhau.
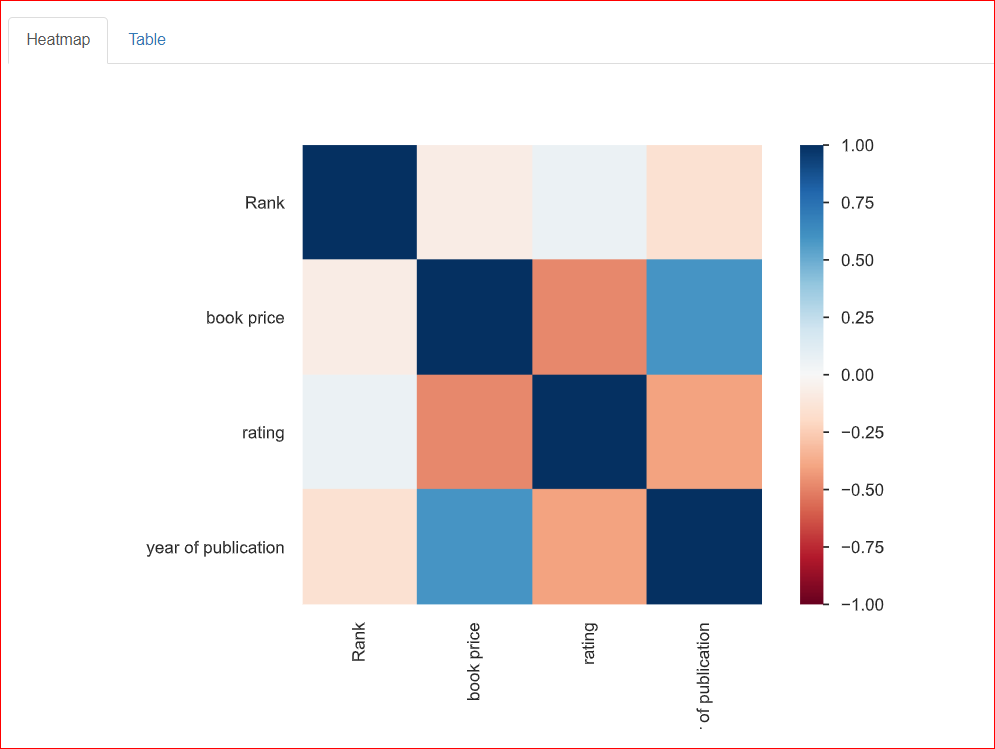
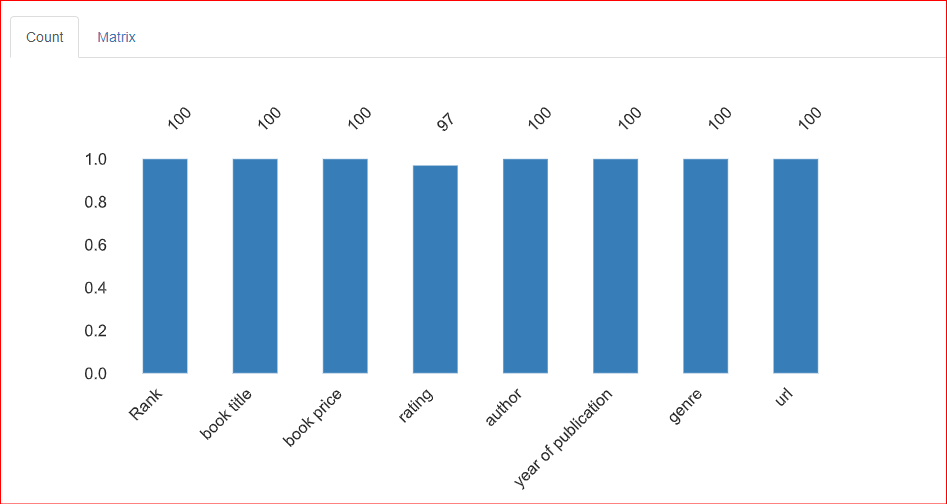
Phần này cung cấp thông tin về các giá trị thiếu trong tập dữ liệu. Thẻ Count của phần này cho biết có 3 giá trị thiếu ở cột rating.
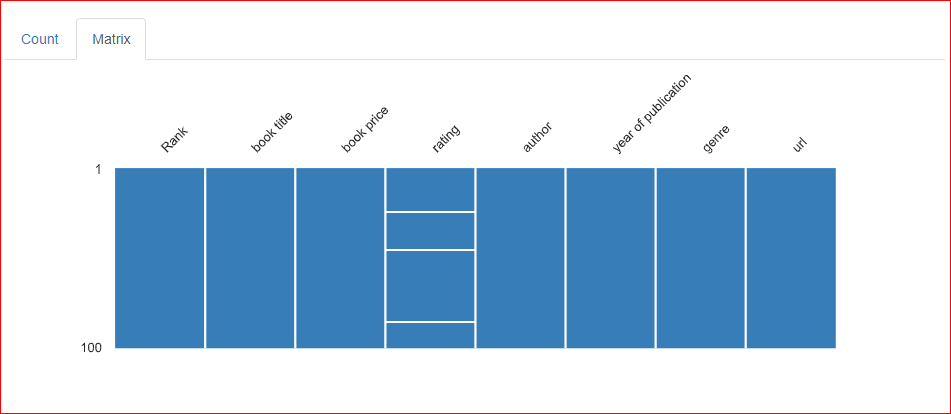
Trong thẻ Matrix của phần giá trị thiếu, có ba đường ngang ở cột Rating, cho thấy có ba giá trị bị thiếu trong cột.
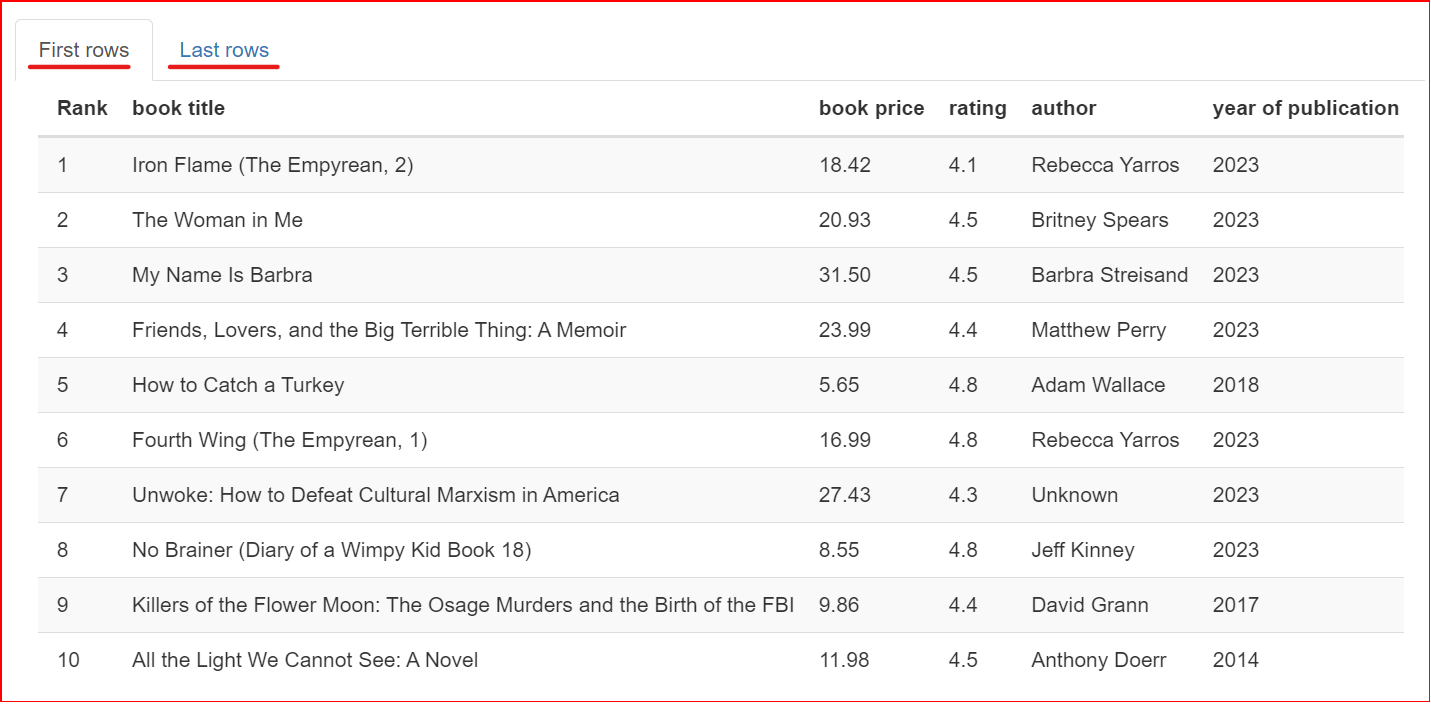
Phần này chứa mẫu của tập dữ liệu. Nó hiển thị 10 hàng đầu và 10 hàng cuối của tập dữ liệu.
Báo cáo hồ sơ của bạn đã được tạo và bạn có thể muốn lưu lại để sử dụng tiếp, chẳng hạn trích xuất dữ liệu hữu ích từ báo cáo hoặc tích hợp với ứng dụng khác. Bạn có thể lưu báo cáo ở định dạng HTML và JSON. Phương thức to_file() sẽ lưu báo cáo ra ngoài Jupyter Notebook.
Dưới đây là toàn bộ mã cho pandas profiling:
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Để tạo báo cáo, chúng ta chỉ cần truyền tệp CSV và không thêm gì khác. Chúng ta không bổ sung thành phần nào; chỉ dùng các giá trị mặc định trong thao tác.
Tuy nhiên, có thể có những phần bạn muốn bỏ qua hoặc thêm thông tin bổ sung. Đây là lúc các cách dùng nâng cao của Pandas Profiling phát huy tác dụng. Bạn có thể kiểm soát nhiều khía cạnh của báo cáo bằng cách thay đổi cấu hình mặc định.
Nếu bạn quan tâm đến việc tìm hiểu thêm về các công cụ phân tích và trực quan hoá dữ liệu, hãy đọc 21 Công cụ Python thiết yếu.
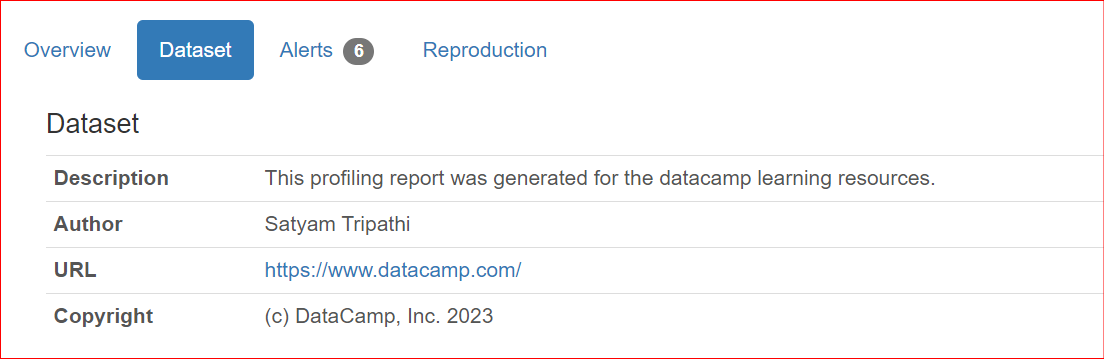
Khi chia sẻ báo cáo với đồng nghiệp hoặc xuất bản trực tuyến, có thể cần bao gồm metadata của tập dữ liệu, như tác giả, chủ sở hữu bản quyền hoặc mô tả. ydata-profiling cho phép bổ sung thông tin đó vào báo cáo.
Các thuộc tính hiện được hỗ trợ gồm description, creator, author, url, copyright_year và copyright_holder. Theo mặc định, các thông tin này được trình bày trong phần Tổng quan của báo cáo.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()Đây là kết quả mã:
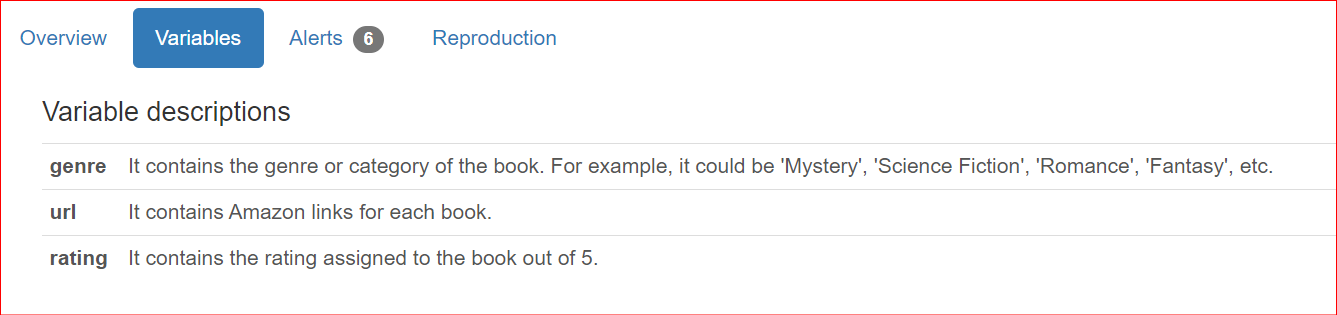
Bên cạnh việc cung cấp chi tiết về tập dữ liệu, người dùng thường muốn thêm mô tả theo từng cột khi chia sẻ báo cáo với thành viên nhóm và các bên liên quan. Theo mặc định, các mô tả này được trình bày trong phần Tổng quan của báo cáo.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()Đây là kết quả mã:
Theo mặc định, ydata-profiling tóm tắt toàn diện tập dữ liệu đầu vào để cung cấp nhiều insight nhất cho phân tích dữ liệu. Với các tập nhỏ, các phép tính này có thể thực hiện nhanh. Tuy nhiên, với tập lớn, việc này có thể trở nên cồng kềnh.
ydata-profiling bao gồm một cấu hình tối giản, trong đó các phép tính tốn kém nhất được tắt theo mặc định. Cấu hình này loại trừ các phần tốn thời gian như tương quan, tương tác, v.v.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling cũng cung cấp một số lựa chọn thay thế để vượt qua thách thức xử lý tập dữ liệu lớn. Khám phá chúng tại đây.
Trong bài viết, bạn đã tìm hiểu về thư viện độc đáo ydata-profiling, trước đây gọi là "Pandas Profiling", để tạo báo cáo chỉ với vài dòng mã. Bạn đã học cách tạo báo cáo hồ sơ và khám phá tất cả các phần và thẻ có trong báo cáo. Quan trọng nhất, bạn đã biết các cách dùng nâng cao của thư viện này, giúp bạn tiến thêm một bước trên hành trình khoa học dữ liệu.
Pandas là thư viện Python phổ biến nhất thế giới, dùng cho mọi việc từ xử lý đến phân tích dữ liệu. Để học cách thao tác với DataFrame khi bạn trích xuất, lọc và biến đổi các tập dữ liệu thực tế để phân tích, hãy xem khoá học Data Manipulation with pandas của chúng tôi.
Khám phá thêm các ứng dụng của pandas
Courses
Courses
Courses