
Cours
Ingestion de données simplifiée avec pandas
4 h
62.7K
Lorsqu'on travaille avec un jeu de données, par exemple 10 000 lignes et 50 colonnes, obtenir rapidement une vue d'ensemble peut s'avérer complexe. C'est là que pandas Profiling est très utile. Il automatise la génération d'un rapport complet sur votre jeu de données, réduisant le temps nécessaire pour explorer des volumes importants.
Dans cet article, vous apprendrez comment démarrer avec ce qui s'appelait autrefois pandas Profiling. Le nom du package pandas-profiling a récemment été remplacé par ydata-profiling. Dans ce tutoriel, vous verrez comment générer un rapport de profil à partir d'un jeu de données, ce que contient ce rapport, comment le lire et, enfin, comment le sauvegarder pour un usage ultérieur.
Pandas Profiling sert à produire un rapport complet et exhaustif d'un jeu de données, offrant de nombreuses fonctionnalités et options de personnalisation. Le rapport inclut des informations comme des statistiques globales, la distribution des valeurs, les valeurs manquantes, l'utilisation mémoire, etc., très utiles pour explorer et analyser efficacement les données.
Pandas Profiling est également très utile pour l'Exploratory Data Analysis (EDA). L'EDA permet de comprendre la structure sous-jacente des données, détecter des motifs et générer des insights de façon visuelle.
Sans cela, l'EDA nécessite souvent de nombreuses lignes de code, parfois complexes et chronophages. Avec pandas Profiling, quelques lignes suffisent pour automatiser une grande partie du travail.
Besoin d'une remise à niveau sur l'EDA ? Consultez Python Exploratory Data Analysis.
Voici un exemple de rapport de profil :
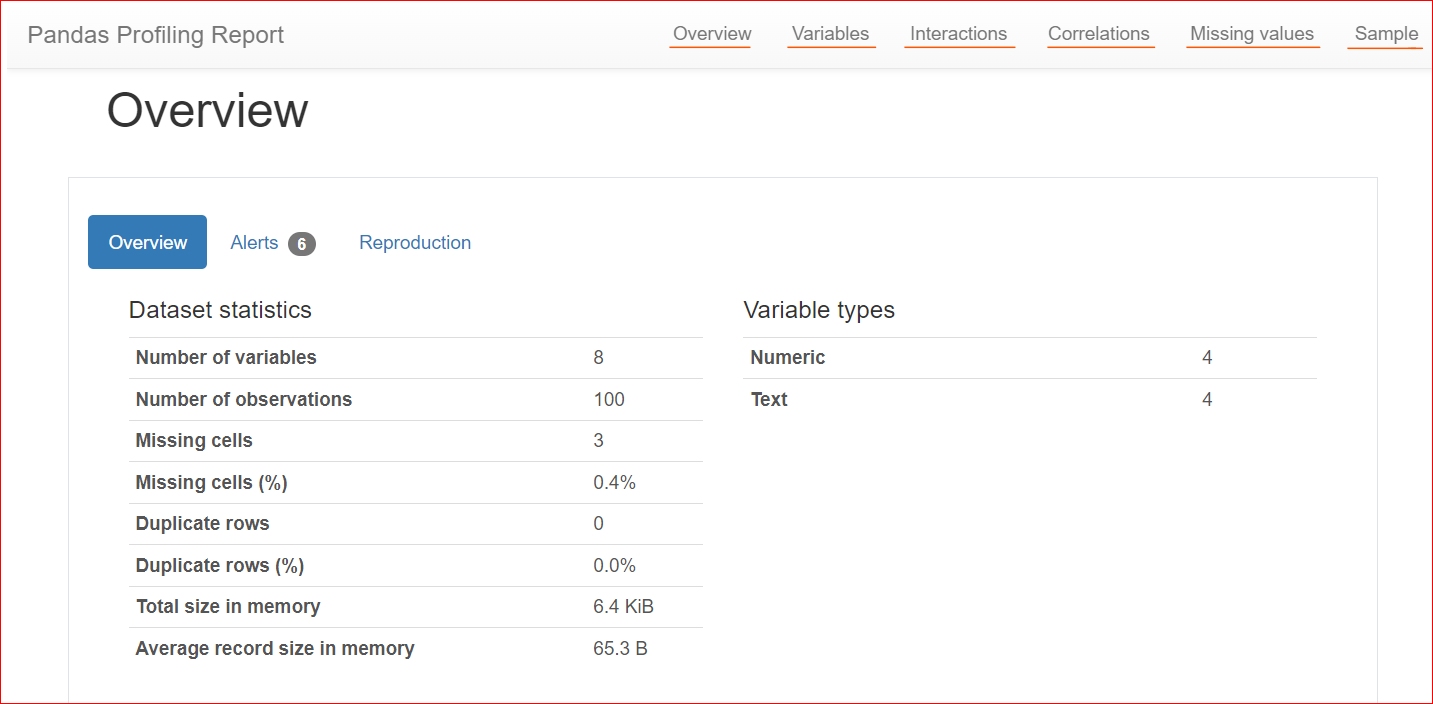
Image par l'auteur
Pandas Profiling est très prisé pour l'EDA grâce à sa simplicité d'usage, au gain de temps et à ses rapports HTML interactifs. Il présente toutefois quelques limites sur de très gros jeux de données.
Pour installer pandas Profiling, utilisez pip ou conda selon votre environnement et vos préférences.
Avec pip :
Ouvrez un terminal et lancez la commande suivante :
pip install ydata-profilingAvec Conda :
Ouvrez l'Anaconda PowerShell Prompt et exécutez :
conda install -c conda-forge ydata-profilingUne fois l'installation terminée, importez ydata-profiling avec l'instruction suivante.
from ydata_profiling import ProfileReportCela importe la classe ProfileReport de la bibliothèque ydata_profiling. Vous utiliserez cette classe pour générer des rapports de profil pour vos DataFrames.
Pour produire un rapport de profil, suivez les étapes ci-dessous :
ydata_profiling.ProfileReport() en lui passant le DataFrame.Voici un code simple qui suit ces étapes. On commence par importer les bibliothèques nécessaires puis on lit un fichier CSV avec read_csv(). Ici, nous utilisons le CSV des 100 meilleures ventes de livres et leurs avis. Ensuite, nous appelons la classe ProfileReport en lui passant notre DataFrame.
Nous définissons également un nouveau titre, "Trending Books". Par défaut, le titre est différent ; pour le personnaliser, utilisez le paramètre title de la classe. Enfin, pour générer et afficher le rapport, utilisez profile ou profile.to_notebook_iframe().
Le rapport est généré en plusieurs étapes : d'abord, résumé du jeu de données, puis construction de la structure du rapport, et enfin affichage. Vous pouvez l'enregistrer en HTML pour une analyse ultérieure.

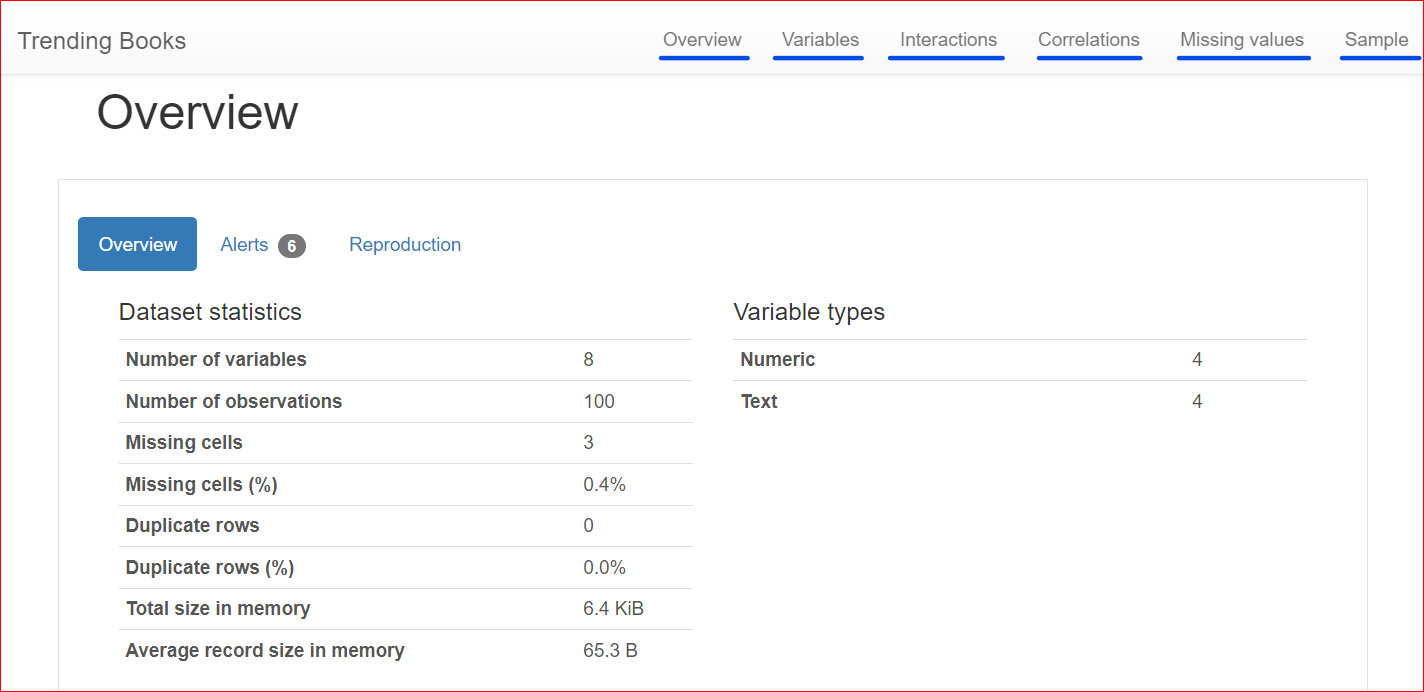
Voici le rapport généré, qui comporte différentes sections : Overview, Variables, Interactions, Correlations, Missing Values et Sample.
Si vous débutez en EDA et plus spécifiquement en data profiling, lisez Exploratory Data Analysis of Craft Beers : Data Profiling.
Le rapport est structuré en plusieurs sections ; explorons-les une à une.
Cette section comporte 3 onglets : Overview, Alerts et Reproduction.
L'onglet Overview présente des statistiques globales : nombre de variables (colonnes), nombre de cellules contenant des valeurs manquantes, lignes dupliquées et taille en mémoire.
Dans notre jeu de données, on compte 8 variables ou colonnes. Parmi elles, quatre sont numériques (classement, prix du livre, note et année de publication) et quatre sont textuelles (titre, auteur, genre et URL). Aucune ligne dupliquée (compteur à 0). La colonne "rating" comporte en outre trois valeurs manquantes.
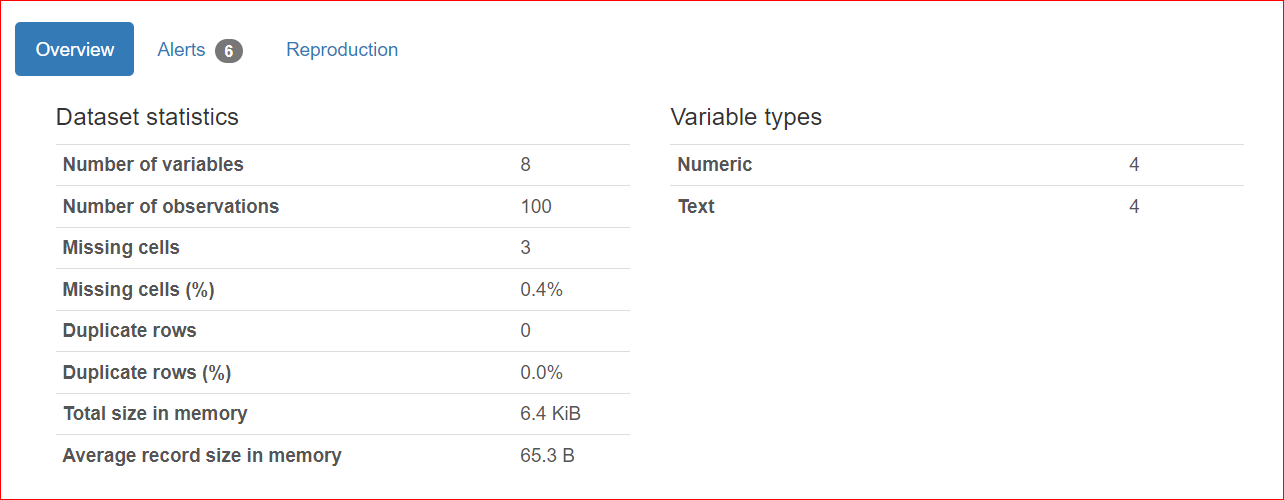
L'onglet Alerts regroupe des alertes liées aux corrélations entre variables, aux valeurs manquantes, aux valeurs uniques, aux zéros, etc.
Dans notre cas, les colonnes URL et Rank ont des valeurs uniques, et la colonne rating présente trois valeurs manquantes.
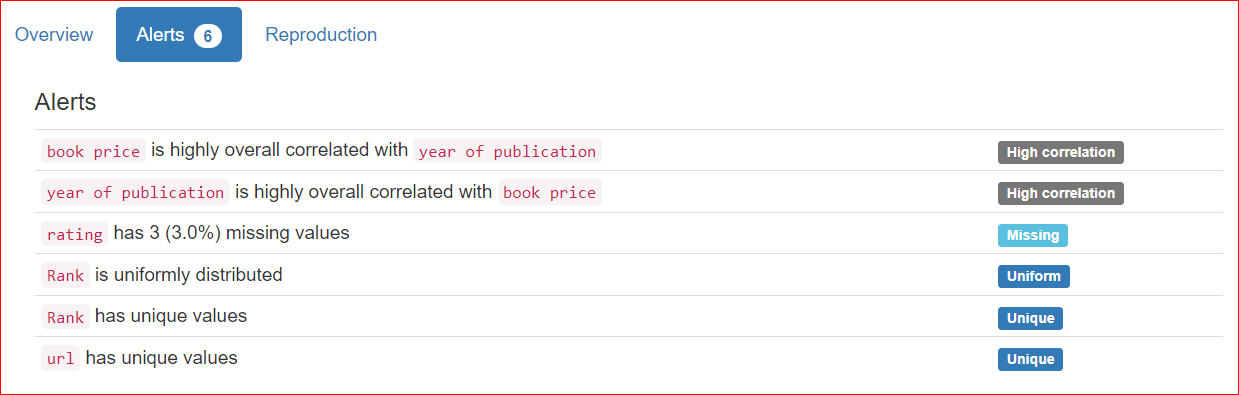
L'onglet Reproduction indique quand l'analyse a démarré et s'est terminée. Il affiche la durée de l'analyse ainsi que la version logicielle utilisée (ici, ydata-profiling v4.6.1).
La section Variables liste toutes les colonnes du jeu de données. Cliquez sur la flèche pour dérouler et sélectionner une colonne.
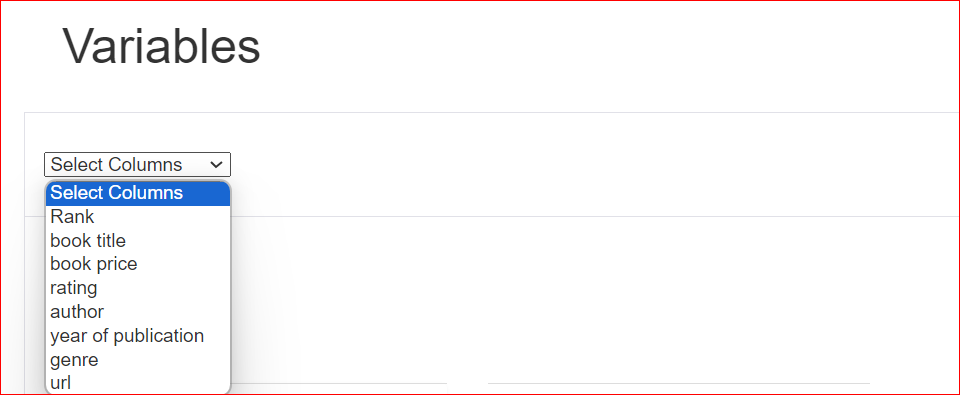
Si vous sélectionnez la colonne rating, le rapport indique qu'elle contient 10 valeurs uniques réparties sur 100 lignes. Trois cellules sont vides. La valeur minimale est 4,1 et la maximale 5. La moyenne des notes est également affichée.
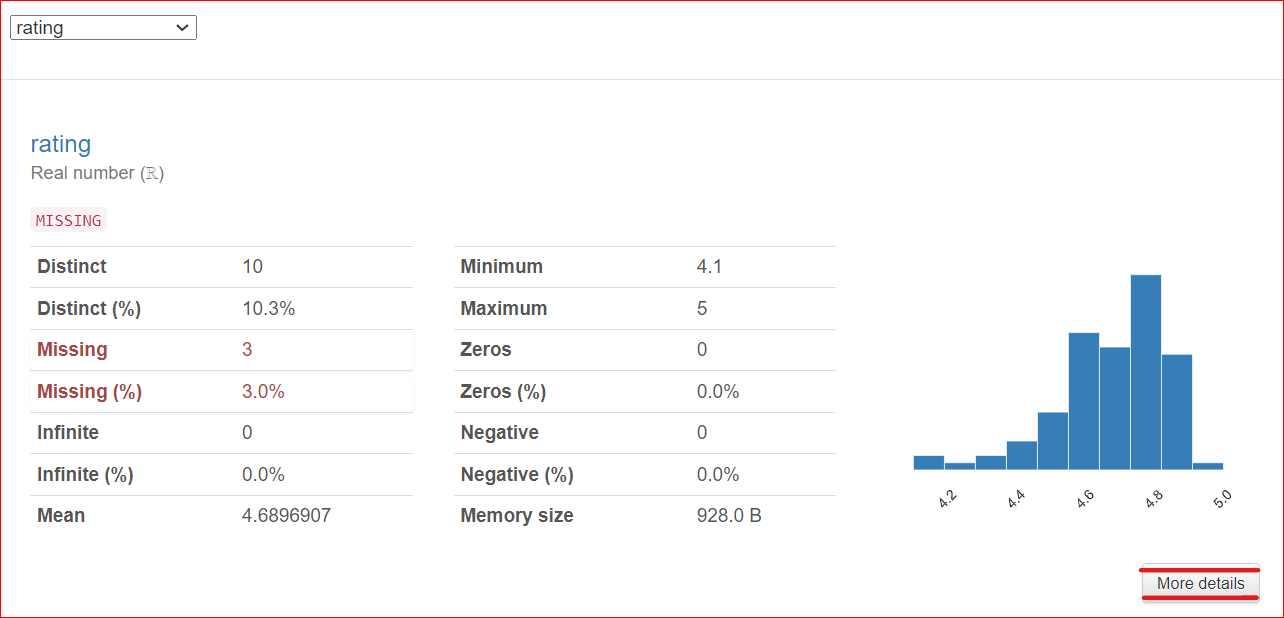
Point important : un bouton More Details se trouve en bas à droite. En cliquant, vous accédez à plus d'informations sur la colonne rating : médiane, écart-type, coefficient de variation et bien d'autres caractéristiques.
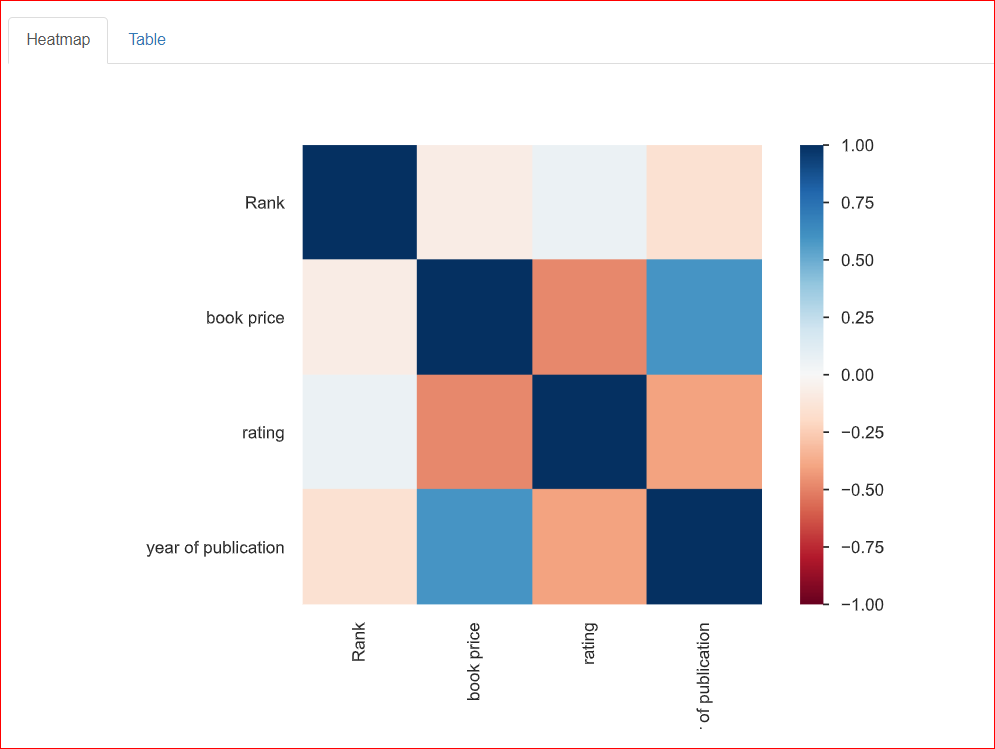
Cette section aide à étudier la relation entre deux variables, autrement dit la corrélation. La carte thermique ci-dessous montre les relations entre toutes les variables. Rank est corrélé à 100 % avec lui-même, d'où le carré bleu foncé en haut à gauche.
L'année de publication est modérément corrélée au prix du livre (autour de 0,75), représentée en bleu clair car la relation n'est pas parfaite. Par exemple, un prix de 20,93 et une année de 2023 sont en partie liés.
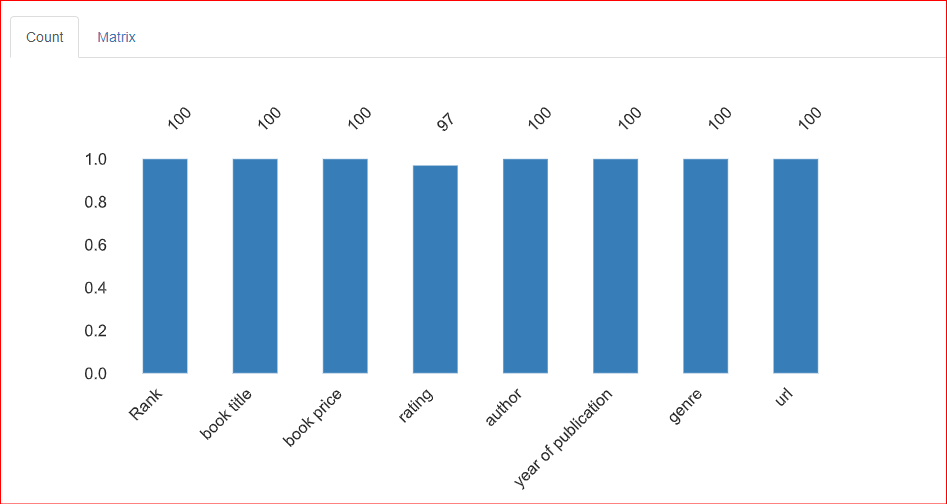
Cette section renseigne sur les valeurs manquantes du jeu de données. L'onglet Count indique qu'il y en a 3 dans la colonne rating.
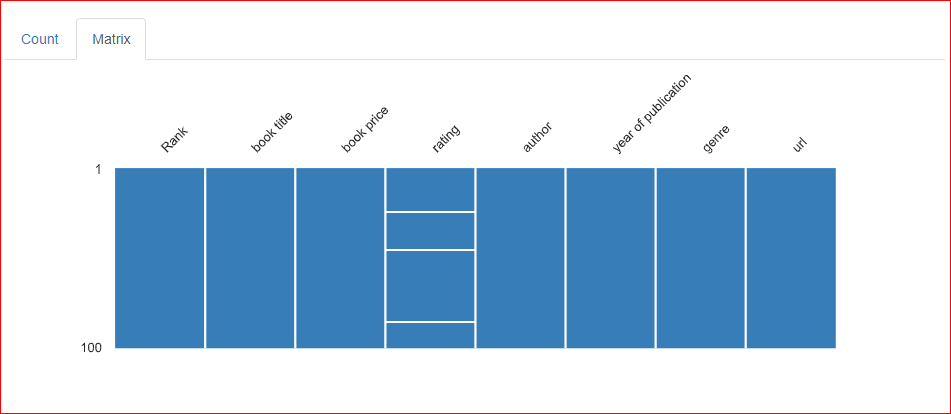
Dans l'onglet Matrix, trois lignes horizontales apparaissent dans la colonne Rating, ce qui indique trois valeurs manquantes.
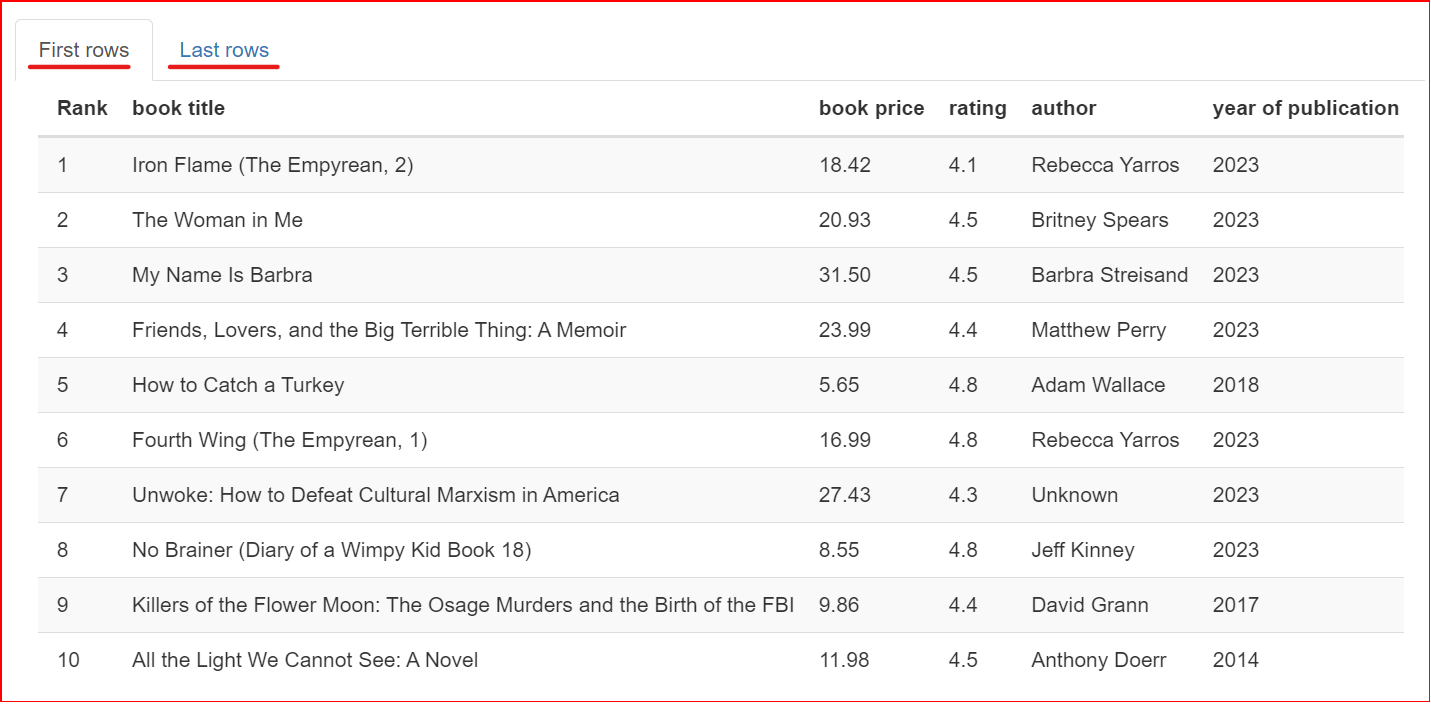
Cette section présente un échantillon du jeu de données : les 10 premières et les 10 dernières lignes.
Votre rapport de profil est généré et vous pouvez souhaiter le conserver pour extraire des informations utiles ou l'intégrer à d'autres applications. Vous pouvez l'enregistrer aux formats HTML et JSON. La méthode to_file() sauvegarde le rapport en dehors de Jupyter Notebook.
Voici le code complet pour pandas Profiling :
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Pour générer le rapport, nous avons simplement passé le fichier CSV sans autre paramètre : seules les valeurs par défaut sont utilisées.
Cependant, vous pouvez souhaiter omettre certaines sections ou ajouter des informations. C'est là que les usages avancés de pandas Profiling entrent en jeu. Vous pouvez contrôler de nombreux aspects du rapport en modifiant la configuration par défaut.
Pour aller plus loin en analyse et visualisation de données, lisez 21 Essential Python Tools.
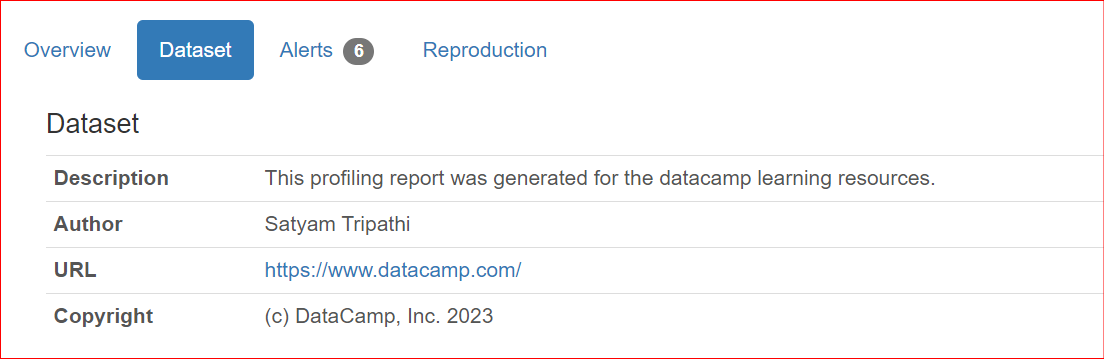
Lorsque vous partagez des rapports avec des collègues ou les publiez en ligne, il peut être utile d'ajouter des métadonnées comme l'auteur, le détenteur des droits ou une description. ydata-profiling permet d'enrichir le rapport avec ces informations.
Les propriétés actuellement prises en charge sont : description, creator, author, url, copyright_year et copyright_holder. Par défaut, elles apparaissent dans la section Overview du rapport.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()Voici le résultat :
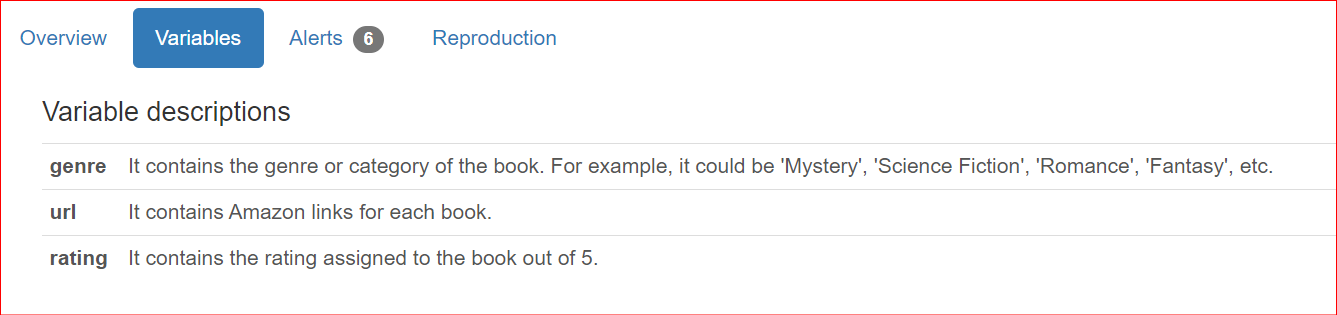
En plus des détails sur le jeu de données, il est fréquent de vouloir ajouter des descriptions spécifiques aux colonnes lors du partage avec des équipes et parties prenantes. Par défaut, ces descriptions figurent dans la section Overview du rapport.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()Voici le résultat :
Par défaut, ydata-profiling résume en profondeur le jeu de données d'entrée pour maximiser les insights. Sur de petits jeux, ces calculs sont rapides. Sur des ensembles volumineux, cela peut devenir trop lourd.
ydata-profiling propose une configuration minimale où les calculs les plus coûteux sont désactivés par défaut. Cette configuration exclut des sections chronophages comme les corrélations, les interactions, etc.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling offre aussi plusieurs alternatives pour gérer de très gros jeux de données. Découvrez-les ici.
Dans cet article, vous avez découvert la bibliothèque ydata-profiling, anciennement "pandas Profiling", qui permet de créer des rapports avec seulement quelques lignes de code. Vous avez appris à générer le rapport, à explorer ses sections et onglets, et surtout à exploiter ses usages avancés pour avancer d'un pas dans votre parcours en data science.
pandas est la bibliothèque Python la plus utilisée au monde, aussi bien pour la manipulation que pour l'analyse des données. Pour apprendre à manipuler des DataFrames — extraire, filtrer et transformer des jeux de données réels pour l'analyse — suivez notre cours Data Manipulation with pandas.
Découvrez d'autres usages de pandas
Cours
Cours
Cours
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali
Tutoriel
Aditya Sharma
Tutoriel
DataCamp Team
Tutoriel
Stephen Gruppetta
Tutoriel
Matt Crabtree