Curso
Ingestão de dados simplificada com pandas
4 h
62.7K
Ao lidar com um conjunto de dados, como um com 10.000 linhas e 50 colunas, obter uma visão geral rápida desses conjuntos de dados pode ser um desafio. É nesse ponto que o pandas Profiling é útil. Ele simplifica o processo gerando um relatório abrangente de seu conjunto de dados, minimizando o tempo de exploração desses grandes conjuntos de dados.
Neste artigo, você aprenderá como começar a usar o que antes era conhecido como pandas Profiling. O nome do pacote pandas-profiling foi recentemente alterado para ydata-profiling. Neste tutorial, você aprenderá a gerar um relatório de perfil a partir do conjunto de dados, o que está dentro do relatório de perfil, como ler esse relatório de perfil e, por fim, como salvar esse relatório para uso posterior.
O Pandas Profiling é usado para gerar um relatório completo e exaustivo para o conjunto de dados, com muitos recursos e personalizações no relatório gerado. Esse relatório inclui várias informações, como estatísticas do conjunto de dados, distribuição de valores, valores ausentes, uso de memória etc., que são muito úteis para explorar e analisar dados com eficiência.
O Pandas Profiling também ajuda muito na Análise Exploratória de Dados (EDA). A EDA é usada para entender a estrutura subjacente dos dados, detectar padrões e gerar percepções em um formato visual.
Para a EDA, temos que escrever muitas linhas de código, o que às vezes pode ser complexo e demorado, mas isso pode ser automatizado usando o Pandas Profiling com apenas algumas linhas de código.
Se você precisar de uma atualização sobre EDA, leia Python Exploratory Data Analysis.
Aqui está um exemplo de um relatório de perfil:
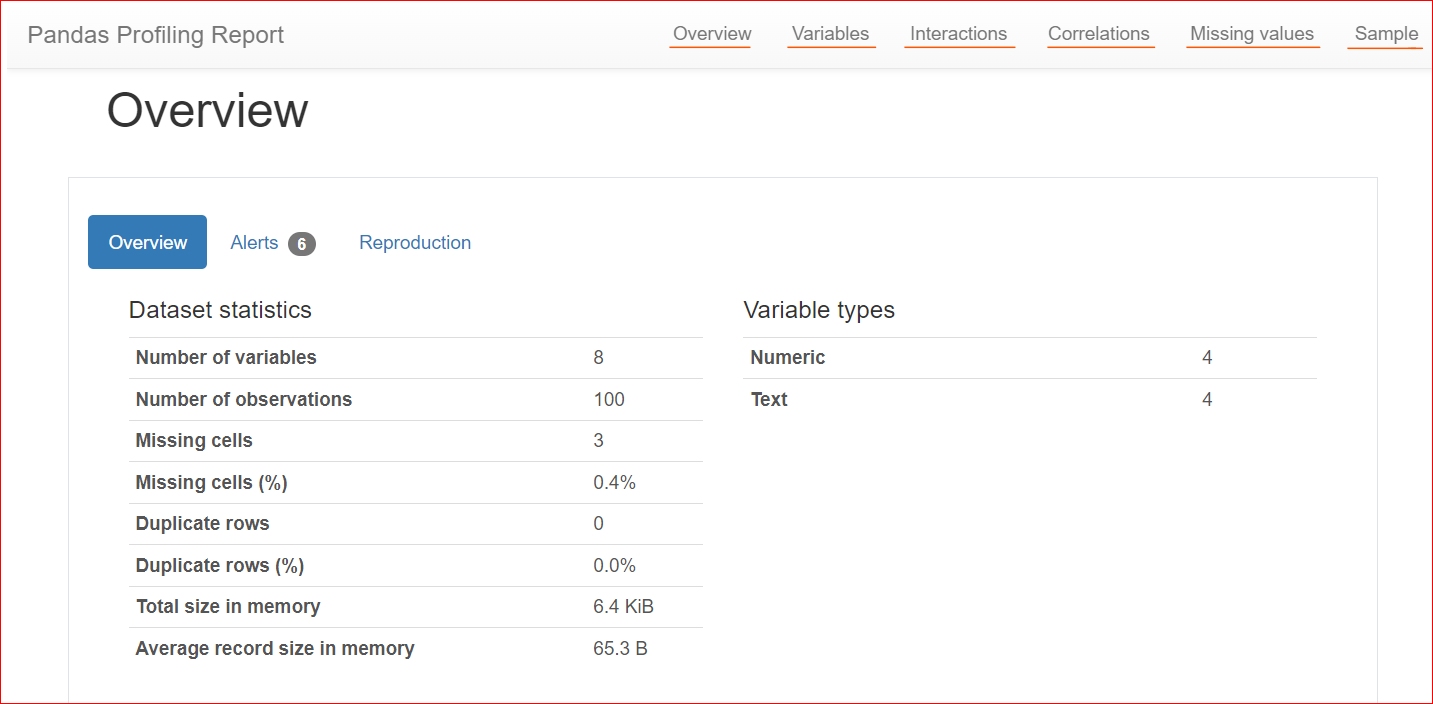
Imagem do autor
A criação de perfil do Pandas é amplamente usada na EDA devido à sua facilidade de uso, eficiência de tempo e relatórios HTML interativos. No entanto, há algumas possíveis desvantagens no uso da criação de perfil do pandas com grandes conjuntos de dados.
Para instalar o pandas Profiling, você pode usar o pip ou o conda, dependendo de sua preferência e ambiente.
Usando o Pip:
Abra um prompt de comando ou terminal e execute o seguinte comando:
pip install ydata-profilingUsando o Conda:
Abra o prompt do PowerShell do Anaconda e execute o seguinte comando:
conda install -c conda-forge ydata-profilingDepois que a instalação for concluída com êxito, importe o site ydata-profiling usando a seguinte instrução.
from ydata_profiling import ProfileReportIsso importará a classe ProfileReport da biblioteca ydata_profiling. Você pode usar essa classe para gerar relatórios de perfil para seus DataFrames.
Para gerar um relatório de perfil, siga as etapas abaixo:
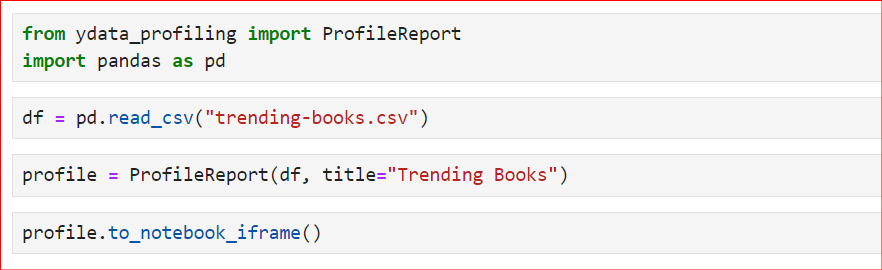
ydata_profiling.ProfileReport() e passe o DataFrame.Aqui está o código simples que segue as etapas descritas acima. Primeiro, importamos as bibliotecas necessárias e, em seguida, lemos o arquivo CSV usando a função read_csv(). Nesse caso, estamos usando o arquivo CSV das 100 principais resenhas de livros mais vendidos. Em seguida, usamos a classe ProfileReport e passamos nosso DataFrame para dentro dela.
Além disso, estamos definindo um novo título, "Trending Books". Por padrão, o título é outro, mas se você quiser personalizá-lo, use a variável title dentro da classe. Por fim, para gerar e exibir o relatório, você pode usar profile ou profile.to_notebook_iframe().
O relatório será gerado na seguinte sequência: Primeiro, todo o conjunto de dados será resumido. Em seguida, a estrutura do relatório será gerada. Por fim, ele exibirá o relatório, que pode ser salvo como um arquivo HTML e usado para análise posterior.

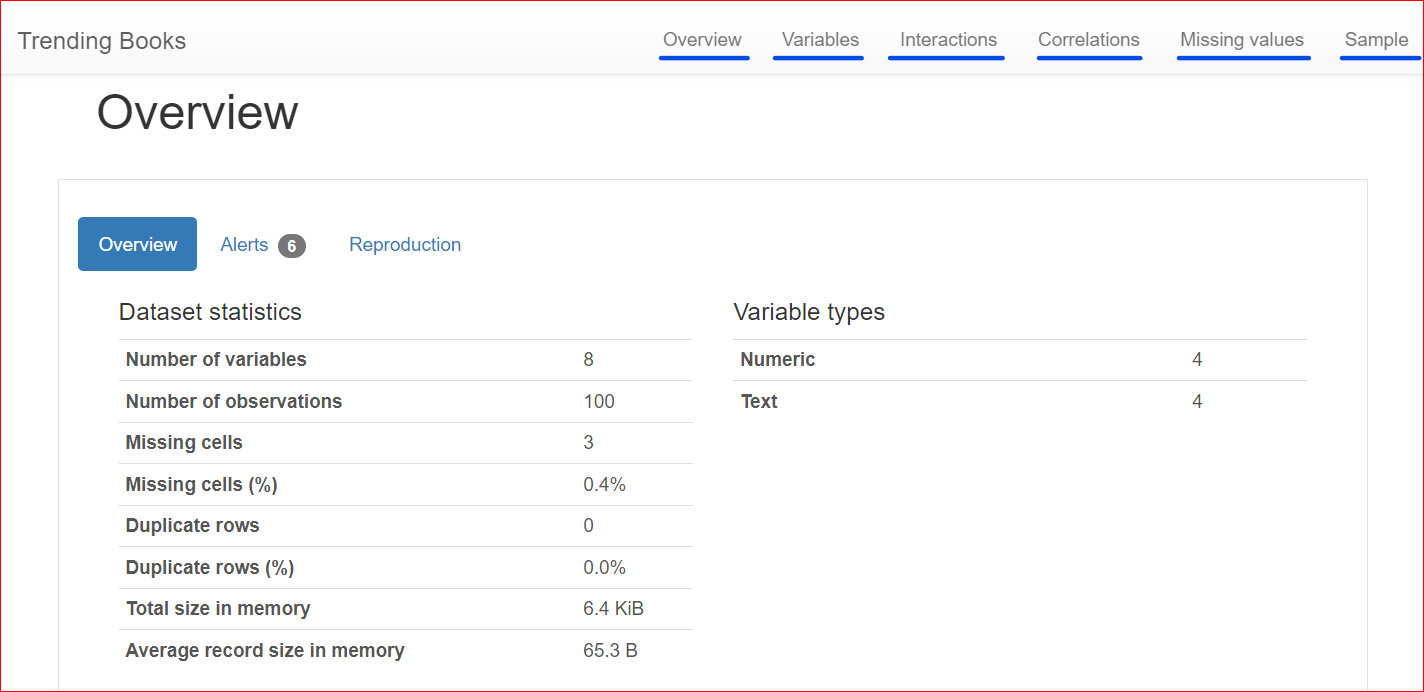
Aqui está o relatório gerado, que inclui diferentes seções, como Overview (Visão geral), Variables (Variáveis), Interactions (Interações), Correlations (Correlações), Missing Values (Valores ausentes) e Sample (Amostra).
Se você não conhece a EDA e, mais especificamente, a criação de perfis de dados, leia Exploratory Data Analysis of Craft Beers (Análise de dados exploratórios de cervejas artesanais): Perfil de dados.
O relatório é gerado em várias seções. Vamos explorar todas as seções, uma a uma.
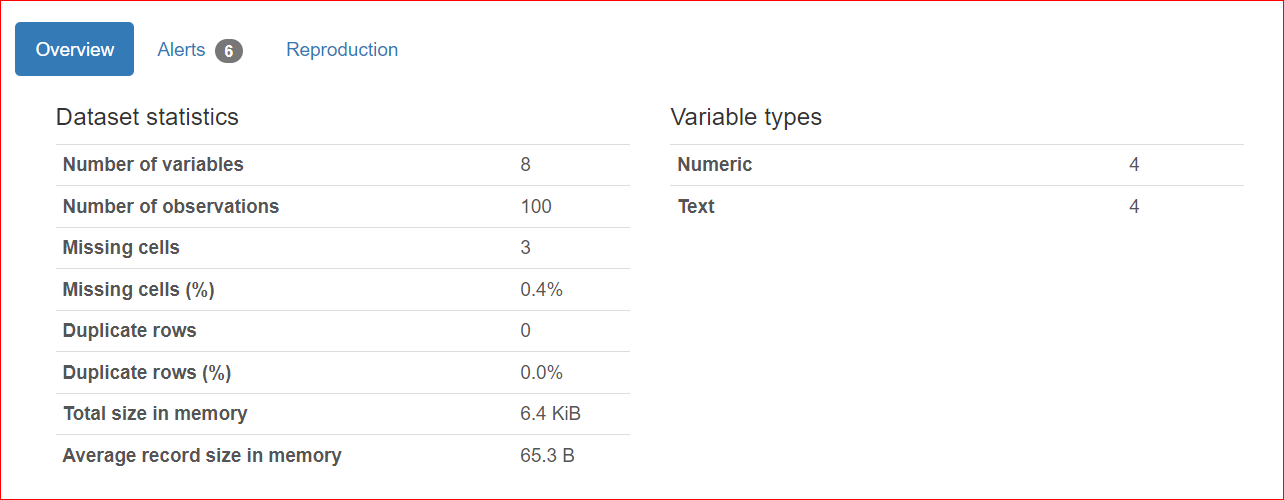
Essa seção consiste em 3 guias: Visão geral, alertas e reprodução.
A guia Overview (Visão geral) inclui estatísticas do conjunto de dados, como o número de variáveis (ou o número de colunas diferentes), o número de células que têm valores ausentes, linhas duplicadas e o tamanho do conjunto de dados na memória.
Em nosso conjunto de dados, há um total de 8 variáveis ou colunas. Entre as variáveis, quatro são numéricas (posição, preço do livro, classificação e ano de publicação), enquanto as quatro restantes são baseadas em texto (título do livro, autor, gênero e URL). Não há linhas duplicadas, conforme mostrado por uma contagem de 0 para duplicatas. Além disso, a coluna "rating" tem três valores ausentes.
A guia Alertas consiste em alertas relacionados a correlações com outras variáveis, valores ausentes, valores exclusivos, zeros, etc.
Em nosso caso, as colunas URL e Rank têm valores exclusivos, e a coluna de classificação tem três valores ausentes.
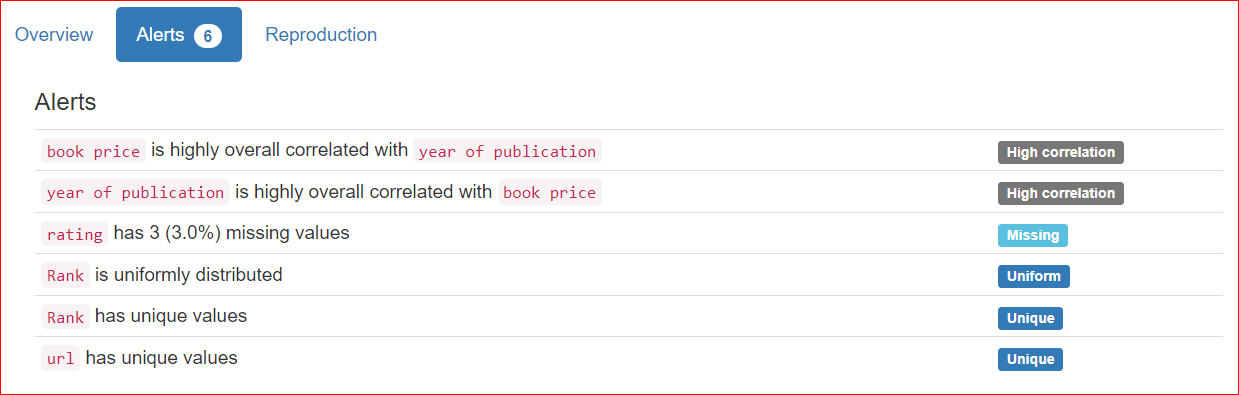
A guia Reprodução mostra quando a análise começou e quando terminou. Ele exibe a duração da análise, incluindo a versão do software que você está usando (no meu caso, é o ydata-profiling v4.6.1).
A seção Variables (Variáveis ) inclui todas as colunas do seu conjunto de dados. Você pode clicar na seta de alternância e selecionar qualquer coluna.
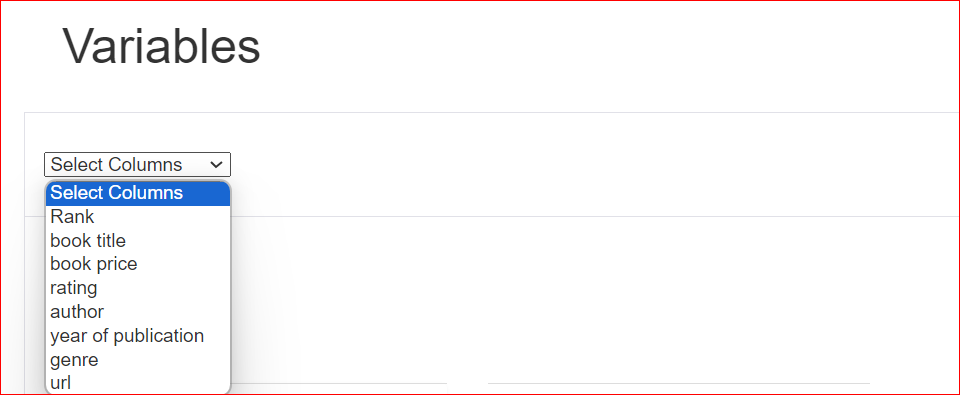
Supondo que você tenha selecionado a coluna de classificação, o relatório mostra que essa coluna contém 10 valores exclusivos distribuídos em 100 linhas. Além disso, três células não têm valor algum. O valor mínimo é 4,1, enquanto o máximo é 5. A média de todas as classificações também é exibida.
Uma observação importante: um botão More Details (Mais detalhes ) está localizado no canto inferior direito. Ao clicar nesse botão, é possível acessar mais informações sobre a coluna de classificação, como a mediana, o desvio padrão, o coeficiente de variação e várias outras características associadas à coluna.
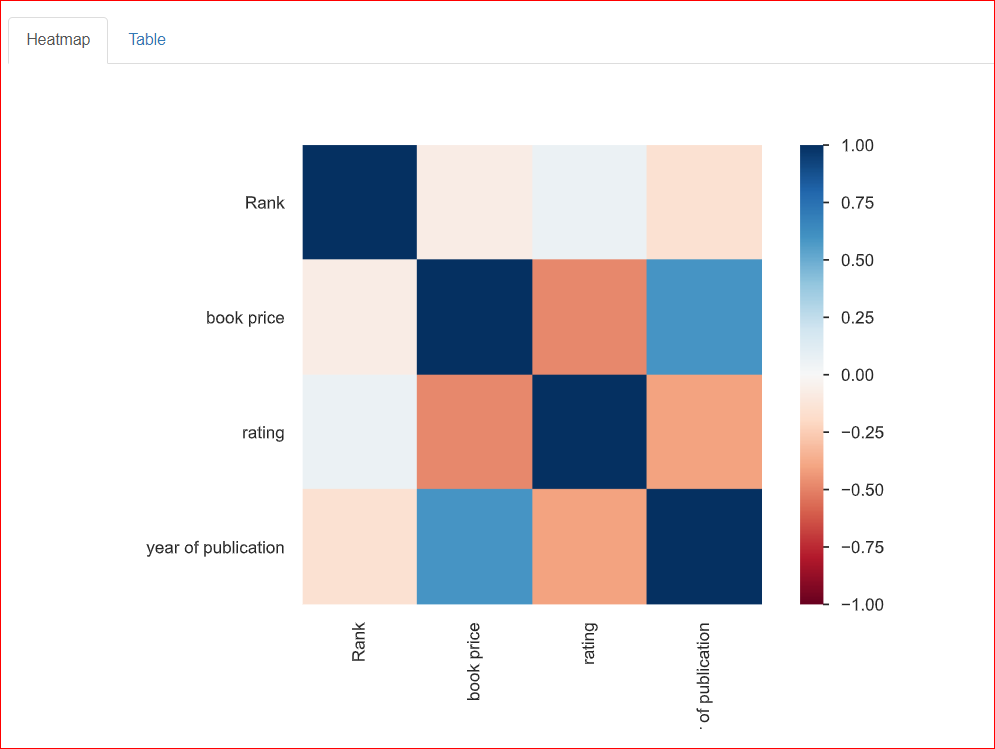
Ela ajuda no estudo da relação entre duas variáveis, o que é conhecido como correlação. O mapa de calor abaixo mostra as relações entre todas as variáveis entre si. A classificação está 100% relacionada à classificação, e é por isso que é representada pelo quadrado azul escuro no canto superior esquerdo.
O ano de publicação está moderadamente relacionado ao preço do livro (cerca de 0,75), que é representado pela cor azul claro porque não estão totalmente relacionados. Por exemplo, o preço do livro é 20,93 e o ano de publicação é 2023, portanto, esses números estão de certa forma relacionados entre si.
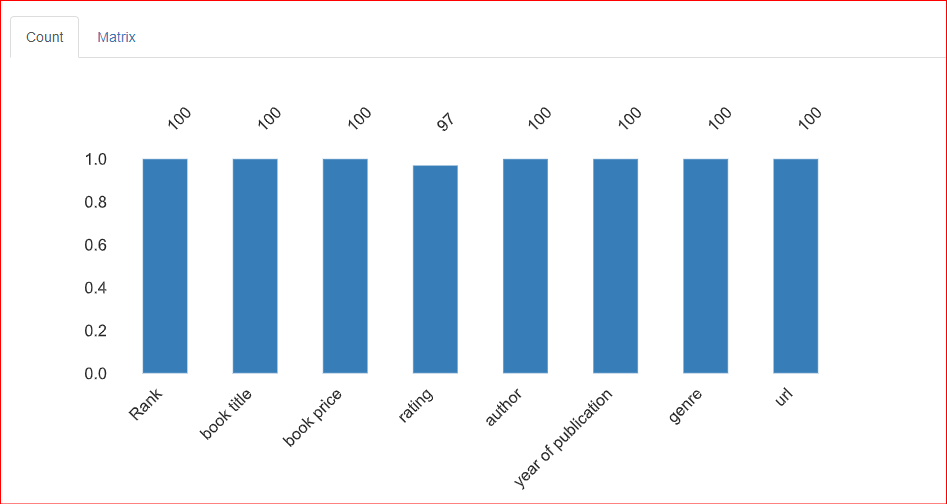
Esta seção fornece informações sobre os valores ausentes no conjunto de dados. A guia Contagem dessa seção indica que há 3 valores ausentes na coluna de classificação.
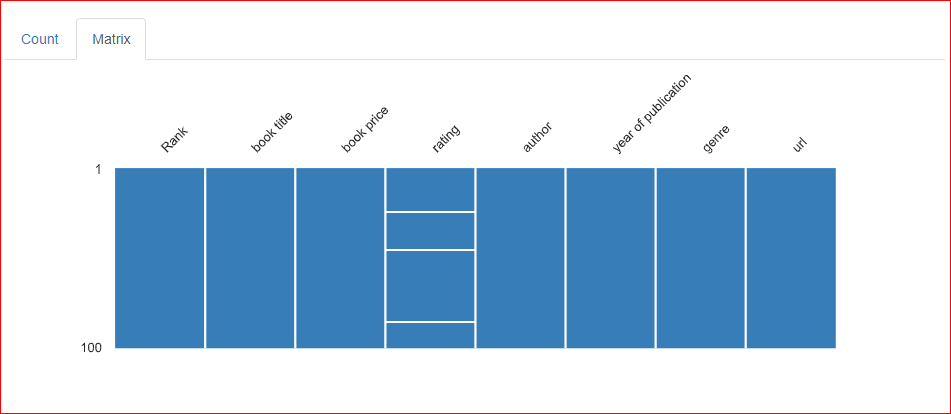
Na guia Matrix da seção de valores ausentes, três linhas horizontais estão presentes na coluna Rating, o que indica que três valores estão ausentes na coluna.
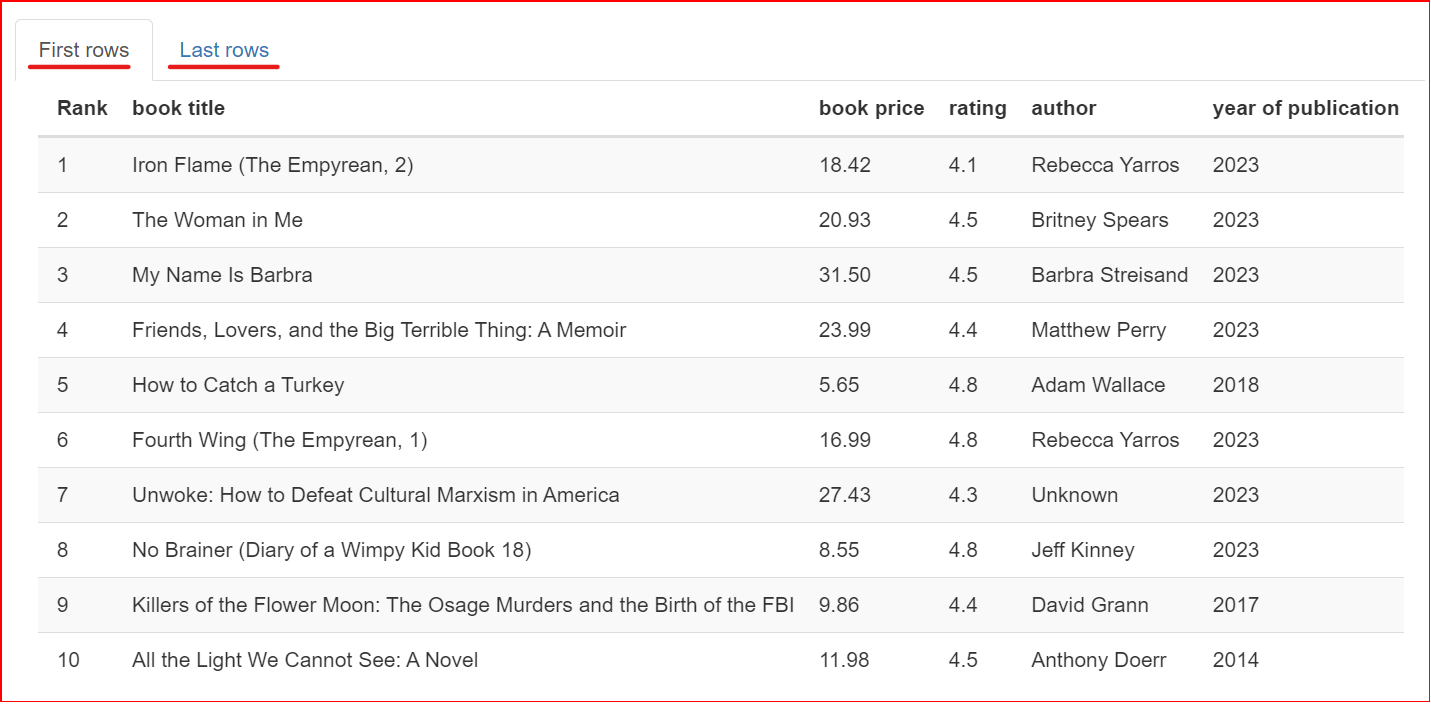
Esta seção contém uma amostra do conjunto de dados. Ele exibe as primeiras e as últimas 10 linhas do conjunto de dados.
O relatório de perfil é gerado e talvez você queira salvá-lo para uso posterior, como extrair dados úteis do relatório de perfil ou integrá-lo a outros aplicativos. Você pode salvar o relatório nos formatos HTML e JSON. O método to_file() salvará o relatório fora do Jupyter Notebook.
Aqui está o código completo para a criação de perfil do Pandas:
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Para gerar o relatório, simplesmente passamos o arquivo CSV e nada mais. Não incluímos nenhum elemento extra; apenas os valores padrão são usados nas ações.
No entanto, pode haver seções que você queira omitir ou incluir informações adicionais. É aqui que os usos avançados do Pandas Profiling entram em ação. Você pode controlar vários aspectos do relatório alterando a configuração padrão.
Se você estiver interessado em saber mais sobre ferramentas de análise e visualização de dados, leia 21 ferramentas essenciais do Python.
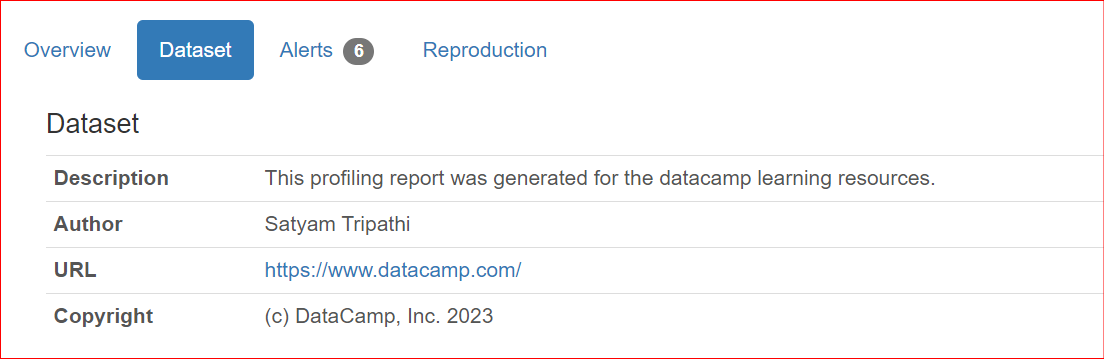
Ao compartilhar relatórios com colegas de trabalho ou publicá-los on-line, pode ser importante incluir metadados do conjunto de dados, como o autor, o detentor dos direitos autorais ou as descrições. O site ydata-profiling permite complementar um relatório com essas informações.
As propriedades suportadas atualmente são description, creator, author, url, copyright_year e copyright_holder. Por padrão, os conjuntos de dados são apresentados na seção Visão geral do relatório.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()Aqui está a saída do código:
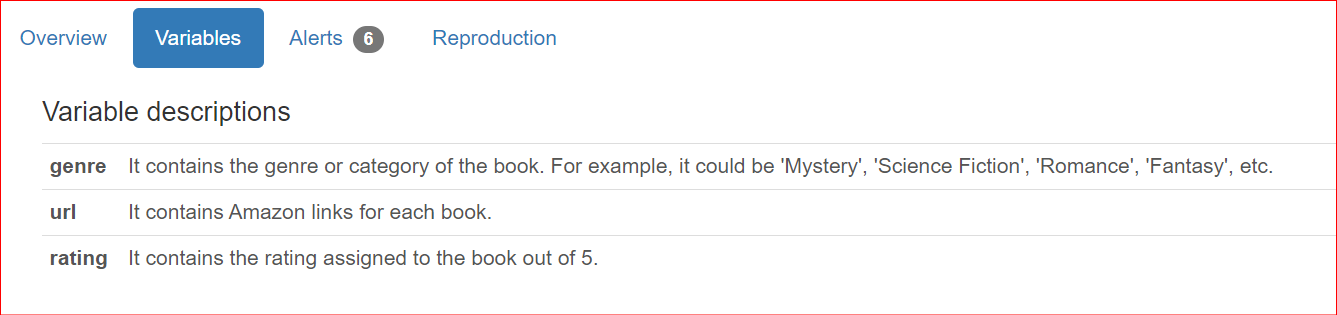
Além de oferecer detalhes do conjunto de dados, os usuários geralmente desejam incluir descrições específicas da coluna ao compartilhar relatórios com membros da equipe e partes interessadas. Por padrão, essas descrições são apresentadas na seção Visão geral do relatório.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()Aqui está a saída do código:
Por padrão, o site ydata-profiling resume de forma abrangente o conjunto de dados de entrada para fornecer o máximo de insights para a análise de dados. Para conjuntos de dados pequenos, esses cálculos podem ser realizados rapidamente. No entanto, para conjuntos de dados maiores, isso pode se tornar muito complicado.
ydata-profiling inclui um arquivo de configuração mínimo em que os cálculos mais caros são desativados por padrão. Essa configuração exclui seções demoradas, como correlações, interações etc.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling também oferece várias alternativas para superar o desafio de lidar com grandes conjuntos de dados. Explore-os aqui.
No artigo, você aprendeu sobre a biblioteca exclusiva,ydata-profiling,, anteriormente conhecida como "Pandas Profiling", para criar relatórios com apenas algumas linhas de código. Você aprendeu a gerar o relatório de perfil e a explorar todas as seções e guias presentes no relatório de perfil. Mais importante ainda, você aprendeu sobre os usos avançados dessa biblioteca, o que o levará um passo à frente em sua jornada de ciência de dados.
O Pandas é a biblioteca Python mais popular do mundo, usada para tudo, desde a manipulação de dados até a análise de dados. Para saber como manipular DataFrames à medida que você extrai, filtra e transforma conjuntos de dados do mundo real para análise, confira nosso curso sobre Manipulação de dados com pandas.
Explorar mais usos de pandas
Curso
Curso
Curso
blog
Moez Ali
9 min
Tutorial
Vidhi Chugh
Tutorial
Karlijn Willems
Tutorial
Abid Ali Awan
Tutorial
Kevin Babitz
Tutorial
Karlijn Willems


