
Kurs
pandas ile Kolaylaştırılmış Veri Alımı
4 sa
63.2K
10.000 satır ve 50 sütun gibi bir veri kümesiyle çalışırken, bu veri kümelerini hızla genel hatlarıyla görmek zor olabilir. İşte bu noktada pandas Profiling işe yarar. Veri kümenizin kapsamlı bir raporunu oluşturarak süreci kolaylaştırır ve büyük veri kümelerini keşfetmek için gereken zamanı en aza indirir.
Bu makalede, eskiden pandas Profiling olarak bilinen araçla nasıl başlayacağınızı öğreneceksiniz. pandas-profiling paket adı yakın zamanda ydata-profiling olarak değiştirildi. Bu eğitimde, veri kümesinden profil raporu oluşturmayı, profil raporunun içinde nelerin bulunduğunu, bu raporun nasıl okunacağını ve son olarak raporu ileri kullanım için nasıl kaydedeceğinizi öğreneceksiniz.
Pandas Profiling, veri kümesi için eksiksiz ve kapsamlı bir rapor oluşturmak amacıyla kullanılır; oluşturulan raporda birçok özellik ve özelleştirme bulunur. Bu rapor, veri kümesi istatistikleri, değer dağılımları, eksik değerler, bellek kullanımı vb. gibi çeşitli bilgileri içerir ve verileri verimli bir şekilde keşfetmek ve analiz etmek için çok kullanışlıdır.
Pandas Profiling, Keşifsel Veri Analizi (EDA) sürecinde de oldukça yardımcıdır. EDA, verinin temel yapısını anlamak, kalıpları tespit etmek ve içgörüleri görsel formatta üretmek için kullanılır.
EDA için genellikle çok sayıda kod satırı yazmamız gerekir; bu da bazen karmaşık ve zaman alıcı olabilir, ancak Pandas Profiling ile sadece birkaç satır kodla otomatikleştirilebilir.
EDA konusunda kısa bir hatırlatmaya ihtiyacınız varsa, Python ile Keşifsel Veri Analizi yazımıza göz atın.
İşte bir profil raporu örneği:
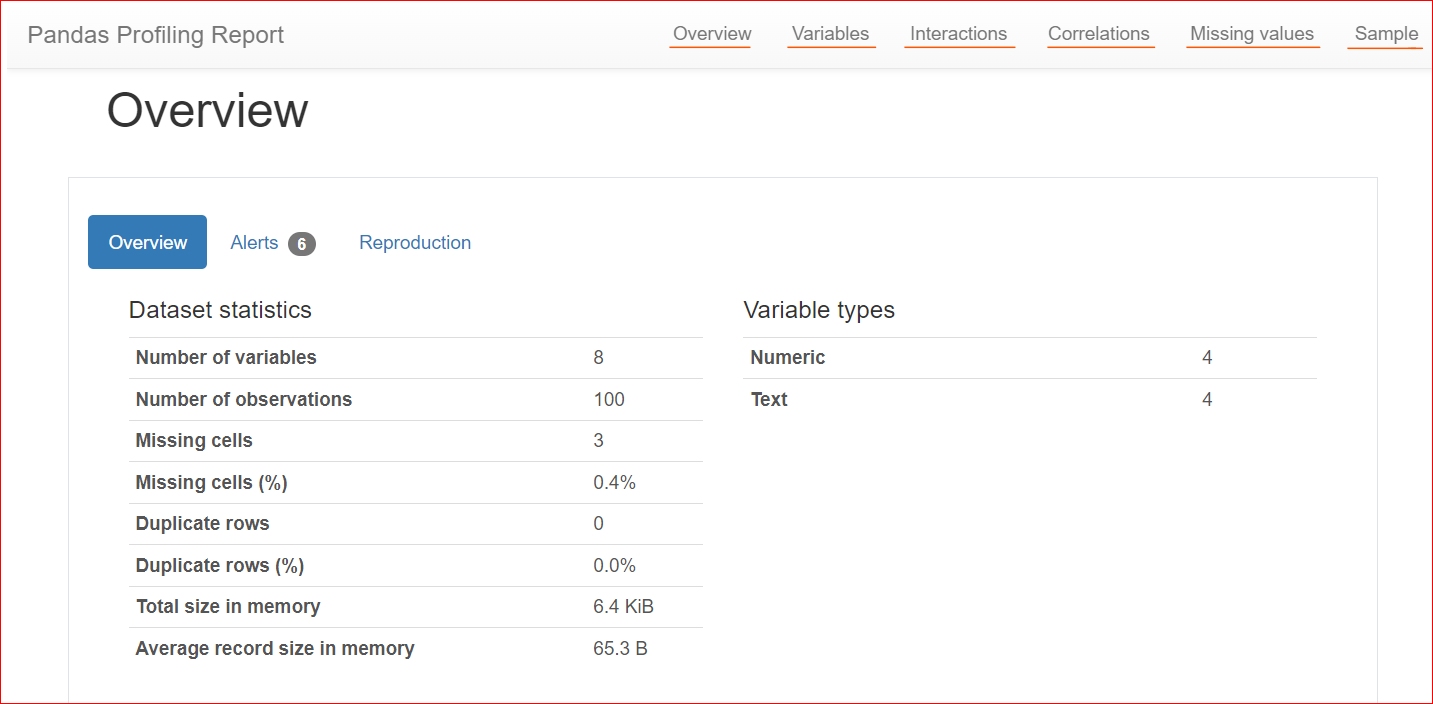
Görsel: Yazar
Pandas profiling; kullanım kolaylığı, zaman verimliliği ve etkileşimli HTML raporları sayesinde EDA'da yaygın olarak kullanılır. Ancak, büyük veri kümeleriyle pandas profiling kullanmanın bazı olası sakıncaları vardır.
pandas Profiling'i kurmak için tercihinize ve ortamınıza bağlı olarak pip veya conda kullanabilirsiniz.
Pip kullanarak:
Bir komut istemi veya terminal açın ve aşağıdaki komutu çalıştırın:
pip install ydata-profilingConda kullanarak:
Anaconda PowerShell Prompt'u açın ve aşağıdaki komutu çalıştırın:
conda install -c conda-forge ydata-profilingKurulum başarıyla tamamlandıktan sonra, aşağıdaki ifade ile ydata-profiling'i içe aktarın.
from ydata_profiling import ProfileReportBu, ydata_profiling kütüphanesinden ProfileReport sınıfını içe aktaracaktır. Bu sınıfı DataFrame'leriniz için profil raporları oluşturmakta kullanabilirsiniz.
Bir profil raporu oluşturmak için aşağıdaki adımları izleyin:
ydata_profiling kütüphanesinden ProfileReport sınıfını içe aktarın.ProfileReport() sınıfını kullanın ve DataFrame'i iletin.Yukarıda belirtilen adımları izleyen basit kod aşağıdadır. Önce gerekli kütüphaneleri içe aktarıyoruz, ardından read_csv() işleviyle CSV dosyasını okuyoruz. Bu örnekte, En Çok Satan 100 Kitap İncelemesinin CSV dosyasını kullanıyoruz. Sonrasında ProfileReport sınıfını kullanıp DataFrame'imizi içine iletiyoruz.
Ayrıca, başlığı "Trending Books" olarak ayarlıyoruz. Varsayılan başlık farklıdır; ancak özelleştirmek isterseniz sınıf içindeki title değişkenini kullanın. Son olarak, raporu oluşturup görüntülemek için profile veya profile.to_notebook_iframe() kullanabilirsiniz.
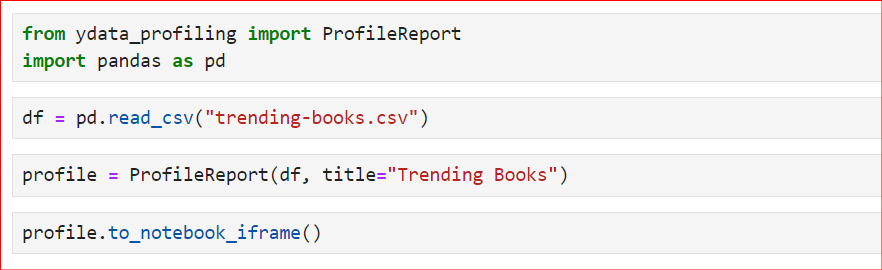
Rapor şu sırayla oluşturulacaktır: İlk olarak, tüm veri kümesi özetlenecek. Ardından rapor yapısı oluşturulacak. Son olarak, rapor görüntülenecek; bu raporu HTML dosyası olarak kaydedebilir ve ileri analizlerde kullanabilirsiniz.

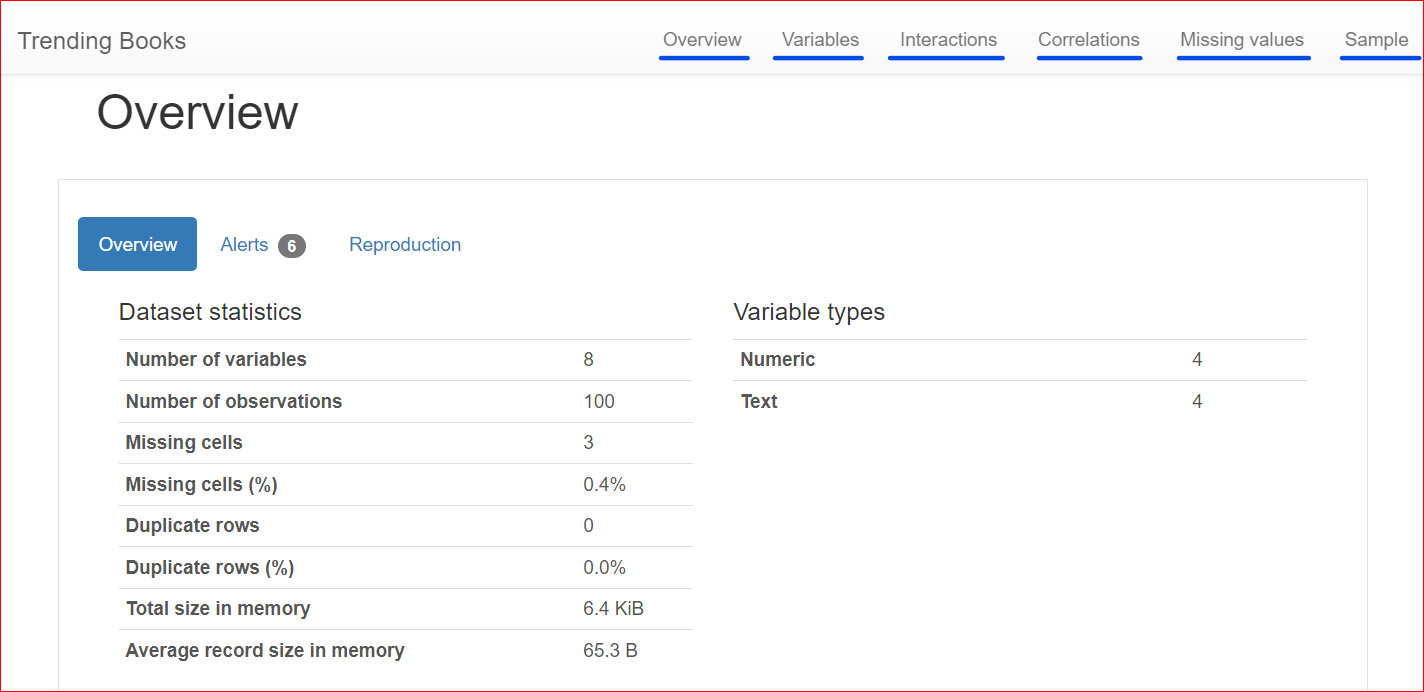
İşte Genel Bakış, Değişkenler, Etkileşimler, Korelasyonlar, Eksik Değerler ve Örnek gibi farklı bölümler içeren oluşturulmuş rapor.
EDA'ya ve özellikle veri profillemeye yeniyseniz, Zanaat Birasında Keşifsel Veri Analizi: Veri Profilleme yazımıza göz atın.
Rapor birçok bölümden oluşur; gelin bölümleri tek tek inceleyelim.
Bu bölüm 3 sekmeden oluşur: Overview, Alerts ve Reproduction.
Overview sekmesi; değişken sayısı (ya da farklı sütun sayısı), eksik değerlere sahip hücrelerin sayısı, yinelenen satırlar ve veri kümesinin bellekte kapladığı boyut gibi veri kümesi istatistiklerini içerir.
Veri kümemizde toplam 8 değişken veya sütun vardır. Değişkenlerin dördü sayısal (sıralama, kitap fiyatı, puan ve yayımlanma yılı), kalan dördü ise metin tabanlıdır (kitap adı, yazar, tür ve URL). Kopya satır yoktur; bu, yinelenenler için 0 sayısıyla gösterilmiştir. Ayrıca 'rating' sütununda üç eksik değer vardır.
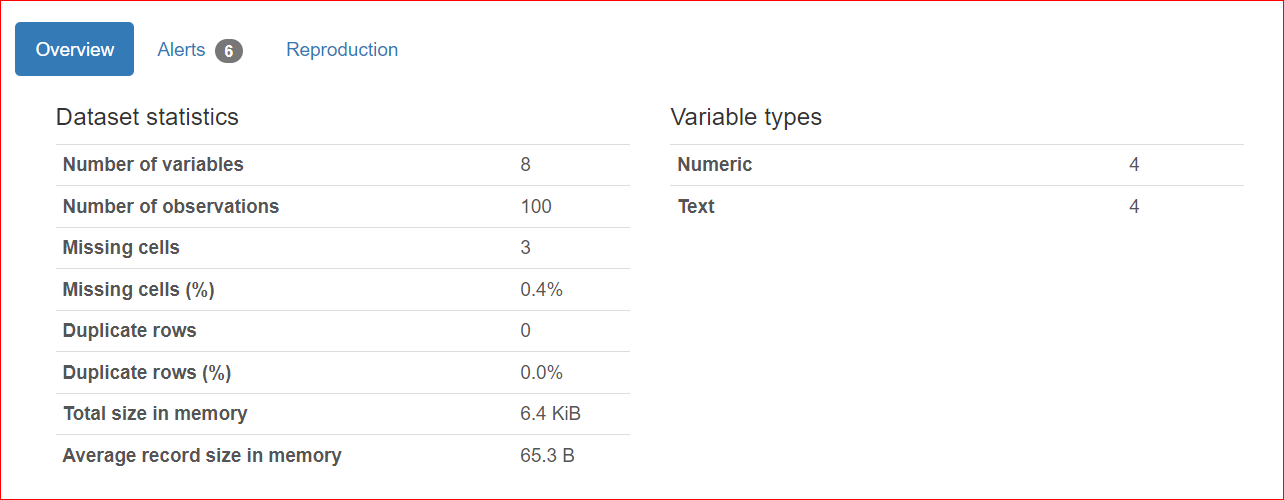
Alerts sekmesi, diğer değişkenlerle olan korelasyonlar, eksik değerler, benzersiz değerler, sıfırlar vb. ile ilgili uyarılardan oluşur.
Bizim durumumuzda, URL ve Rank sütunlarının benzersiz değerleri vardır ve rating sütununda üç eksik değer bulunmaktadır.
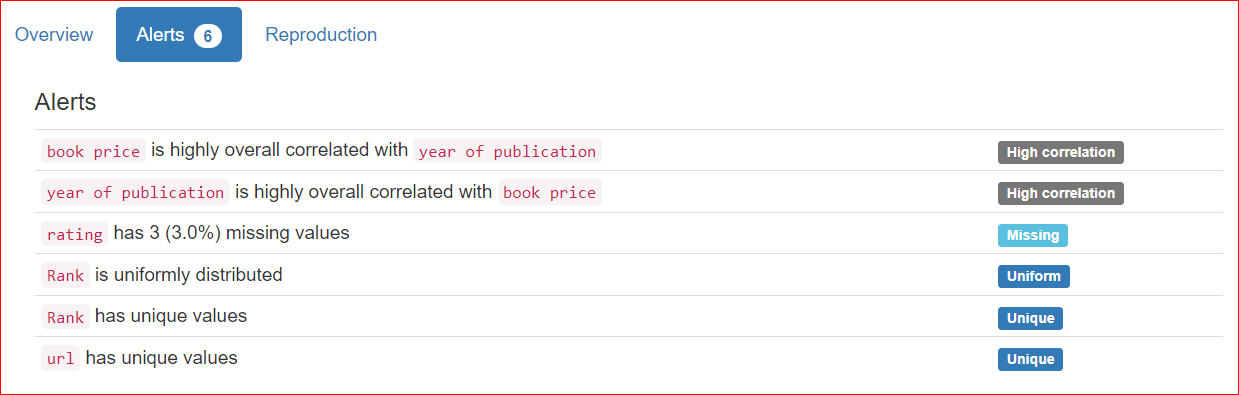
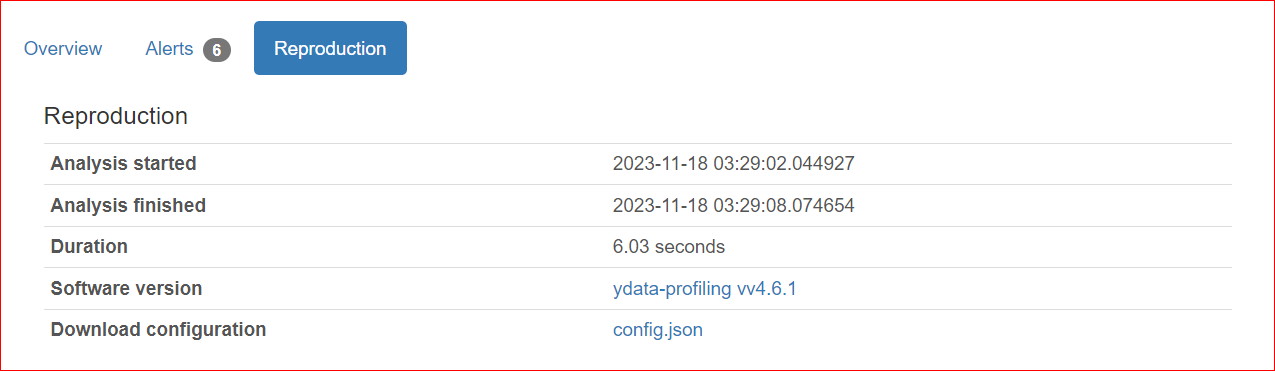
Reproduction sekmesi, analizin ne zaman başladığını ve ne zaman bittiğini gösterir. Analizin süresini ve kullandığınız yazılım sürümünü (benim durumda ydata-profiling v4.6.1) içerir.
Değişkenler bölümü, veri kümenizdeki tüm sütunları içerir. Aşağı açılır oku tıklayarak herhangi bir sütunu seçebilirsiniz.
rating sütununu seçtiğinizi varsayarsak, rapor bu sütunda 100 satıra dağılan 10 benzersiz değer bulunduğunu gösterir. Ayrıca üç hücrede hiç değer yoktur. Minimum değer 4,1, maksimum ise 5'tir. Tüm puanların ortalaması da görüntülenir.
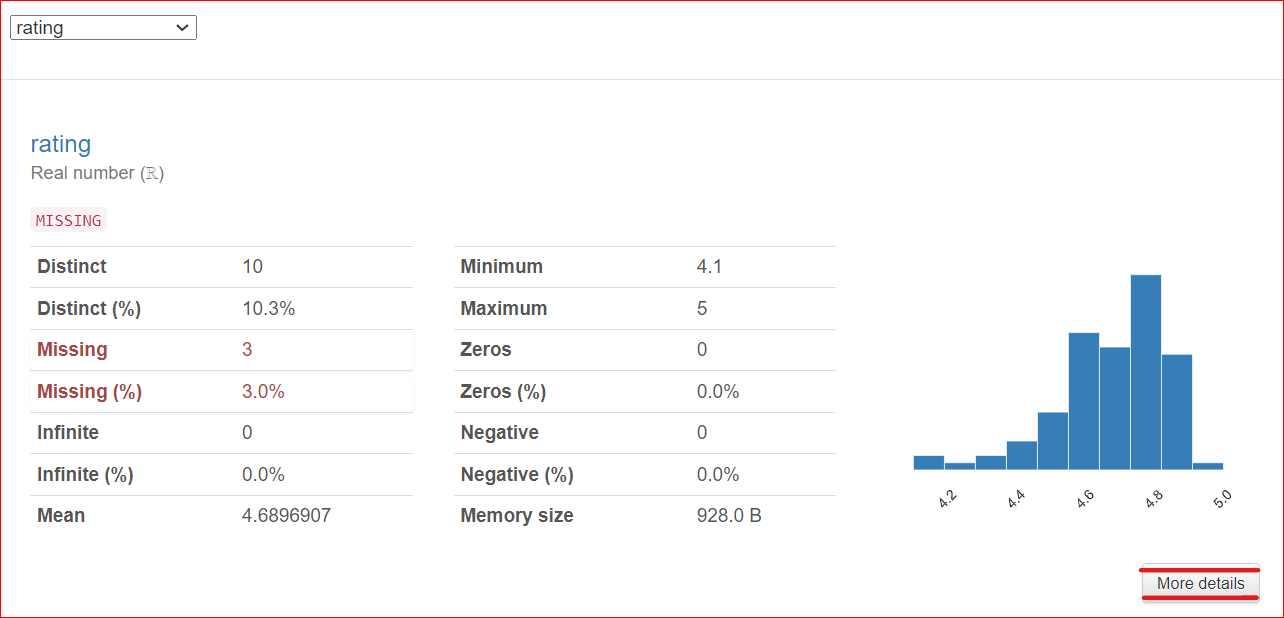
Önemli bir not: Sağ alt köşede bir Daha Fazla Ayrıntı düğmesi bulunur. Bu düğmeye tıklamak, medyan, standart sapma, varyasyon katsayısı ve sütunla ilişkili çeşitli diğer özellikler gibi rating sütunu hakkında daha fazla bilgiye erişmenizi sağlar.
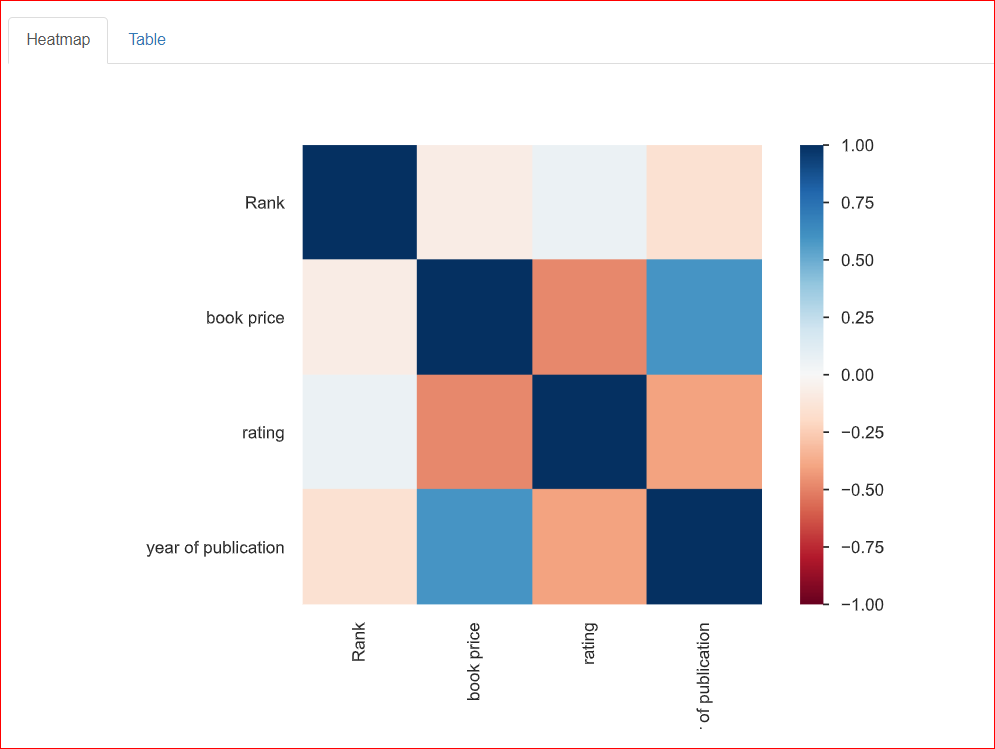
İki değişken arasındaki ilişkiyi, yani korelasyonu incelemeye yardımcı olur. Aşağıdaki ısı haritası, tüm değişkenlerin birbiriyle olan ilişkilerini gösterir. Rank, Rank ile %100 ilişkilidir ve bu nedenle sol üstteki koyu mavi kare ile temsil edilir.
Yayımlanma yılı, kitap fiyatıyla orta düzeyde ilişkilidir (yaklaşık 0,75); bu, tam olarak ilişkili olmadıklarından açık mavi renkle gösterilir. Örneğin, kitap fiyatı 20,93 ve yayımlanma yılı 2023 ise bu sayılar birbiriyle bir ölçüde ilişkilidir.
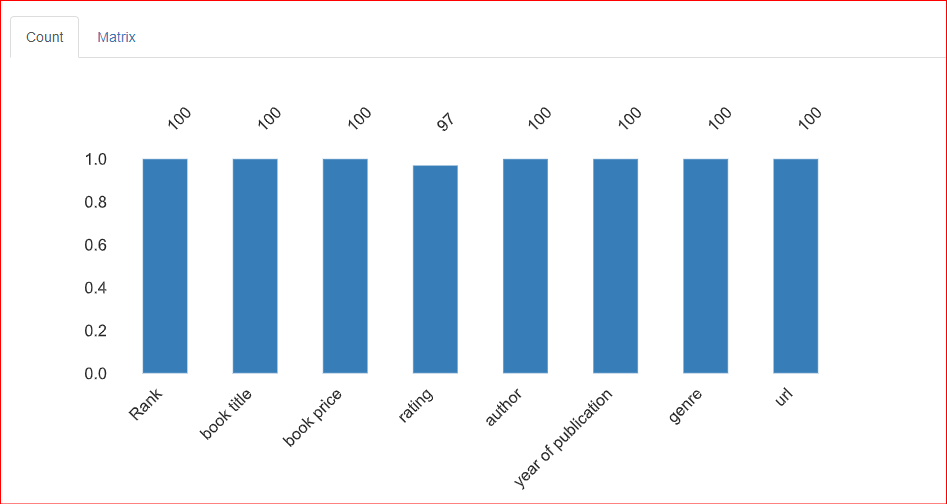
Bu bölüm, veri kümesindeki eksik değerler hakkında bilgi sağlar. Bu bölümün Count sekmesi, rating sütununda 3 eksik değer olduğunu belirtir.
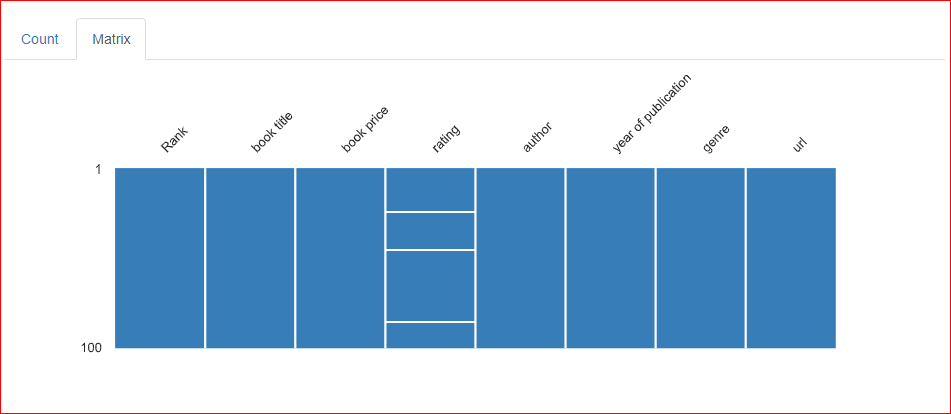
Eksik değerler bölümünün Matrix sekmesinde, Rating sütununda üç yatay çizgi bulunur; bu, sütunda üç değerin eksik olduğunu gösterir.
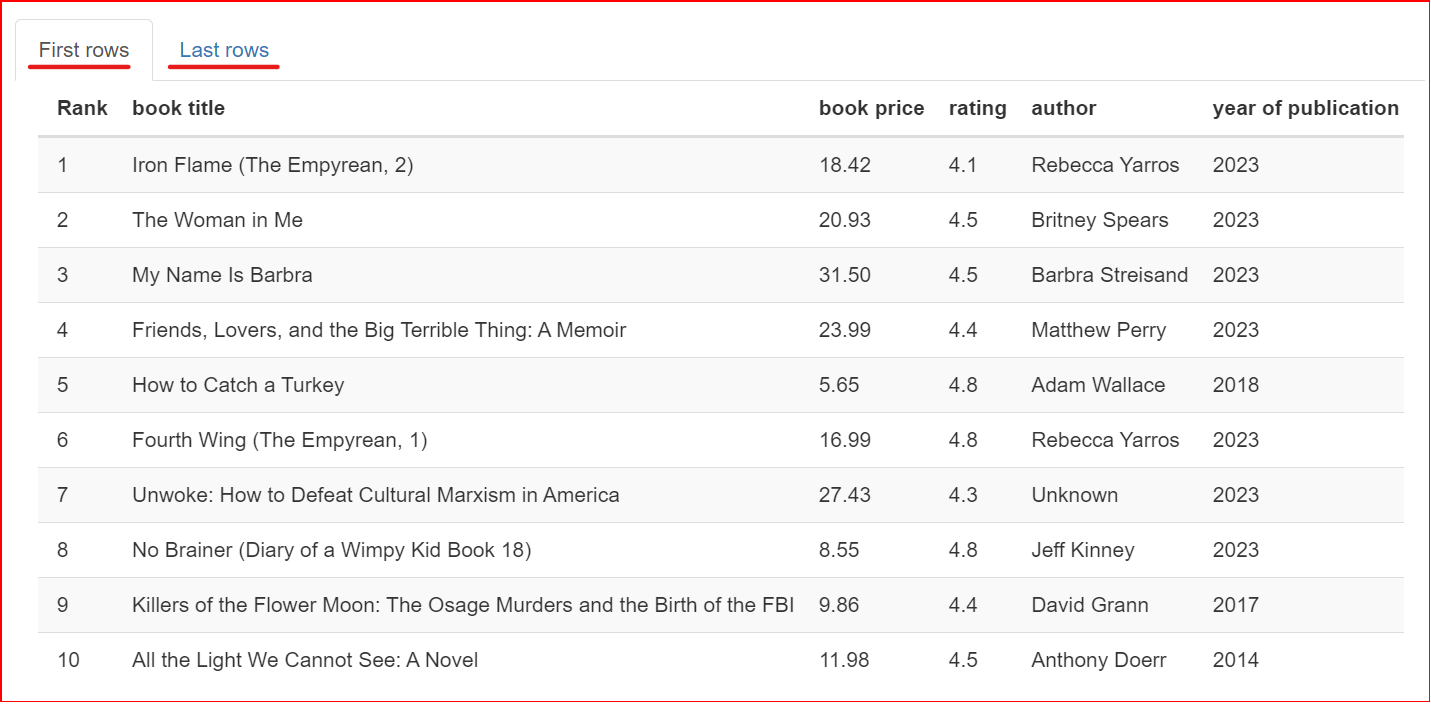
Bu bölüm veri kümesinden bir örnek içerir. Veri kümesinin ilk ve son 10 satırını görüntüler.
Profil raporunuz oluşturuldu ve bunu profil raporundan faydalı veriler çıkarmak veya diğer uygulamalarla entegre etmek gibi ileri kullanım için kaydetmek isteyebilirsiniz. Raporu HTML ve JSON formatlarında kaydedebilirsiniz. to_file() yöntemi raporu Jupyter Notebook dışında kaydedecektir.
İşte Pandas profiling için tam kod:
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Raporu oluştururken yalnızca CSV dosyasını iletiyoruz ve başka bir şey yapmıyoruz. Ek öğeler dahil etmiyoruz; işlemlerde yalnızca varsayılan değerler kullanılıyor.
Ancak, çıkarmak istediğiniz bölümler veya eklemek istediğiniz bilgiler olabilir. İşte Pandas Profiling'in ileri düzey kullanımları burada devreye girer. Varsayılan yapılandırmayı değiştirerek raporun çeşitli yönlerini kontrol edebilirsiniz.
Veri analizi ve görselleştirme araçları hakkında daha fazla bilgi edinmek istiyorsanız, 21 Temel Python Aracı yazımıza göz atın.
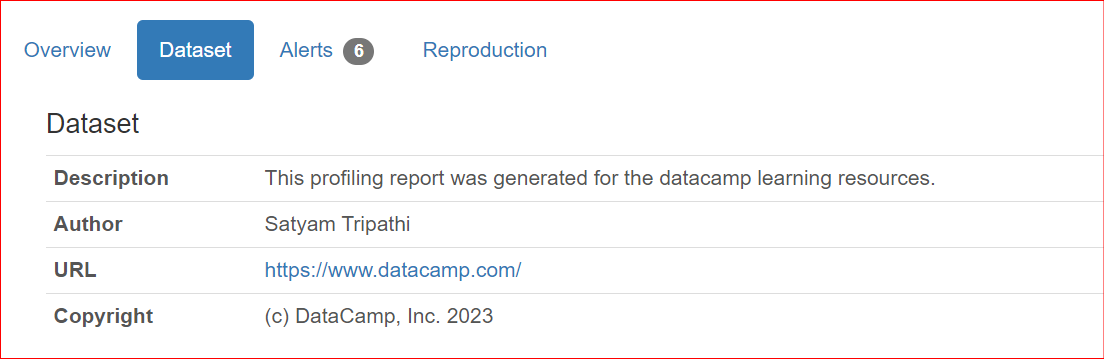
Raporları iş arkadaşlarınızla paylaşırken veya çevrimiçi yayımlarken, yazar, telif hakkı sahibi veya açıklamalar gibi veri kümesine ait üstverileri dahil etmek önemli olabilir. ydata-profiling, bir raporu bu bilgilerle zenginleştirmenize olanak tanır.
Şu anda desteklenen özellikler description, creator, author, url, copyright_year ve copyright_holder'dır. Varsayılan olarak, veri kümeleri raporun Overview bölümünde sunulur.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()İşte kod çıktısı:
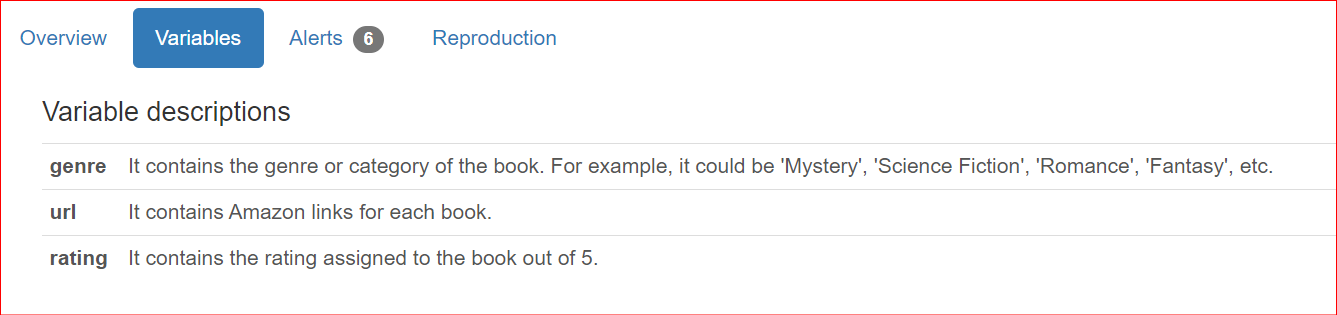
Veri kümesi ayrıntıları sunmanın yanı sıra, kullanıcılar raporları ekip üyeleri ve paydaşlarla paylaşırken sütunlara özel açıklamalar eklemek isteyebilir. Varsayılan olarak bu açıklamalar raporun Overview bölümünde sunulur.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()İşte kod çıktısı:
Varsayılan olarak, ydata-profiling veri analizine en fazla içgörü sağlamak için girdi veri kümesini kapsamlı biçimde özetler. Küçük veri kümeleri için bu hesaplamalar hızlıca yapılabilir. Ancak daha büyük veri kümelerinde aşırı ağır hale gelebilir.
ydata-profiling, en maliyetli hesaplamaların varsayılan olarak kapalı olduğu minimal bir yapılandırma dosyası içerir. Bu yapılandırma, korelasyonlar, etkileşimler vb. gibi zaman alan bölümleri dışlar.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling, büyük veri kümelerini ele alma zorluğunun üstesinden gelmek için çeşitli alternatifler de sunar. Onları buradan keşfedin.
Bu makalede, yalnızca birkaç satır kodla raporlar oluşturmaya yarayan, eskiden "Pandas Profiling" olarak bilinen ydata-profiling adlı benzersiz kütüphaneyi öğrendiniz. Profil raporunu nasıl oluşturacağınızı ve raporda yer alan tüm bölüm ve sekmeleri nasıl keşfedeceğinizi gördünüz. En önemlisi, veri bilimi yolculuğunuzda sizi bir adım öne taşıyacak bu kütüphanenin ileri düzey kullanımlarını öğrendiniz.
Pandas, verileri dönüştürmeden veri analizine kadar her şey için kullanılan, dünyanın en popüler Python kütüphanesidir. Gerçek dünyadaki veri kümelerini analiz için çıkarma, filtreleme ve dönüştürme sırasında DataFrame'leri nasıl işleyebileceğinizi öğrenmek için pandas ile Veri Manipülasyonu kursumuza göz atın.
Daha Fazla pandas Kullanımını Keşfedin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
