
Corso
Acquisizione dati semplificata con pandas
4 h
63.2K
Quando lavori con un dataset, ad esempio con 10.000 righe e 50 colonne, ottenere rapidamente una panoramica d’insieme può essere complicato. È qui che torna utile pandas Profiling. Semplifica il processo generando un report completo del tuo dataset, riducendo al minimo il tempo necessario per esplorare dataset di grandi dimensioni.
In questo articolo imparerai a iniziare con quello che un tempo era noto come pandas Profiling. Il nome del pacchetto pandas-profiling è stato recentemente cambiato in ydata-profiling. In questo tutorial vedrai come generare un report di profilazione a partire dal dataset, cosa contiene il report, come leggerlo e, infine, come salvarlo per usi futuri.
Pandas Profiling serve per generare un report completo ed esaustivo del dataset, con molte funzionalità e opzioni di personalizzazione nel report generato. Il report include varie informazioni come statistiche del dataset, distribuzione dei valori, valori mancanti, uso della memoria, ecc., molto utili per esplorare e analizzare i dati in modo efficiente.
Pandas Profiling è anche di grande aiuto nella Exploratory Data Analysis (EDA). L’EDA viene usata per comprendere la struttura sottostante dei dati, rilevare pattern e generare insight in formato visivo.
Per l’EDA, spesso dobbiamo scrivere molte righe di codice, talvolta complesse e dispendiose in termini di tempo, ma con Pandas Profiling si può automatizzare il tutto con poche righe di codice.
Se ti serve un ripasso sull’EDA, leggi Python Exploratory Data Analysis.
Ecco un esempio di report di profilazione:
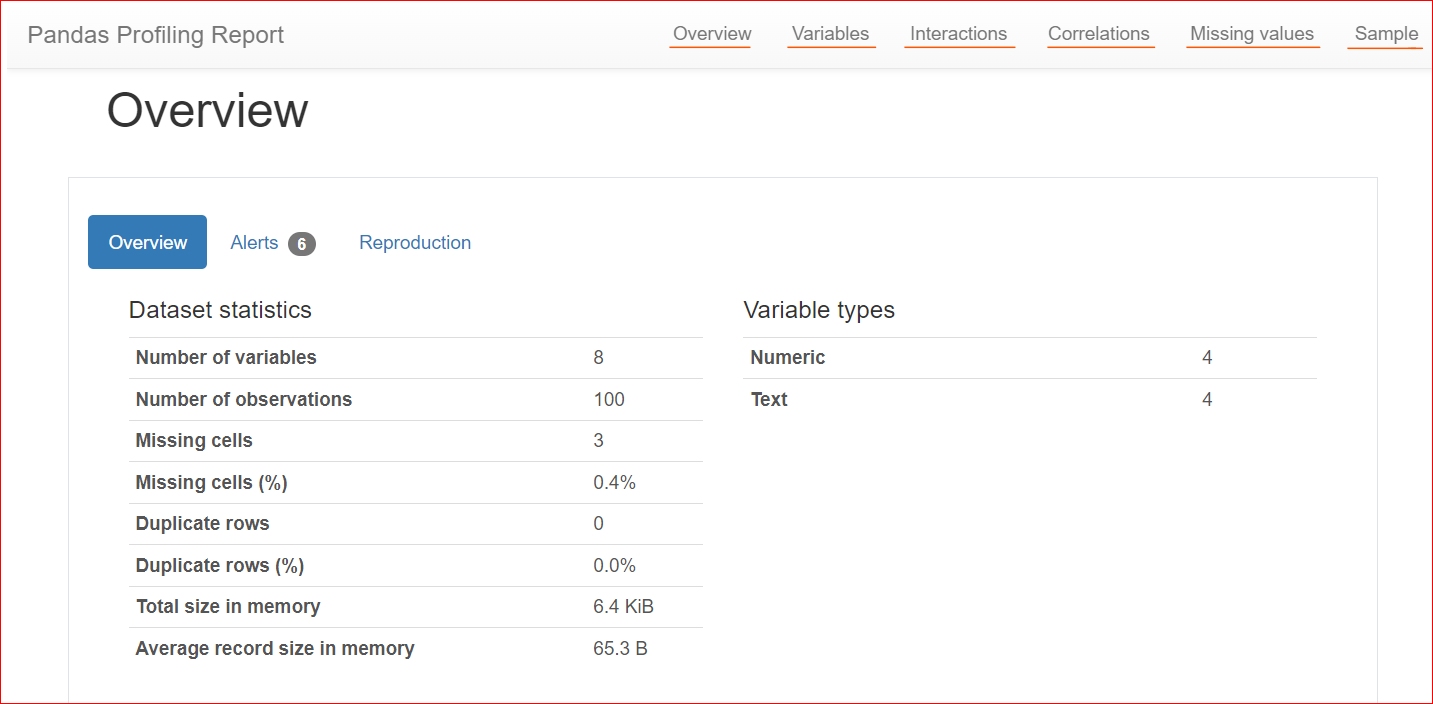
Immagine dell’autore
Pandas profiling è ampiamente usato nell’EDA per la sua facilità d’uso, l’efficienza in termini di tempo e i report HTML interattivi. Tuttavia, ci sono alcuni potenziali svantaggi nell’uso di pandas profiling con dataset di grandi dimensioni.
Per installare pandas Profiling puoi usare pip o conda, a seconda delle tue preferenze e dell’ambiente.
Con Pip:
Apri un prompt dei comandi o un terminale ed esegui il seguente comando:
pip install ydata-profilingCon Conda:
Apri l’Anaconda PowerShell Prompt ed esegui il seguente comando:
conda install -c conda-forge ydata-profilingDopo aver completato l’installazione, importa ydata-profiling con la seguente istruzione.
from ydata_profiling import ProfileReportQuesto importerà la classe ProfileReport dalla libreria ydata_profiling. Puoi usare questa classe per generare report di profilazione per i tuoi DataFrame.
Per generare un report di profilazione, segui questi passaggi:
ydata_profiling.ProfileReport() e passale il DataFrame.Ecco il codice essenziale che segue i passaggi sopra. Per prima cosa importiamo le librerie necessarie e poi leggiamo il file CSV con la funzione read_csv(). In questo caso, usiamo il file CSV delle Top 100 Bestselling Book Reviews. Successivamente, usiamo la classe ProfileReport e le passiamo il nostro DataFrame.
Inoltre, impostiamo un nuovo titolo, "Trending Books". Per impostazione predefinita il titolo è diverso, ma se vuoi personalizzarlo usa la variabile title all’interno della classe. Infine, per generare e mostrare il report, puoi usare profile oppure profile.to_notebook_iframe().
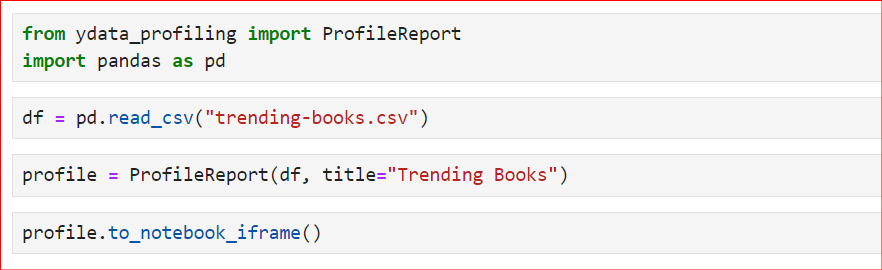
Il report verrà generato nel seguente ordine: prima verrà riassunto l’intero dataset. Poi verrà creata la struttura del report. Infine, verrà mostrato il report, che potrai salvare come file HTML e usare per ulteriori analisi.

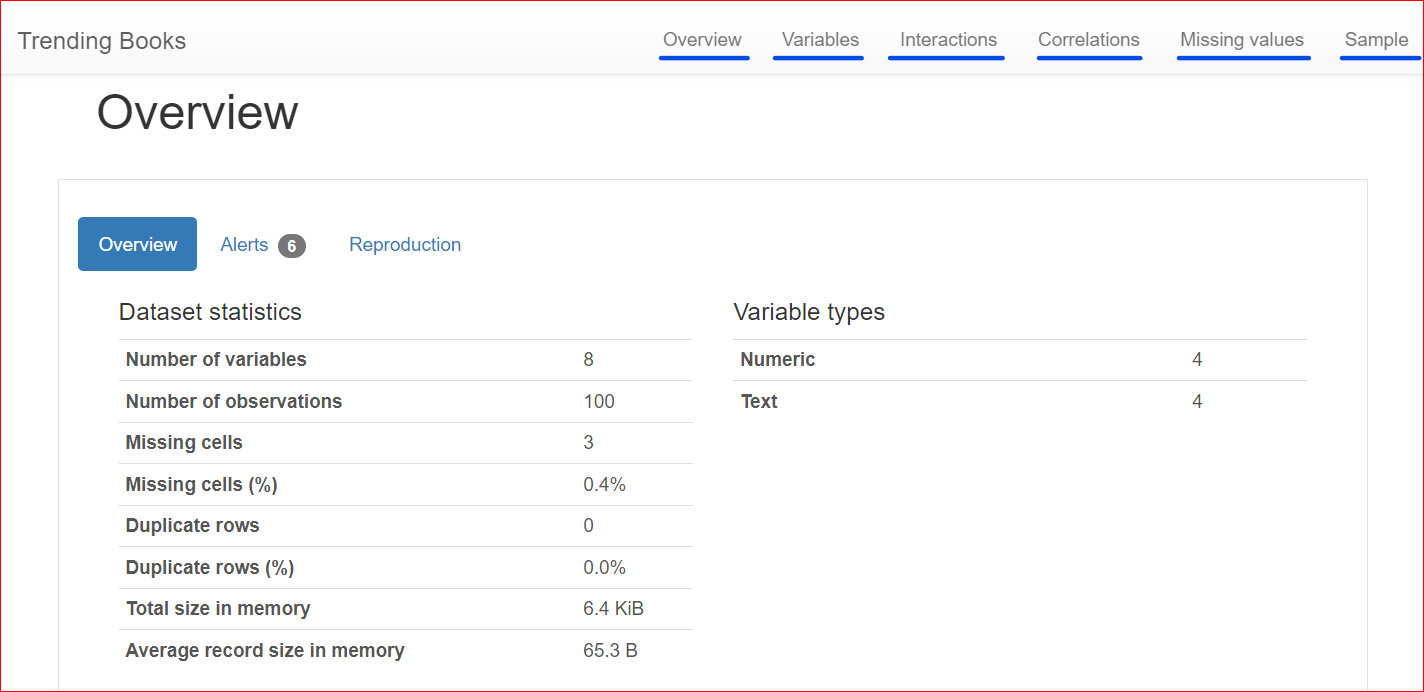
Ecco il report generato, che include diverse sezioni come Panoramica, Variabili, Interazioni, Correlazioni, Valori mancanti e Campione.
Se sei alle prime armi con l’EDA e, in particolare, con la profilazione dei dati, leggi Exploratory Data Analysis of Craft Beers: Data Profiling.
Il report è suddiviso in diverse sezioni: esploriamole una per una.
Questa sezione comprende 3 schede: Overview, Alerts e Reproduction.
La scheda Overview include statistiche sul dataset, come il numero di variabili (ovvero il numero di colonne diverse), il numero di celle con valori mancanti, le righe duplicate e la dimensione del dataset in memoria.
Nel nostro dataset ci sono in totale 8 variabili o colonne. Tra queste, quattro sono numeriche (posizione in classifica, prezzo del libro, valutazione e anno di pubblicazione), mentre le restanti quattro sono testuali (titolo del libro, autore, genere e URL). Non ci sono righe duplicate, come mostra il conteggio dei duplicati pari a 0. Inoltre, la colonna "rating" ha tre valori mancanti.
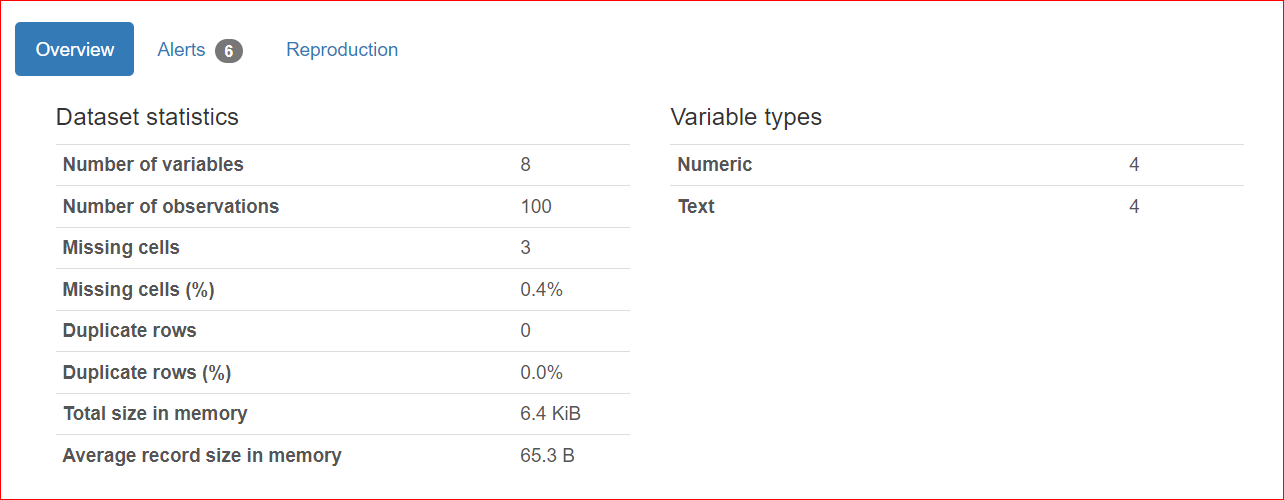
La scheda Alerts contiene avvisi relativi a correlazioni con altre variabili, valori mancanti, valori unici, zeri, ecc.
Nel nostro caso, le colonne URL e Rank hanno valori unici e la colonna rating ha tre valori mancanti.
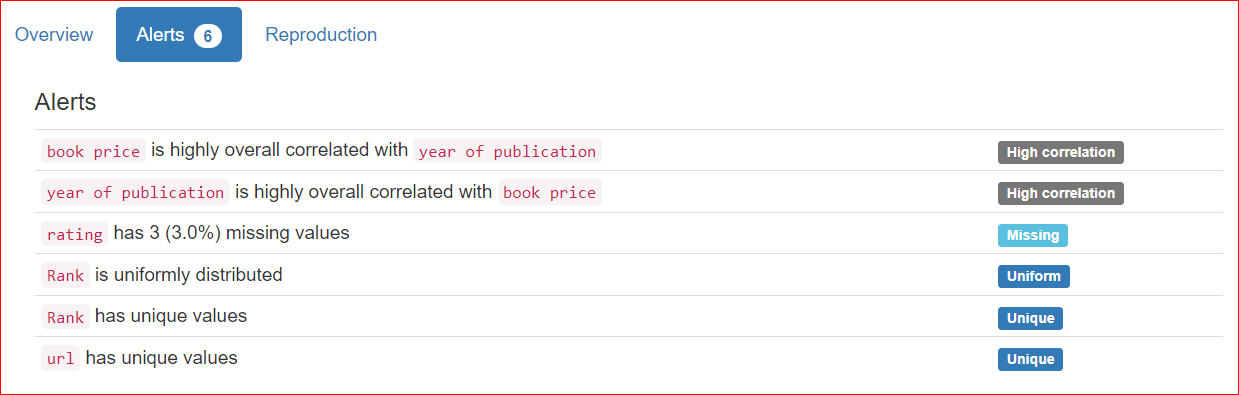
La scheda Reproduction mostra quando l’analisi è iniziata e quando è terminata. Visualizza la durata dell’analisi, inclusa la versione del software in uso (nel mio caso, ydata-profiling v4.6.1).
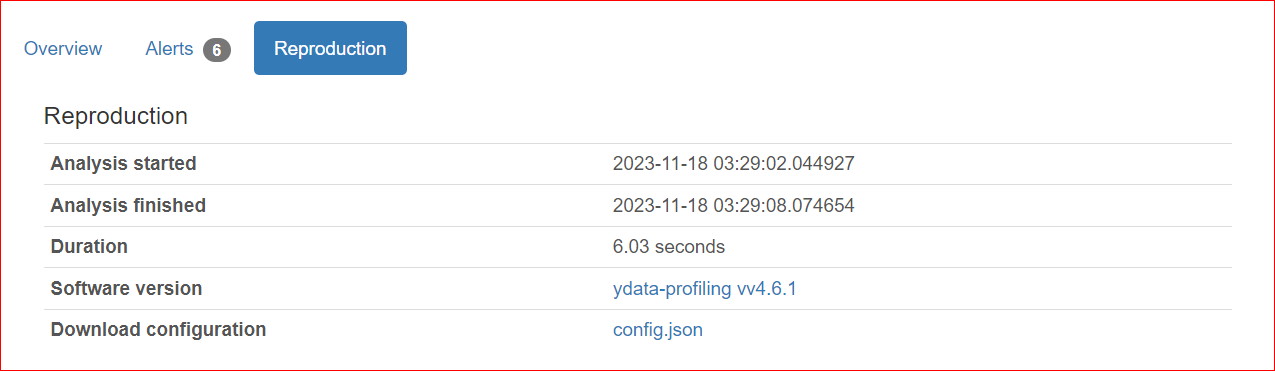
La sezione Variables include tutte le colonne del tuo dataset. Puoi fare clic sulla freccia di espansione e selezionare qualsiasi colonna.
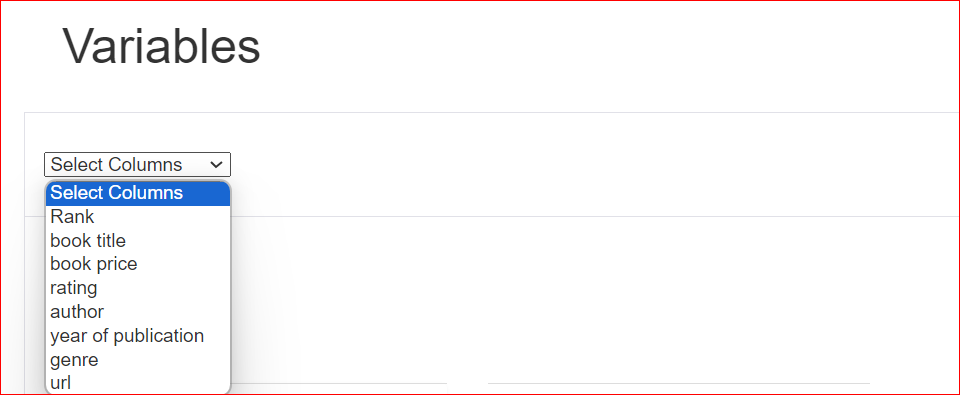
Selezionando la colonna rating, il report mostra che questa colonna contiene 10 valori unici distribuiti su 100 righe. Inoltre, tre celle non hanno alcun valore. Il valore minimo è 4,1, mentre il massimo è 5. Viene mostrata anche la media di tutte le valutazioni.
Nota importante: in basso a destra è presente un pulsante More Details. Facendo clic su questo pulsante accedi a ulteriori informazioni sulla colonna rating, come mediana, deviazione standard, coefficiente di variazione e varie altre caratteristiche associate alla colonna.
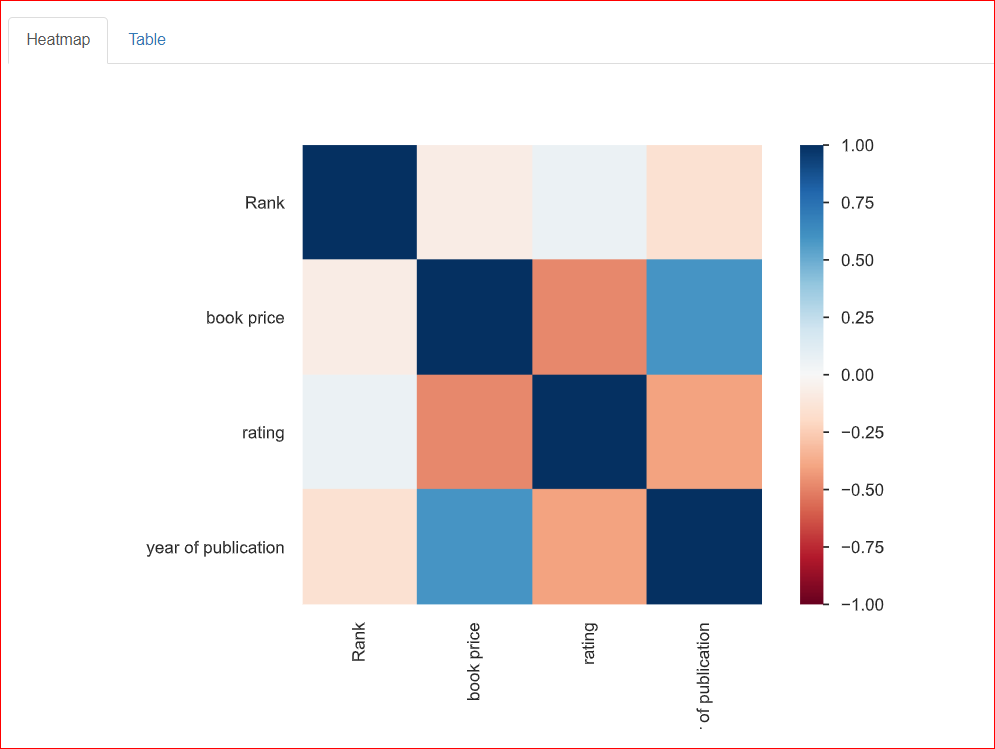
Questa sezione aiuta a studiare la relazione tra due variabili, ovvero la correlazione. La heatmap qui sotto mostra le relazioni tra tutte le variabili tra loro. Rank è correlato al 100% con Rank, motivo per cui è rappresentato dal quadrato blu scuro in alto a sinistra.
L’anno di pubblicazione è moderatamente correlato al prezzo del libro (circa 0,75), rappresentato dal colore azzurro perché non sono completamente correlati. Ad esempio, il prezzo del libro è 20,93 e l’anno di pubblicazione è 2023: questi numeri sono in qualche modo correlati tra loro.
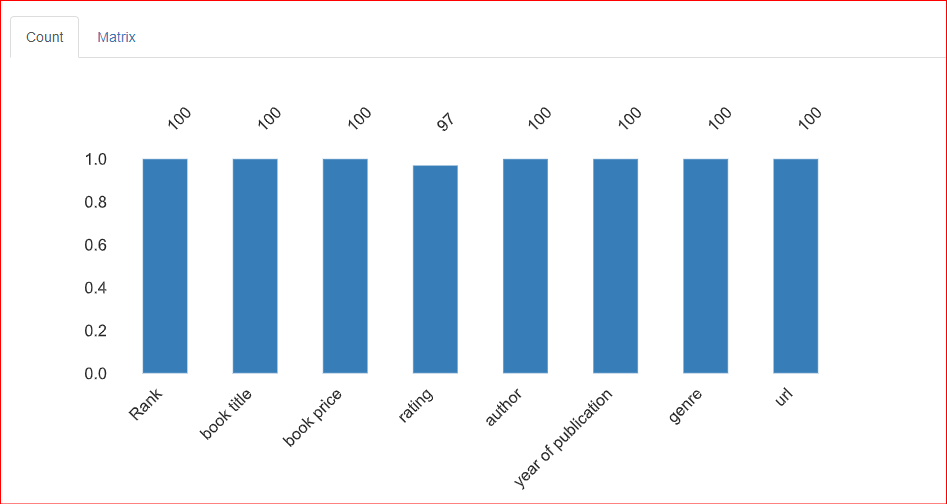
Questa sezione fornisce informazioni sui valori mancanti nel dataset. La scheda Count di questa sezione indica che ci sono 3 valori mancanti nella colonna rating.
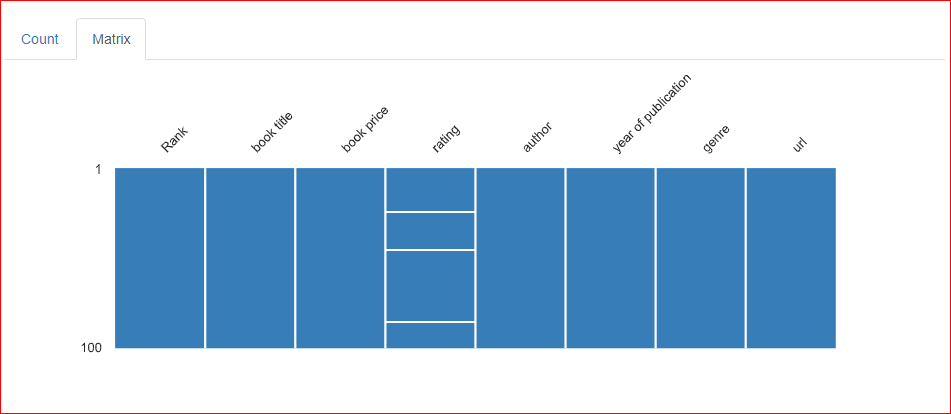
Nella scheda Matrix della sezione dei valori mancanti, sono presenti tre linee orizzontali nella colonna Rating, che indicano che nella colonna mancano tre valori.
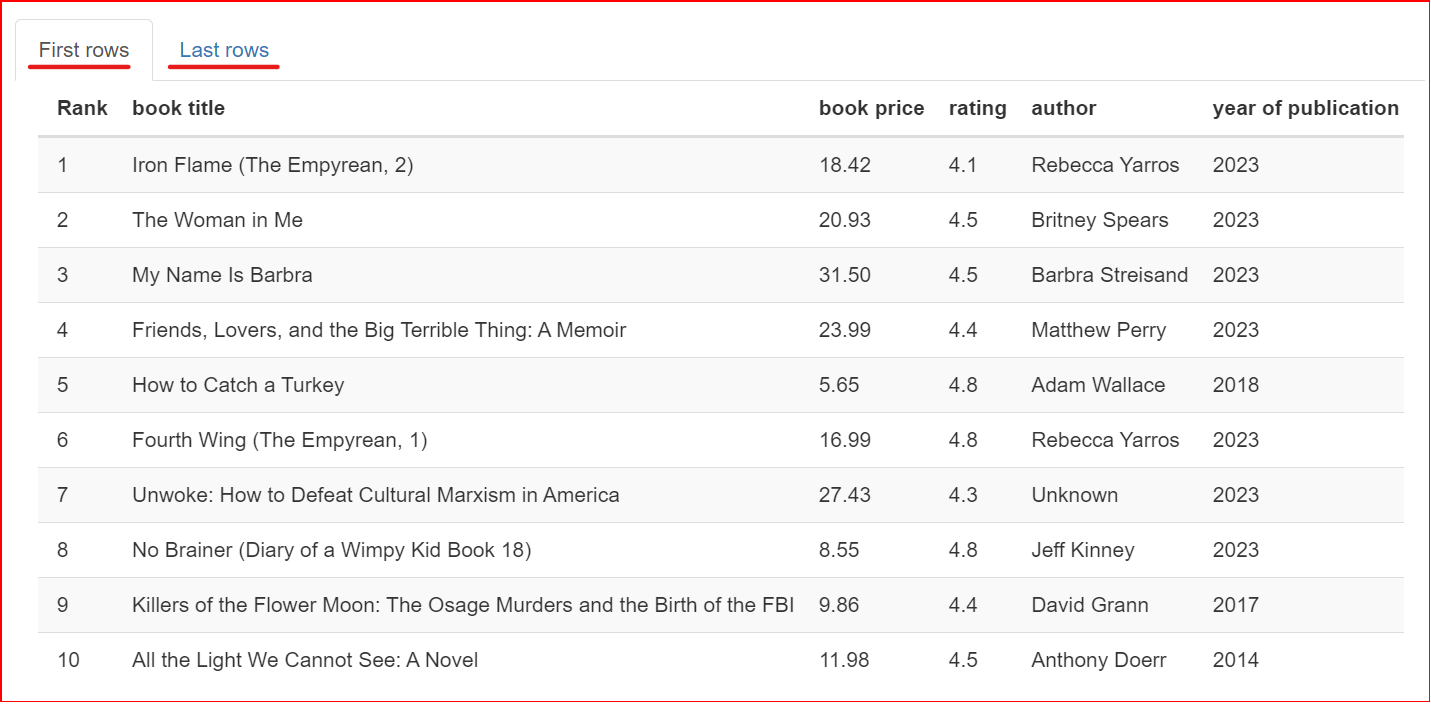
Questa sezione contiene un campione del dataset. Mostra le prime e le ultime 10 righe del dataset.
Il tuo report di profilazione è stato generato e potresti volerlo salvare per usi futuri, ad esempio per estrarre dati utili dal report o integrarlo con altre applicazioni. Puoi salvare il report in formato HTML e JSON. Il metodo to_file() salverà il report al di fuori di Jupyter Notebook.
Ecco il codice completo per il profiling con Pandas:
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Per generare il report, passiamo semplicemente il file CSV e nient’altro. Non includiamo elementi extra: nelle operazioni vengono usati solo i valori predefiniti.
Tuttavia, potrebbero esserci sezioni che vuoi omettere o informazioni aggiuntive che desideri includere. Qui entrano in gioco gli usi avanzati di Pandas Profiling. Puoi controllare vari aspetti del report modificando la configurazione predefinita.
Se ti interessa approfondire strumenti di analisi e visualizzazione dei dati, leggi 21 Essential Python Tools.
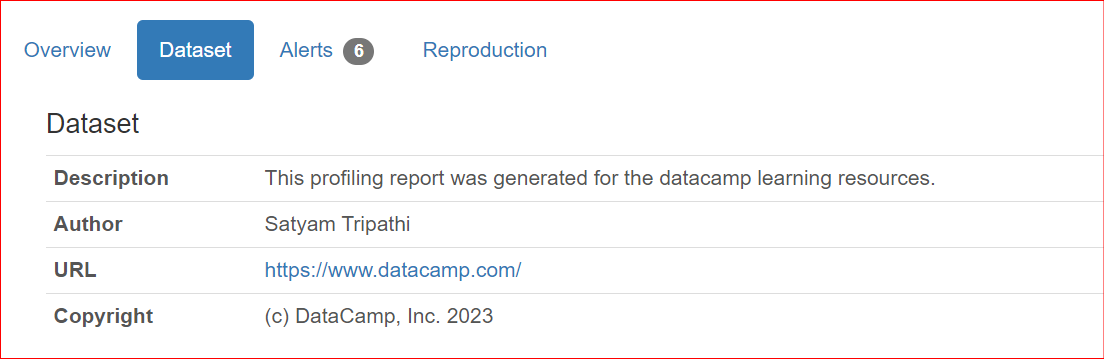
Quando condividi report con i colleghi o li pubblichi online, potrebbe essere importante includere i metadati del dataset, come autore, titolare del copyright o descrizioni. ydata-profiling permette di completare un report con queste informazioni.
Le proprietà attualmente supportate sono description, creator, author, url, copyright_year e copyright_holder. Per impostazione predefinita, i dataset sono presentati nella sezione Overview del report.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()Ecco l’output del codice:
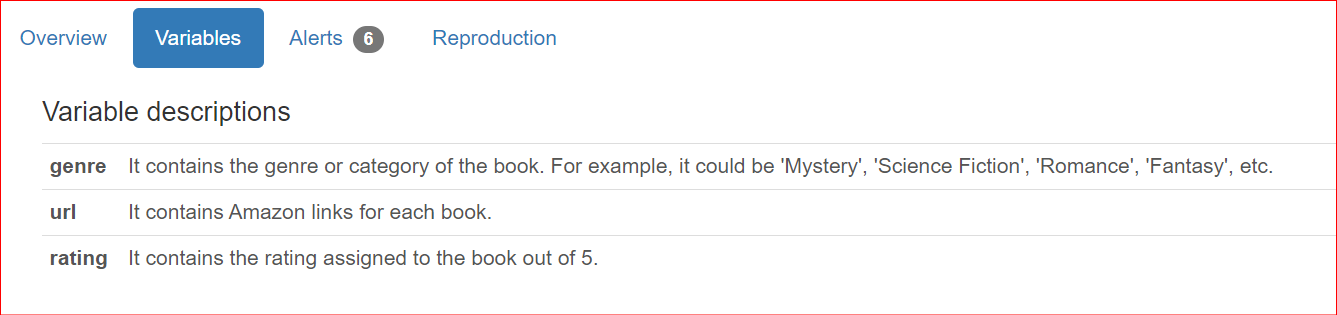
Oltre a fornire dettagli sul dataset, spesso si desidera includere descrizioni specifiche per colonna quando si condividono report con membri del team e stakeholder. Per impostazione predefinita, queste descrizioni sono presentate nella sezione Overview del report.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()Ecco l’output del codice:
Per impostazione predefinita, ydata-profiling riassume in modo completo il dataset in input per fornire il massimo degli insight per l’analisi dei dati. Per dataset piccoli, queste elaborazioni possono essere eseguite rapidamente. Tuttavia, per dataset più grandi, potrebbero diventare troppo pesanti.
ydata-profiling include un file di configurazione minimale in cui le elaborazioni più costose sono disattivate per impostazione predefinita. Questa configurazione esclude sezioni che richiedono molto tempo, come correlazioni, interazioni, ecc.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling offre anche diverse alternative per superare la sfida di gestire dataset di grandi dimensioni. Esplorale qui.
In questo articolo hai conosciuto l’utile libreria ydata-profiling, in precedenza chiamata "Pandas Profiling", per creare report con appena un paio di righe di codice. Hai visto come generare il report di profilazione ed esplorare tutte le sezioni e le schede presenti nel report. Soprattutto, hai imparato gli usi avanzati di questa libreria, che ti porteranno un passo avanti nel tuo percorso in data science.
Pandas è la libreria Python più popolare al mondo, usata per tutto, dalla manipolazione all’analisi dei dati. Per imparare a manipolare i DataFrame mentre estrai, filtri e trasformi dataset reali per l’analisi, dai un’occhiata al nostro corso Data Manipulation with pandas.
Scopri altri usi di pandas
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

