Kursus
Pengantar Python
4 Hr
6.9M
Bayangkan Anda memiliki masalah kompleks untuk dipecahkan, lalu Anda mengumpulkan sekelompok ahli dari berbagai bidang untuk memberikan masukan. Setiap ahli menyampaikan pendapat berdasarkan keahlian dan pengalamannya. Kemudian, para ahli tersebut memberikan suara untuk mencapai keputusan akhir.
Dalam klasifikasi random forest, beberapa decision tree dibuat menggunakan subset acak yang berbeda dari data dan fitur. Setiap decision tree seperti seorang ahli, yang memberikan pendapatnya tentang cara mengklasifikasikan data. Prediksi dilakukan dengan menghitung prediksi dari setiap decision tree lalu mengambil hasil yang paling populer. (Untuk regresi, prediksi menggunakan teknik perataan/averaging.)
Pada diagram di bawah, kita memiliki random forest dengan n decision tree, dan kami menampilkan 5 yang pertama beserta prediksinya (antara “Dog” atau “Cat”). Setiap tree terekspos pada jumlah fitur yang berbeda dan sampel dataset asli yang berbeda, sehingga setiap tree bisa berbeda. Masing-masing tree membuat prediksi.
Melihat 5 tree pertama, kita dapat melihat bahwa 4/5 memprediksi sampel tersebut adalah Cat. Lingkaran hijau menunjukkan jalur hipotetis yang diambil tree untuk mencapai keputusannya. Random forest akan menghitung jumlah prediksi dari decision tree untuk Cat dan untuk Dog, lalu memilih prediksi yang paling populer.
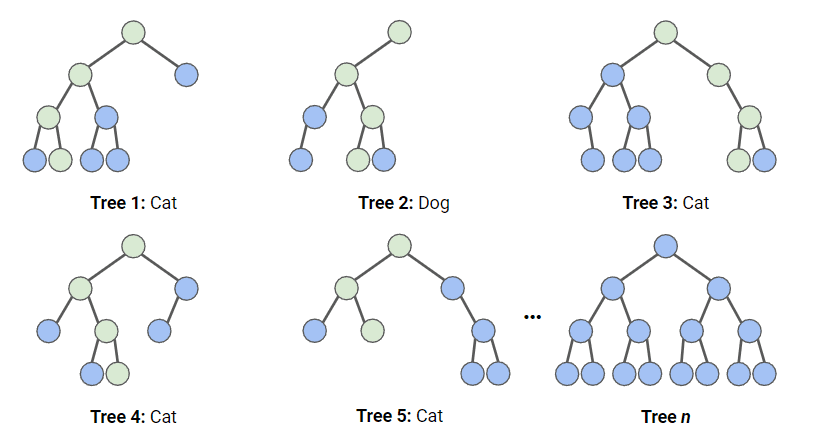 Ilustrasi cara kerja klasifikasi random forest. Gambar oleh Penulis
Ilustrasi cara kerja klasifikasi random forest. Gambar oleh Penulis
Dataset ini terdiri dari kampanye pemasaran langsung oleh sebuah institusi perbankan Portugal menggunakan panggilan telepon. Kampanye tersebut bertujuan menjual langganan deposito berjangka bank. Kita akan menyimpan dataset ini dalam variabel bernama bank_data. Kolom yang akan kita gunakan adalah:
age: Usia orang yang menerima panggilan telepon
default: Apakah orang tersebut memiliki kredit dalam status gagal bayar
cons.price.idx: Skor indeks harga konsumen pada saat panggilan
cons.conf.idx: Skor indeks kepercayaan konsumen pada saat panggilan
y: Apakah orang tersebut berlangganan (ini yang ingin kita prediksi)
Paket dan fungsi berikut digunakan dalam tutorial ini:
# Data Processing
import pandas as pd
import numpy as np
# Modelling
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, ConfusionMatrixDisplay
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from scipy.stats import randint
# Tree Visualisation
from sklearn.tree import export_graphviz
from IPython.display import Image
import graphvizUntuk melakukan fitting dan melatih model ini, kita akan mengikuti infografik The Machine Learning Workflow; namun, karena data kita cukup bersih, kita tidak akan menjalankan setiap langkah. Kita akan melakukan hal-hal berikut:
Model berbasis tree jauh lebih tangguh terhadap outlier dibandingkan model linear, dan tidak memerlukan normalisasi variabel agar dapat bekerja. Karena itu, kita hanya perlu sedikit prapemrosesan pada data kita.
Kita akan memetakan kolom default, yang berisi no dan yes, menjadi 0 dan 1. Untuk contoh ini, nilai unknown akan diperlakukan sebagai no.
Kita juga akan memetakan target kita, y, menjadi 1 dan 0.
bank_data['default'] = bank_data['default'].map({'no':0,'yes':1,'unknown':0})
bank_data['y'] = bank_data['y'].map({'no':0,'yes':1})Saat melatih model pembelajaran terawasi apa pun, penting untuk membagi data menjadi data latih dan data uji. Data latih digunakan untuk menyesuaikan model. Algoritma menggunakan data latih untuk mempelajari hubungan antara fitur dan target. Data uji digunakan untuk mengevaluasi kinerja model.
Kode di bawah ini membagi data menjadi variabel terpisah untuk fitur dan target, lalu membaginya menjadi data latih dan data uji.
# Split the data into features (X) and target (y)
X = bank_data.drop('y', axis=1)
y = bank_data['y']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)Pertama, kita membuat instance model Random Forest dengan parameter default. Lalu kita fit ke data latih. Kita meneruskan fitur dan variabel target agar model dapat belajar.
rf = RandomForestClassifier()
rf.fit(X_train, y_train)Pada tahap ini, kita memiliki model random forest terlatih, tetapi kita perlu mengetahui apakah model tersebut membuat prediksi yang akurat.
y_pred = rf.predict(X_test)Cara paling sederhana untuk mengevaluasi model ini adalah menggunakan akurasi; kita membandingkan prediksi dengan nilai aktual pada set uji dan menghitung berapa banyak yang benar.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Keluaran:
Accuracy: 0.888Ini skor yang cukup bagus! Namun, kita mungkin bisa mendapatkan hasil lebih baik dengan mengoptimalkan hyperparameter.
Catatan: Akurasi saja dapat menyesatkan pada data yang tidak seimbang. Selalu periksa precision dan recall untuk memahami trade-off false positive dan false negative.
Kita dapat menggunakan kode berikut untuk memvisualisasikan 3 tree pertama.
# Export the first three decision trees from the forest
for i in range(3):
tree = rf.estimators_[i]
dot_data = export_graphviz(tree,
feature_names=X_train.columns,
filled=True,
max_depth=2,
impurity=False,
proportion=True)
graph = graphviz.Source(dot_data)
display(graph)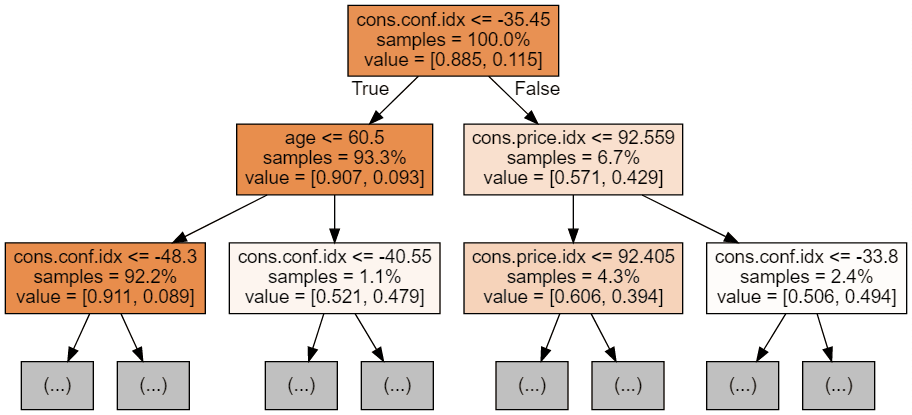
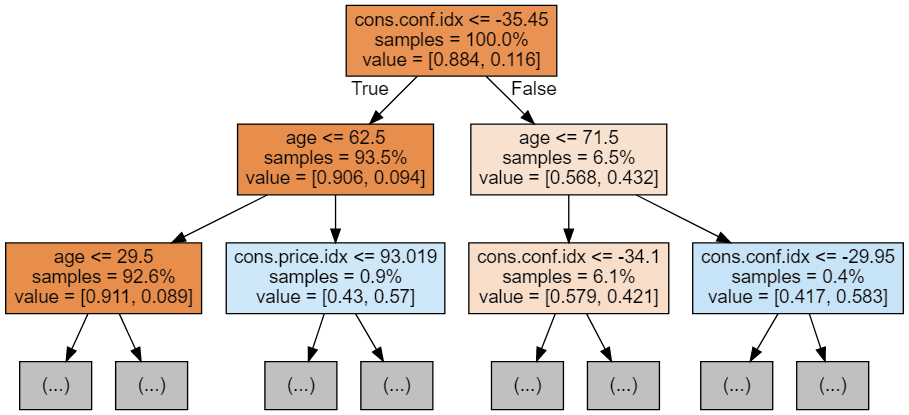
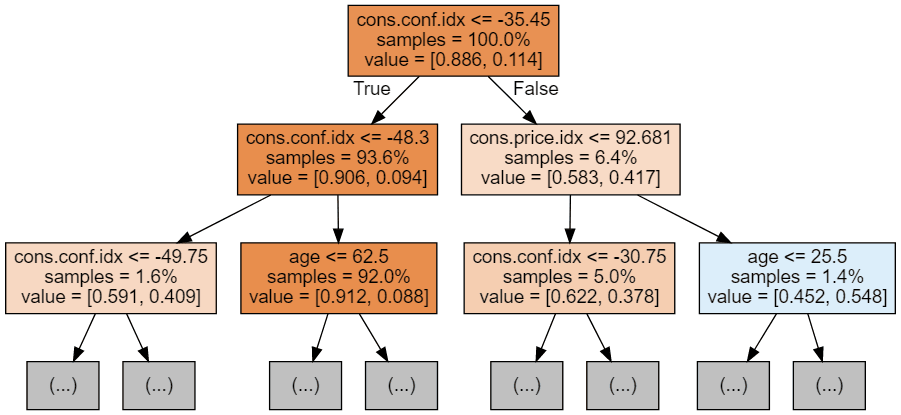
Setiap gambar tree dibatasi hanya menampilkan beberapa node pertama. Tree ini bisa menjadi sangat besar dan sulit divisualisasikan. Warna mewakili kelas mayoritas di setiap node (kotak), dengan merah menunjukkan mayoritas 0 (tidak berlangganan) dan biru menunjukkan mayoritas 1 (berlangganan). Warnanya semakin gelap semakin mendekati node sepenuhnya 0 atau 1. Setiap node juga memuat informasi berikut:
Kode di bawah menggunakan RandomizedSearchCV dari Scikit-Learn, yang akan secara acak mencari parameter dalam suatu rentang per hyperparameter. Kita mendefinisikan hyperparameter yang digunakan dan rentangnya dalam dictionary param_dist. Dalam kasus kita, yang digunakan adalah:
n_estimators: jumlah decision tree dalam forest. Meningkatkan hyperparameter ini umumnya memperbaiki kinerja model tetapi juga meningkatkan biaya komputasi pelatihan dan prediksi.
max_depth: kedalaman maksimum setiap decision tree dalam forest. Menetapkan nilai max_depth yang lebih tinggi dapat menyebabkan overfitting, sementara menetapkannya terlalu rendah dapat menyebabkan underfitting.
param_dist = {
'n_estimators': randint(100, 500),
'max_depth': randint(3, 15),
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 5)
}
# Create a random forest classifier
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
# Use random search to find the best hyperparameters
rand_search = RandomizedSearchCV(
rf, param_distributions=param_dist,
n_iter=10, cv=5, scoring='accuracy',
n_jobs=-1, random_state=42
RandomizedSearchCV akan melatih banyak model (ditentukan oleh n_iter_) dan menyimpan masing-masing sebagai variabel. Kode di bawah membuat variabel untuk model terbaik dan mencetak hyperparameter-nya.
Dalam kasus ini, kita belum meneruskan sistem penilaian ke fungsi, sehingga default-nya adalah akurasi. Fungsi ini juga menggunakan cross-validation, yang berarti membagi data menjadi lima kelompok berukuran sama dan menggunakan 4 kelompok untuk melatih dan 1 untuk menguji hasil. Ia akan berulang melalui setiap kelompok dan memberikan skor akurasi, yang dirata-ratakan untuk menemukan model terbaik.
# Create a variable for the best model
best_rf = rand_search.best_estimator_
# Print the best hyperparameters
print('Best hyperparameters:', rand_search.best_params_)Keluaran:
Best hyperparameters: {'max_depth': 5, 'n_estimators': 260}Mari lihat confusion matrix. Ini memplot apa yang diprediksi model terhadap prediksi yang benar. Kita dapat menggunakannya untuk memahami trade-off antara false positive (kanan atas) dan false negative (kiri bawah). Kita dapat memplot confusion matrix menggunakan kode ini:
# Generate predictions with the best model
y_pred = best_rf.predict(X_test)
# Create the confusion matrix
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(confusion_matrix=cm).plot();Keluaran:
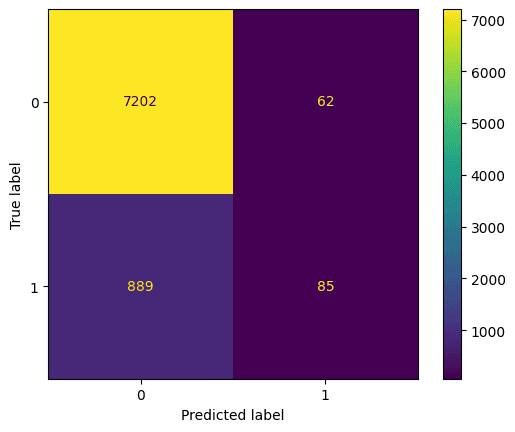
Evaluasi classifier random forest menggunakan confusion matrix. Gambar oleh Penulis
Kita juga harus mengevaluasi model terbaik dengan akurasi, precision, dan recall (catatan: hasil Anda mungkin berbeda karena proses acak)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Keluaran:
Accuracy: 0.885
Precision: 0.578
Recall: 0.0873Kode di bawah memplot tingkat kepentingan setiap fitur, menggunakan skor internal model untuk menemukan cara terbaik membagi data dalam setiap decision tree.
# Create a series containing feature importances from the model and feature names from the training data
importances = pd.Series(best_rf.feature_importances_, index=X_train.columns)
importances.sort_values(ascending=False).plot.bar()
Ini menunjukkan bahwa indeks kepercayaan konsumen pada saat panggilan merupakan prediktor terbesar apakah seseorang akan berlangganan.
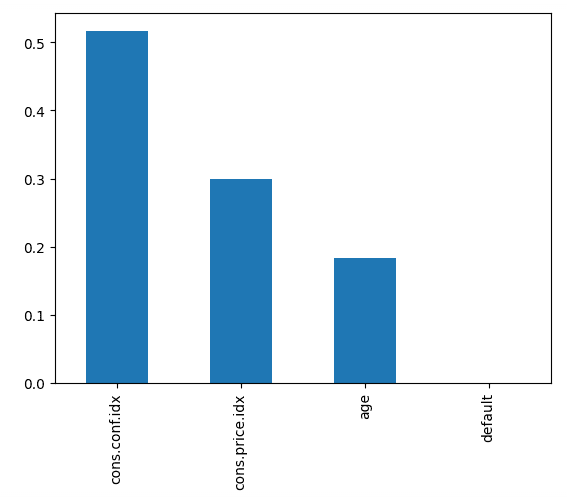
Fitur-fitur classifier random forest berdasarkan urutan kepentingan. Gambar oleh Penulis
Random Forest adalah pilihan tepat saat Anda memerlukan model baseline yang kuat yang bekerja baik tanpa banyak penyesuaian. Model ini menangani fitur numerik dan kategorikal, mengelola nilai hilang dengan baik, dan kurang rentan terhadap overfitting dibandingkan single decision tree.
Gunakan Random Forest ketika:
Namun, Random Forest mungkin kurang ideal ketika:
Untuk memulai pembelajaran terawasi di Python, ikuti Supervised Learning with scikit-learn. Untuk mempelajari lebih lanjut tentang penggunaan random forest dan model machine learning berbasis tree lainnya, lihat kursus Machine Learning with Tree-Based Models in Python dan Ensemble Methods in Python.
Kursus Python
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
