Kurs
Einführung in Python
4 Std.
6.9M
Stell dir vor, du hast ein komplexes Problem zu lösen und versammelst eine Gruppe von Experten aus verschiedenen Bereichen, um ihren Beitrag zu leisten. Jeder Experte gibt seine Meinung auf der Grundlage seines Fachwissens und seiner Erfahrung ab. Dann würden die Experten abstimmen, um eine endgültige Entscheidung zu treffen.
Bei einer Random-Forest-Klassifizierung werden mehrere Entscheidungsbäume mit verschiedenen zufälligen Teilmengen der Daten und Merkmale erstellt. Jeder Entscheidungsbaum ist wie ein Experte, der seine Meinung dazu abgibt, wie die Daten zu klassifizieren sind. Die Vorhersagen werden erstellt, indem die Vorhersage für jeden Entscheidungsbaum berechnet wird und dann das beliebteste Ergebnis genommen wird. (Bei Regressionsvorhersagen wird stattdessen eine Mittelwertbildung verwendet.)
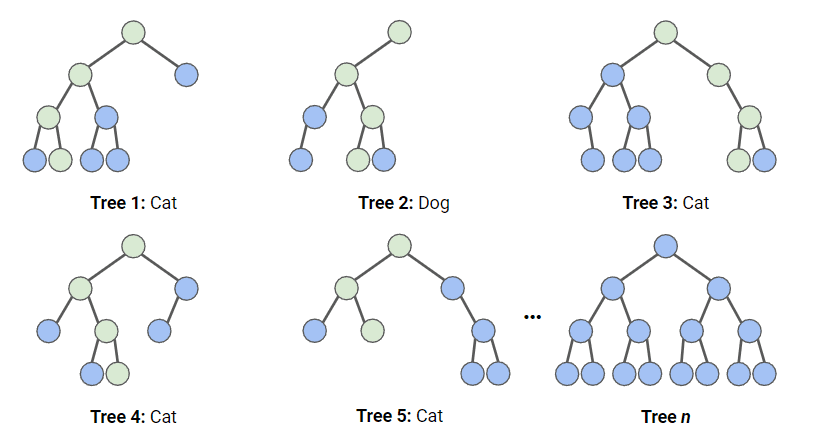
Im folgenden Diagramm haben wir einen Zufallsforst mit n Entscheidungsbäumen, von denen wir die ersten 5 zusammen mit ihren Vorhersagen (entweder "Hund" oder "Katze") dargestellt haben. Jeder Baum wird mit einer anderen Anzahl von Merkmalen und einer anderen Stichprobe des Originaldatensatzes konfrontiert, so dass jeder Baum anders sein kann. Jeder Baum macht eine Vorhersage. Wenn wir uns die ersten 5 Bäume ansehen, können wir feststellen, dass 4/5 der Stichprobe eine Katze war. Die grünen Kreise zeigen einen hypothetischen Weg, den der Baum genommen hat, um zu seiner Entscheidung zu kommen. Der Random Forest würde die Anzahl der Vorhersagen der Entscheidungsbäume für Katze und Hund zählen und die beliebteste Vorhersage auswählen.
Dieser Datensatz besteht aus Direktmarketingkampagnen eines portugiesischen Bankinstituts, bei denen Telefonanrufe verwendet werden. Die Kampagnen zielten darauf ab, Abonnements für eine Festgeldanlage bei einer Bank zu verkaufen. Wir werden diesen Datensatz in einer Variablen namens bank_data speichern.
Die Spalten, die wir verwenden werden, sind:
age: Das Alter der Person, die den Anruf erhalten hatdefault: Ob die Person einen säumigen Kredit hatcons.price.idx: Wert des Verbraucherpreisindex zum Zeitpunkt des Anrufscons.conf.idx:Index des Verbrauchervertrauens zum Zeitpunkt des Anrufsy: Ob die Person ein Abonnement abgeschlossen hat (das ist es, was wir vorhersagen wollen)Die folgenden Pakete und Funktionen werden in diesem Lernprogramm verwendet:
# Data Processing
import pandas as pd
import numpy as np
# Modelling
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, ConfusionMatrixDisplay
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from scipy.stats import randint
# Tree Visualisation
from sklearn.tree import export_graphviz
from IPython.display import Image
import graphvizUm dieses Modell anzupassen und zu trainieren, folgen wir der Infografik "The Machine Learning Workflow". Da unsere Daten jedoch ziemlich sauber sind, werden wir nicht jeden Schritt ausführen. Wir werden Folgendes tun:
Baumbasierte Modelle sind viel robuster gegenüber Ausreißern als lineare Modelle, und die Variablen müssen nicht normalisiert werden, damit sie funktionieren. Daher müssen wir unsere Daten nur sehr wenig vorverarbeiten.
no und yes enthält, auf 0s bzw. 1s abbilden. Für dieses Beispiel werden wir die Werte von unknown als no behandeln.y, auch auf 1s und 0s abbilden.bank_data['default'] = bank_data['default'].map({'no':0,'yes':1,'unknown':0})
bank_data['y'] = bank_data['y'].map({'no':0,'yes':1})Beim Training eines überwachten Lernmodells ist es wichtig, die Daten in Trainings- und Testdaten aufzuteilen. Die Trainingsdaten werden verwendet, um das Modell anzupassen. Der Algorithmus nutzt die Trainingsdaten, um die Beziehung zwischen den Merkmalen und dem Ziel zu lernen. Die Testdaten werden verwendet, um die Leistung des Modells zu bewerten.
Der folgende Code teilt die Daten in separate Variablen für die Merkmale und das Ziel auf und unterteilt sie dann in Trainings- und Testdaten.
# Split the data into features (X) and target (y)
X = bank_data.drop('y', axis=1)
y = bank_data['y']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Zuerst erstellen wir eine Instanz des Random Forest-Modells mit den Standardparametern. Dann passen wir sie an unsere Trainingsdaten an. Wir übergeben sowohl die Merkmale als auch die Zielvariable, damit das Modell lernen kann.
rf = RandomForestClassifier()
rf.fit(X_train, y_train)Jetzt haben wir ein trainiertes Random Forest-Modell, aber wir müssen herausfinden, ob es genaue Vorhersagen macht.
y_pred = rf.predict(X_test)Die einfachste Art, dieses Modell zu bewerten, ist die Genauigkeit: Wir vergleichen die Vorhersagen mit den tatsächlichen Werten in der Testmenge und zählen, wie viele das Modell richtig lag.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Output:
Accuracy: 0.888Das ist ein ziemlich gutes Ergebnis! Vielleicht können wir aber noch mehr erreichen, wenn wir unsere Hyperparameter optimieren.
Wir können den folgenden Code verwenden, um unsere ersten 3 Bäume zu visualisieren.
# Export the first three decision trees from the forest
for i in range(3):
tree = rf.estimators_[i]
dot_data = export_graphviz(tree,
feature_names=X_train.columns,
filled=True,
max_depth=2,
impurity=False,
proportion=True)
graph = graphviz.Source(dot_data)
display(graph)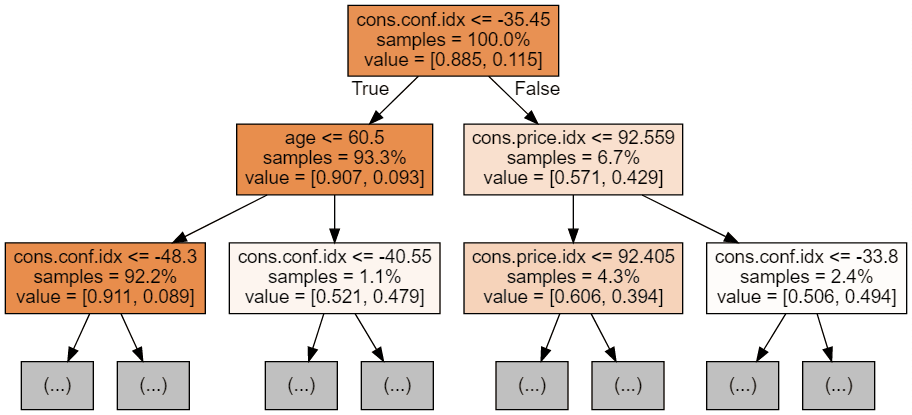
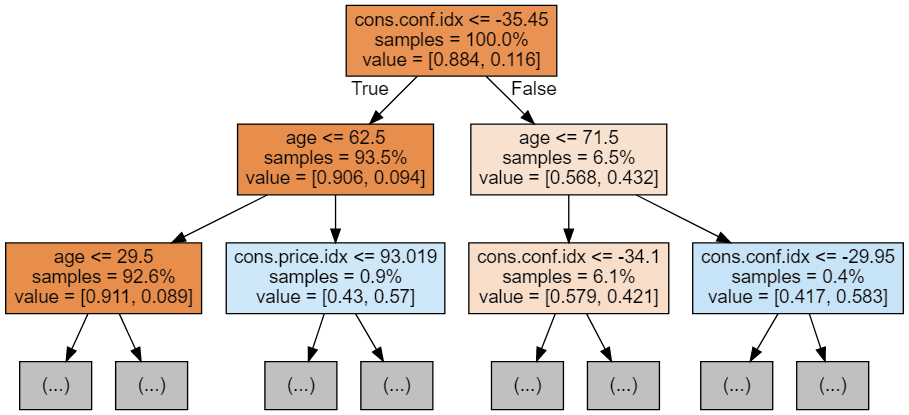
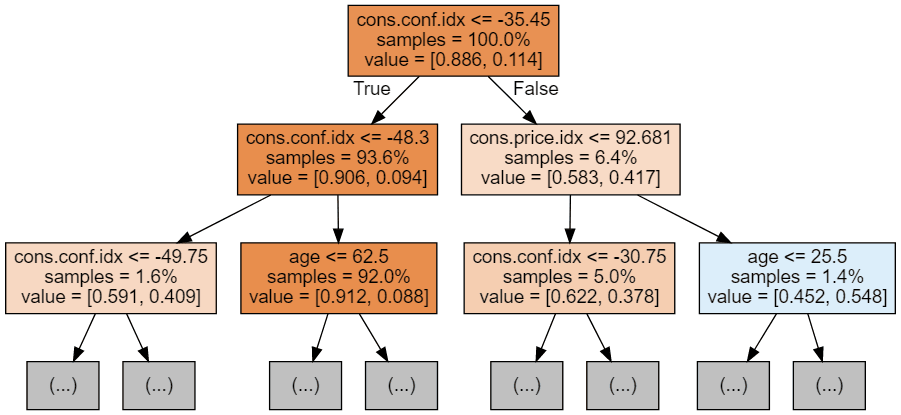
Jedes Baumbild beschränkt sich darauf, nur die ersten paar Knoten zu zeigen. Diese Bäume können sehr groß und schwer zu visualisieren sein. Die Farben stehen für die Mehrheitsklasse jedes Knotens (Box), wobei Rot die Mehrheit 0 (kein Abonnement) und Blau die Mehrheit 1 (Abonnement) anzeigt. Die Farben werden dunkler, je näher der Knoten an 0 oder 1 ist. Jeder Knoten enthält außerdem die folgenden Informationen:
Der folgende Code verwendet Scikit-Learn's RandomizedSearchCV, das zufällig nach Parametern innerhalb eines Bereichs pro Hyperparameter sucht. Wir definieren die zu verwendenden Hyperparameter und ihre Bereiche im Wörterbuch param_dist. In unserem Fall verwenden wir:
param_dist = {'n_estimators': randint(50,500),
'max_depth': randint(1,20)}
# Create a random forest classifier
rf = RandomForestClassifier()
# Use random search to find the best hyperparameters
rand_search = RandomizedSearchCV(rf,
param_distributions = param_dist,
n_iter=5,
cv=5)
# Fit the random search object to the data
rand_search.fit(X_train, y_train)RandomizedSearchCV viele Modelle trainiert (definiert durch n_iter_ und jedes als Variable speichert, erstellt der folgende Code eine Variable für das beste Modell und gibt die Hyperparameter aus. In diesem Fall haben wir der Funktion kein Bewertungssystem übergeben, also ist sie standardmäßig auf Genauigkeit eingestellt. Diese Funktion verwendet ebenfalls eine Kreuzvalidierung, d.h. sie teilt die Daten in fünf gleich große Gruppen auf und verwendet 4 zum Trainieren und 1 zum Testen des Ergebnisses. Es geht in einer Schleife durch jede Gruppe und gibt eine Trefferquote an, die gemittelt wird, um das beste Modell zu finden.
# Create a variable for the best model
best_rf = rand_search.best_estimator_
# Print the best hyperparameters
print('Best hyperparameters:', rand_search.best_params_)Output:
Best hyperparameters: {'max_depth': 5, 'n_estimators': 260}Schauen wir uns die Verwirrungsmatrix an. Hier wird dargestellt, was das Modell vorhergesagt hat und was die richtige Vorhersage war. Wir können dies nutzen, um den Kompromiss zwischen falsch-positiven (oben rechts) und falsch-negativen (unten links) Ergebnissen zu verstehen:
# Generate predictions with the best model
y_pred = best_rf.predict(X_test)
# Create the confusion matrix
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(confusion_matrix=cm).plot();Output:
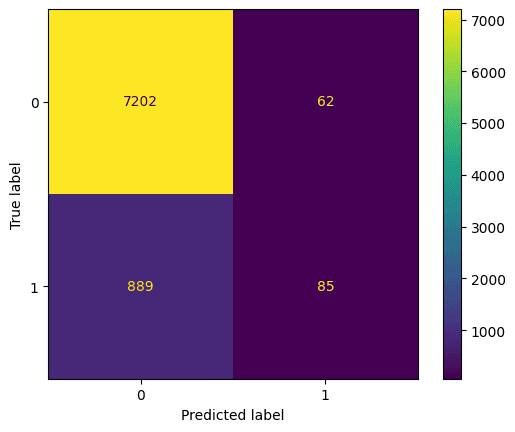
Wir sollten das beste Modell auch nach Genauigkeit, Präzision und Wiedererkennung bewerten (beachte, dass deine Ergebnisse aufgrund der Randomisierung abweichen können).
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Output:
Accuracy: 0.885
Precision: 0.578
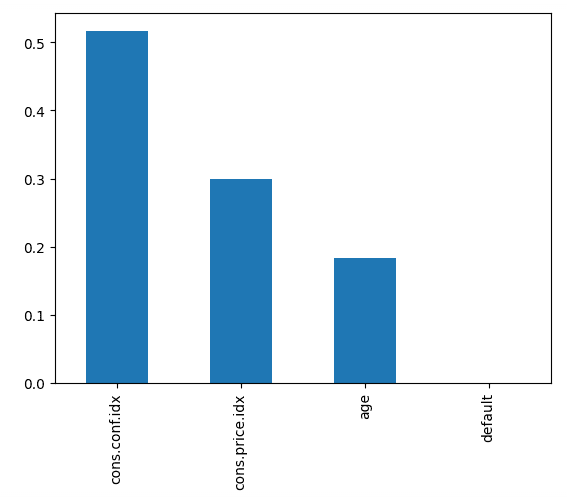
Recall: 0.0873Der folgende Code stellt die Wichtigkeit jedes Merkmals dar und verwendet den internen Score des Modells, um den besten Weg zur Aufteilung der Daten in jedem Entscheidungsbaum zu finden.
# Create a series containing feature importances from the model and feature names from the training data
feature_importances = pd.Series(best_rf.feature_importances_, index=X_train.columns).sort_values(ascending=False)
# Plot a simple bar chart
feature_importances.plot.bar();Dies zeigt uns, dass der Index des Verbrauchervertrauens zum Zeitpunkt des Anrufs der wichtigste Indikator dafür war, ob die Person ein Abonnement abschloss.
Python-Kurse
Kurs
Kurs
Kurs
Tutorial
Derrick Mwiti
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Aditya Sharma
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
