Corso
Introduzione a Python
4 h
6.9M
Immagina di avere un problema complesso da risolvere e di riunire un gruppo di esperti di settori diversi per avere il loro parere. Ogni esperto fornisce la propria opinione in base a competenze ed esperienza. Poi, gli esperti votano per arrivare a una decisione finale.
In una classificazione random forest, si creano più alberi decisionali usando diversi sottoinsiemi casuali dei dati e delle caratteristiche. Ogni albero decisionale è come un esperto, che fornisce il proprio parere su come classificare i dati. Le previsioni si ottengono calcolando la previsione di ciascun albero decisionale e poi prendendo il risultato più popolare. (Per la regressione, invece, si usa una tecnica di media.)
Nello schema qui sotto, abbiamo una random forest con n alberi decisionali e mostriamo i primi 5, insieme alle loro previsioni ("Dog" o "Cat"). Ogni albero vede un numero diverso di feature e un campione diverso del dataset originale e, di conseguenza, ogni albero può essere diverso. Ogni albero effettua una previsione.
Guardando i primi 5 alberi, vediamo che 4/5 hanno previsto che il campione fosse un Cat. I cerchi verdi indicano un percorso ipotetico che l'albero ha seguito per arrivare alla decisione. La random forest conterebbe il numero di previsioni degli alberi decisionali per Cat e per Dog, e sceglierebbe la previsione più popolare.
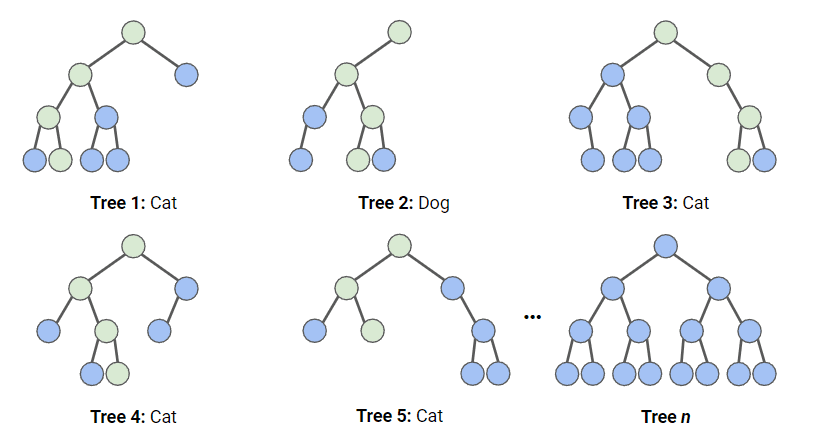 Illustrazione di come funziona la classificazione random forest. Immagine dell'autore
Illustrazione di come funziona la classificazione random forest. Immagine dell'autore
Questo dataset consiste in campagne di marketing diretto di un istituto bancario portoghese tramite telefonate. Le campagne miravano a vendere abbonamenti a un deposito a termine bancario. Salveremo questo dataset in una variabile chiamata bank_data. Le colonne che useremo sono:
age: Età della persona che ha ricevuto la telefonata
default: Se la persona ha crediti in sofferenza
cons.price.idx: Indice dei prezzi al consumo al momento della chiamata
cons.conf.idx: Indice di fiducia dei consumatori al momento della chiamata
y: Se la persona ha sottoscritto (è ciò che stiamo cercando di prevedere)
I seguenti pacchetti e funzioni sono usati in questo tutorial:
# Data Processing
import pandas as pd
import numpy as np
# Modelling
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, ConfusionMatrixDisplay
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from scipy.stats import randint
# Tree Visualisation
from sklearn.tree import export_graphviz
from IPython.display import Image
import graphvizPer adattare e addestrare questo modello, seguiremo l'infografica The Machine Learning Workflow; tuttavia, dato che i nostri dati sono piuttosto puliti, non eseguiremo ogni passaggio. Faremo quanto segue:
I modelli basati su alberi sono molto più robusti ai valori anomali rispetto ai modelli lineari e non hanno bisogno che le variabili siano normalizzate per funzionare. Pertanto, dobbiamo fare pochissimo preprocessing sui nostri dati.
Mappiamo la colonna default, che contiene no e yes, rispettivamente in 0 e 1. Tratteremo i valori unknown come no in questo esempio.
Mapperemo anche la nostra variabile target, y, in 1 e 0.
bank_data['default'] = bank_data['default'].map({'no':0,'yes':1,'unknown':0})
bank_data['y'] = bank_data['y'].map({'no':0,'yes':1})Quando si addestra qualsiasi modello di apprendimento supervisionato, è importante suddividere i dati in training e test. I dati di training sono usati per adattare il modello. L'algoritmo usa i dati di training per apprendere la relazione tra feature e target. I dati di test sono usati per valutare le prestazioni del modello.
Il codice seguente divide i dati in variabili separate per feature e target, quindi li suddivide in training e test.
# Split the data into features (X) and target (y)
X = bank_data.drop('y', axis=1)
y = bank_data['y']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)Per prima cosa creiamo un'istanza del modello Random Forest con i parametri predefiniti. Poi lo adattiamo ai nostri dati di training. Passiamo sia le feature che la variabile target in modo che il modello possa apprendere.
rf = RandomForestClassifier()
rf.fit(X_train, y_train)A questo punto abbiamo un modello random forest addestrato, ma dobbiamo capire se effettua previsioni accurate.
y_pred = rf.predict(X_test)Il modo più semplice per valutare questo modello è usare l'accuracy; confrontiamo le previsioni con i valori reali nel set di test e contiamo quante volte il modello ha indovinato.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Output:
Accuracy: 0.888È un ottimo punteggio! Tuttavia, potremmo fare meglio ottimizzando i nostri iperparametri.
Nota: L'accuracy da sola può essere fuorviante su dati sbilanciati. Controlla sempre precision e recall per capire il trade-off tra falsi positivi e falsi negativi.
Possiamo usare il seguente codice per visualizzare i nostri primi 3 alberi.
# Export the first three decision trees from the forest
for i in range(3):
tree = rf.estimators_[i]
dot_data = export_graphviz(tree,
feature_names=X_train.columns,
filled=True,
max_depth=2,
impurity=False,
proportion=True)
graph = graphviz.Source(dot_data)
display(graph)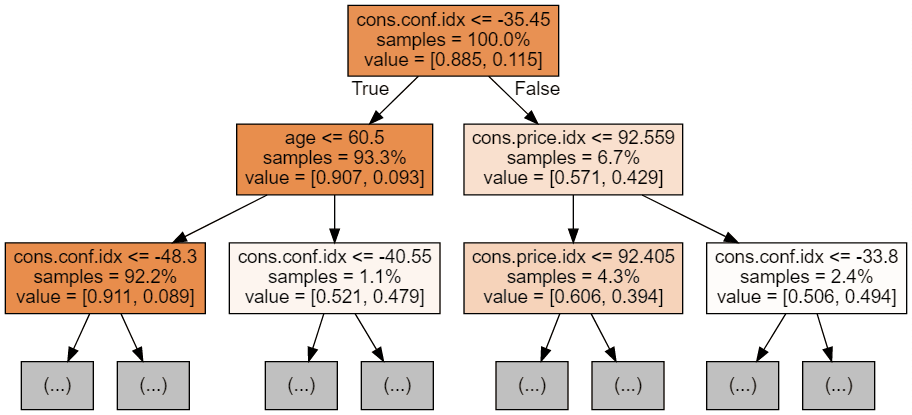
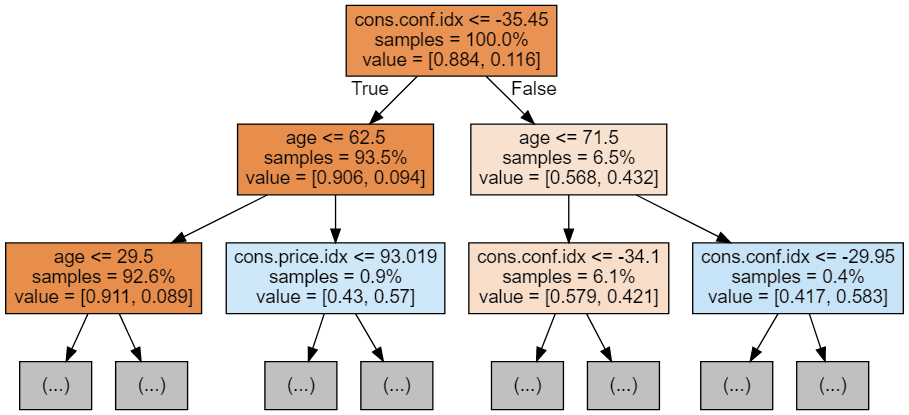
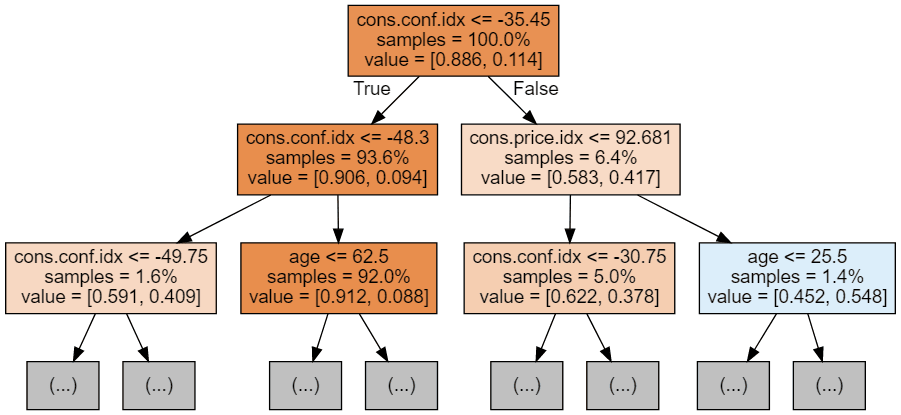
Ogni immagine dell'albero è limitata a mostrare solo i primi nodi. Questi alberi possono diventare molto grandi e difficili da visualizzare. I colori rappresentano la classe maggioritaria di ciascun nodo (riquadro), con il rosso a indicare maggioranza 0 (nessuna sottoscrizione) e il blu a indicare maggioranza 1 (sottoscrizione). I colori diventano più scuri quanto più il nodo si avvicina a essere completamente 0 o 1. Ogni nodo contiene anche le seguenti informazioni:
Il codice seguente usa RandomizedSearchCV di Scikit-Learn, che cercherà casualmente i parametri entro un intervallo per ciascun iperparametro. Definiamo gli iperparametri da usare e i loro intervalli nel dizionario param_dist. Nel nostro caso stiamo usando:
n_estimators: il numero di alberi decisionali nella foresta. Aumentare questo iperparametro in genere migliora le prestazioni del modello ma aumenta anche il costo computazionale di training e prediction.
max_depth: la profondità massima di ciascun albero decisionale nella foresta. Impostare un valore alto per max_depth può portare a overfitting, mentre impostarlo troppo basso può portare a underfitting.
param_dist = {
'n_estimators': randint(100, 500),
'max_depth': randint(3, 15),
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 5)
}
# Create a random forest classifier
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
# Use random search to find the best hyperparameters
rand_search = RandomizedSearchCV(
rf, param_distributions=param_dist,
n_iter=10, cv=5, scoring='accuracy',
n_jobs=-1, random_state=42
RandomizedSearchCV allenerà molti modelli (definiti da n_iter_) e salverà ciascuno come variabile. Il codice seguente crea una variabile per il modello migliore e stampa gli iperparametri.
In questo caso non abbiamo passato un sistema di scoring alla funzione, quindi il default è l'accuracy. Questa funzione usa anche la cross-validation, il che significa che divide i dati in cinque gruppi di dimensioni uguali e usa 4 per addestrare e 1 per testare il risultato. Ciclerà ogni gruppo e fornirà un punteggio di accuracy, che viene mediato per trovare il modello migliore.
# Create a variable for the best model
best_rf = rand_search.best_estimator_
# Print the best hyperparameters
print('Best hyperparameters:', rand_search.best_params_)Output:
Best hyperparameters: {'max_depth': 5, 'n_estimators': 260}Vediamo la confusion matrix. Questa mette a confronto ciò che il modello ha predetto con la previsione corretta. Possiamo usarla per comprendere il compromesso tra falsi positivi (in alto a destra) e falsi negativi (in basso a sinistra). Possiamo tracciare la confusion matrix con questo codice:
# Generate predictions with the best model
y_pred = best_rf.predict(X_test)
# Create the confusion matrix
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(confusion_matrix=cm).plot();Output:
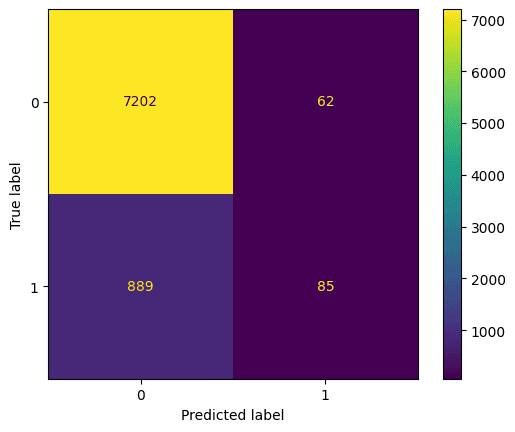
Valutazione del classificatore random forest tramite confusion matrix. Immagine dell'autore
Dovremmo anche valutare il modello migliore con accuracy, precision e recall (nota: i tuoi risultati possono differire a causa della randomizzazione)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Output:
Accuracy: 0.885
Precision: 0.578
Recall: 0.0873Il codice qui sotto traccia l'importanza di ciascuna feature, usando il punteggio interno del modello per trovare il modo migliore di suddividere i dati all'interno di ciascun albero decisionale.
# Create a series containing feature importances from the model and feature names from the training data
importances = pd.Series(best_rf.feature_importances_, index=X_train.columns)
importances.sort_values(ascending=False).plot.bar()
Questo ci dice che l'indice di fiducia dei consumatori, al momento della chiamata, è stato il principale predittore del fatto che la persona sottoscrivesse.
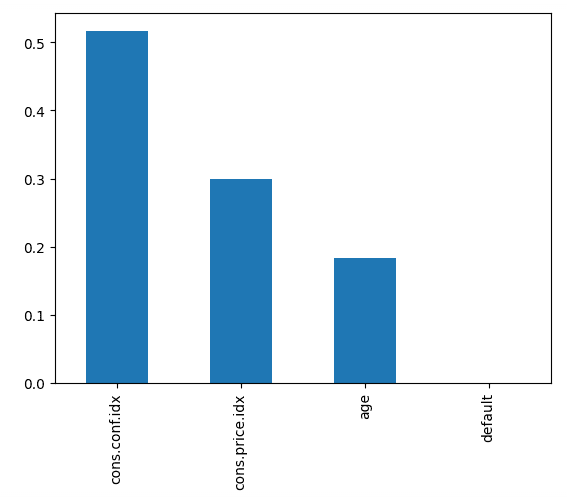
Feature del classificatore random forest in ordine di importanza. Immagine dell'autore
Le Random Forest sono un'ottima scelta quando ti serve un solido modello di base che funzioni bene fin da subito. Gestiscono sia feature numeriche che categoriali, trattano bene i valori mancanti e sono meno inclini all'overfitting rispetto a singoli alberi decisionali.
Usa le Random Forest quando:
Tuttavia, le Random Forest potrebbero non essere ideali quando:
Per iniziare con il machine learning supervisionato in Python, segui Supervised Learning with scikit-learn. Per saperne di più sull'uso delle random forest e di altri modelli di machine learning basati su alberi, guarda i nostri corsi Machine Learning with Tree-Based Models in Python e Ensemble Methods in Python.
Corsi Python
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

