Courses
Nhập môn Python
4 giờ
6.9M
Hãy tưởng tượng bạn có một vấn đề phức tạp cần giải quyết và bạn tập hợp một nhóm chuyên gia từ các lĩnh vực khác nhau để xin ý kiến. Mỗi chuyên gia đưa ra quan điểm dựa trên chuyên môn và kinh nghiệm của họ. Sau đó, các chuyên gia sẽ bỏ phiếu để đi đến quyết định cuối cùng.
Trong phân loại bằng random forest, nhiều cây quyết định được tạo bằng các tập con ngẫu nhiên khác nhau của dữ liệu và đặc trưng. Mỗi cây quyết định giống như một chuyên gia, đưa ra ý kiến về cách phân loại dữ liệu. Dự đoán được thực hiện bằng cách tính dự đoán của từng cây quyết định rồi lấy kết quả phổ biến nhất. (Đối với hồi quy, dự đoán sẽ sử dụng kỹ thuật trung bình thay thế.)
Trong sơ đồ dưới đây, chúng ta có một random forest với n cây quyết định, và chúng tôi hiển thị 5 cây đầu tiên cùng với dự đoán của chúng (hoặc “Dog” hoặc “Cat”). Mỗi cây được tiếp xúc với số lượng đặc trưng khác nhau và một mẫu khác nhau của bộ dữ liệu gốc, do đó mỗi cây có thể khác nhau. Mỗi cây tạo ra một dự đoán.
Nhìn vào 5 cây đầu tiên, ta thấy 4/5 dự đoán mẫu là Cat. Các vòng tròn màu xanh lá cho biết một đường đi giả định mà cây đã chọn để đi đến quyết định. Random forest sẽ đếm số lượng dự đoán từ các cây quyết định cho Cat và cho Dog, rồi chọn dự đoán phổ biến nhất.
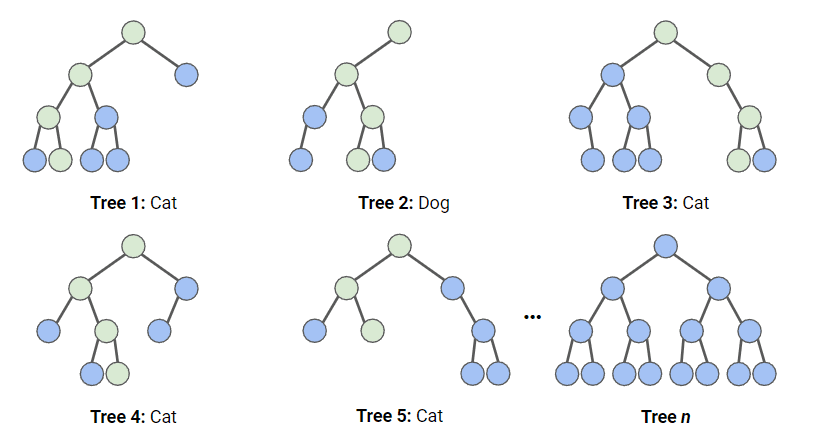 Minh họa cách phân loại random forest hoạt động. Ảnh: Tác giả
Minh họa cách phân loại random forest hoạt động. Ảnh: Tác giả
Bộ dữ liệu này gồm các chiến dịch tiếp thị trực tiếp qua điện thoại của một tổ chức ngân hàng Bồ Đào Nha. Mục tiêu của chiến dịch là bán gói tiền gửi có kỳ hạn. Chúng ta sẽ lưu bộ dữ liệu này trong biến bank_data. Các cột sẽ sử dụng gồm:
age: Tuổi của người nhận cuộc gọi
default: Người đó có đang trong tình trạng vỡ nợ tín dụng hay không
cons.price.idx: Điểm chỉ số giá tiêu dùng tại thời điểm gọi
cons.conf.idx: Điểm chỉ số niềm tin người tiêu dùng tại thời điểm gọi
y: Người đó có đăng ký (đây là thứ chúng ta cố gắng dự đoán) hay không
Các gói và hàm sau được dùng trong hướng dẫn này:
# Data Processing
import pandas as pd
import numpy as np
# Modelling
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, ConfusionMatrixDisplay
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from scipy.stats import randint
# Tree Visualisation
from sklearn.tree import export_graphviz
from IPython.display import Image
import graphvizĐể fit và huấn luyện mô hình này, chúng ta sẽ theo infographic The Machine Learning Workflow; tuy nhiên, vì dữ liệu của chúng ta khá sạch, chúng ta sẽ không thực hiện mọi bước. Chúng ta sẽ làm như sau:
Các mô hình dựa trên cây vững vàng hơn nhiều trước ngoại lệ so với mô hình tuyến tính, và không cần chuẩn hóa biến để hoạt động. Vì vậy, chúng ta cần rất ít tiền xử lý dữ liệu.
Chúng ta sẽ ánh xạ cột default, chứa no và yes, thành các 0 và 1 tương ứng. Với ví dụ này, chúng ta coi giá trị unknown là no.
Chúng ta cũng sẽ ánh xạ biến mục tiêu y thành 1 và 0.
bank_data['default'] = bank_data['default'].map({'no':0,'yes':1,'unknown':0})
bank_data['y'] = bank_data['y'].map({'no':0,'yes':1})Khi huấn luyện bất kỳ mô hình học có giám sát nào, việc chia dữ liệu thành dữ liệu huấn luyện và dữ liệu kiểm tra là quan trọng. Dữ liệu huấn luyện được dùng để fit mô hình. Thuật toán sử dụng dữ liệu huấn luyện để học mối quan hệ giữa các đặc trưng và biến mục tiêu. Dữ liệu kiểm tra được dùng để đánh giá hiệu suất của mô hình.
Đoạn mã dưới đây chia dữ liệu thành các biến riêng cho đặc trưng và mục tiêu, rồi tiếp tục chia chúng thành dữ liệu huấn luyện và kiểm tra.
# Split the data into features (X) and target (y)
X = bank_data.drop('y', axis=1)
y = bank_data['y']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)Đầu tiên, chúng ta tạo một thể hiện của mô hình Random Forest với các tham số mặc định. Sau đó fit mô hình này với dữ liệu huấn luyện. Chúng ta truyền cả đặc trưng và biến mục tiêu để mô hình có thể học.
rf = RandomForestClassifier()
rf.fit(X_train, y_train)Ở thời điểm này, chúng ta đã có một mô hình random forest được huấn luyện, nhưng cần biết liệu nó dự đoán có chính xác không.
y_pred = rf.predict(X_test)Cách đơn giản nhất để đánh giá mô hình là dùng độ chính xác (accuracy); chúng ta so sánh dự đoán với giá trị thực trong tập kiểm tra và đếm xem mô hình đoán đúng bao nhiêu.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Kết quả:
Accuracy: 0.888Đây là một điểm số khá tốt! Tuy vậy, chúng ta có thể làm tốt hơn bằng cách tối ưu các siêu tham số.
Lưu ý: Chỉ dùng accuracy có thể gây hiểu nhầm với dữ liệu mất cân bằng. Luôn kiểm tra precision và recall để hiểu sự đánh đổi giữa dương tính giả và âm tính giả.
Chúng ta có thể dùng đoạn mã sau để trực quan hóa 3 cây đầu tiên.
# Export the first three decision trees from the forest
for i in range(3):
tree = rf.estimators_[i]
dot_data = export_graphviz(tree,
feature_names=X_train.columns,
filled=True,
max_depth=2,
impurity=False,
proportion=True)
graph = graphviz.Source(dot_data)
display(graph)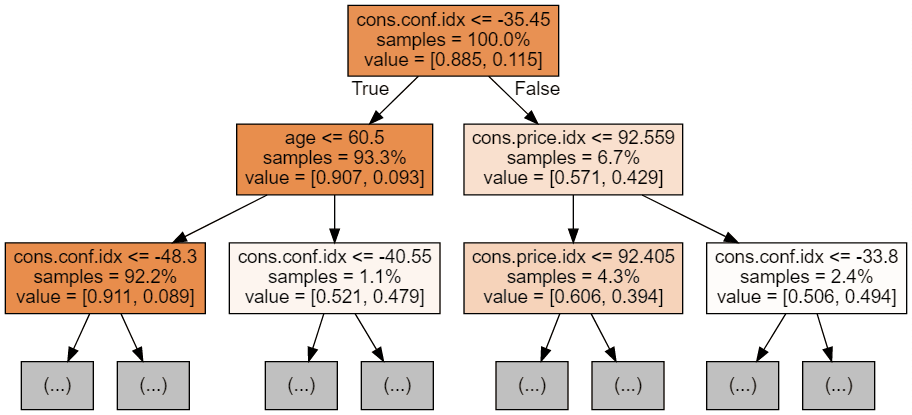
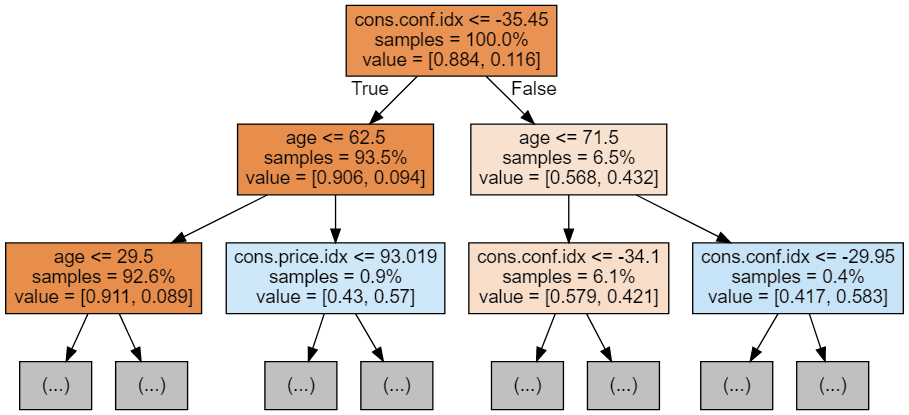
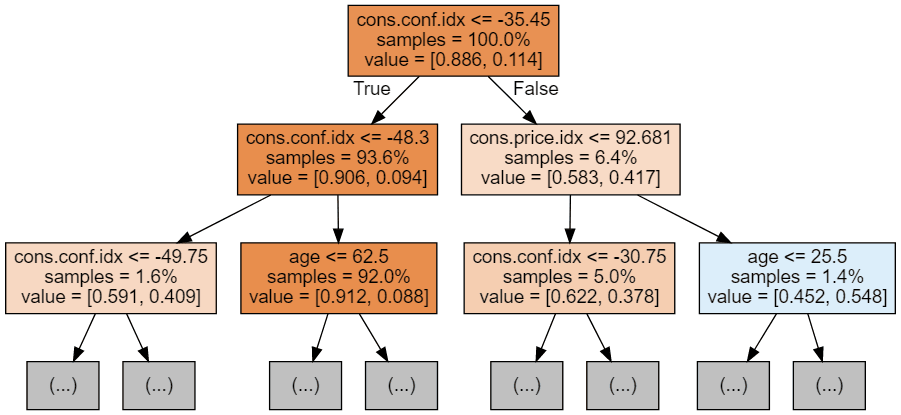
Mỗi ảnh cây chỉ hiển thị một vài nút đầu tiên. Các cây này có thể rất lớn và khó trực quan hóa. Màu sắc thể hiện lớp chiếm đa số của mỗi nút (hộp), với đỏ là đa số 0 (không đăng ký) và xanh dương là đa số 1 (đăng ký). Màu càng đậm khi nút càng tiến gần đến hoàn toàn 0 hoặc 1. Mỗi nút cũng chứa các thông tin sau:
Đoạn mã dưới đây sử dụng RandomizedSearchCV của Scikit-Learn, công cụ sẽ tìm ngẫu nhiên các tham số trong một phạm vi cho mỗi siêu tham số. Chúng ta xác định các siêu tham số và phạm vi của chúng trong từ điển param_dist. Trong trường hợp này, chúng ta dùng:
n_estimators: số lượng cây quyết định trong rừng. Tăng siêu tham số này thường cải thiện hiệu suất mô hình nhưng cũng làm tăng chi phí tính toán cho huấn luyện và dự đoán.
max_depth: độ sâu tối đa của mỗi cây quyết định trong rừng. Đặt max_depth quá cao có thể dẫn tới overfitting, còn quá thấp có thể dẫn tới underfitting.
param_dist = {
'n_estimators': randint(100, 500),
'max_depth': randint(3, 15),
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 5)
}
# Create a random forest classifier
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
# Use random search to find the best hyperparameters
rand_search = RandomizedSearchCV(
rf, param_distributions=param_dist,
n_iter=10, cv=5, scoring='accuracy',
n_jobs=-1, random_state=42
RandomizedSearchCVsẽ huấn luyện nhiều mô hình (được xác định bởi n_iter_) và lưu từng mô hình làm một biến. Đoạn mã dưới đây tạo một biến cho mô hình tốt nhất và in ra các siêu tham số.
Trong trường hợp này, chúng ta chưa truyền hệ thống chấm điểm cho hàm, vì vậy mặc định là accuracy. Hàm này cũng dùng cross-validation, nghĩa là nó chia dữ liệu thành năm nhóm có kích thước bằng nhau và dùng 4 nhóm để huấn luyện, 1 nhóm để kiểm tra kết quả. Nó sẽ lặp qua mỗi nhóm và cho điểm accuracy, sau đó lấy trung bình để tìm mô hình tốt nhất.
# Create a variable for the best model
best_rf = rand_search.best_estimator_
# Print the best hyperparameters
print('Best hyperparameters:', rand_search.best_params_)Kết quả:
Best hyperparameters: {'max_depth': 5, 'n_estimators': 260}Hãy xem ma trận nhầm lẫn. Biểu đồ này so sánh dự đoán của mô hình với dự đoán đúng. Chúng ta có thể dùng nó để hiểu sự đánh đổi giữa dương tính giả (góc trên bên phải) và âm tính giả (góc dưới bên trái). Chúng ta có thể vẽ ma trận nhầm lẫn bằng đoạn mã sau:
# Generate predictions with the best model
y_pred = best_rf.predict(X_test)
# Create the confusion matrix
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(confusion_matrix=cm).plot();Kết quả:
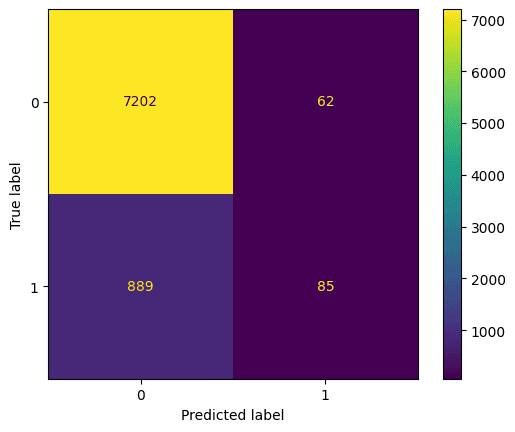
Đánh giá bộ phân loại random forest bằng ma trận nhầm lẫn. Ảnh: Tác giả
Chúng ta cũng nên đánh giá mô hình tốt nhất bằng accuracy, precision và recall (lưu ý kết quả của bạn có thể khác do ngẫu nhiên)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Kết quả:
Accuracy: 0.885
Precision: 0.578
Recall: 0.0873Đoạn mã dưới đây vẽ mức độ quan trọng của từng đặc trưng, sử dụng điểm số nội bộ của mô hình để tìm cách chia dữ liệu tốt nhất trong mỗi cây quyết định.
# Create a series containing feature importances from the model and feature names from the training data
importances = pd.Series(best_rf.feature_importances_, index=X_train.columns)
importances.sort_values(ascending=False).plot.bar()
Điều này cho thấy chỉ số niềm tin người tiêu dùng tại thời điểm gọi là yếu tố dự báo lớn nhất về việc người đó có đăng ký hay không.
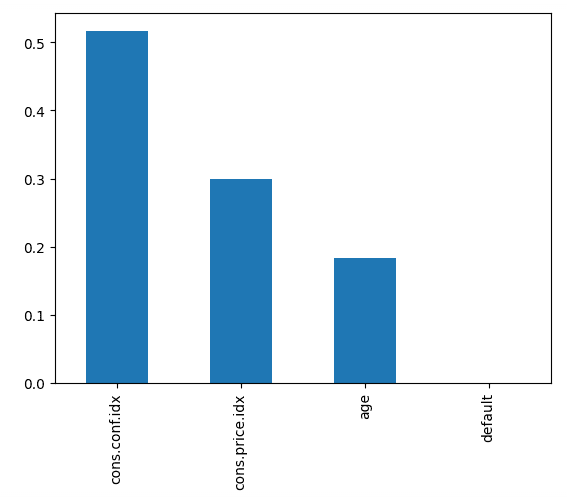
Các đặc trưng của bộ phân loại random forest theo thứ tự quan trọng. Ảnh: Tác giả
Random Forest là lựa chọn tuyệt vời khi bạn cần một mô hình nền tảng mạnh hoạt động tốt ngay từ đầu. Chúng xử lý cả đặc trưng số và phân loại, quản lý giá trị thiếu tốt, và ít dễ bị overfitting hơn so với cây quyết định đơn lẻ.
Hãy dùng Random Forest khi:
Tuy nhiên, Random Forest có thể không lý tưởng khi:
Để bắt đầu với học có giám sát trong Python, hãy học Supervised Learning with scikit-learn. Để tìm hiểu thêm về random forest và các mô hình máy học dựa trên cây khác, hãy xem các khóa Machine Learning with Tree-Based Models in Python và Ensemble Methods in Python.
Khóa học Python
Courses
Courses
Courses