Cursus
Introductie tot Python
4 Hr
6.9M
Stel, je hebt een complex probleem op te lossen en je verzamelt een groep experts uit verschillende vakgebieden om hun input te geven. Elke expert geeft zijn mening op basis van expertise en ervaring. Vervolgens stemmen de experts om tot een eindoordeel te komen.
Bij random forest-classificatie worden meerdere beslissingsbomen gemaakt met verschillende willekeurige deelverzamelingen van de data en features. Elke beslissingsboom is als een expert die zijn oordeel geeft over hoe de data te classificeren. Voorspellingen worden gedaan door de voorspelling van elke beslissingsboom te berekenen en vervolgens de meest populaire uitkomst te nemen. (Voor regressie wordt in plaats daarvan een gemiddelde gebruikt.)
In het onderstaande diagram hebben we een random forest met n beslissingsbomen en tonen we de eerste 5, samen met hun voorspellingen (ofwel “Dog” of “Cat”). Elke boom ziet een andere set features en een andere steekproef van de oorspronkelijke dataset, en daardoor kan elke boom verschillen. Elke boom doet een voorspelling.
Kijkend naar de eerste 5 bomen, zien we dat 4/5 voorspelden dat het sample een Cat was. De groene cirkels geven een hypothetisch pad aan dat de boom nam om tot zijn beslissing te komen. Het random forest telt het aantal voorspellingen van beslissingsbomen voor Cat en voor Dog, en kiest de meest populaire voorspelling.
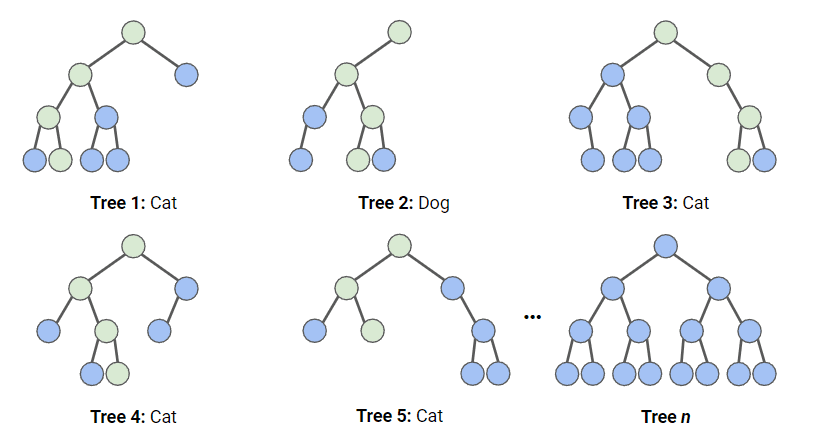 Illustratie van hoe random forest-classificatie werkt. Afbeelding door de auteur
Illustratie van hoe random forest-classificatie werkt. Afbeelding door de auteur
Deze dataset bestaat uit direct marketingcampagnes van een Portugese bank via telefoongesprekken. De campagnes waren gericht op de verkoop van abonnementen op een termijndeposito. We slaan deze dataset op in een variabele genaamd bank_data. De kolommen die we gebruiken zijn:
age: De leeftijd van de persoon die het telefoontje ontving
default: Of de persoon een betalingsachterstand op krediet heeft
cons.price.idx: Consumentenprijsindex ten tijde van het gesprek
cons.conf.idx: Consumentenvertrouwensindex ten tijde van het gesprek
y: Of de persoon heeft geabonneerd (dit is wat we proberen te voorspellen)
De volgende pakketten en functies worden in deze tutorial gebruikt:
# Data Processing
import pandas as pd
import numpy as np
# Modelling
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, ConfusionMatrixDisplay
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from scipy.stats import randint
# Tree Visualisation
from sklearn.tree import export_graphviz
from IPython.display import Image
import graphvizOm dit model te fitten en te trainen, volgen we de infographic The Machine Learning Workflow; omdat onze data vrij schoon is, doorlopen we echter niet elke stap. We doen het volgende:
Boomgebaseerde modellen zijn veel robuuster voor uitschieters dan lineaire modellen en ze hoeven geen genormaliseerde variabelen te hebben om te werken. We hoeven dus maar weinig voorbewerking op onze data toe te passen.
We mappen onze kolom default, die no en yes bevat, respectievelijk naar 0 en 1. Voor dit voorbeeld behandelen we unknown als no.
We mappen ook onze target, y, naar 1 en 0.
bank_data['default'] = bank_data['default'].map({'no':0,'yes':1,'unknown':0})
bank_data['y'] = bank_data['y'].map({'no':0,'yes':1})Bij het trainen van elk supervised learning-model is het belangrijk om de data op te splitsen in trainings- en testdata. De trainingsdata wordt gebruikt om het model te fitten. Het algoritme gebruikt de trainingsdata om de relatie tussen de features en de target te leren. De testdata wordt gebruikt om de prestaties van het model te evalueren.
De onderstaande code splitst de data in aparte variabelen voor de features en de target, en splitst deze vervolgens in trainings- en testdata.
# Split the data into features (X) and target (y)
X = bank_data.drop('y', axis=1)
y = bank_data['y']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)We maken eerst een instantie van het Random Forest-model met de standaardparameters. Vervolgens fitten we dit op onze trainingsdata. We geven zowel de features als de doelvariabele mee zodat het model kan leren.
rf = RandomForestClassifier()
rf.fit(X_train, y_train)Op dit punt hebben we een getraind random forest-model, maar we moeten nagaan of het nauwkeurige voorspellingen doet.
y_pred = rf.predict(X_test)De eenvoudigste manier om dit model te evalueren is met accuracy; we vergelijken de voorspellingen met de werkelijke waarden in de testset en tellen hoeveel het model er goed had.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Output:
Accuracy: 0.888Dit is een prima score! Maar we kunnen mogelijk nog beter door onze hyperparameters te optimaliseren.
Let op: Alleen accuracy kan misleidend zijn bij scheve classverhoudingen. Controleer altijd precision en recall om de trade-off tussen false positives en false negatives te begrijpen.
Met de volgende code kunnen we onze eerste 3 bomen visualiseren.
# Export the first three decision trees from the forest
for i in range(3):
tree = rf.estimators_[i]
dot_data = export_graphviz(tree,
feature_names=X_train.columns,
filled=True,
max_depth=2,
impurity=False,
proportion=True)
graph = graphviz.Source(dot_data)
display(graph)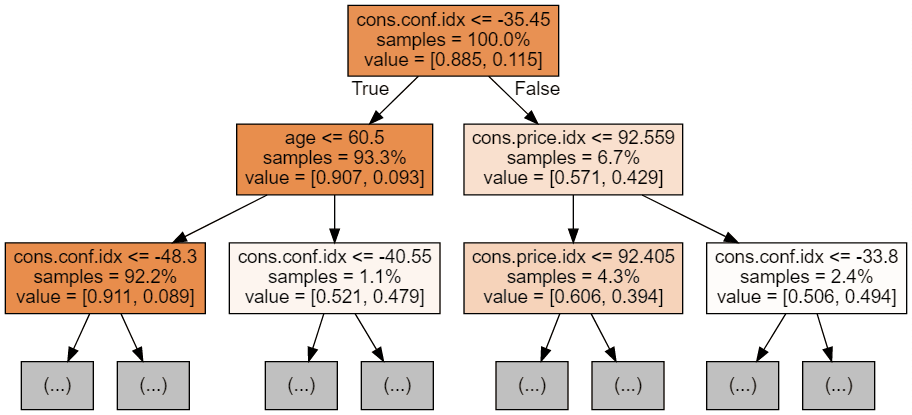
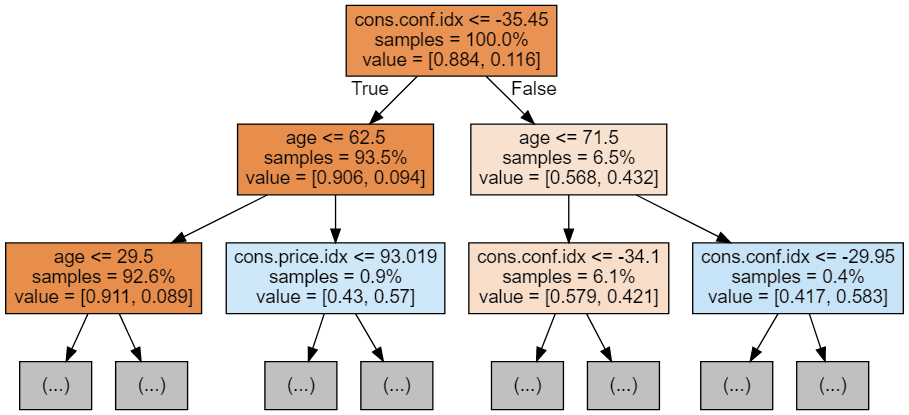
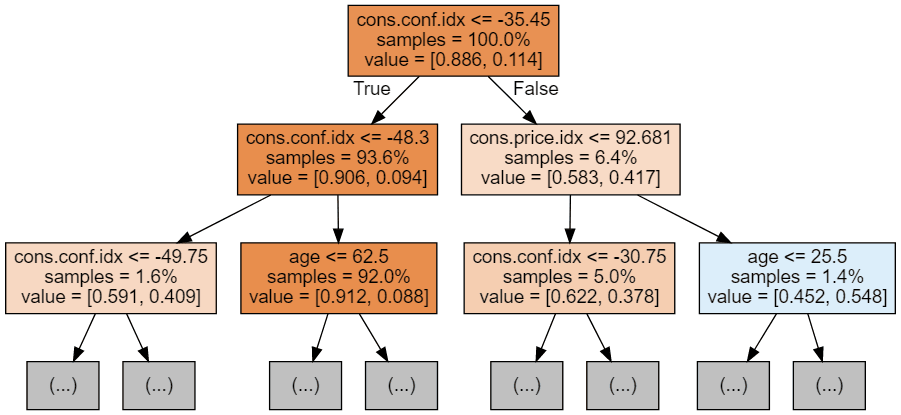
Elke boomafbeelding toont alleen de eerste paar knopen. Deze bomen kunnen erg groot en lastig te visualiseren worden. De kleuren geven de meerderheidsklasse van elke knoop (vak) aan, waarbij rood meerderheid 0 (geen abonnement) en blauw meerderheid 1 (abonnement) betekent. De kleuren worden donkerder naarmate de knoop dichter bij volledig 0 of 1 komt. Elke knoop bevat bovendien de volgende informatie:
De onderstaande code gebruikt Scikit-Learn’s RandomizedSearchCV, die per hyperparameter willekeurig binnen een bereik naar parameters zoekt. We definiëren de te gebruiken hyperparameters en hun bereiken in de dictionary param_dist. In ons geval gebruiken we:
n_estimators: het aantal beslissingsbomen in het forest. Deze hyperparameter verhogen verbetert doorgaans de prestaties van het model, maar verhoogt ook de rekentijd voor trainen en voorspellen.
max_depth: de maximale diepte van elke beslissingsboom in het forest. Een hogere waarde voor max_depth kan tot overfitting leiden, terwijl te laag instellen tot underfitting kan leiden.
param_dist = {
'n_estimators': randint(100, 500),
'max_depth': randint(3, 15),
'min_samples_split': randint(2, 10),
'min_samples_leaf': randint(1, 5)
}
# Create a random forest classifier
rf = RandomForestClassifier(random_state=42, n_jobs=-1)
# Use random search to find the best hyperparameters
rand_search = RandomizedSearchCV(
rf, param_distributions=param_dist,
n_iter=10, cv=5, scoring='accuracy',
n_jobs=-1, random_state=42
RandomizedSearchCV zal veel modellen trainen (bepaald door n_iter_) en elk model als variabele opslaan. De code hieronder maakt een variabele aan voor het beste model en print de hyperparameters.
In dit geval hebben we geen scoringsmethode meegegeven, dus de functie gebruikt standaard accuracy. Deze functie gebruikt ook cross-validatie, wat betekent dat de data in vijf even grote groepen wordt gesplitst en 4 worden gebruikt om te trainen en 1 om het resultaat te testen. Hij loopt door elke groep en geeft een accuracy-score, die wordt gemiddeld om het beste model te vinden.
# Create a variable for the best model
best_rf = rand_search.best_estimator_
# Print the best hyperparameters
print('Best hyperparameters:', rand_search.best_params_)Output:
Best hyperparameters: {'max_depth': 5, 'n_estimators': 260}Laten we naar de confusion matrix kijken. Deze zet wat het model voorspelde uit tegen wat de juiste voorspelling was. Hiermee kun je de afruil tussen false positives (rechtsboven) en false negatives (linksonder) begrijpen. We kunnen de confusion matrix plotten met deze code:
# Generate predictions with the best model
y_pred = best_rf.predict(X_test)
# Create the confusion matrix
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(confusion_matrix=cm).plot();Output:
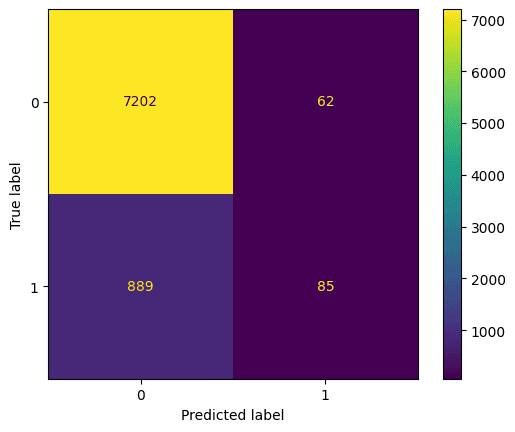
Evaluatie van een random forest-classifier met een confusion matrix. Afbeelding door de auteur
We moeten het beste model ook beoordelen met accuracy, precision en recall (let op: je resultaten kunnen verschillen door randomisatie)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Output:
Accuracy: 0.885
Precision: 0.578
Recall: 0.0873De onderstaande code plot het belang van elke feature, met gebruik van de interne score van het model om de beste manier te vinden om de data binnen elke beslissingsboom te splitsen.
# Create a series containing feature importances from the model and feature names from the training data
importances = pd.Series(best_rf.feature_importances_, index=X_train.columns)
importances.sort_values(ascending=False).plot.bar()
Hieruit blijkt dat de consumentenvertrouwensindex, op het moment van het gesprek, de grootste voorspeller was of iemand zich abonneerde.
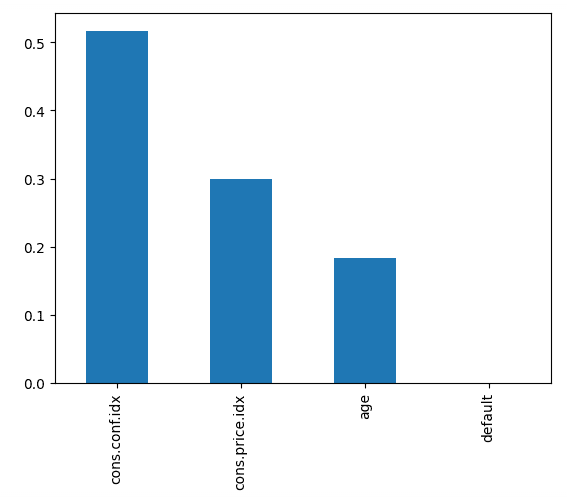
Random forest-classifierfeatures op volgorde van belangrijkheid. Afbeelding door de auteur
Random forests zijn een uitstekende keuze wanneer je een sterk basismodel nodig hebt dat direct goed presteert. Ze kunnen zowel numerieke als categorische features aan, gaan soepel om met ontbrekende waarden en zijn minder gevoelig voor overfitting dan losse beslissingsbomen.
Gebruik random forests wanneer:
Random forests zijn echter minder ideaal wanneer:
Om aan de slag te gaan met supervised machine learning in Python, volg Supervised Learning with scikit-learn. Wil je meer leren over random forests en andere boomgebaseerde machine learning-modellen, bekijk dan onze cursussen Machine Learning with Tree-Based Models in Python en Ensemble Methods in Python.
Python-cursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
