Cours
Introduction à Python
4 h
6.9M
Imaginez que vous ayez un problème complexe à résoudre et que vous réunissiez un groupe d'experts de différents domaines pour qu'ils apportent leur contribution. Chaque expert donne son avis sur la base de son expertise et de son expérience. Ensuite, les experts voteront pour prendre une décision finale.
Dans une classification par forêt aléatoire, plusieurs arbres de décision sont créés en utilisant différents sous-ensembles aléatoires de données et de caractéristiques. Chaque arbre de décision est comme un expert qui donne son avis sur la manière de classer les données. Les prédictions sont faites en calculant la prédiction pour chaque arbre de décision et en prenant le résultat le plus populaire. (Pour la régression, les prévisions utilisent plutôt une technique de calcul de la moyenne).
Dans le diagramme ci-dessous, nous avons une forêt aléatoire avec n arbres de décision, et nous avons montré les 5 premiers, ainsi que leurs prédictions (soit "Chien", soit "Chat"). Chaque arbre est exposé à un nombre différent de caractéristiques et à un échantillon différent de l'ensemble de données original. Chaque arbre fait une prédiction.
En regardant les 5 premiers arbres, nous pouvons voir que 4/5 ont prédit que l'échantillon était un Chat. Les cercles verts indiquent un chemin hypothétique emprunté par l'arbre pour parvenir à sa décision. La forêt aléatoire compterait le nombre de prédictions des arbres de décision pour Cat et pour Dog, et choisirait la prédiction la plus populaire.
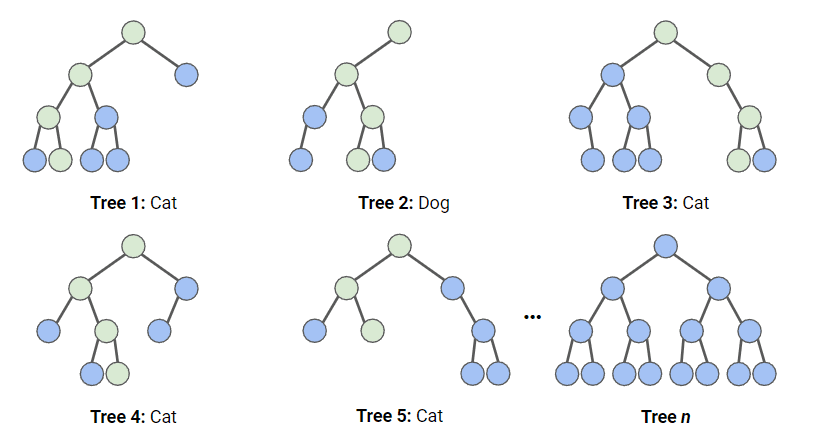 Illustration du fonctionnement de la classification par forêt aléatoire. Image par l'auteur
Illustration du fonctionnement de la classification par forêt aléatoire. Image par l'auteur
Cet ensemble de données est constitué de campagnes de marketing direct menées par une institution bancaire portugaise au moyen d'appels téléphoniques. Les campagnes visaient à vendre des abonnements à un dépôt bancaire à terme. Nous allons stocker cet ensemble de données dans une variable appelée bank_data. Les colonnes que nous utiliserons sont les suivantes :
age: L'âge de la personne qui a reçu l'appel téléphoniquedefault: Si la personne est en défaut de paiementcons.price.idx: Indice des prix à la consommation au moment de l'appelcons.conf.idxIndice de confiance des consommateurs au moment de l'appely: Si la personne s'est abonnée (c'est ce que nous essayons de prédire)Les paquets et fonctions suivants sont utilisés dans ce tutoriel :
# Data Processing
import pandas as pd
import numpy as np
# Modelling
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, ConfusionMatrixDisplay
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from scipy.stats import randint
# Tree Visualisation
from sklearn.tree import export_graphviz
from IPython.display import Image
import graphvizPour ajuster et entraîner ce modèle, nous suivrons l'infographie The Machine Learning Workflow; cependant, comme nos données sont assez propres, nous n'effectuerons pas toutes les étapes. Nous ferons ce qui suit :
Les modèles arborescents sont beaucoup plus résistants aux valeurs aberrantes que les modèles linéaires, et ils n'ont pas besoin de normaliser les variables pour fonctionner. Ainsi, nous n'avons besoin que de très peu de prétraitement sur nos données.
default, qui contient no et yes, aux colonnes 0et 1, respectivement. Dans cet exemple, nous traiterons les valeurs unknown comme no.y, à 1s et 0s.bank_data['default'] = bank_data['default'].map({'no':0,'yes':1,'unknown':0})
bank_data['y'] = bank_data['y'].map({'no':0,'yes':1})Lors de l'apprentissage d'un modèle d'apprentissage supervisé, il est important de diviser les données en données d'apprentissage et en données de test. Les données d'apprentissage sont utilisées pour ajuster le modèle. L'algorithme utilise les données d'apprentissage pour apprendre la relation entre les caractéristiques et la cible. Les données de test sont utilisées pour évaluer la performance du modèle.
Le code ci-dessous divise les données en variables distinctes pour les caractéristiques et la cible, puis en données de formation et de test.
# Split the data into features (X) and target (y)
X = bank_data.drop('y', axis=1)
y = bank_data['y']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Nous commençons par créer une instance du modèle Random forest avec les paramètres par défaut. Nous l'adaptons ensuite à nos données d'apprentissage. Nous transmettons à la fois les caractéristiques et la variable cible afin que le modèle puisse apprendre.
rf = RandomForestClassifier()
rf.fit(X_train, y_train)À ce stade, nous disposons d'un modèle de forêt aléatoire entraîné, mais nous devons déterminer si ses prédictions sont exactes.
y_pred = rf.predict(X_test)La façon la plus simple d'évaluer ce modèle est d'utiliser la précision ; nous vérifions les prédictions par rapport aux valeurs réelles de l'ensemble de test et comptons combien le modèle a eu raison.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Sortie :
Accuracy: 0.888C'est un très bon score ! Cependant, nous pouvons faire mieux en optimisant nos hyperparamètres.
Nous pouvons utiliser le code suivant pour visualiser nos trois premiers arbres.
# Export the first three decision trees from the forest
for i in range(3):
tree = rf.estimators_[i]
dot_data = export_graphviz(tree,
feature_names=X_train.columns,
filled=True,
max_depth=2,
impurity=False,
proportion=True)
graph = graphviz.Source(dot_data)
display(graph)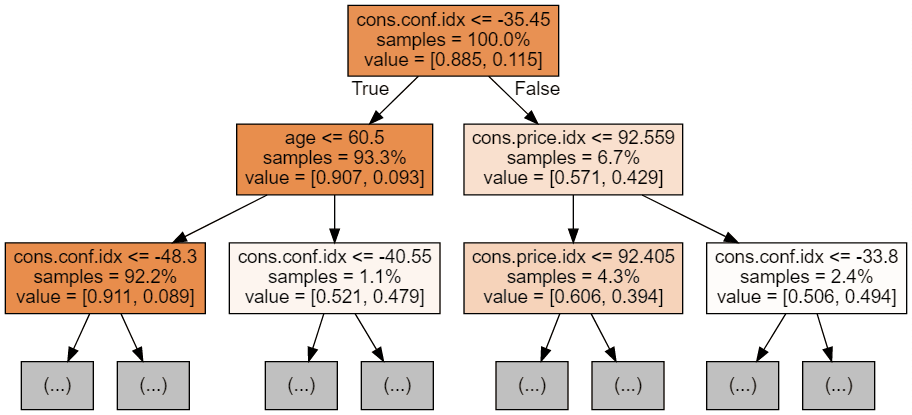
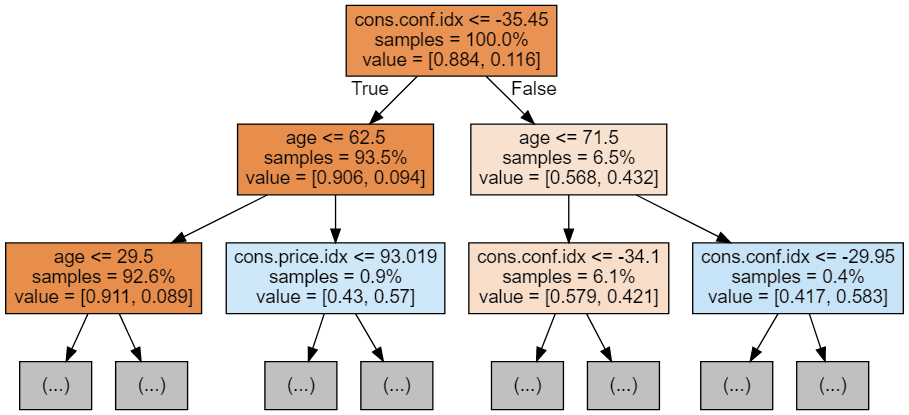
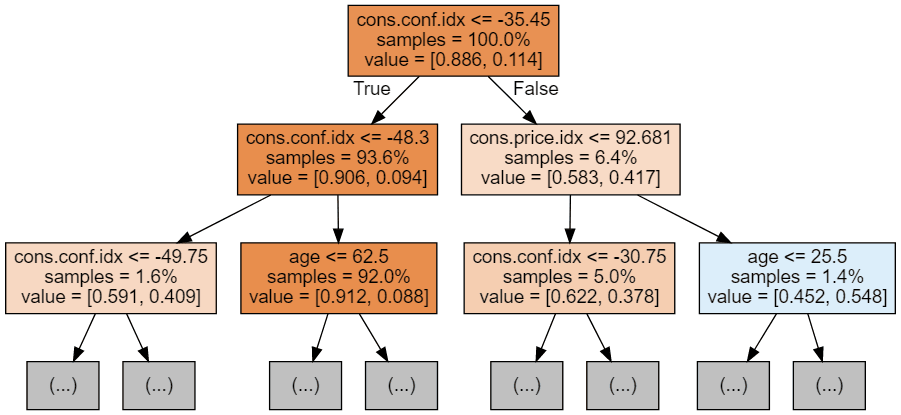
Chaque image d'arbre ne montre que les premiers nœuds. Ces arbres peuvent devenir très grands et difficiles à visualiser. Les couleurs représentent la classe majoritaire de chaque nœud (boîte), le rouge indiquant la majorité 0 (pas d'abonnement) et le bleu la majorité 1 (abonnement). Les couleurs sont d'autant plus foncées que le nœud est proche de 0 ou de 1. Chaque nœud contient également les informations suivantes :
Le code ci-dessous utilise la fonction RandomizedSearchCV de Scikit-Learn, qui recherche aléatoirement des paramètres dans une fourchette par hyperparamètre. Nous définissons les hyperparamètres à utiliser et leurs plages dans le dictionnaire param_dist. Dans notre cas, nous utilisons :
param_dist = {'n_estimators': randint(50,500),
'max_depth': randint(1,20)}
# Create a random forest classifier
rf = RandomForestClassifier()
# Use random search to find the best hyperparameters
rand_search = RandomizedSearchCV(rf,
param_distributions = param_dist,
n_iter=5,
cv=5)
# Fit the random search object to the data
rand_search.fit(X_train, y_train)RandomizedSearchCV entraînera de nombreux modèles (définis par n_iter_ et enregistrera chacun d'entre eux en tant que variables, le code ci-dessous crée une variable pour le meilleur modèle et imprime les hyperparamètres. Dans ce cas, nous n'avons pas transmis de système d'évaluation à la fonction, qui utilise donc par défaut la précision. Cette fonction utilise également la validation croisée, ce qui signifie qu'elle divise les données en cinq groupes de taille égale et qu'elle en utilise quatre pour la formation et un pour le test. Il passe en boucle sur chaque groupe et donne un score de précision, dont la moyenne est calculée pour trouver le meilleur modèle.
# Create a variable for the best model
best_rf = rand_search.best_estimator_
# Print the best hyperparameters
print('Best hyperparameters:', rand_search.best_params_)Sortie :
Best hyperparameters: {'max_depth': 5, 'n_estimators': 260}Examinons la matrice de confusion. Il s'agit d'une représentation graphique de ce que le modèle a prédit par rapport à ce qu'a été la prédiction correcte. Nous pouvons l'utiliser pour comprendre le compromis entre les faux positifs (en haut à droite) et les faux négatifs (en bas à gauche). Nous pouvons tracer la matrice de confusion à l'aide de ce code :
# Generate predictions with the best model
y_pred = best_rf.predict(X_test)
# Create the confusion matrix
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(confusion_matrix=cm).plot();Sortie :
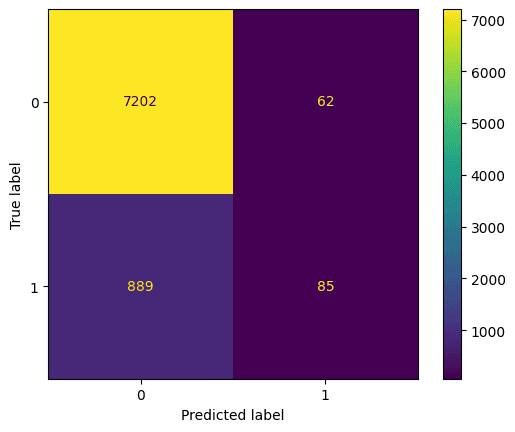
Évaluation d'un classificateur de forêt aléatoire à l'aide d'une matrice de confusion. Image par l'auteur
Nous devrions également évaluer le meilleur modèle en termes d'exactitude, de précision et de rappel (notez que vos résultats peuvent différer en raison de la randomisation).
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Sortie :
Accuracy: 0.885
Precision: 0.578
Recall: 0.0873Le code ci-dessous indique l'importance de chaque caractéristique, en utilisant le score interne du modèle pour trouver la meilleure façon de diviser les données dans chaque arbre de décision.
# Create a series containing feature importances from the model and feature names from the training data
feature_importances = pd.Series(best_rf.feature_importances_, index=X_train.columns).sort_values(ascending=False)
# Plot a simple bar chart
feature_importances.plot.bar();Cela nous indique que l'indice de confiance des consommateurs, au moment de l'appel, était le principal facteur permettant de prédire si la personne s'abonnait ou non.
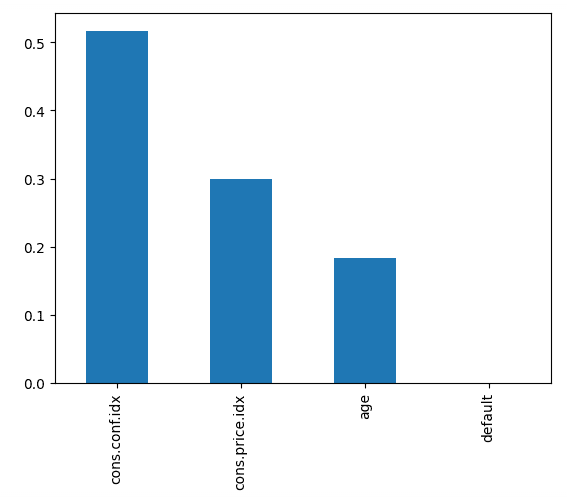
Les caractéristiques du classificateur de forêt aléatoire sont classées par ordre d'importance. Image par l'auteur
Pour commencer avec l'apprentissage automatique supervisé en Python, prenez Apprentissage supervisé avec scikit-learn. Pour en savoir plus sur l'utilisation des forêts aléatoires et d'autres modèles d'apprentissage automatique basés sur des arbres, consultez nos cours Machine Learning with Tree-Based Models in Python (Apprentissage automatique avec des modèles basés sur des arbres en Python ) et Ensemble Methods in Python (Méthodes d'ensemble en Python).
Cours Python
Cours
Cours
Cours
Tutoriel
DataCamp Team
Tutoriel
Abid Ali Awan
Tutoriel
Sejal Jaiswal
Tutoriel
Allan Ouko
Tutoriel
Derrick Mwiti
Tutoriel
Aditya Sharma
