
Program
Dasar-Dasar Bisnis Kecerdasan Buatan
12 Hr
Penggunaan large language models (LLM) di sistem lokal semakin populer berkat peningkatan privasi, kontrol, dan keandalannya. Terkadang, model-model ini bahkan bisa lebih akurat dan lebih cepat daripada ChatGPT.
Kami akan menunjukkan tujuh cara untuk menjalankan LLM secara lokal dengan akselerasi GPU di Windows 11, namun metode yang kami bahas juga berfungsi di macOS dan Linux.
Jika Anda ingin mempelajari LLM dari awal, tempat yang baik untuk memulai adalah kursus tentang Large Learning Models (LLMs).
Mari mulai dengan menelusuri kerangka LLM pertama kita.
Ollama adalah ekosistem utama untuk menjalankan LLM seperti Llama 4, Mistral 3, dan Gemma 3 secara lokal.
Selain itu, banyak aplikasi menerima integrasi Ollama, yang menjadikannya alat yang sangat baik untuk akses model bahasa yang lebih cepat dan mudah di mesin lokal kita.
Ollama kini menawarkan kompatibilitas penuh dengan OpenAI API, menjadikannya pengganti langsung untuk layanan cloud OpenAI. Fitur terbaru mencakup function calling, keluaran JSON terstruktur, Flash Attention untuk model visi, dan inferensi 30% lebih cepat pada Apple Silicon dan GPU AMD.
Kita dapat mengunduh Ollama dari halaman unduhan.
Setelah kita memasangnya (menggunakan pengaturan default), logo Ollama akan muncul di system tray.
Kita dapat mengunduh model Llama 3 dengan mengetik perintah terminal berikut:
$ ollama run llama3Llama 3 sekarang siap digunakan! Di bawah ini, kita melihat daftar perintah yang perlu digunakan jika ingin memakai LLM lain:
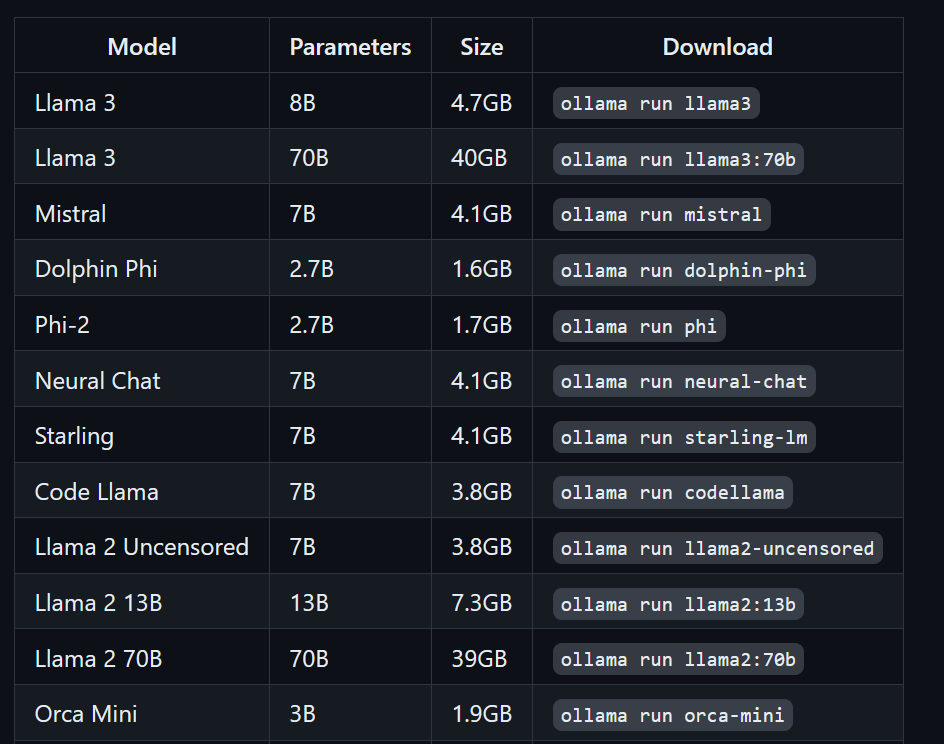
Untuk mengakses model yang sudah diunduh dan tersedia di folder llama.cpp, kita perlu:
cd.$ cd C:/Repository/GitHub/llama.cppModelfile dan menambahkan baris "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf".$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bDengan metode ini, kita dapat mengunduh LLM apa pun dari Hugging Face dengan ekstensi .gguf dan menggunakannya di terminal. Jika Anda ingin belajar lebih lanjut, lihat kursus Working with Hugging Face.
LM Studio adalah workbench serba guna untuk menjalankan LLM secara lokal dan menawarkan fine-tuning secara native. Selain itu, ia mendukung banyak model secara bersamaan, speculative decoding (token 1,5x–3x lebih cepat), dan integrasi dokumen RAG.
Kita dapat mengunduh penginstal dari beranda LM Studio.
Setelah pengunduhan selesai, kita memasang aplikasinya dengan opsi default.
Terakhir, luncurkan LM Studio!
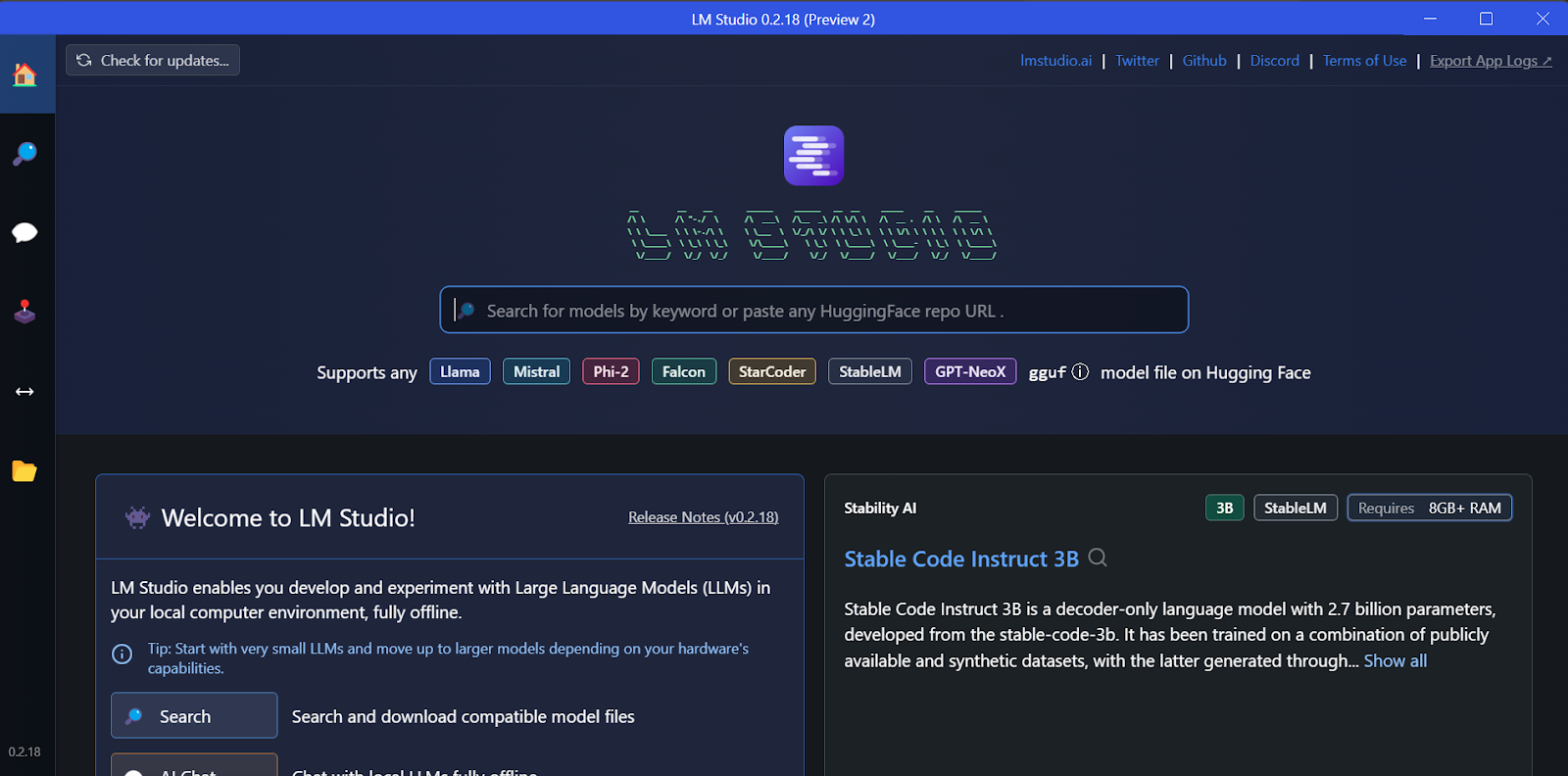
Kita dapat mengunduh model apa pun dari Hugging Face menggunakan fungsi pencarian.
Dalam kasus kami, kami akan mengunduh model terkecil, Gemma 2B Instruct dari Google.
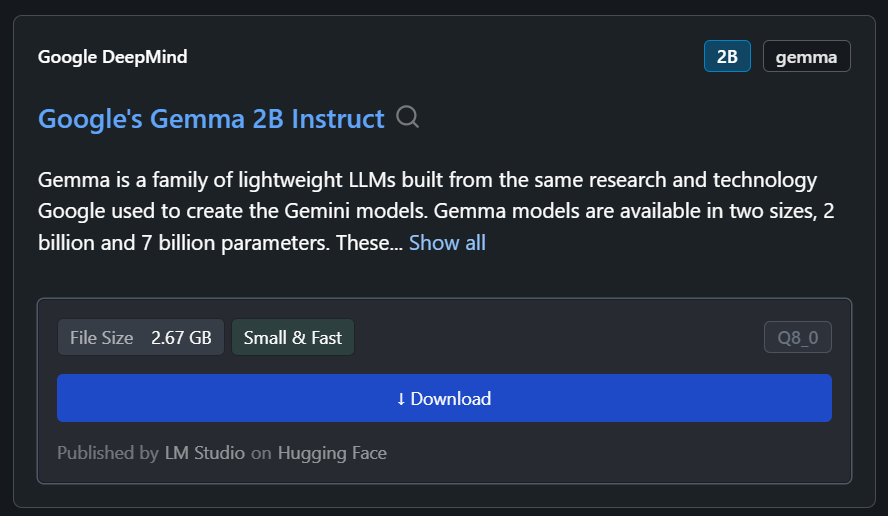
Kita dapat memilih model yang diunduh dari menu drop-down di bagian atas dan mengobrol seperti biasa. LM Studio menawarkan lebih banyak opsi penyesuaian dibandingkan GPT4All.
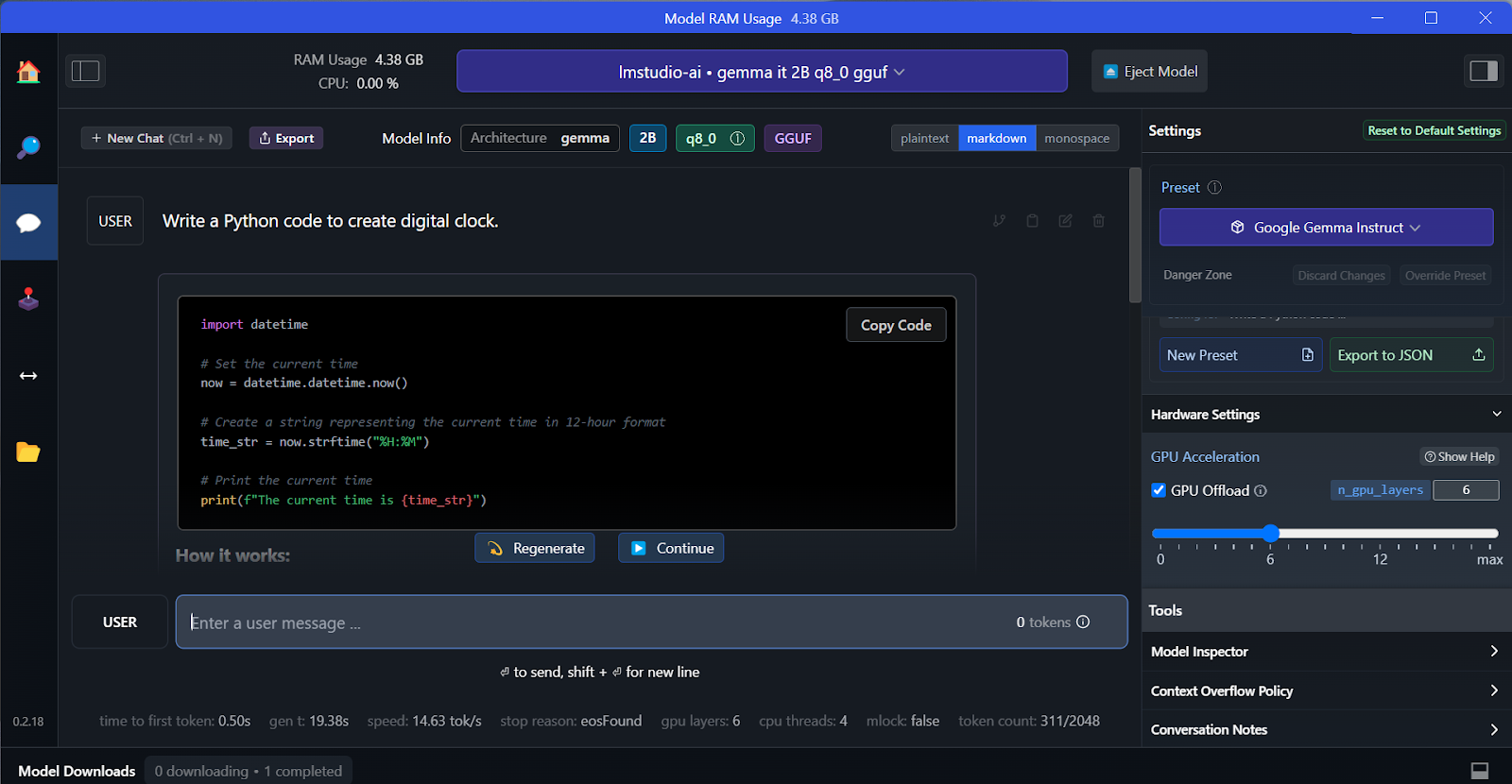
Seperti GPT4All, kita dapat menyesuaikan model dan meluncurkan server API dengan satu klik. Untuk mengakses model, kita dapat menggunakan paket Python OpenAI API, CURL, atau langsung mengintegrasikannya dengan aplikasi apa pun.
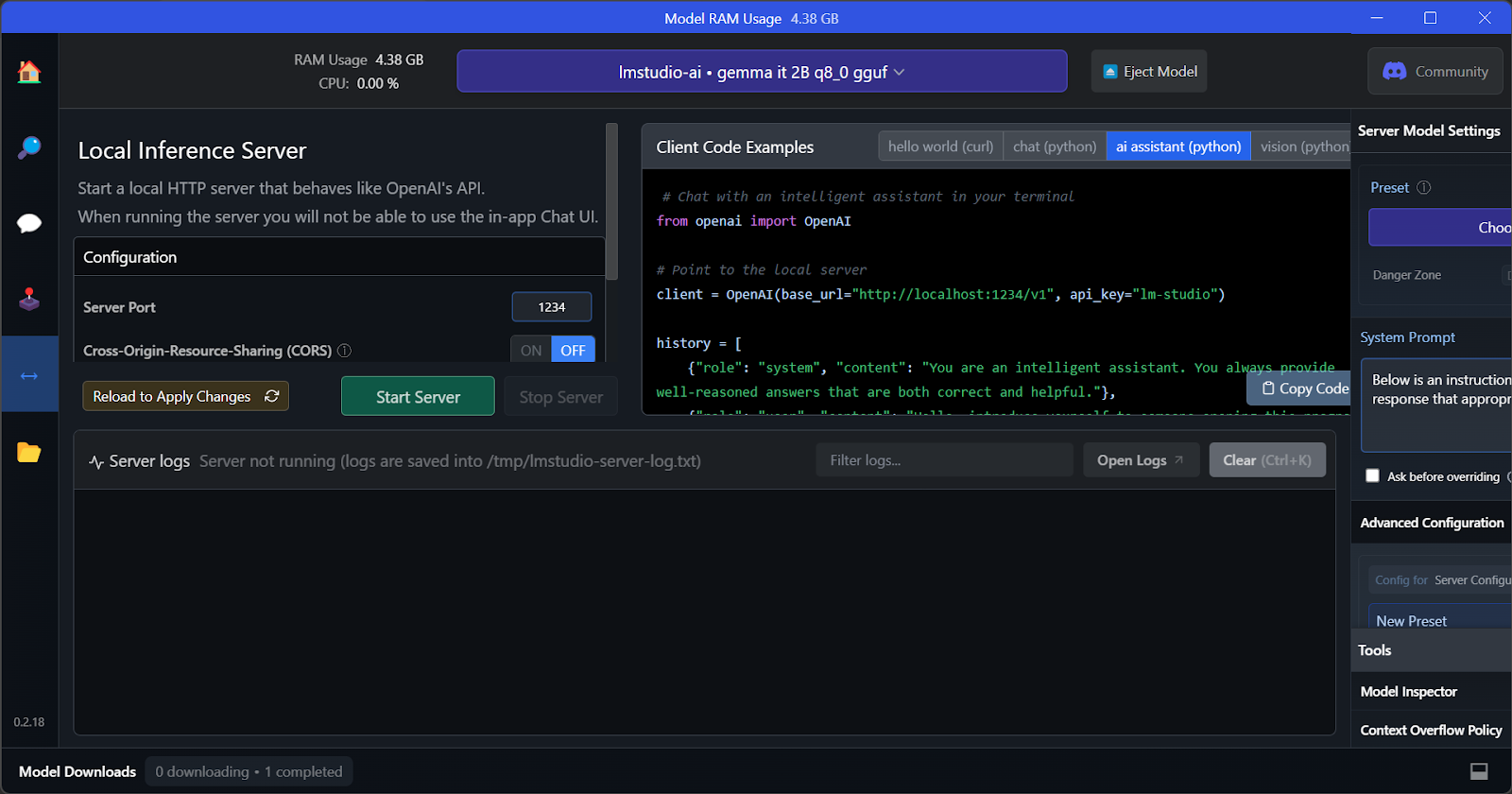
Fitur kunci LM Studio adalah menawarkan opsi untuk menjalankan dan melayani banyak model sekaligus. Ini memungkinkan pengguna membandingkan hasil model yang berbeda dan menggunakannya untuk banyak aplikasi. Untuk menjalankan beberapa sesi model, kita memerlukan VRAM GPU yang tinggi.
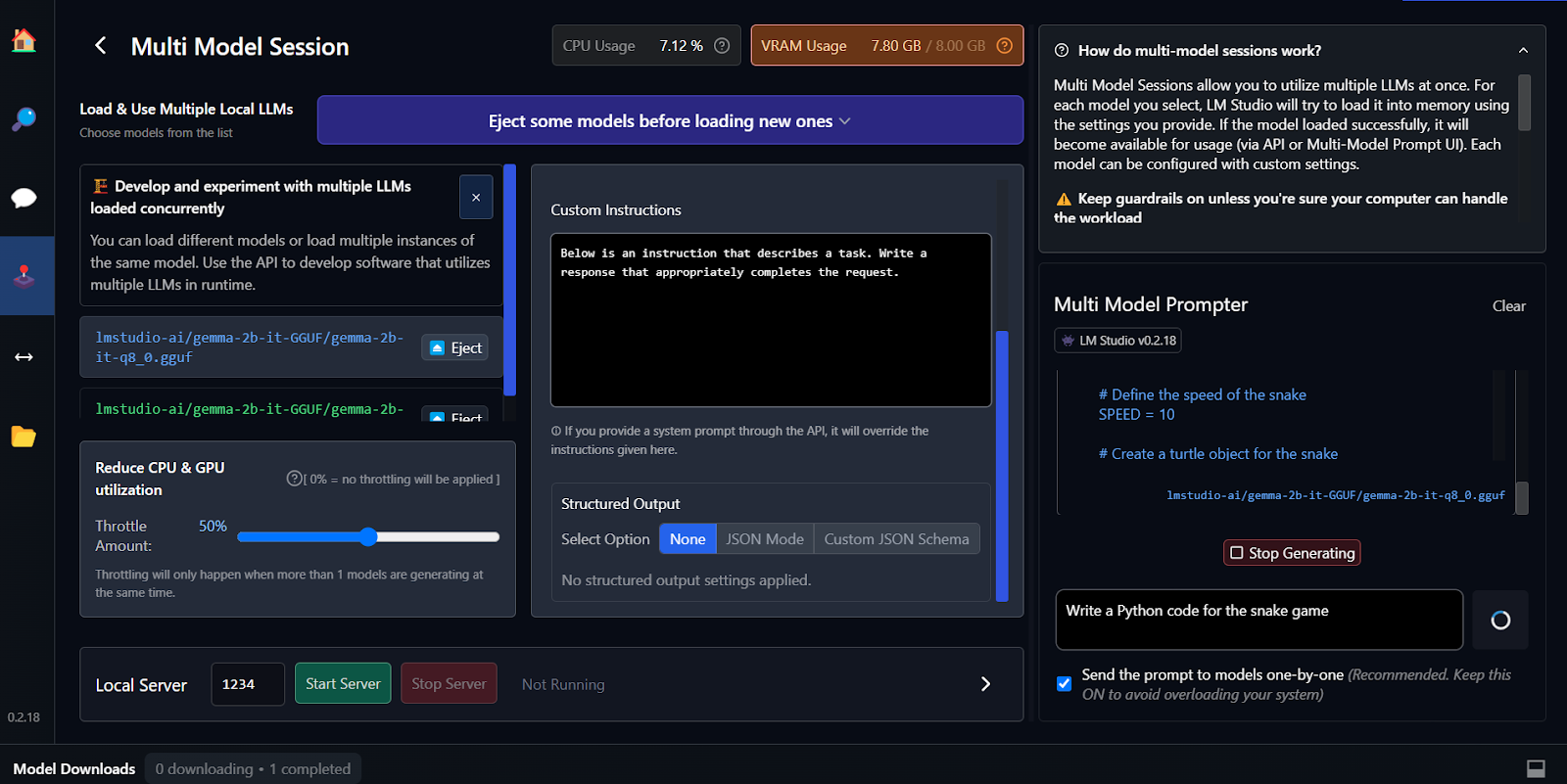
Fine-tuning adalah cara lain untuk menghasilkan respons yang kontekstual dan disesuaikan. Anda dapat mempelajari cara fine-tune model Google Gemma Anda dengan mengikuti tutorial Fine Tuning Google Gemma: Enhancing LLMs with Customized Instructions. Anda akan belajar menjalankan inferensi di GPU/TPU dan fine-tune model Gemma 7b-it terbaru pada dataset role-play.
vLLM adalah mesin inferensi open-source untuk menjalankan LLM dalam skala produksi. Berbeda dengan Ollama atau LM Studio, vLLM memprioritaskan throughput dan latensi untuk skenario multi-pengguna.
Inovasi intinya adalah PagedAttention, yang mengelola memori GPU seperti memori virtual, menggunakan kembali halaman kecil alih-alih memesan blok besar, dipadukan dengan continuous batching. Benchmark nyata menunjukkan vLLM menghasilkan 793 token per detik pada Llama 70B dibandingkan 41 token per detik pada Ollama di bawah beban konkuren.
vLLM juga mendukung tensor parallelism lintas GPU, prefix caching, dan multi-LoRA batching untuk melayani varian fine-tuned secara bersamaan.
Di Mac dan Linux, vLLM dapat dengan mudah dipasang menggunakan pip.
Di Linux dengan CUDA 11.8+:
pip install vllmDi macOS dengan Apple Silicon:
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmBelum ada dukungan resmi untuk Windows saat ini. Namun, tersedia solusi lewat WSL2 atau Docker.
Mulai server yang kompatibel dengan OpenAI:
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Untuk model 70B pada beberapa GPU:
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Untuk pemrosesan batch di Python:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Untuk melakukan kueri, gunakan SDK OpenAI:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Opsi lain adalah menjalankannya melalui cURL:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Pilih vLLM untuk API produksi yang melayani ratusan pengguna secara bersamaan; gunakan Ollama untuk pengembangan lokal.
Salah satu aplikasi LLM lokal yang paling populer dan tampak terbaik adalah Jan. Ini adalah alternatif yang mengutamakan privasi untuk ChatGPT.
Kita dapat mengunduh penginstal dari Jan.ai.
Setelah kita memasang aplikasi Jan dengan pengaturan default, kita siap meluncurkan aplikasi.
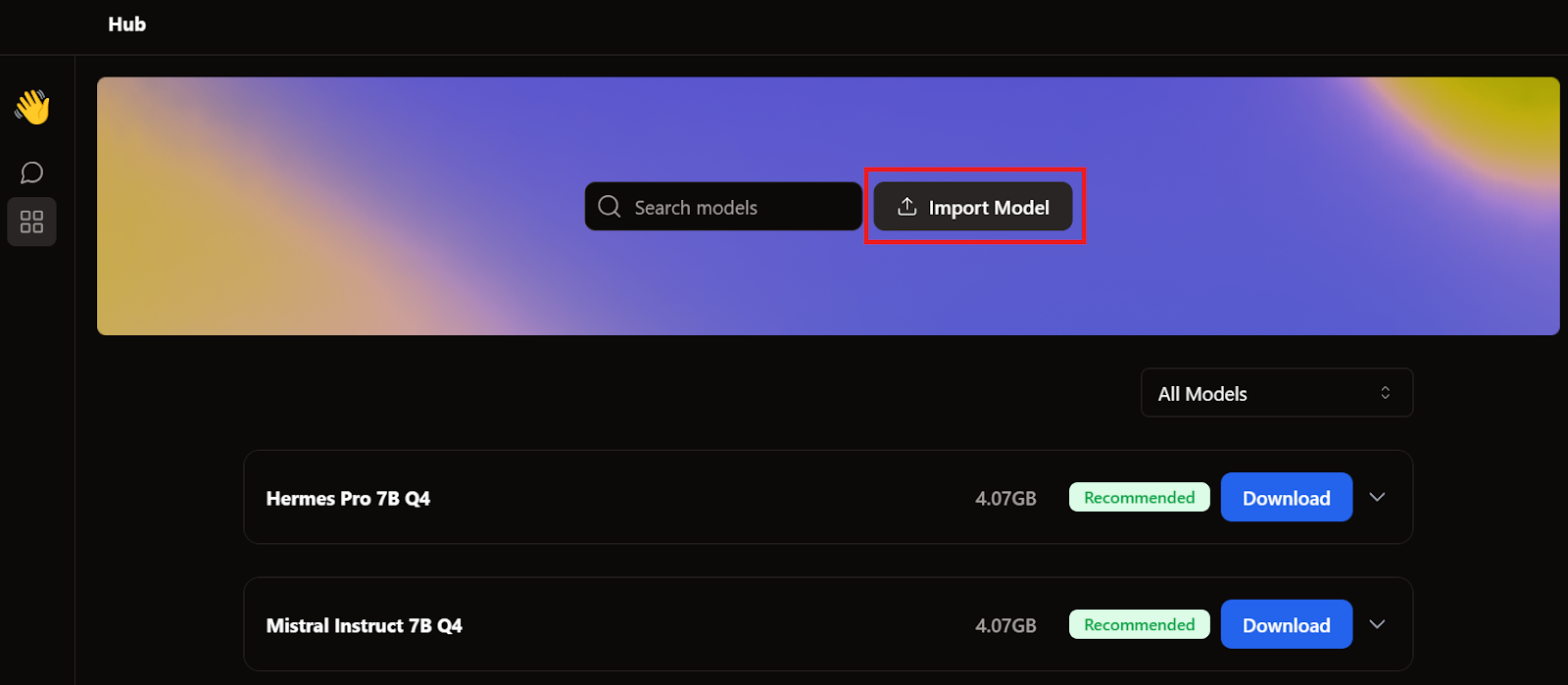
Saat membahas GPT4All dan LM Studio, kita sudah mengunduh dua model. Alih-alih mengunduh model lain, kita akan mengimpor yang sudah ada dengan pergi ke halaman model dan mengeklik tombol Import Model.
Lalu, kita menuju direktori aplikasi, memilih model GPT4All dan LM Studio, dan mengimpor masing-masing.
Untuk mengakses model lokal, kita pergi ke antarmuka pengguna chat dan membuka bagian model di panel kanan.
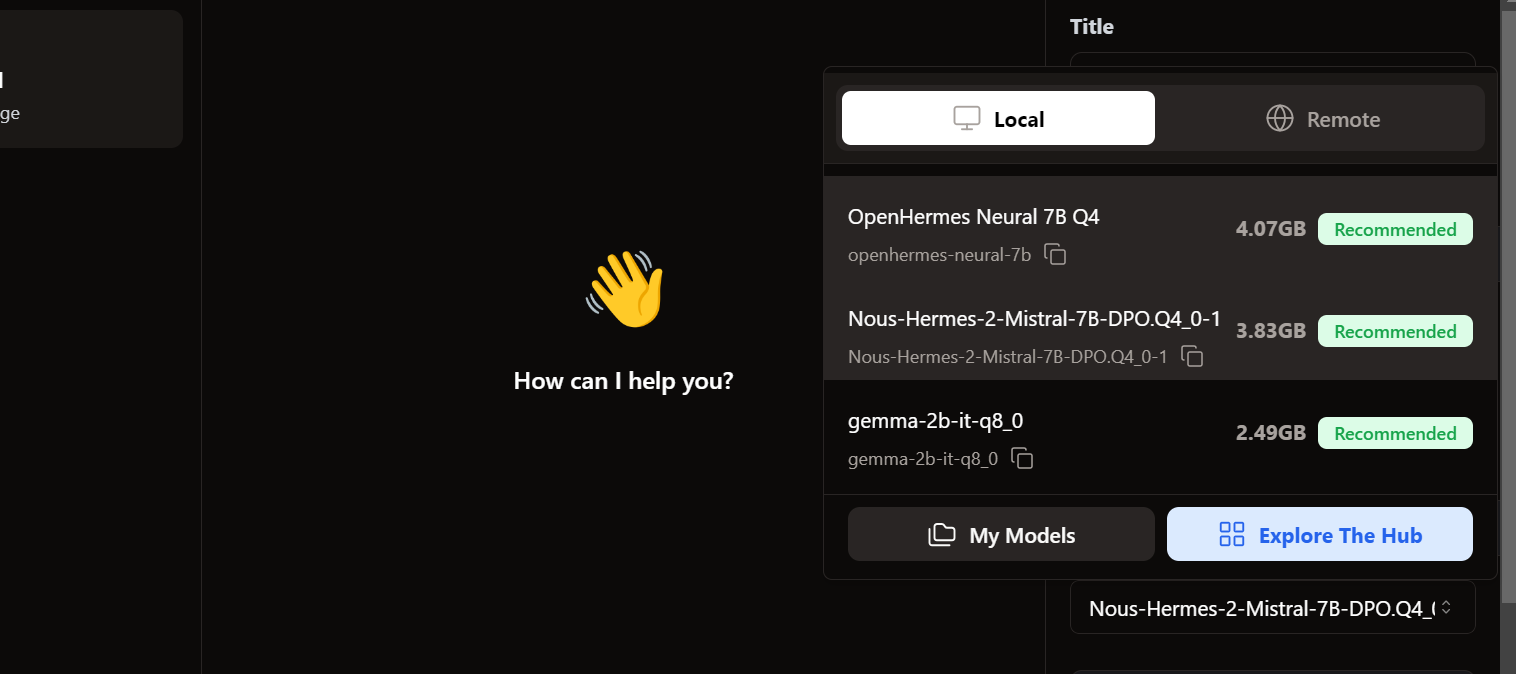
Kita melihat model yang diimpor sudah ada. Kita dapat memilih yang diinginkan dan langsung mulai menggunakannya!
Pembuatan respons sangat cepat. Antarmuka pengguna terasa alami, mirip ChatGPT, dan tidak memperlambat laptop atau PC Anda.
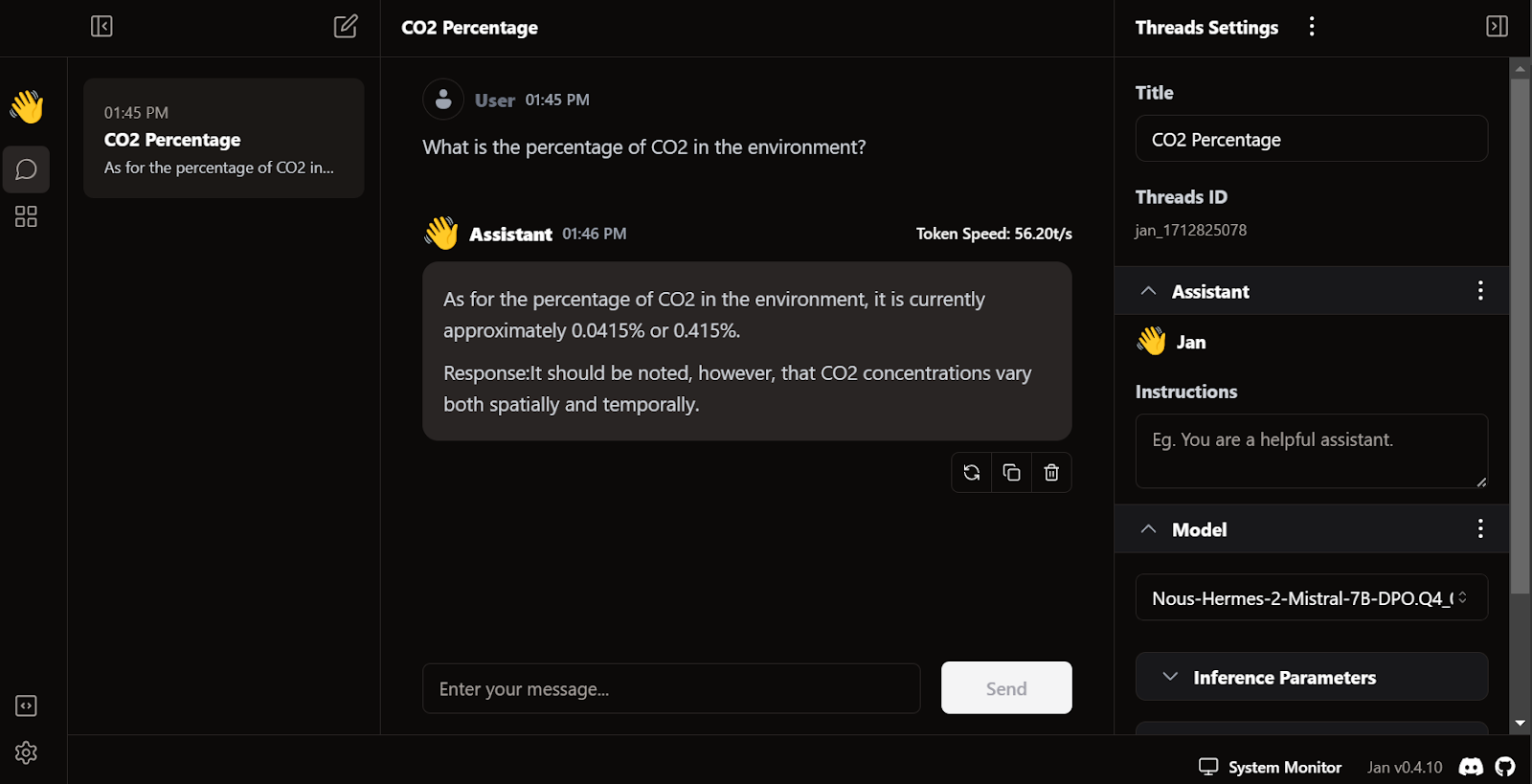
Fitur unik Jan adalah memungkinkan kita memasang ekstensi dan menggunakan model proprietari dari OpenAI, MistralAI, Groq, TensorRT, dan Triton RT.
Seperti LM Studio, kita juga dapat menggunakan Jan sebagai server API lokal. Ini menyediakan kemampuan logging yang lebih banyak dan kontrol atas respons LLM, dan mengintegrasikan OpenAI, Mistral AI, Groq, Claude, dan DeepSeek melalui penyiapan kunci API sederhana di pengaturan.
Kerangka LLM open-source populer lainnya adalah llama.cpp. Ini ditulis murni dalam C/C++, sehingga cepat dan efisien.
Banyak aplikasi AI lokal dan berbasis web dibangun di atas llama.cpp. Maka, mempelajarinya secara lokal akan memberi Anda keunggulan dalam memahami cara aplikasi LLM lain bekerja di balik layar.
Pertama, kita perlu masuk ke direktori proyek menggunakan perintah cd di shell—Anda dapat mempelajari lebih lanjut tentang terminal dalam kursus Introduction to Shell ini.
Lalu, kita mengkloning semua berkas dari server GitHub menggunakan perintah di bawah ini:
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitAlat baris perintah make tersedia secara default di Linux dan MacOS. Namun, untuk Windows, kita perlu melakukan langkah-langkah berikut:
$ cd C:/Repository/GitHub/llama.cpp untuk masuk ke folder llama.cpp.$ make dan tekan Enter untuk memasang llama.cpp.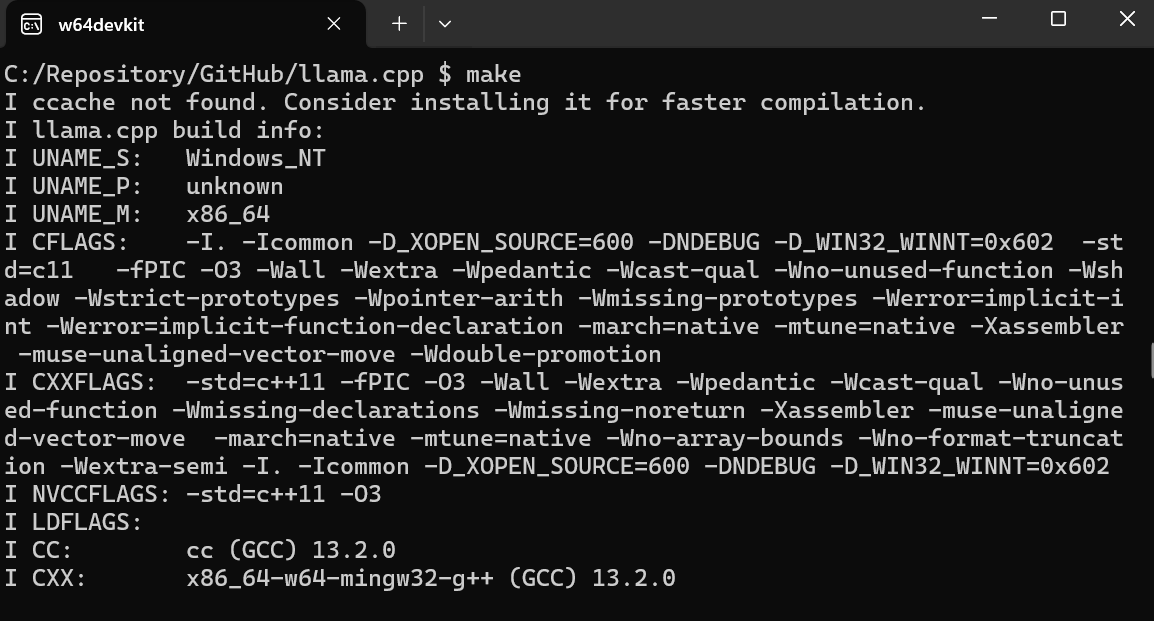
Setelah kita menyelesaikan instalasi, kita menjalankan server web UI llama.cpp dengan mengetik perintah di bawah ini. (Catatan: Kami telah menyalin berkas model dari folder GPT4All ke folder llama.cpp agar lebih mudah mengakses model).
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589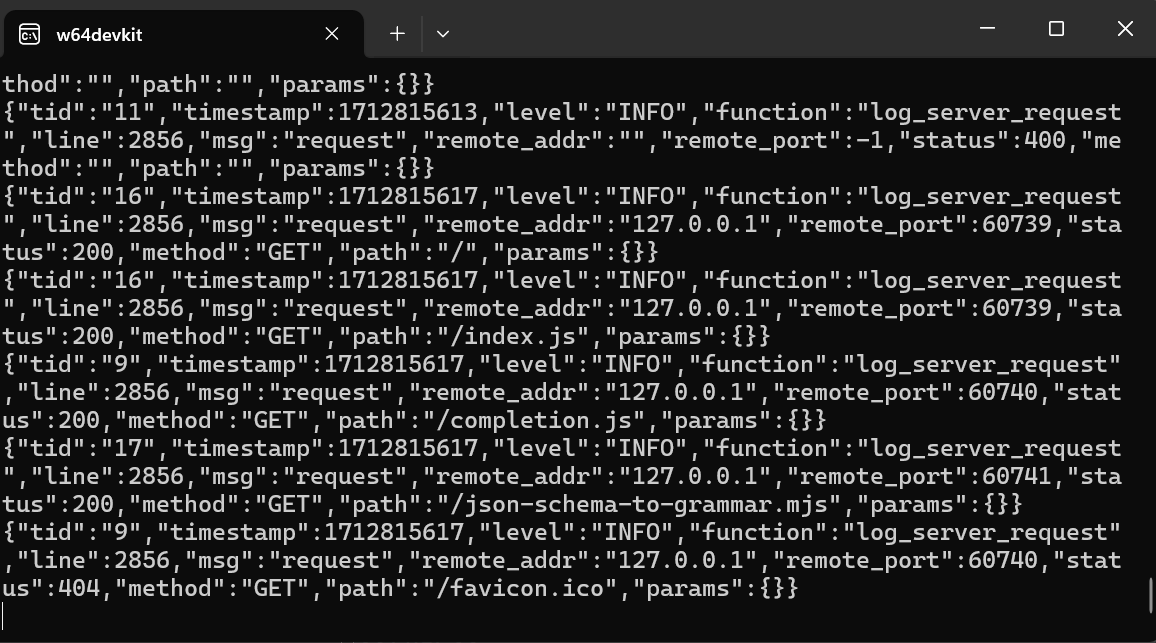
Server web berjalan di http://127.0.0.1:6589/. Anda dapat menyalin URL ini dan menempelkannya ke browser untuk mengakses antarmuka web llama.cpp.
Sebelum berinteraksi dengan chatbot, kita sebaiknya menyesuaikan pengaturan dan parameter model.
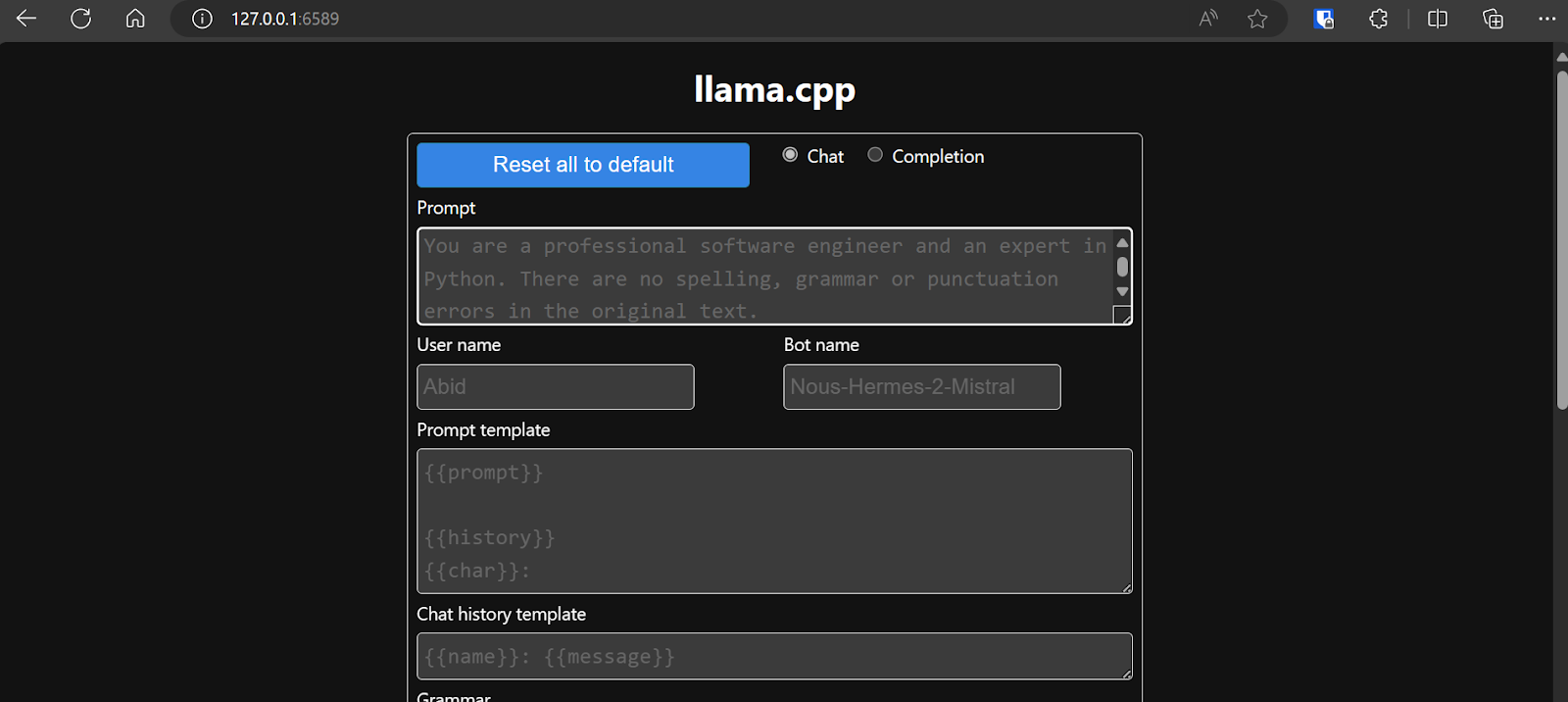 Lihat tutorial llama.cpp ini jika Anda ingin belajar lebih lanjut!
Lihat tutorial llama.cpp ini jika Anda ingin belajar lebih lanjut!
Pembuatan respons lambat karena kita menjalankannya di CPU, bukan GPU. Kita harus memasang versi llama.cpp yang berbeda untuk menjalankannya di GPU.
$ make LLAMA_CUDA=1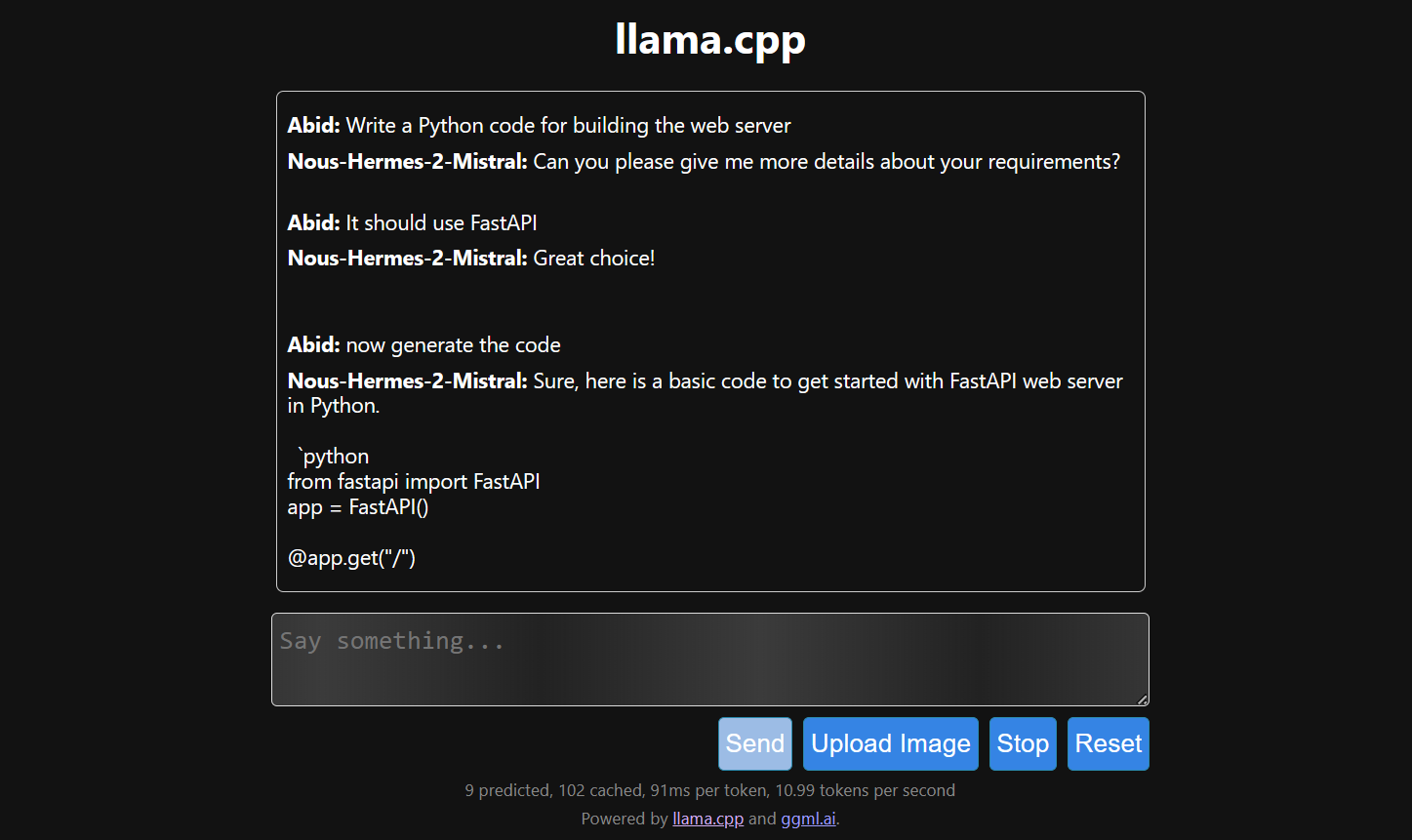
Jika Anda merasa llama.cpp agak terlalu kompleks, coba llamafile. Kerangka ini menyederhanakan LLM bagi pengembang dan pengguna akhir dengan menggabungkan llama.cpp dengan Cosmopolitan Libc menjadi executable satu berkas. Ini menghilangkan semua kerumitan terkait LLM, sehingga lebih mudah diakses.
Kita dapat mengunduh berkas model yang diinginkan dari repositori GitHub llamafile.
Kita akan mengunduh LLaVA 1.5 karena dapat memahami gambar juga.
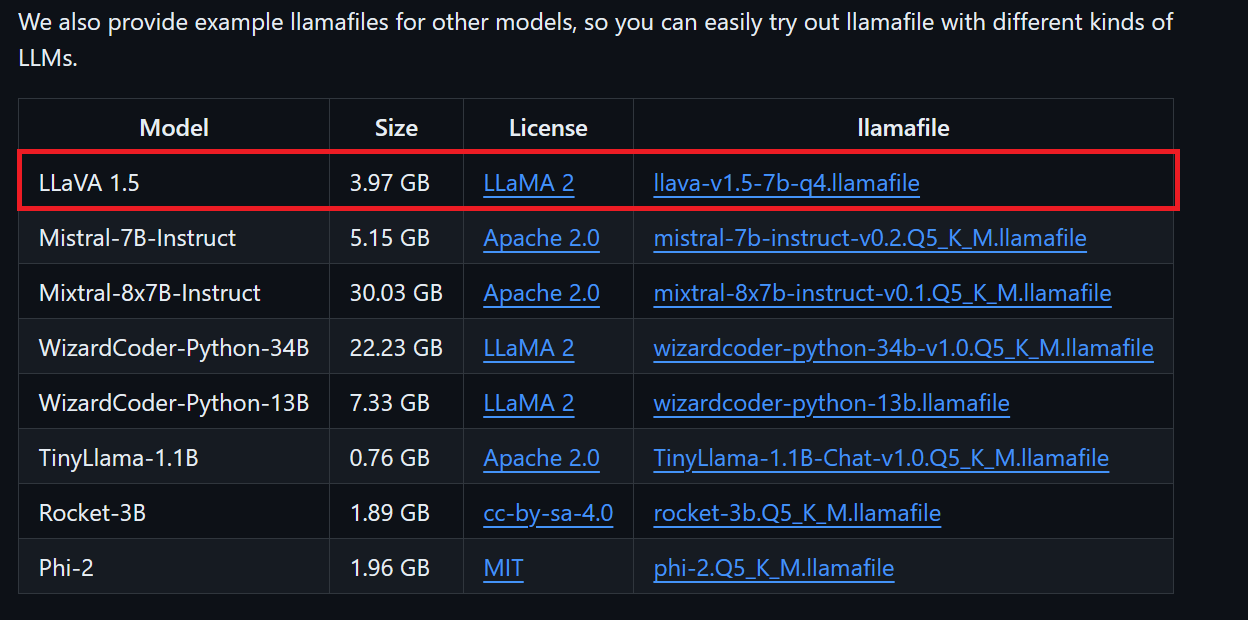
Pengguna Windows harus menambahkan .exe ke nama berkas di terminal. Untuk melakukannya, klik kanan berkas yang diunduh dan pilih Rename.

Pertama kita masuk ke direktori llamafile dengan perintah cd di terminal. Lalu, jalankan perintah di bawah untuk memulai server web llama.cpp.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999Server web menggunakan GPU tanpa mengharuskan Anda memasang atau mengonfigurasi apa pun.
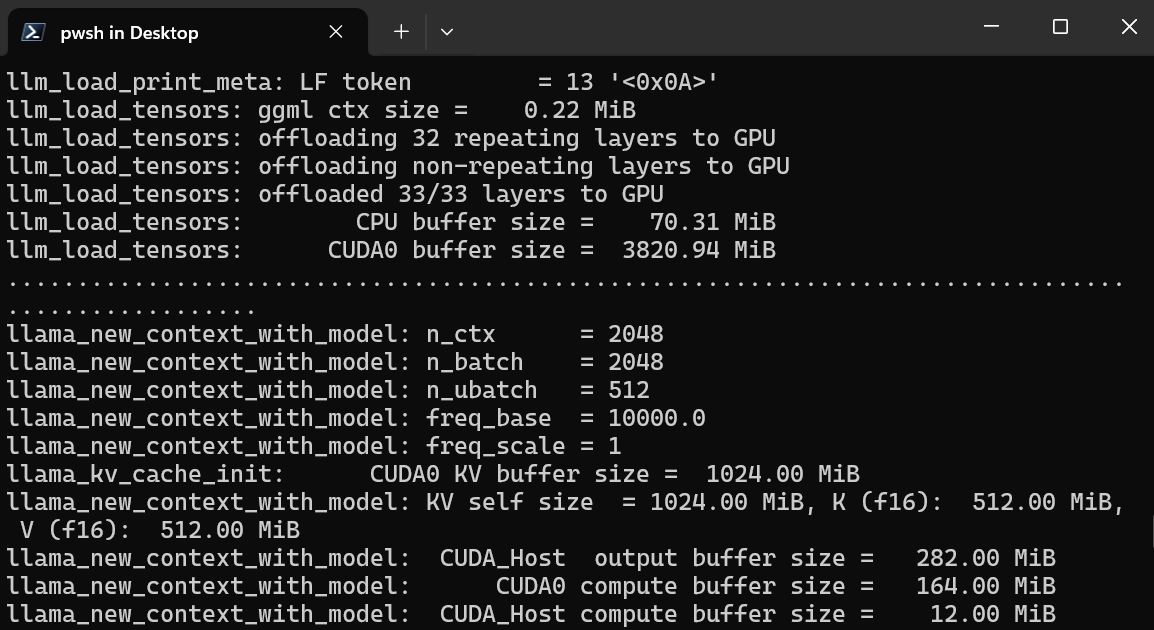
Ini juga akan otomatis meluncurkan browser web default dengan aplikasi web llama.cpp yang berjalan. Jika tidak, kita dapat menggunakan URL http://127.0.0.1:8080/ untuk mengaksesnya langsung.
Setelah kita menetapkan konfigurasi model, kita dapat mulai menggunakan aplikasi web.
Menjalankan llama.cpp menggunakan llamafile lebih mudah dan lebih efisien. Kami menghasilkan respons dengan 53,18 token/detik (tanpa llamafile, kecepatannya 10,99 token/detik).
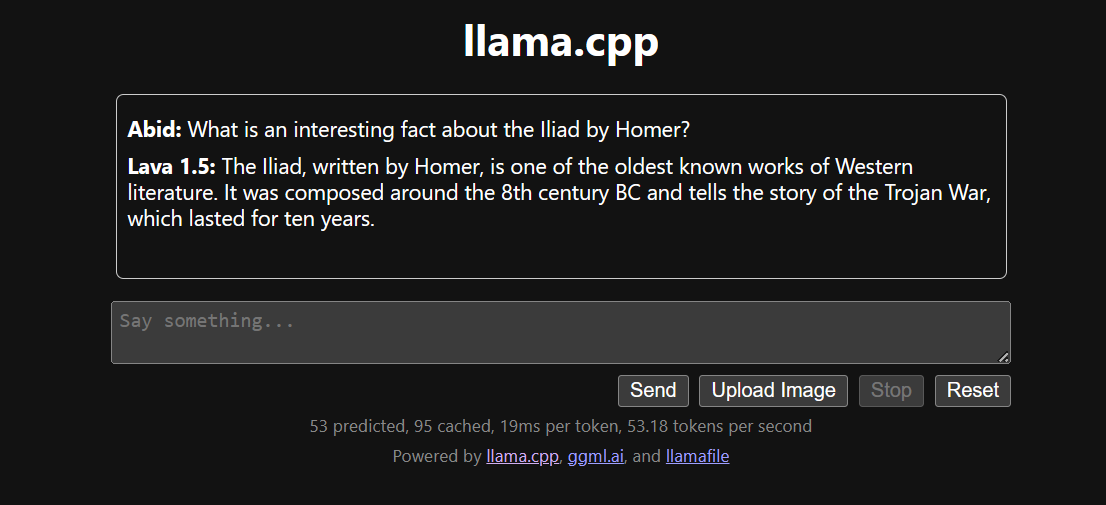
Menginstal dan menggunakan LLM secara lokal bisa menjadi pengalaman yang menyenangkan dan menarik. Kita dapat bereksperimen dengan model open-source terbaru sendiri, menikmati privasi, kontrol, dan pengalaman chat yang lebih baik.
Menggunakan LLM secara lokal juga memiliki aplikasi praktis, seperti mengintegrasikannya dengan aplikasi lain menggunakan server API dan menghubungkan folder lokal untuk memberikan respons yang peka konteks. Dalam beberapa kasus, sangat penting menggunakan LLM secara lokal, terutama ketika privasi dan keamanan merupakan faktor krusial.
Anda dapat mempelajari lebih lanjut tentang LLM dan membangun aplikasi AI dengan mengikuti sumber daya berikut:
Bangun karier AI Anda bersama DataCamp!
Program
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
