
Leerpad
Basisprincipes van AI-business
12 Hr
Grote taalmodellen (LLM’s) lokaal gebruiken wordt steeds populairder dankzij de betere privacy, controle en betrouwbaarheid. Soms zijn deze modellen zelfs nauwkeuriger en sneller dan ChatGPT.
We laten zeven manieren zien om LLM’s lokaal met GPU-versnelling op Windows 11 te draaien, maar de methoden die we bespreken werken ook op macOS en Linux.
Als je LLM’s vanaf nul wilt leren, is deze cursus over Large Learning Models (LLMs) een goed startpunt.
Laten we beginnen met ons eerste LLM-framework.
Ollama is het toonaangevende ecosysteem om LLM’s zoals Llama 4, Mistral 3 en Gemma 3 lokaal te draaien.
Bovendien ondersteunen meerdere applicaties een Ollama-integratie, wat het een uitstekende tool maakt voor snellere en makkelijkere toegang tot taalmodellen op je lokale machine.
Ollama biedt nu volledige compatibiliteit met de OpenAI API en is daarmee een drop-in vervanger voor de cloudservice van OpenAI. Recente features zijn onder andere function calling, gestructureerde JSON-output, Flash Attention voor vision-modellen en 30% snellere inferentie op Apple Silicon en AMD GPU’s.
Je kunt Ollama downloaden van de downloadpagina.
Zodra we het geïnstalleerd hebben (met de standaardinstellingen), verschijnt het Ollama-logo in het systeemvak.
We kunnen het Llama 3-model downloaden door de volgende terminalopdracht te typen:
$ ollama run llama3Llama 3 is nu klaar voor gebruik! Hieronder zie je een lijst met commando’s die we kunnen gebruiken als we andere LLM’s willen gebruiken:
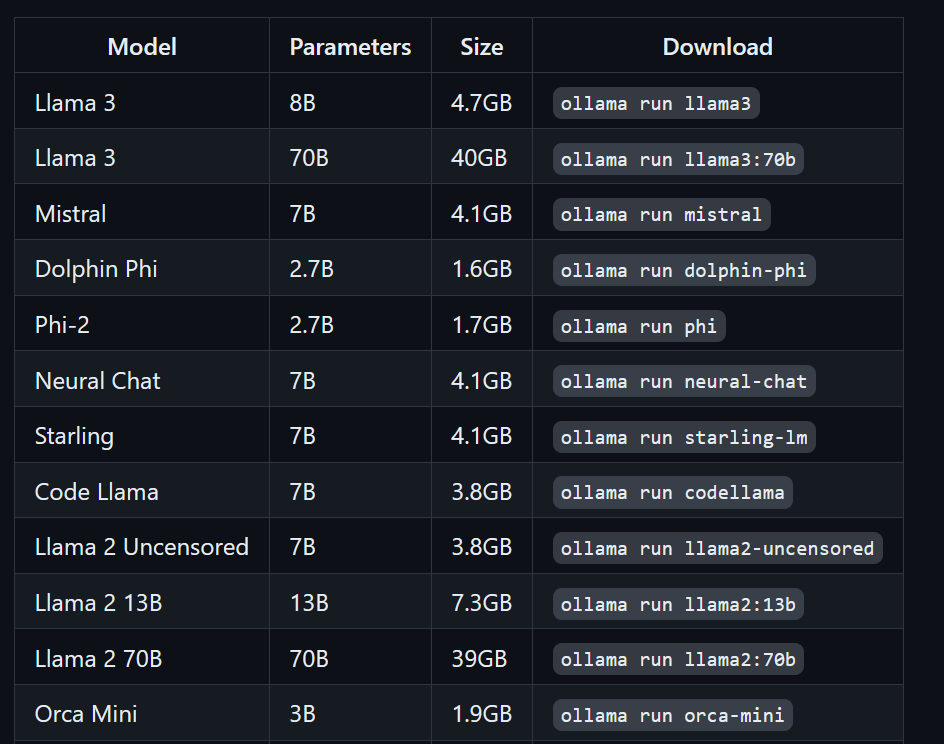
Om toegang te krijgen tot modellen die al zijn gedownload en beschikbaar zijn in de map llama.cpp, moeten we het volgende doen:
cd-commando.$ cd C:/Repository/GitHub/llama.cppModelfile aan en voeg de regel "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" toe.$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bMet deze methode kunnen we elk LLM met de extensie .gguf van Hugging Face downloaden en in de terminal gebruiken. Wil je meer leren, bekijk dan deze cursus over Working with Hugging Face.
LM Studio is een alles-in-één werkbank om LLM’s lokaal te draaien en biedt native fine-tuning. Daarnaast ondersteunt het meerdere gelijktijdige modellen, speculative decoding (1,5x–3x snellere tokens) en document-RAG-integratie.
We kunnen de installer downloaden vanaf de homepagina van LM Studio.
Zodra de download is voltooid, installeren we de app met de standaardopties.
Tot slot starten we LM Studio!
We kunnen elk model van Hugging Face downloaden via de zoekfunctie.
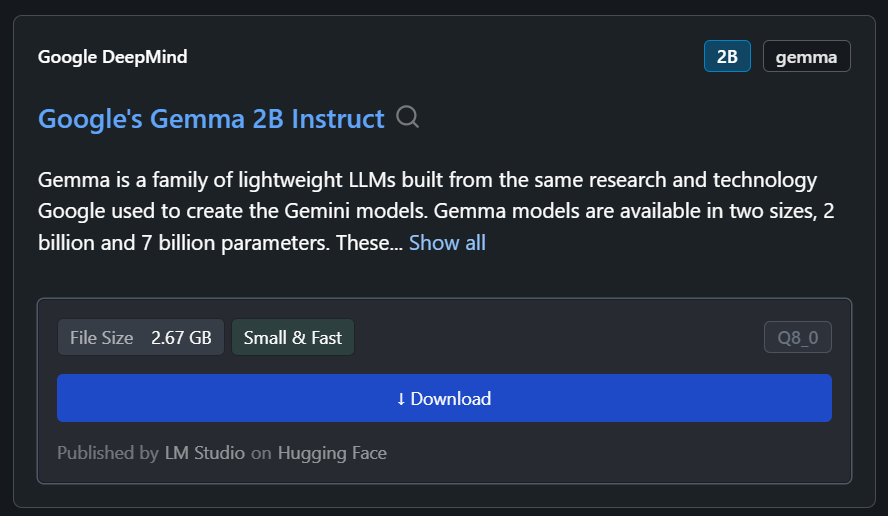
In ons geval downloaden we het kleinste model, Google’s Gemma 2B Instruct.
We kunnen het gedownloade model selecteren in het keuzemenu bovenaan en er zoals gebruikelijk mee chatten. LM Studio biedt meer aanpassingsopties dan GPT4All.
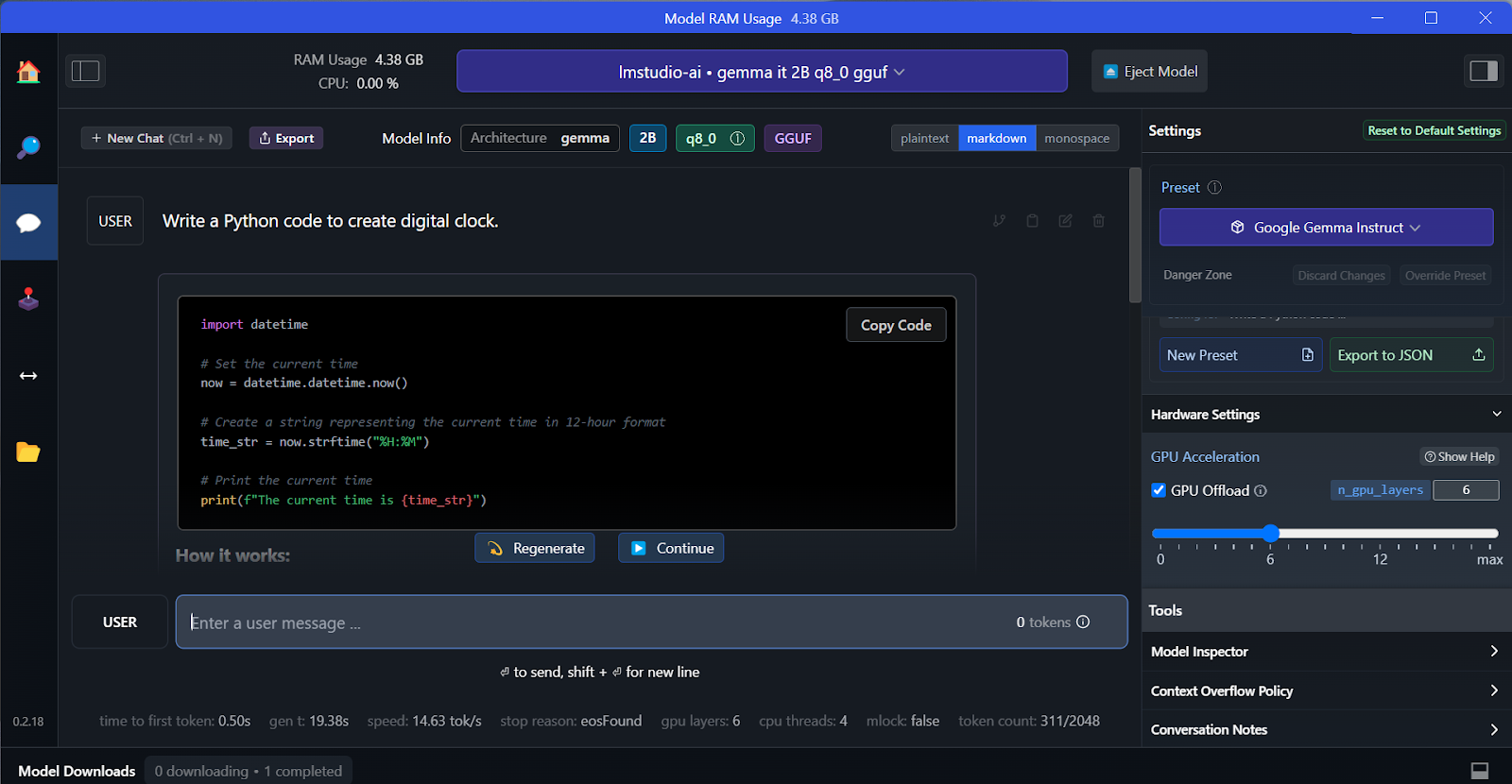
Net als GPT4All kunnen we het model aanpassen en met één klik de API-server starten. Om toegang te krijgen tot het model kunnen we het OpenAI API Python-pakket, CURL of directe integraties met elke applicatie gebruiken.
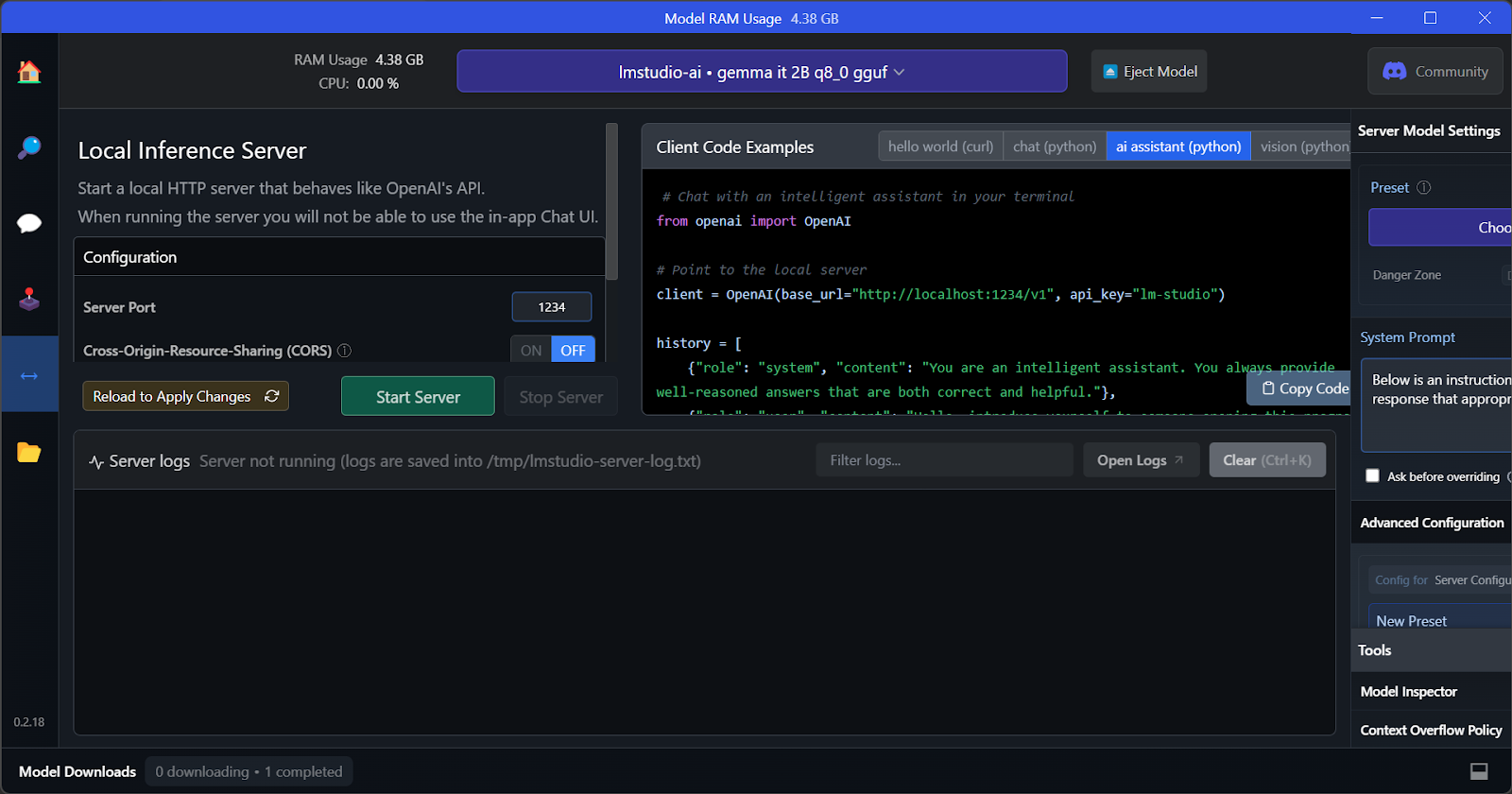
De belangrijkste feature van LM Studio is dat je meerdere modellen tegelijk kunt draaien en aanbieden. Hierdoor kunnen gebruikers verschillende modelresultaten vergelijken en ze voor meerdere applicaties inzetten. Om meerdere modelsessies te draaien, heb je veel GPU-VRAM nodig.
Fine-tuning is een andere manier om contextbewuste en aangepaste antwoorden te genereren. Je kunt leren hoe je je Google Gemma-model fine-tunet in de tutorial Fine Tuning Google Gemma: Enhancing LLMs with Customized Instructions. Je leert inferentie draaien op GPU’s/TPU’s en het nieuwste Gemma 7b-it-model fine-tunen op een roleplay-dataset.
vLLM is een open-source inferentie-engine om LLM’s op productieschaal te draaien. In tegenstelling tot Ollama of LM Studio geeft vLLM prioriteit aan throughput en latentie voor multi-user-scenario’s.
De kerninnovatie is PagedAttention, dat GPU-geheugen beheert als virtueel geheugen: het hergebruikt kleine pagina’s in plaats van enorme blokken te reserveren, gecombineerd met continue batching. Echte benchmarks laten zien dat vLLM 793 tokens per seconde levert op Llama 70B tegenover 41 tokens per seconde voor Ollama onder gelijktijdige belasting.
vLLM ondersteunt ook tensor-parallelisme over GPU’s, prefix caching en multi-LoRA-batching om meerdere fine-tunede varianten tegelijk te serveren.
Op Mac en Linux kan vLLM eenvoudig worden geïnstalleerd met pip.
Op Linux met CUDA 11.8+:
pip install vllmOp macOS met Apple Silicon:
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmEr is op dit moment geen officiële ondersteuning voor Windows. Er bestaan echter workarounds via WSL2 of Docker.
Start de OpenAI-compatibele server:
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Voor 70B-modellen op meerdere GPU’s:
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Voor batchverwerking in Python:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Om te query’en, gebruik de OpenAI SDK:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Een andere optie is om het via cURL te draaien:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Kies vLLM voor productie-API’s met honderden gelijktijdige gebruikers; gebruik Ollama voor lokale ontwikkeling.
Een van de populairste en mooist ogende lokale LLM-applicaties is Jan. Het is een privacy-first alternatief voor ChatGPT.
We kunnen de installer downloaden van Jan.ai.
Zodra we de Jan-app met de standaardinstellingen installeren, kunnen we de applicatie starten.
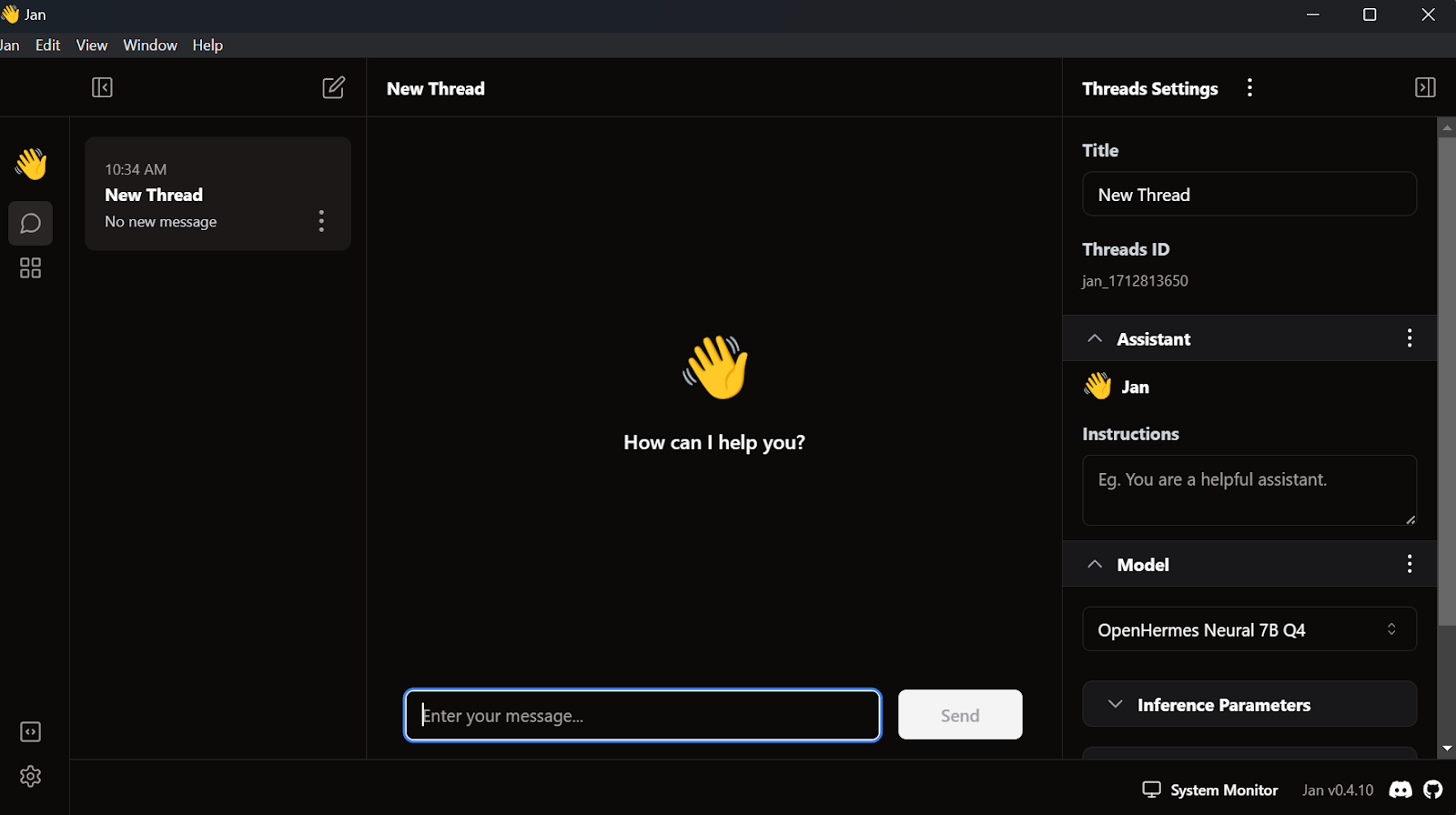
Bij GPT4All en LM Studio hebben we al twee modellen gedownload. In plaats van er nog een te downloaden, importeren we degene die we al hebben door naar de modelpagina te gaan en op de knop Import Model te klikken.
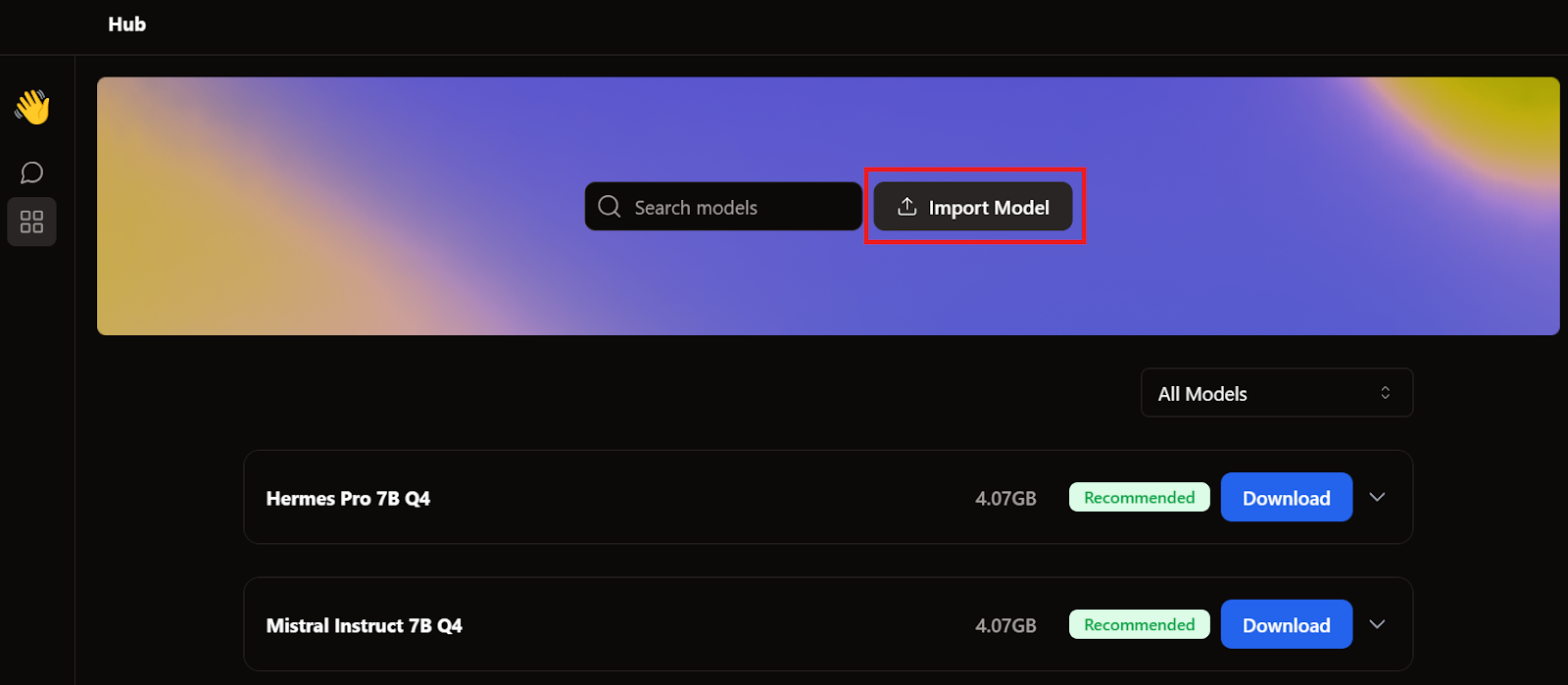
Ga daarna naar de applicatiemap, selecteer de GPT4All- en LM Studio-modellen en importeer ze allebei.
Om toegang te krijgen tot de lokale modellen, ga je naar de chatinterface en open je het modelgedeelte in het rechterpaneel.
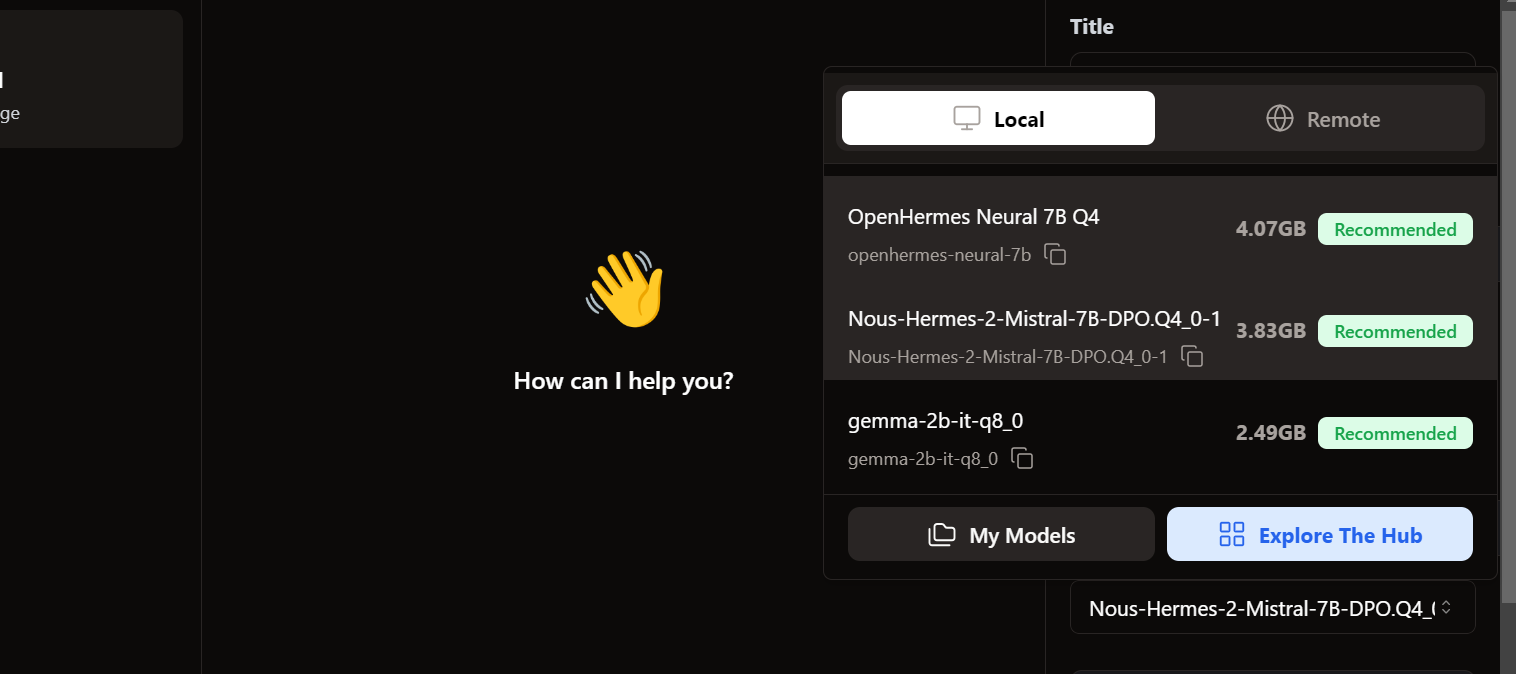
We zien dat onze geïmporteerde modellen al aanwezig zijn. We kunnen degene kiezen die we willen en er meteen mee aan de slag gaan!
Het genereren van antwoorden gaat erg snel. De gebruikersinterface voelt natuurlijk aan, vergelijkbaar met ChatGPT, en vertraagt je laptop of pc niet.
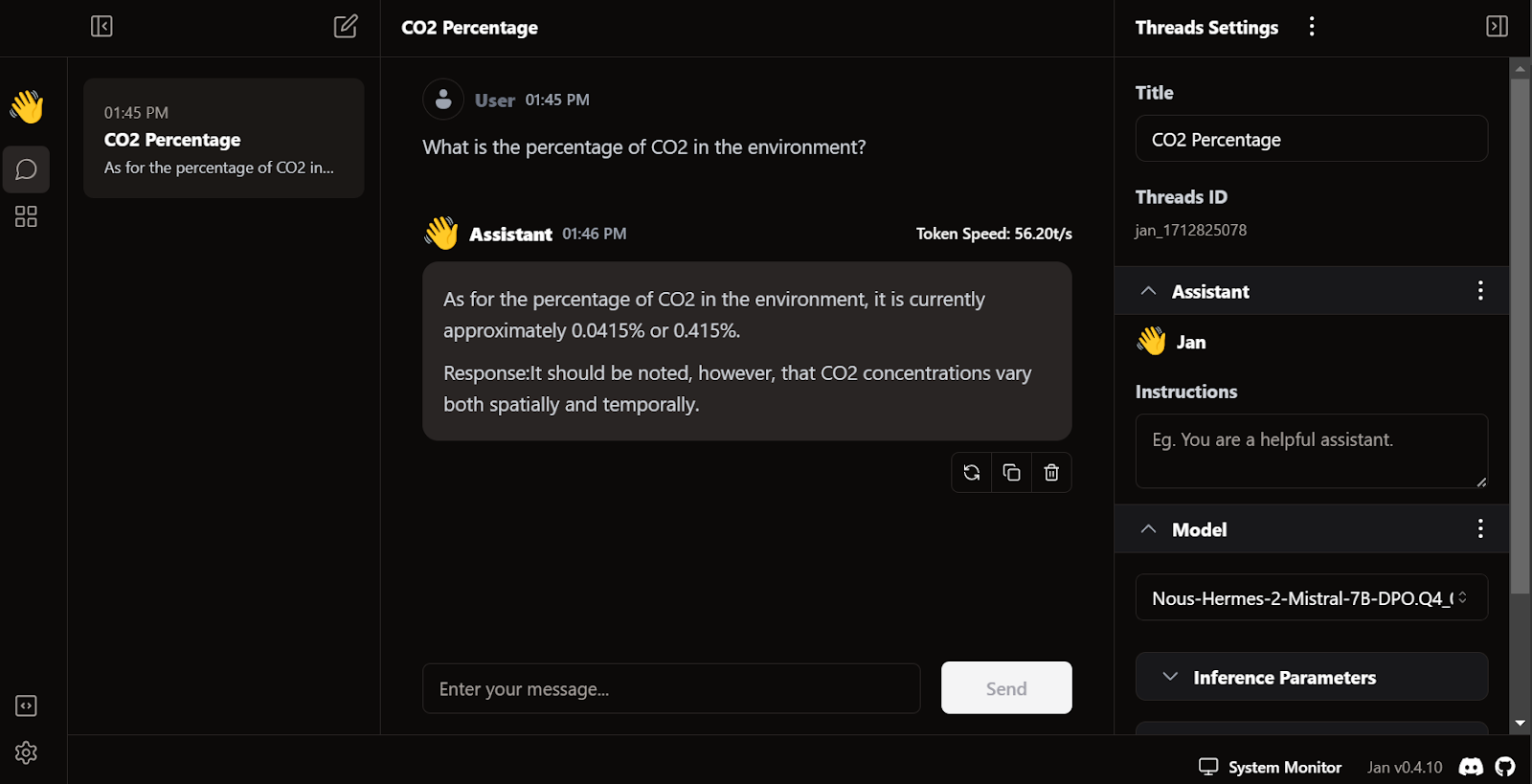
Een unieke feature van Jan is dat je extensies kunt installeren en proprietaire modellen van OpenAI, MistralAI, Groq, TensorRT en Triton RT kunt gebruiken.
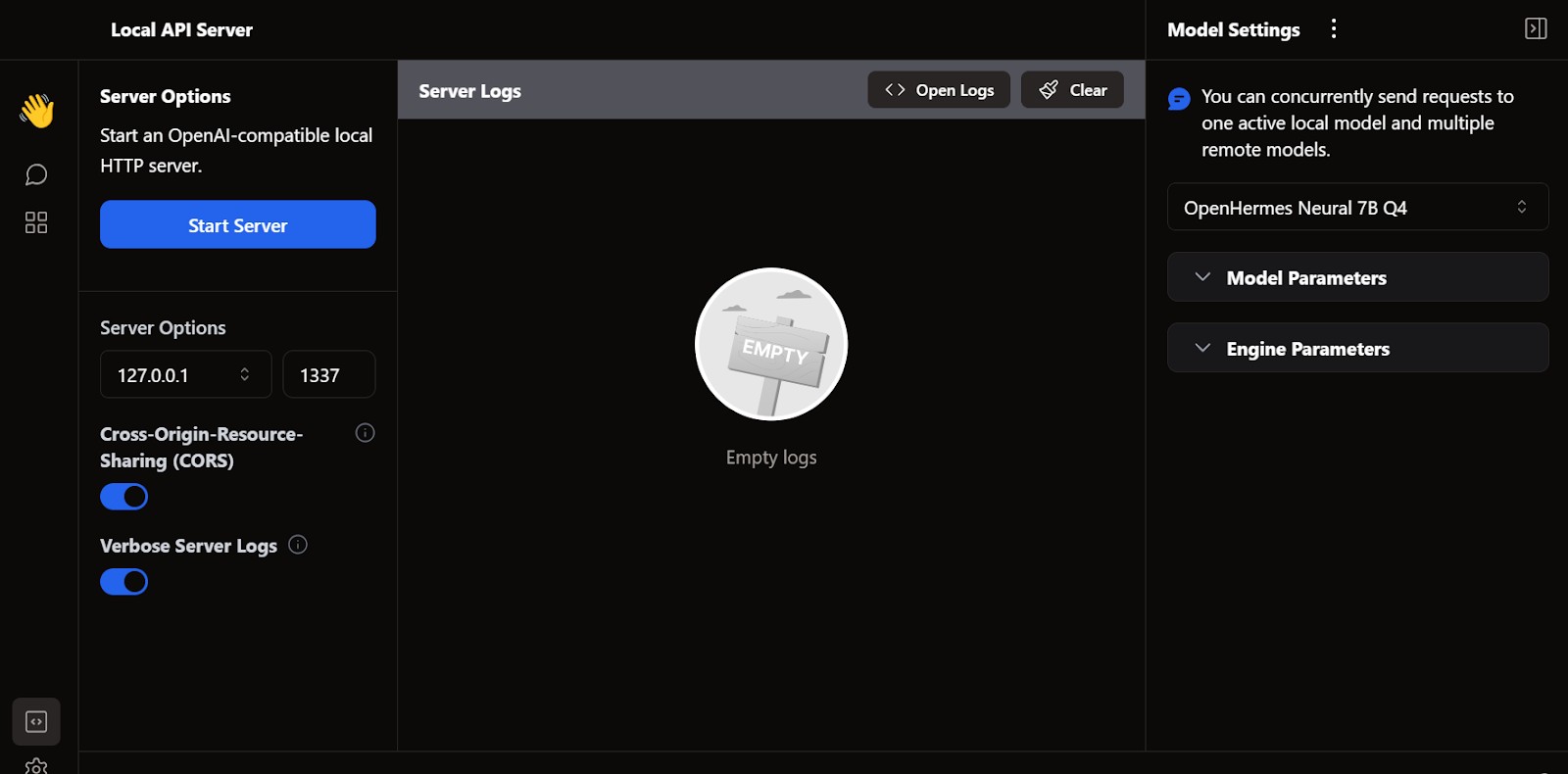
Net als LM Studio kunnen we Jan ook gebruiken als lokale API-server. Het biedt meer logmogelijkheden en controle over het LLM-antwoord, en integreert OpenAI, Mistral AI, Groq, Claude en DeepSeek via een eenvoudige API-sleutelconfiguratie in de instellingen.
Een ander populair open-source LLM-framework is llama.cpp. Het is volledig in C/C++ geschreven, wat het snel en efficiënt maakt.
Veel lokale en webgebaseerde AI-applicaties zijn gebaseerd op llama.cpp. Het lokaal leren gebruiken geeft je dus een voorsprong in het begrijpen van hoe andere LLM-applicaties onder de motorkap werken.
Eerst moeten we naar onze projectmap gaan met het cd-commando in de shell—meer over de terminal leer je in deze cursus Introduction to Shell.
Vervolgens klonen we alle bestanden van de GitHub-server met het onderstaande commando:
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitDe commandlinetool make is standaard beschikbaar in Linux en macOS. Voor Windows moeten we echter de volgende stappen nemen:
$ cd C:/Repository/GitHub/llama.cpp om naar de map llama.cpp te gaan.$ make en druk op Enter om llama.cpp te installeren.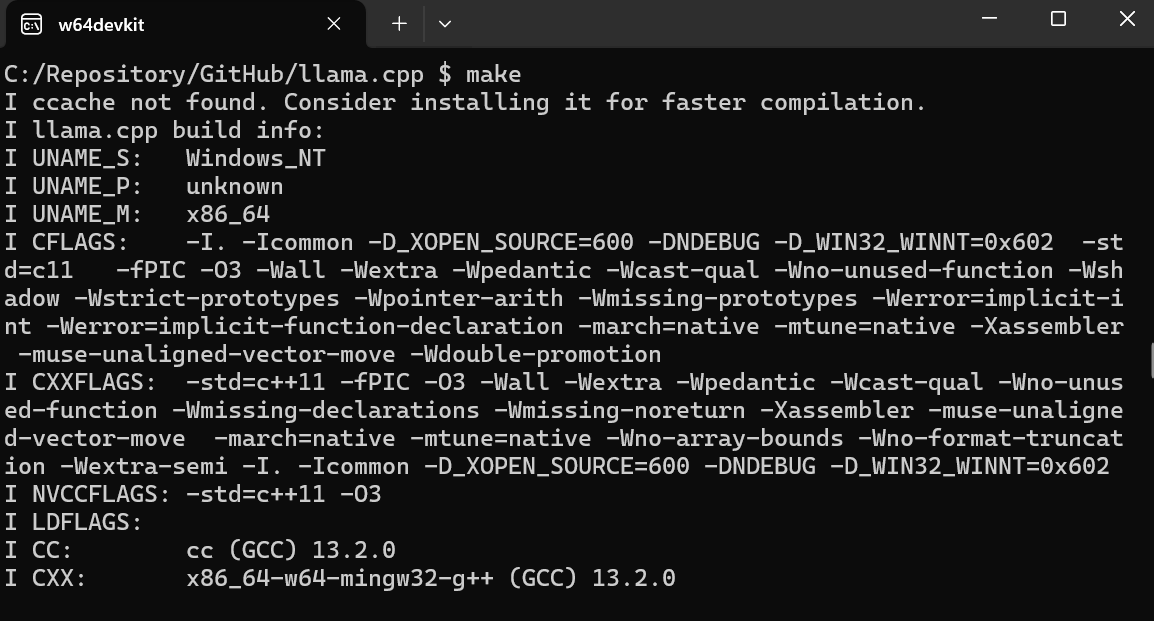
Na het voltooien van de installatie starten we de web-UI-server van llama.cpp door het onderstaande commando te typen. (Opmerking: we hebben het modelbestand van de GPT4All-map naar de llama.cpp-map gekopieerd zodat we er makkelijk bij kunnen.)
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589
De webserver draait op http://127.0.0.1:6589/. Je kunt deze URL kopiëren en in je browser plakken om de webinterface van llama.cpp te openen.
Voordat we met de chatbot interacteren, moeten we de instellingen en parameters van het model aanpassen.
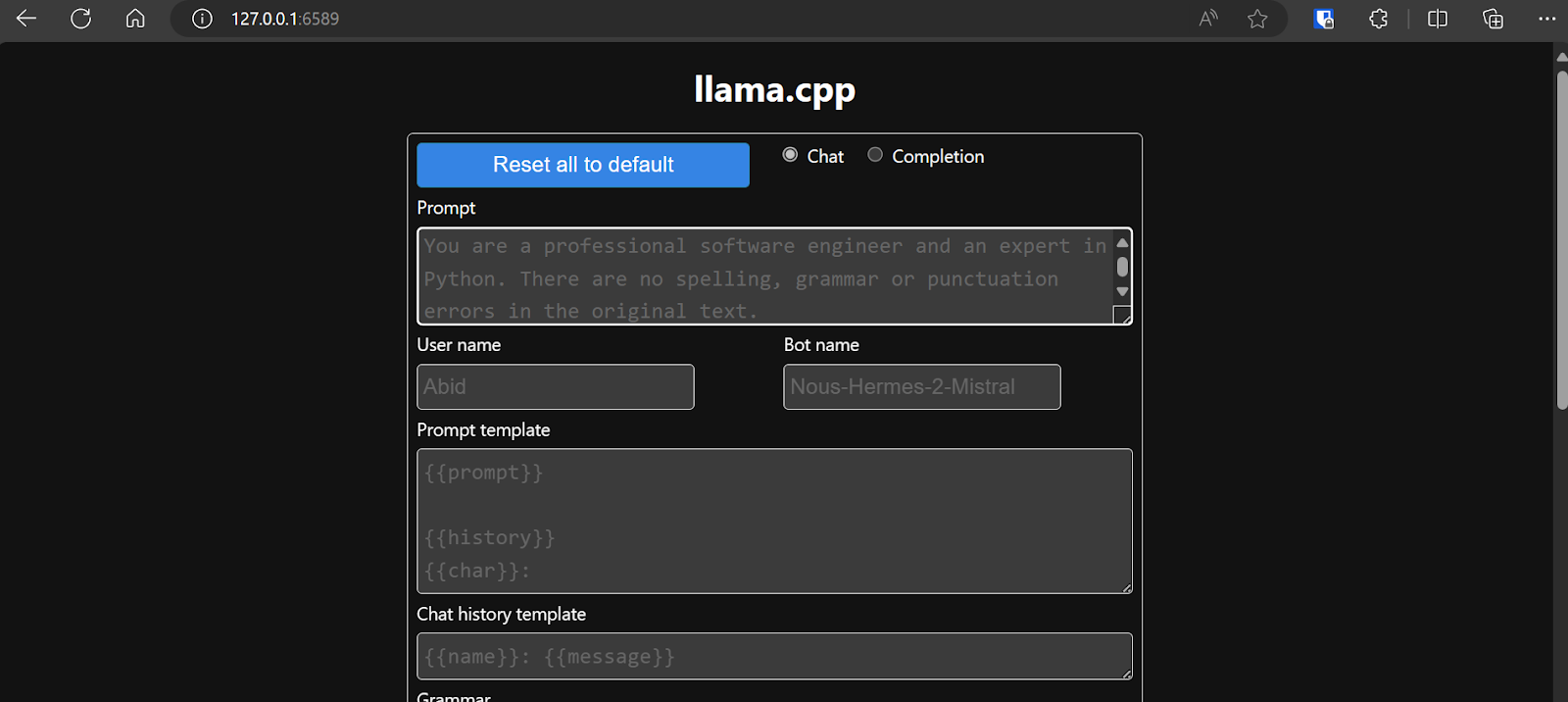 Bekijk deze llama.cpp-tutorial als je meer wilt leren!
Bekijk deze llama.cpp-tutorial als je meer wilt leren!
Het genereren van antwoorden is traag omdat we het op de CPU draaien en niet op de GPU. We moeten een andere versie van llama.cpp installeren om het op de GPU te draaien.
$ make LLAMA_CUDA=1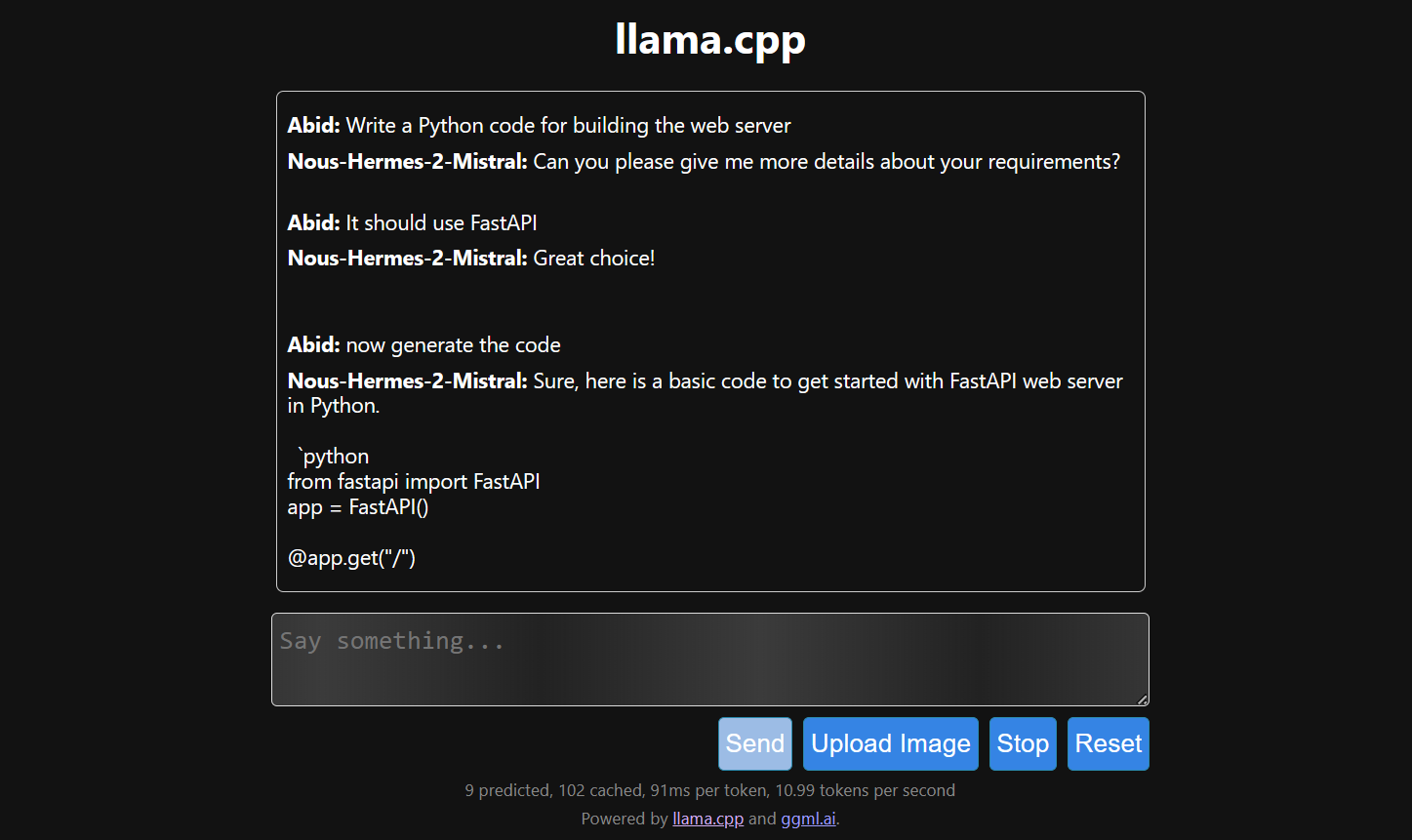
Vind je llama.cpp net iets te complex, probeer dan llamafile. Dit framework vereenvoudigt LLM’s voor zowel ontwikkelaars als eindgebruikers door llama.cpp met Cosmopolitan Libc te combineren tot een uitvoerbaar bestand van één file. Het haalt alle complexiteit rond LLM’s weg en maakt ze toegankelijker.
We kunnen het gewenste modelbestand downloaden uit de GitHub-repository van llamafile.
We downloaden LLaVA 1.5 omdat dit model ook afbeeldingen kan begrijpen.
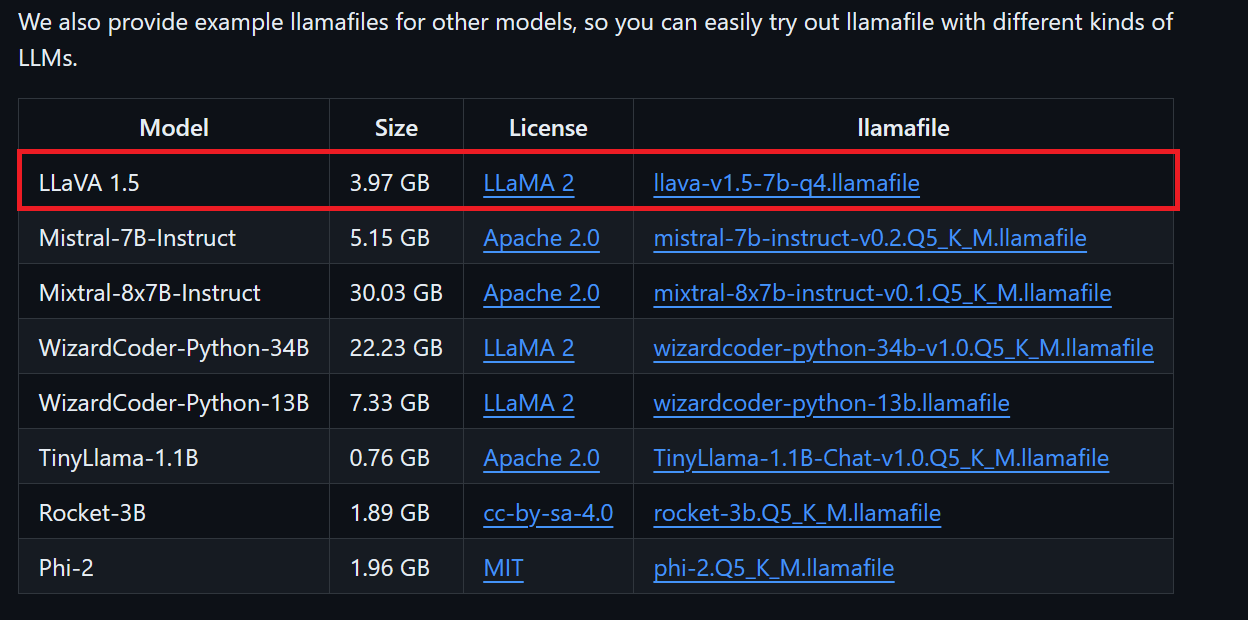
Windows-gebruikers moeten in de terminal .exe aan bestandsnamen toevoegen. Klik hiervoor met de rechtermuisknop op het gedownloade bestand en kies Rename.

We gaan eerst naar de llamafile-map met het cd-commando in de terminal. Vervolgens draaien we onderstaand commando om de webserver van llama.cpp te starten.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999De webserver gebruikt de GPU zonder dat je iets hoeft te installeren of configureren.
Hij start ook automatisch de standaardwebbrowser met de llama.cpp-webapp. Als dat niet gebeurt, kun je de URL http://127.0.0.1:8080/ gebruiken om er direct toegang toe te krijgen.
Nadat we de configuratie van het model hebben bepaald, kunnen we de webapplicatie gaan gebruiken.
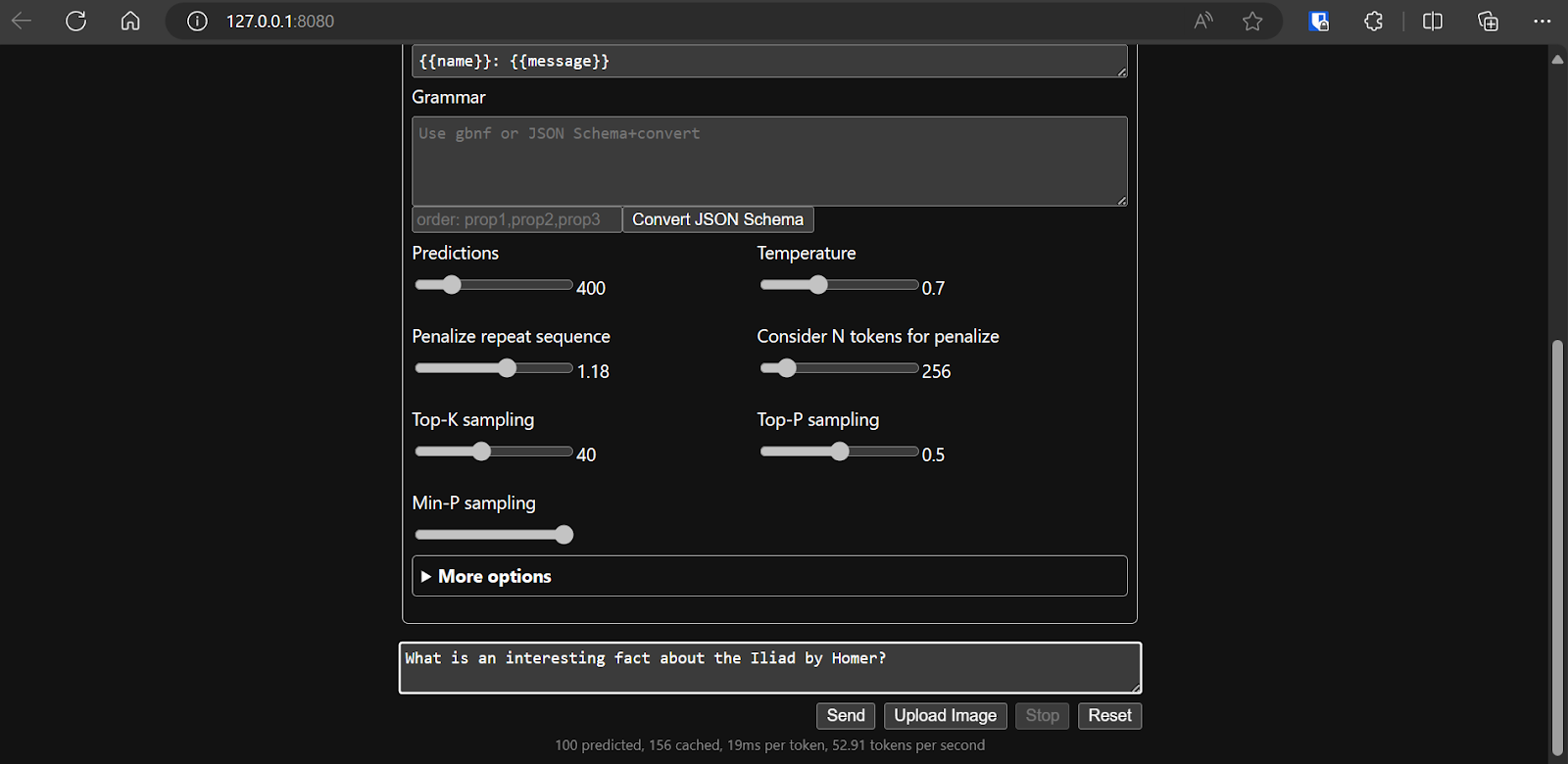
Llama.cpp draaien met llamafile is makkelijker en efficiënter. We genereerden het antwoord met 53,18 tokens/sec (zonder llamafile was de snelheid 10,99 tokens/sec).
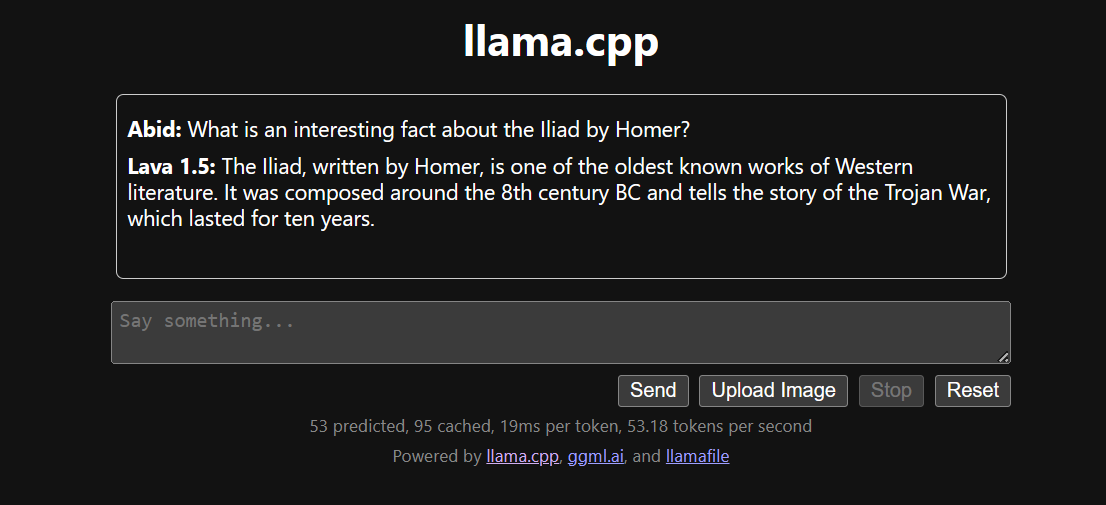
LLM’s lokaal installeren en gebruiken kan een leuke en spannende ervaring zijn. We kunnen zelf experimenteren met de nieuwste open-sourcemodellen en profiteren van privacy, controle en een betere chatervaring.
LLM’s lokaal gebruiken heeft ook praktische toepassingen, zoals integratie met andere applicaties via API-servers en het koppelen van lokale mappen om contextbewuste antwoorden te geven. In sommige gevallen is het essentieel om LLM’s lokaal te gebruiken, vooral wanneer privacy en beveiliging kritieke factoren zijn.
Je kunt meer leren over LLM’s en het bouwen van AI-applicaties via deze resources:
Bouw je AI-carrière met DataCamp!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
