
Tracks
Cơ bản về Kinh doanh Trí tuệ Nhân tạo
12 giờ
Việc sử dụng các mô hình ngôn ngữ lớn (LLM) trên hệ thống cục bộ ngày càng phổ biến nhờ quyền riêng tư, khả năng kiểm soát và độ tin cậy được cải thiện. Đôi khi, các mô hình này còn có thể chính xác và nhanh hơn ChatGPT.
Chúng tôi sẽ giới thiệu bảy cách để chạy LLM cục bộ với tăng tốc GPU trên Windows 11, nhưng các phương pháp này cũng hoạt động trên macOS và Linux.
Nếu bạn muốn tìm hiểu về LLM từ đầu, một điểm khởi đầu tốt là khóa học về Large Learning Models (LLMs).
Hãy bắt đầu bằng cách khám phá framework LLM đầu tiên.
Ollama là hệ sinh thái chủ đạo để chạy các LLM như Llama 4, Mistral 3 và Gemma 3 trên máy cục bộ.
Ngoài ra, nhiều ứng dụng hỗ trợ tích hợp Ollama, khiến đây trở thành công cụ tuyệt vời để truy cập nhanh và dễ hơn vào các mô hình ngôn ngữ trên máy của chúng ta.
Ollama nay đã tương thích hoàn toàn với OpenAI API, cho phép thay thế trực tiếp dịch vụ đám mây của OpenAI. Các tính năng mới gồm có function calling, xuất JSON có cấu trúc, Flash Attention cho mô hình thị giác và suy luận nhanh hơn 30% trên Apple Silicon và GPU AMD.
Bạn có thể tải Ollama từ trang tải xuống.
Sau khi cài đặt (với thiết lập mặc định), logo Ollama sẽ hiện ở khay hệ thống.
Bạn có thể tải mô hình Llama 3 bằng cách gõ lệnh terminal sau:
$ ollama run llama3Llama 3 đã sẵn sàng! Bên dưới là danh sách lệnh cần dùng nếu bạn muốn sử dụng các LLM khác:
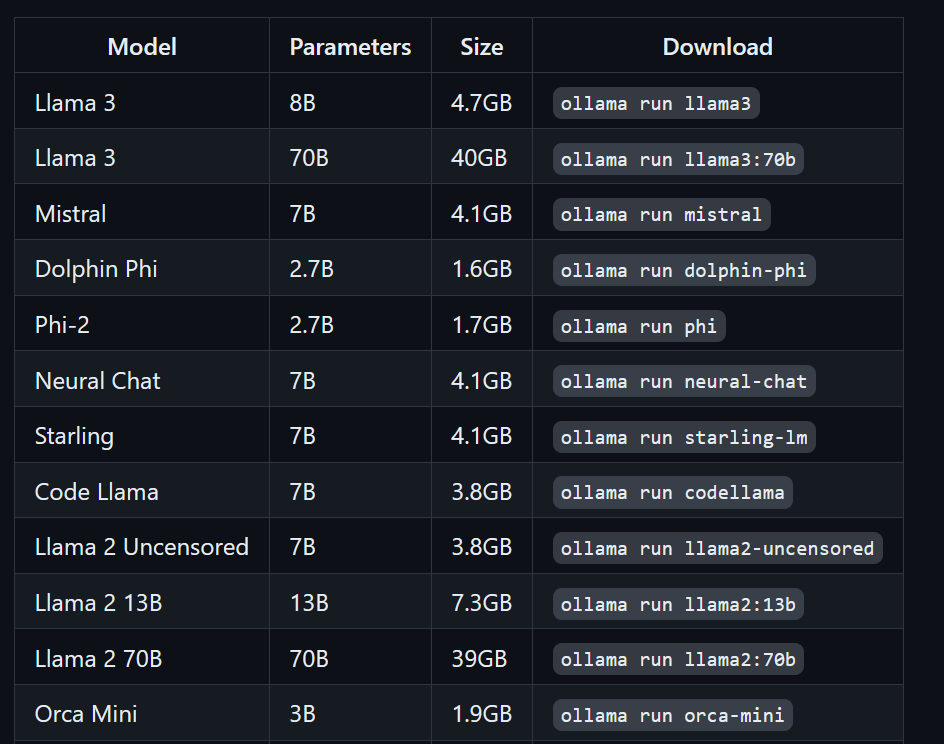
Để truy cập các mô hình đã tải về và có sẵn trong thư mục llama.cpp, chúng ta cần:
cd.$ cd C:/Repository/GitHub/llama.cppModelfile và thêm dòng "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf".$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bVới phương pháp này, chúng ta có thể tải bất kỳ LLM nào từ Hugging Face với phần mở rộng .gguf và dùng trong terminal. Nếu muốn tìm hiểu thêm, hãy xem khóa học Working with Hugging Face.
LM Studio là một bàn làm việc tất cả-trong-một để chạy LLM cục bộ và hỗ trợ fine-tuning nguyên bản. Bên cạnh đó, nó hỗ trợ nhiều mô hình đồng thời, speculative decoding (tốc độ token nhanh hơn 1.5x-3x) và tích hợp RAG cho tài liệu.
Bạn có thể tải trình cài đặt từ trang chủ của LM Studio.
Sau khi tải xong, cài ứng dụng với các tùy chọn mặc định.
Cuối cùng, khởi chạy LM Studio!
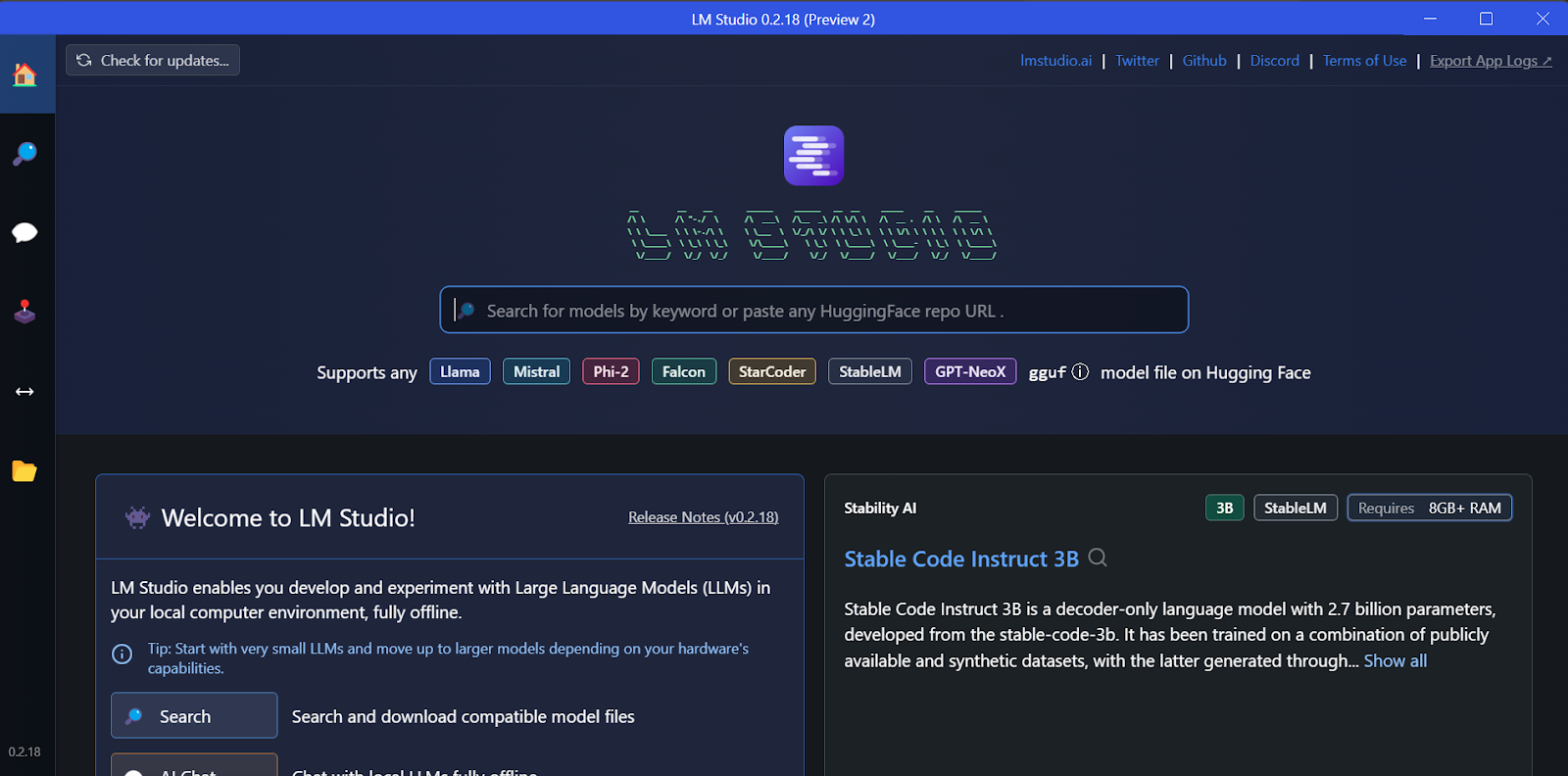
Bạn có thể tải bất kỳ mô hình nào từ Hugging Face bằng chức năng tìm kiếm.
Trong ví dụ này, chúng tôi sẽ tải mô hình nhỏ nhất, Gemma 2B Instruct của Google.
Bạn có thể chọn mô hình đã tải từ menu thả xuống phía trên và trò chuyện như bình thường. LM Studio cung cấp nhiều tùy chọn tùy biến hơn GPT4All.
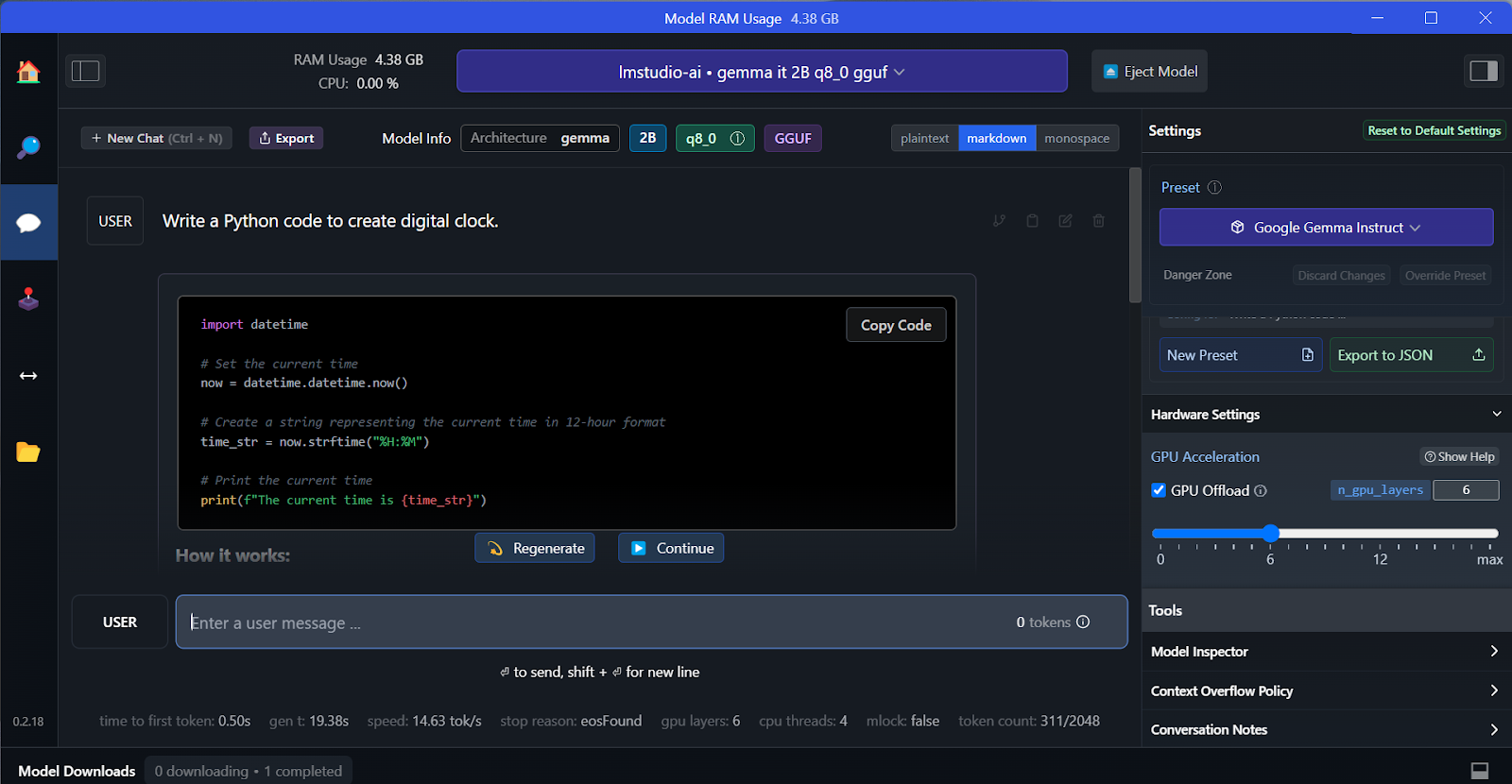
Tương tự GPT4All, bạn có thể tùy chỉnh mô hình và khởi chạy máy chủ API chỉ với một cú nhấp. Để truy cập mô hình, bạn có thể dùng gói Python OpenAI API, CURL hoặc tích hợp trực tiếp với bất kỳ ứng dụng nào.
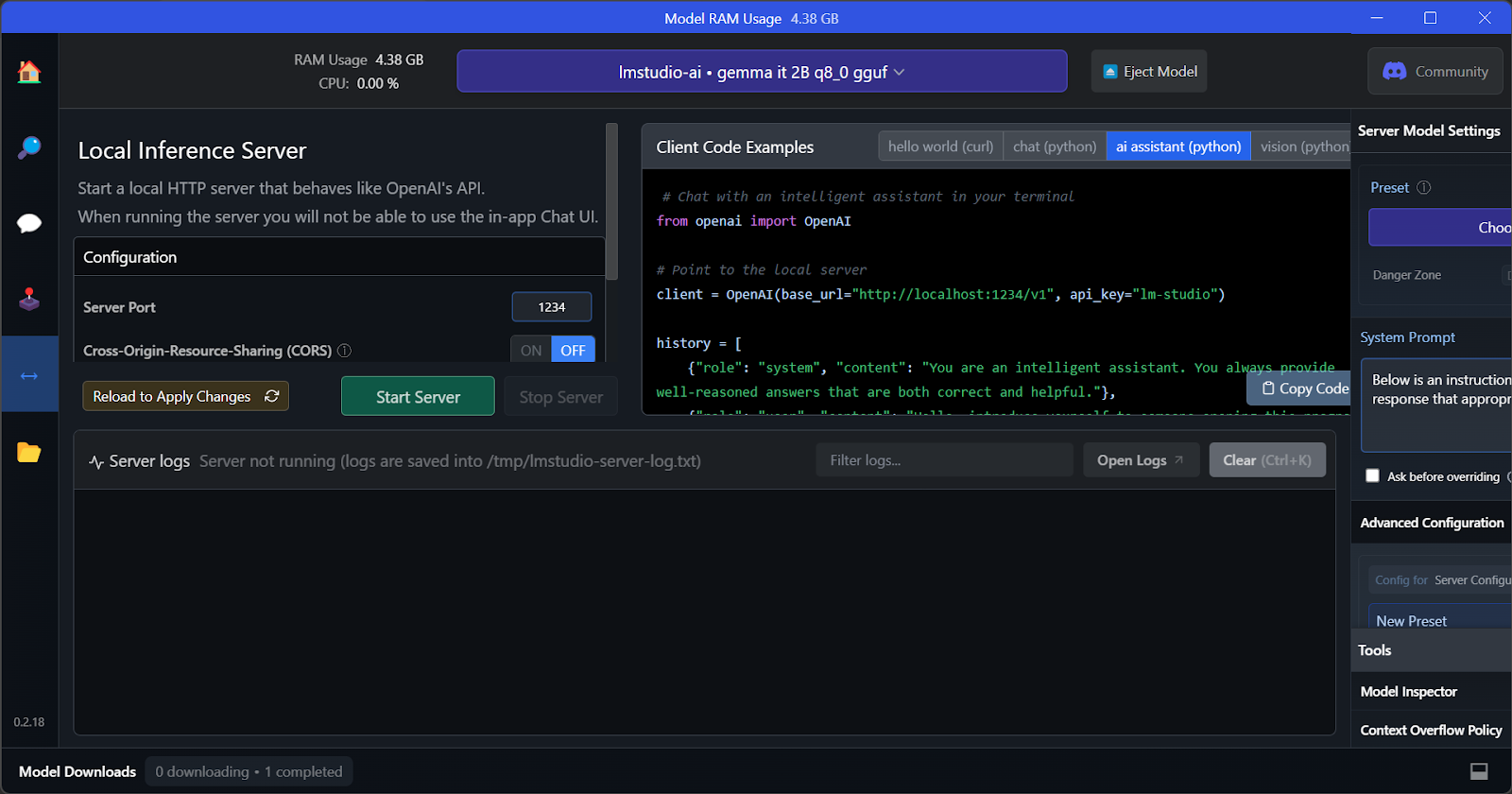
Tính năng chủ chốt của LM Studio là cho phép chạy và phục vụ nhiều mô hình cùng lúc. Điều này giúp người dùng so sánh kết quả giữa các mô hình và dùng cho nhiều ứng dụng. Để chạy nhiều phiên mô hình, chúng ta cần VRAM GPU cao.
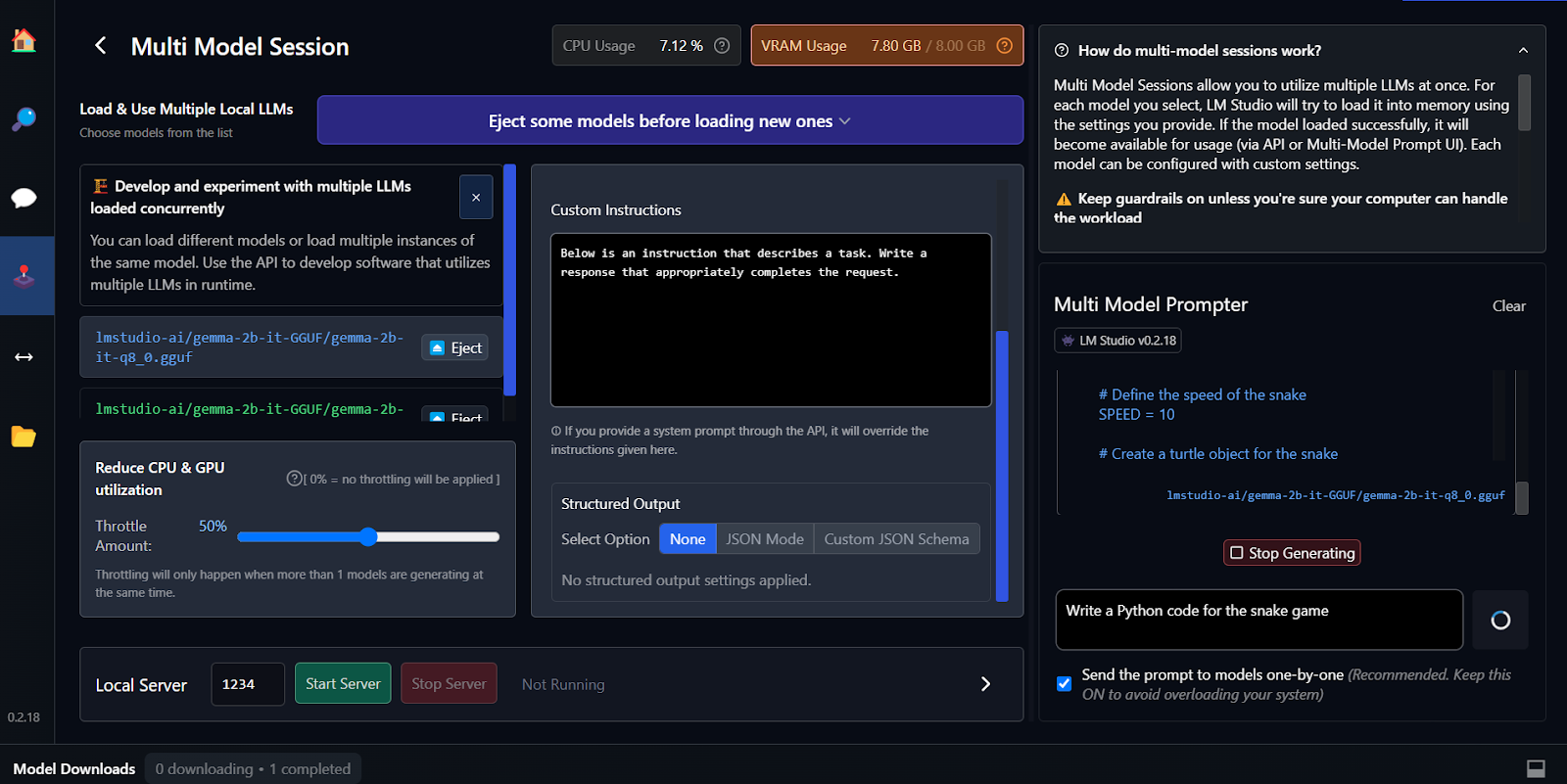
Fine-tuning là một cách khác để tạo phản hồi theo ngữ cảnh và tùy biến. Bạn có thể học cách fine-tune mô hình Google Gemma bằng hướng dẫn Fine Tuning Google Gemma: Nâng cao LLM với hướng dẫn tùy chỉnh. Bạn sẽ học chạy suy luận trên GPU/TPU và fine-tune mô hình Gemma 7b-it mới nhất trên bộ dữ liệu nhập vai (role-play).
vLLM là một engine suy luận mã nguồn mở để chạy LLM ở quy mô sản xuất. Khác với Ollama hoặc LM Studio, vLLM ưu tiên thông lượng và độ trễ cho kịch bản nhiều người dùng.
Đổi mới cốt lõi của nó là PagedAttention, quản lý bộ nhớ GPU như bộ nhớ ảo, tái sử dụng các trang nhỏ thay vì dành sẵn các khối lớn, kết hợp batching liên tục. Các benchmark thực tế cho thấy vLLM đạt 793 token mỗi giây trên Llama 70B so với 41 token mỗi giây của Ollama dưới tải đồng thời.
vLLM cũng hỗ trợ song song tensor trên nhiều GPU, prefix caching và multi-LoRA batching để phục vụ đồng thời các biến thể đã fine-tune.
Trên Mac và Linux, vLLM có thể cài dễ dàng bằng pip.
Trên Linux với CUDA 11.8+:
pip install vllmTrên macOS với Apple Silicon:
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmHiện chưa có hỗ trợ chính thức cho Windows. Tuy nhiên, có thể dùng WSL2 hoặc Docker như giải pháp tạm.
Khởi động máy chủ tương thích OpenAI:
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Với mô hình 70B trên nhiều GPU:
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Xử lý theo lô trong Python:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Để truy vấn, dùng SDK OpenAI:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Một tùy chọn khác là chạy qua cURL:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Chọn vLLM cho API sản xuất phục vụ hàng trăm người dùng đồng thời; dùng Ollama cho phát triển cục bộ.
Một trong những ứng dụng LLM cục bộ phổ biến và đẹp mắt nhất là Jan. Đây là lựa chọn ưu tiên quyền riêng tư thay thế cho ChatGPT.
Bạn có thể tải trình cài từ Jan.ai.
Sau khi cài ứng dụng Jan với thiết lập mặc định, bạn đã sẵn sàng khởi chạy ứng dụng.
Khi đề cập GPT4All và LM Studio, chúng ta đã tải hai mô hình. Thay vì tải thêm, chúng ta sẽ nhập các mô hình sẵn có bằng cách vào trang mô hình và nhấp nút Import Model.
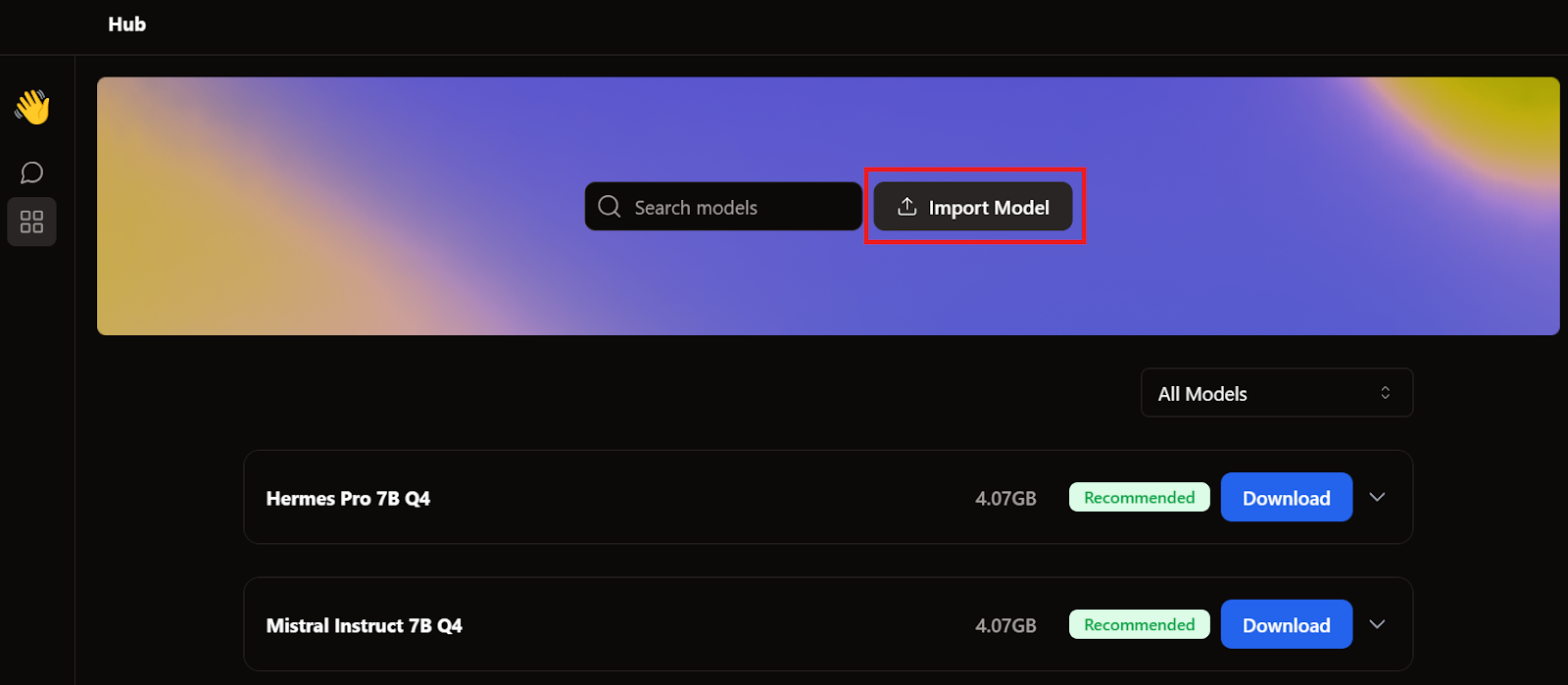
Sau đó, vào thư mục ứng dụng, chọn các mô hình của GPT4All và LM Studio, rồi nhập từng mô hình.
Để truy cập mô hình cục bộ, vào giao diện trò chuyện và mở phần mô hình ở bảng bên phải.
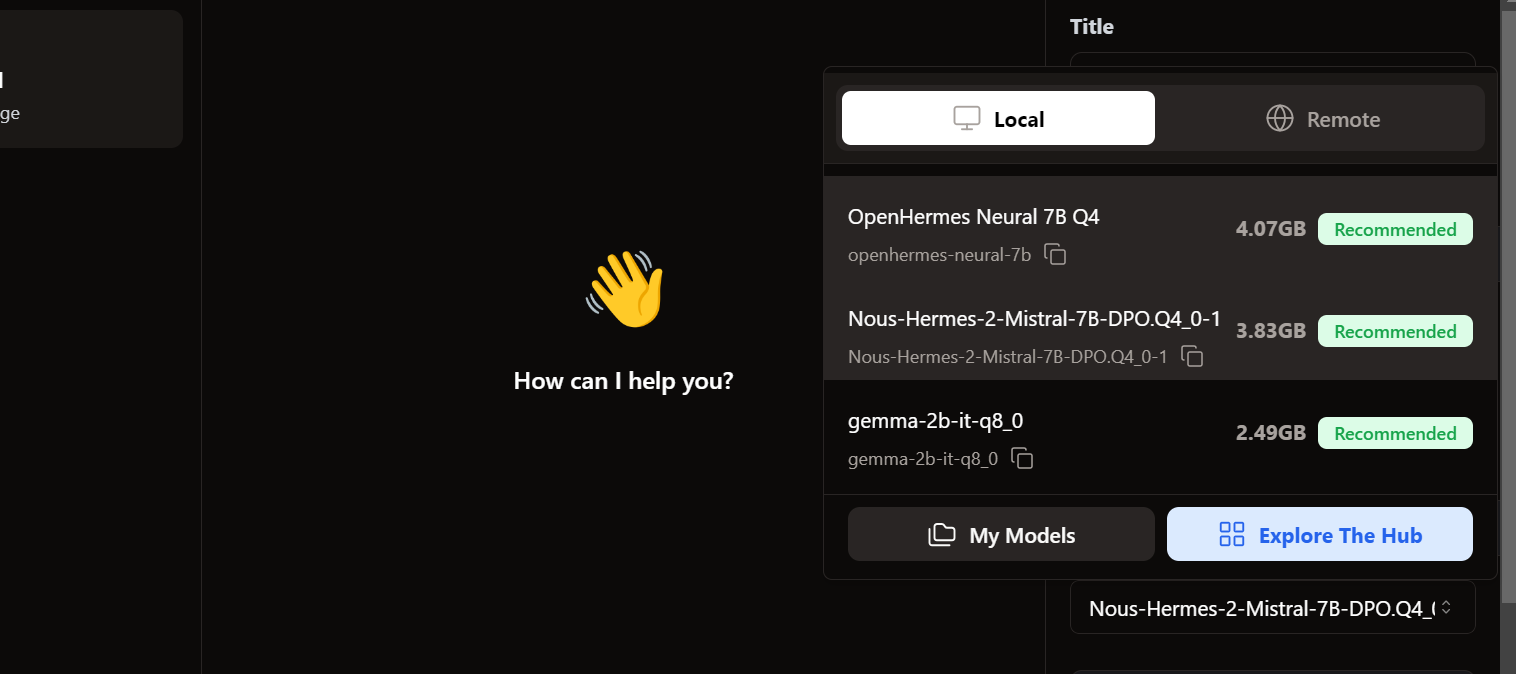
Bạn sẽ thấy các mô hình đã nhập có sẵn. Chọn mô hình mong muốn và bắt đầu sử dụng ngay!
Tốc độ sinh phản hồi rất nhanh. Giao diện người dùng tự nhiên, tương tự ChatGPT, và không làm chậm laptop hay PC của bạn.
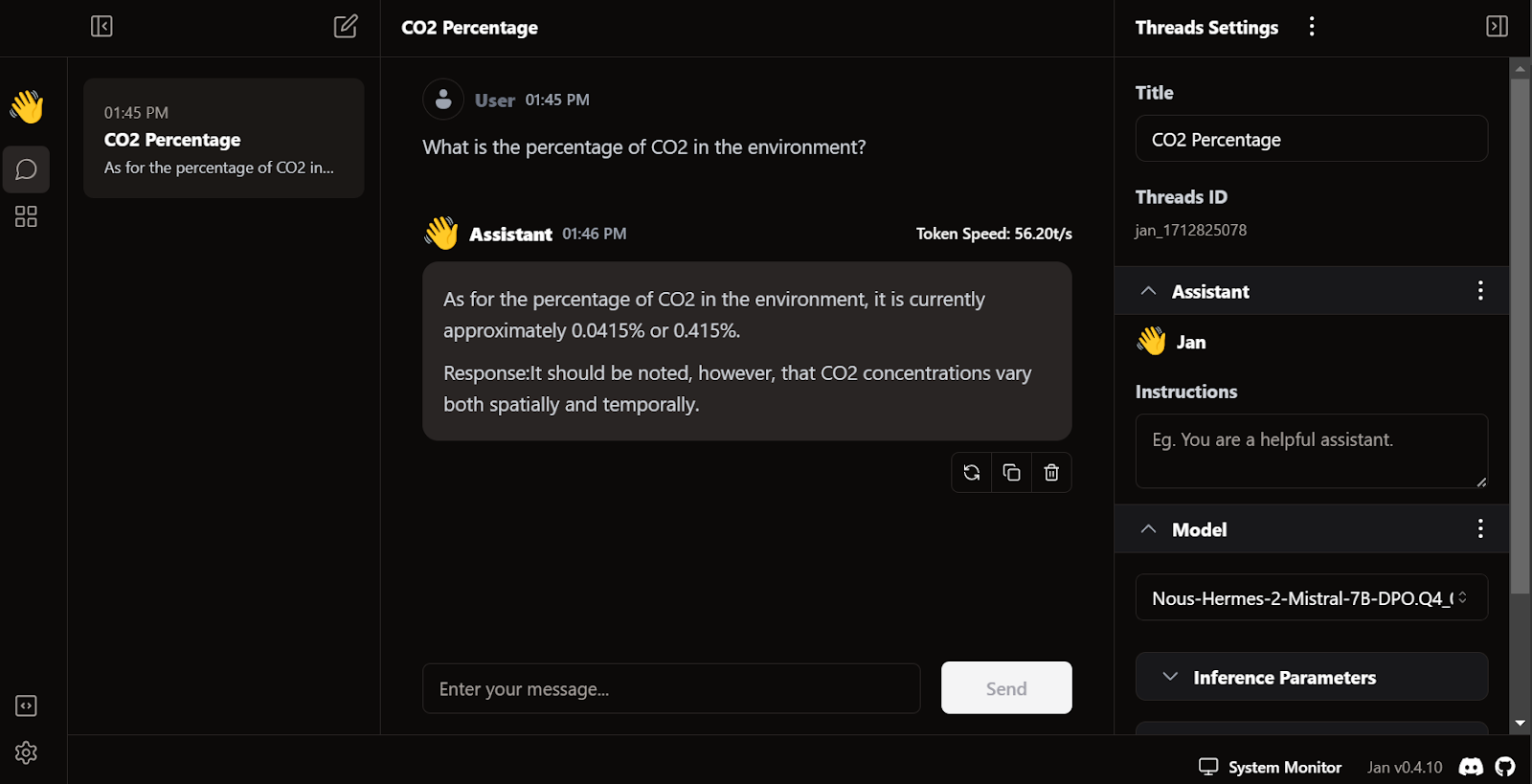
Điểm độc đáo của Jan là cho phép cài tiện ích mở rộng và dùng các mô hình sở hữu độc quyền từ OpenAI, MistralAI, Groq, TensorRT và Triton RT.
Giống LM Studio, bạn cũng có thể dùng Jan như một máy chủ API cục bộ. Nó cung cấp khả năng ghi log tốt hơn và kiểm soát phản hồi LLM, đồng thời tích hợp OpenAI, Mistral AI, Groq, Claude và DeepSeek qua thiết lập khóa API đơn giản trong phần cài đặt.
Một framework LLM mã nguồn mở phổ biến khác là llama.cpp. Nó được viết hoàn toàn bằng C/C++, giúp nhanh và hiệu quả.
Nhiều ứng dụng AI cục bộ và trên web dựa trên llama.cpp. Do đó, học cách sử dụng nó cục bộ sẽ giúp bạn hiểu cách các ứng dụng LLM khác vận hành phía sau hậu trường.
Trước tiên, chúng ta cần đi đến thư mục dự án bằng lệnh cd trong shell—bạn có thể tìm hiểu thêm về terminal trong khóa học Introduction to Shell.
Sau đó, clone tất cả tệp từ máy chủ GitHub bằng lệnh dưới đây:
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitCông cụ dòng lệnh make có sẵn theo mặc định trên Linux và MacOS. Với Windows, chúng ta cần thực hiện các bước sau:
$ cd C:/Repository/GitHub/llama.cpp để vào thư mục llama.cpp.$ make và nhấn Enter để cài đặt llama.cpp.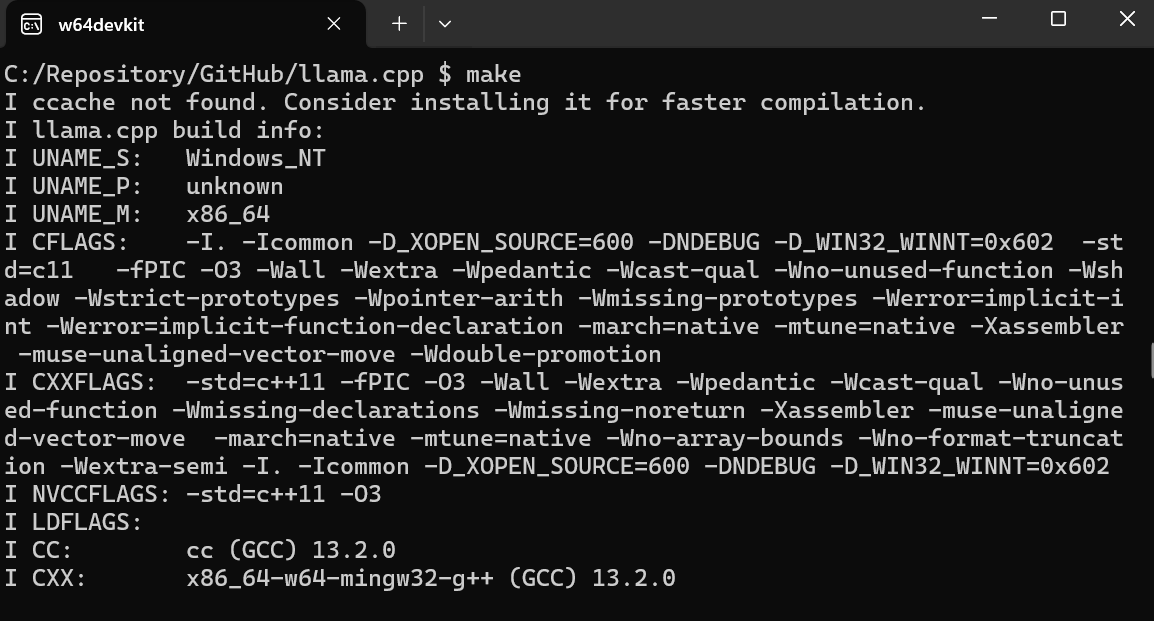
Sau khi hoàn tất cài đặt, chúng ta chạy máy chủ web UI của llama.cpp bằng lệnh dưới đây. (Lưu ý: Chúng tôi đã sao chép tệp mô hình từ thư mục GPT4All sang thư mục llama.cpp để tiện truy cập mô hình).
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589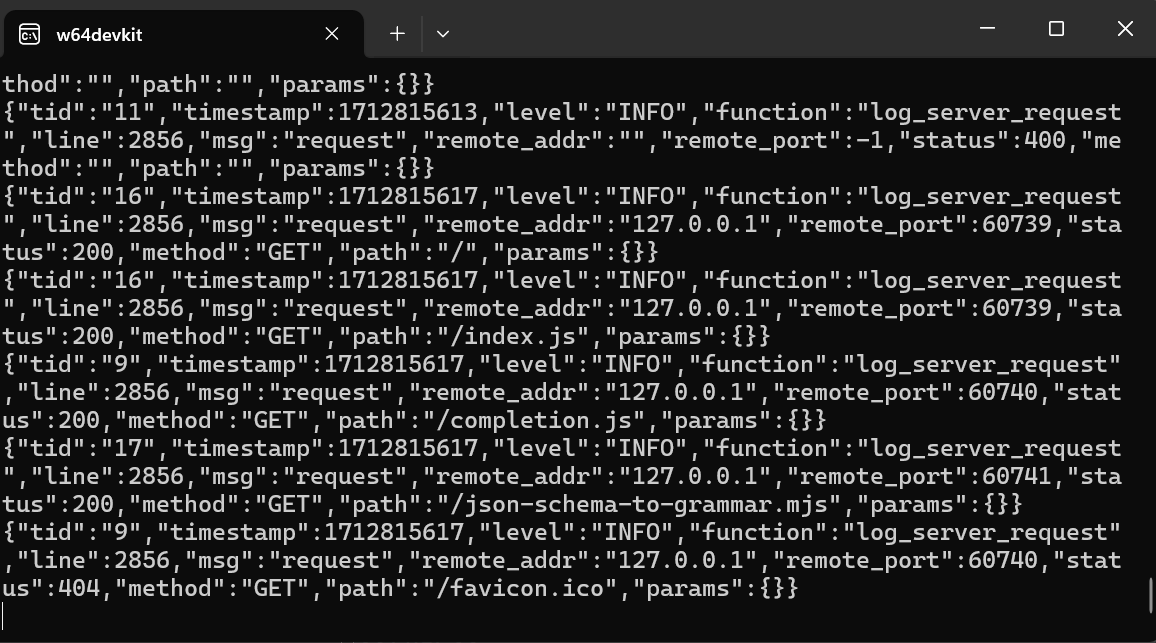
Máy chủ web chạy tại http://127.0.0.1:6589/. Bạn có thể sao chép URL này và dán vào trình duyệt để truy cập giao diện web của llama.cpp.
Trước khi tương tác với chatbot, chúng ta nên điều chỉnh cài đặt và tham số của mô hình.
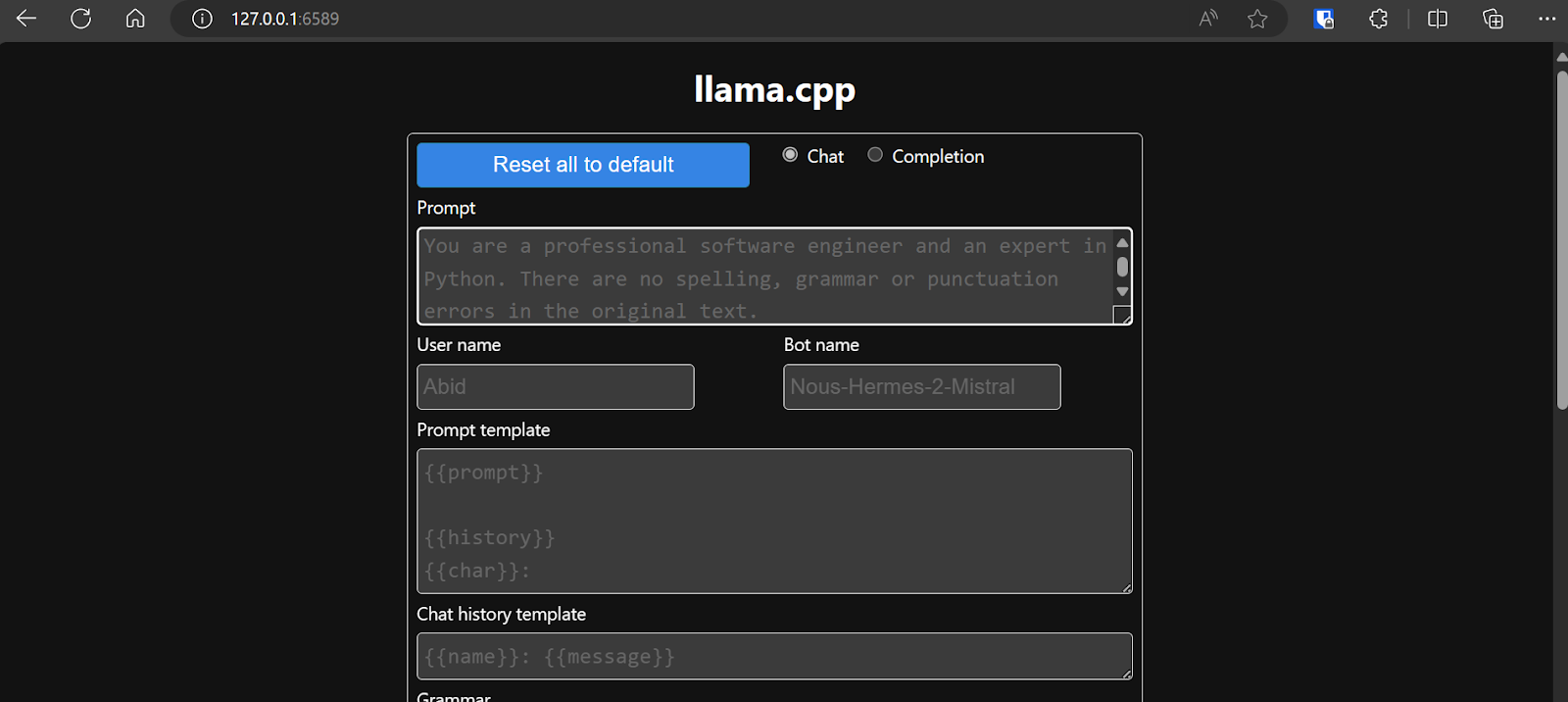 Xem thêm hướng dẫn llama.cpp nếu bạn muốn học sâu hơn!
Xem thêm hướng dẫn llama.cpp nếu bạn muốn học sâu hơn!
Tốc độ sinh phản hồi chậm vì chúng ta chạy trên CPU, không phải GPU. Cần cài một phiên bản khác của llama.cpp để chạy trên GPU.
$ make LLAMA_CUDA=1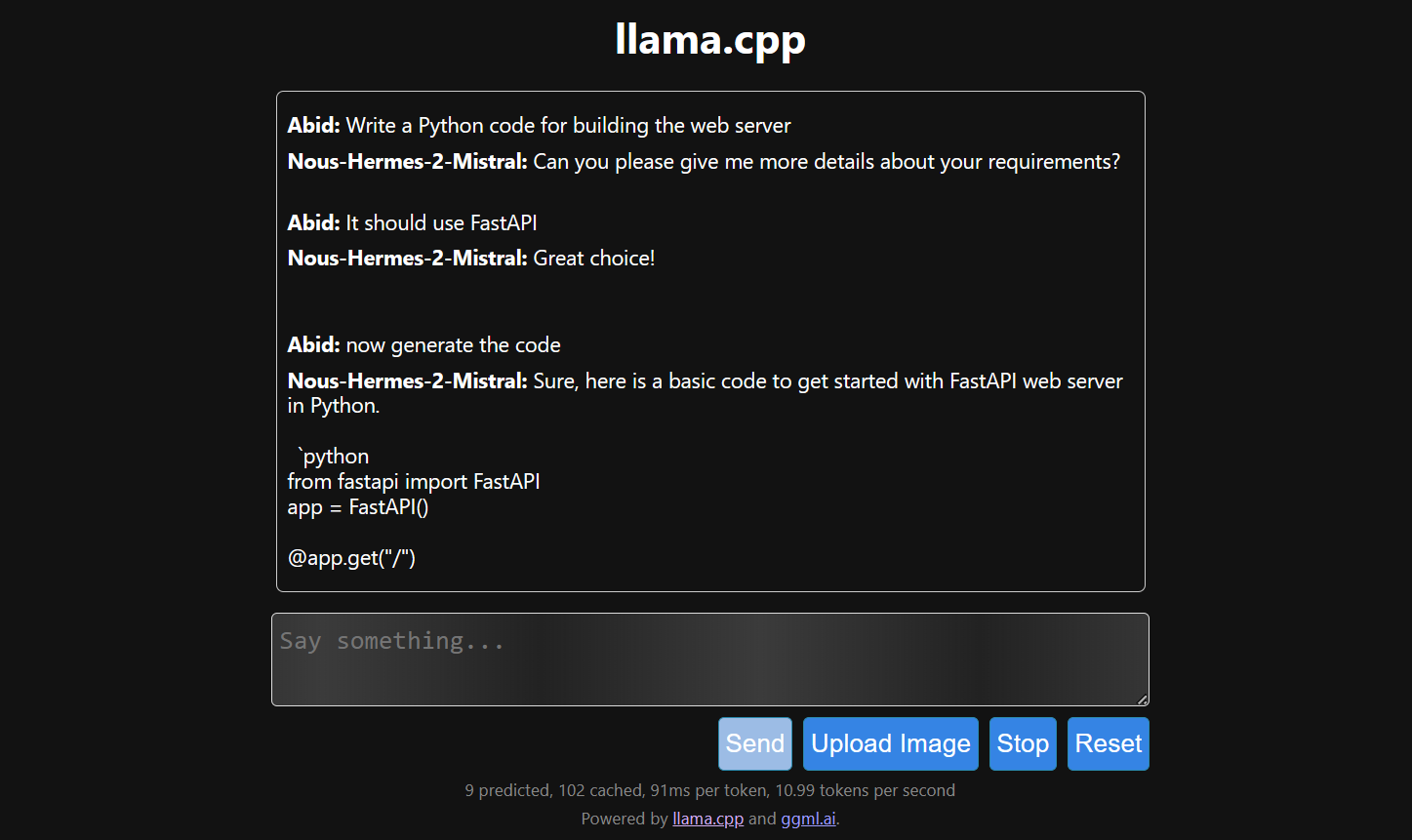
Nếu bạn thấy llama.cpp hơi phức tạp, hãy thử llamafile. Framework này đơn giản hóa LLM cho cả nhà phát triển và người dùng cuối bằng cách kết hợp llama.cpp với Cosmopolitan Libc thành một file thực thi đơn lẻ. Nó loại bỏ mọi phức tạp liên quan đến LLM, giúp dễ tiếp cận hơn.
Bạn có thể tải tệp mô hình mong muốn từ kho GitHub của llamafile.
Chúng ta sẽ tải LLaVA 1.5 vì nó cũng có thể hiểu hình ảnh.
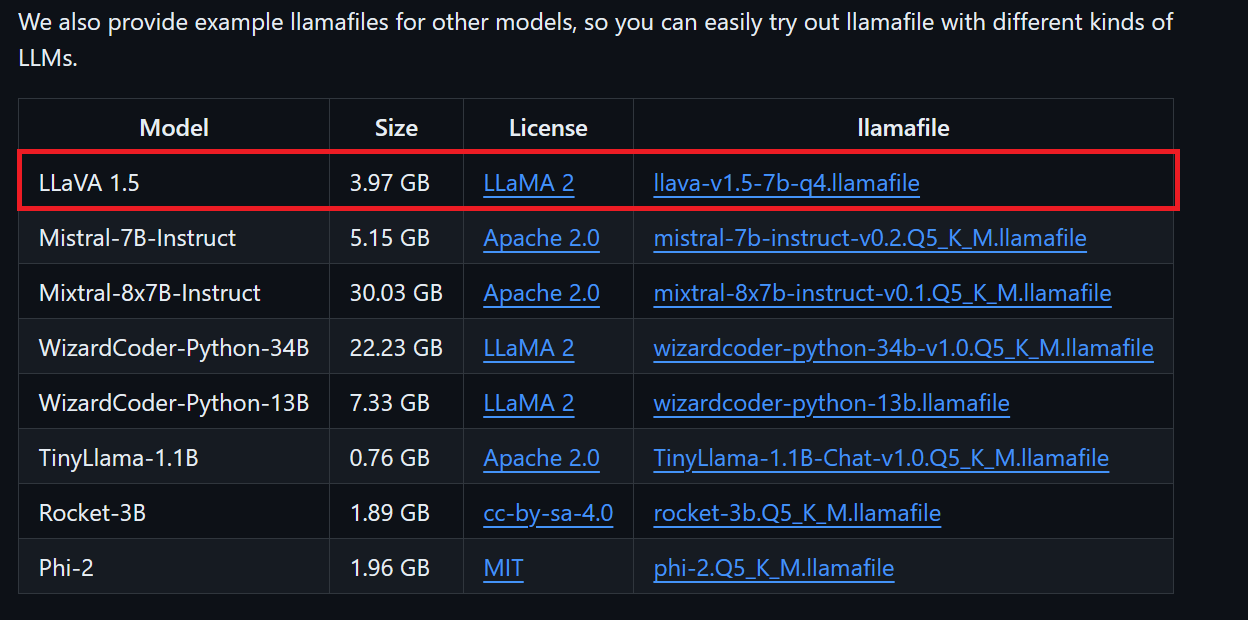
Người dùng Windows cần thêm .exe vào tên tệp trong terminal. Để làm điều này, nhấp chuột phải vào tệp đã tải và chọn Rename.

Đầu tiên, vào thư mục llamafile bằng lệnh cd trong terminal. Sau đó, chạy lệnh dưới đây để khởi động máy chủ web llama.cpp.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999Máy chủ web sử dụng GPU mà không cần bạn cài đặt hay cấu hình gì thêm.
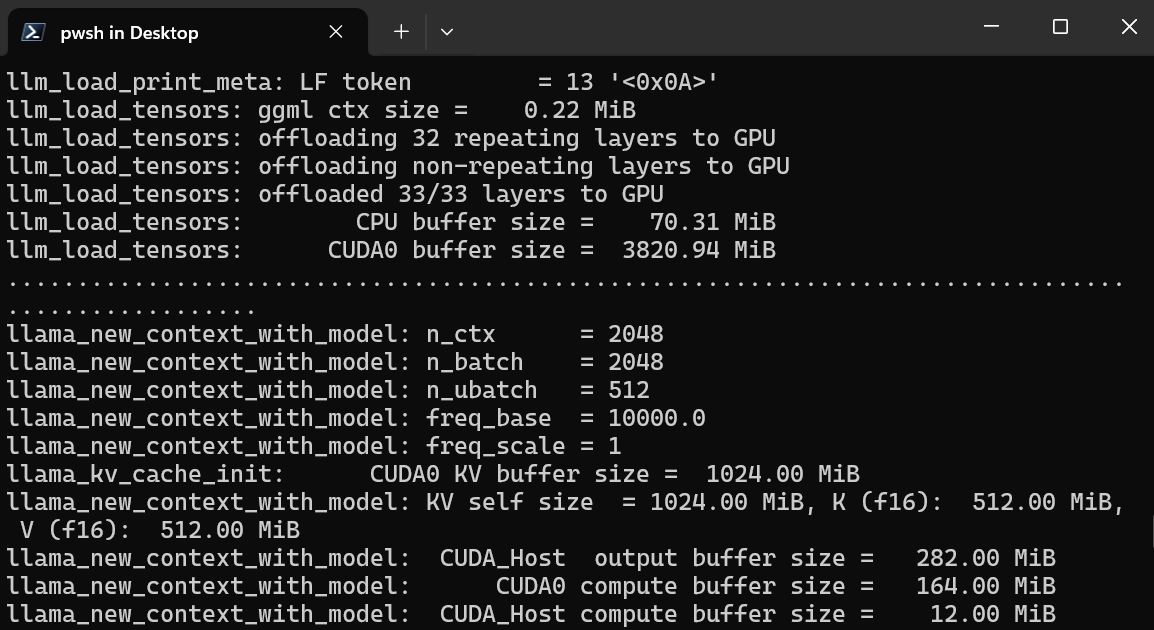
Nó cũng sẽ tự động mở trình duyệt mặc định với ứng dụng web llama.cpp đang chạy. Nếu không, bạn có thể dùng URL http://127.0.0.1:8080/ để truy cập trực tiếp.
Sau khi chốt cấu hình mô hình, bạn có thể bắt đầu dùng ứng dụng web.
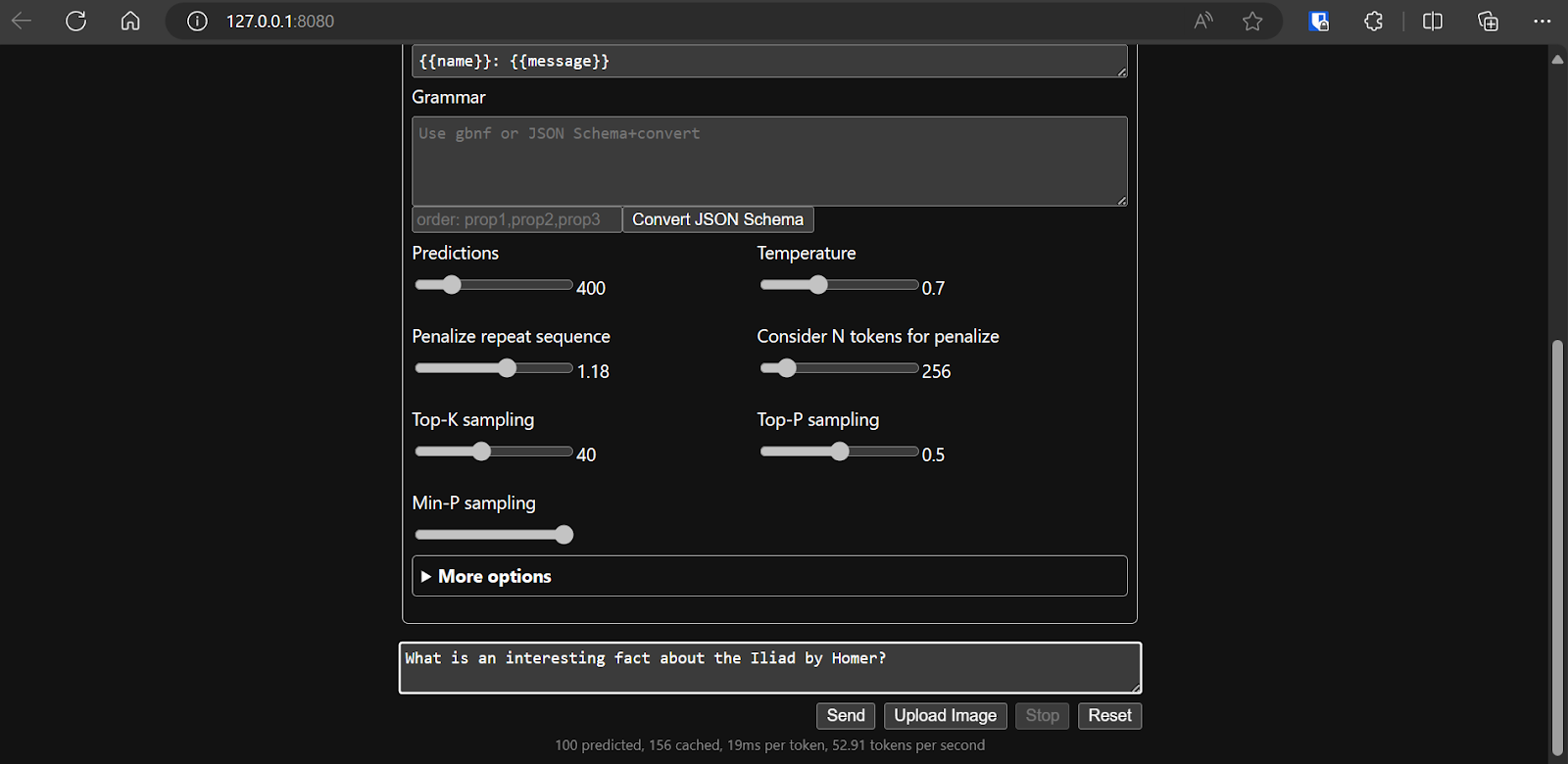
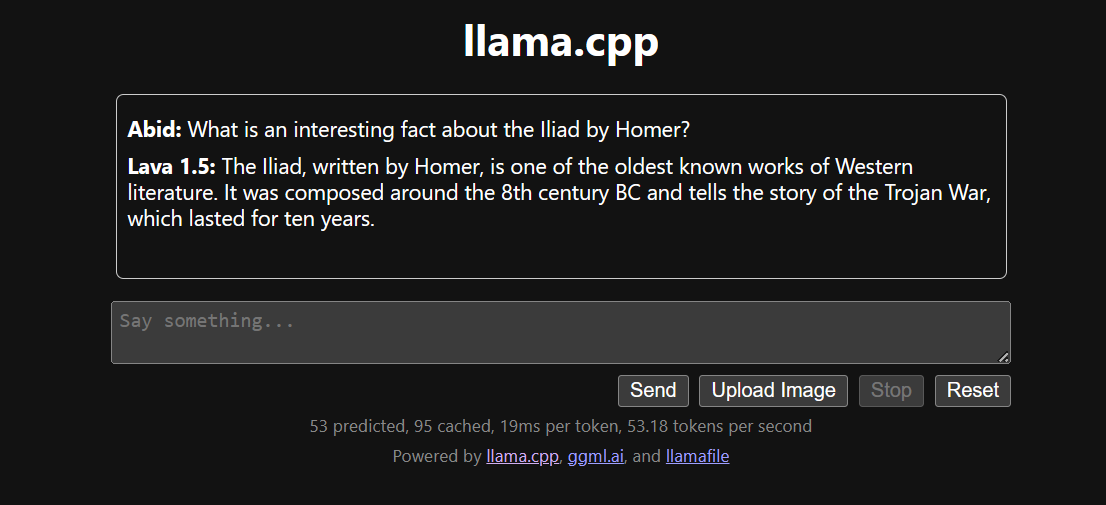
Chạy llama.cpp bằng llamafile dễ hơn và hiệu quả hơn. Chúng tôi tạo phản hồi với tốc độ 53,18 token/giây (không dùng llamafile, tốc độ là 10,99 token/giây).
Cài đặt và sử dụng LLM cục bộ có thể là trải nghiệm thú vị và hấp dẫn. Chúng ta có thể tự mình thử nghiệm các mô hình mã nguồn mở mới nhất, tận hưởng quyền riêng tư, khả năng kiểm soát và trải nghiệm trò chuyện tốt hơn.
Việc dùng LLM cục bộ cũng có nhiều ứng dụng thiết thực, như tích hợp với các ứng dụng khác qua máy chủ API và kết nối thư mục cục bộ để cung cấp phản hồi theo ngữ cảnh. Trong một số trường hợp, việc dùng LLM cục bộ là thiết yếu, đặc biệt khi quyền riêng tư và bảo mật là yếu tố then chốt.
Bạn có thể tìm hiểu thêm về LLM và xây dựng ứng dụng AI qua các tài nguyên sau:
Xây dựng sự nghiệp AI của bạn với DataCamp!
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút