
Program
AI İşletme Temelleri
12 sa
Büyük dil modellerini (LLM'ler) yerel sistemlerde kullanmak; gelişmiş gizlilik, kontrol ve güvenilirlik sayesinde giderek daha popüler hale geliyor. Bazı durumlarda bu modeller, ChatGPT'den bile daha doğru ve hızlı olabilir.
Windows 11'de GPU hızlandırmasıyla LLM'leri yerelde çalıştırmanın yedi yolunu göstereceğiz, ancak ele aldığımız yöntemler macOS ve Linux'ta da çalışır.
LLM'leri en baştan öğrenmek istiyorsanız, Büyük Dil Modelleri (LLM'ler) üzerine bu kurs iyi bir başlangıç noktasıdır.
İlk LLM çerçevemizi keşfederek başlayalım.
Ollama, Llama 4, Mistral 3 ve Gemma 3 gibi LLM'leri yerelde çalıştırmak için baskın bir ekosistemdir.
Ayrıca çok sayıda uygulama Ollama entegrasyonunu kabul eder; bu da onu, dil modellerine yerel makinemizden daha hızlı ve kolay erişim için mükemmel bir araç yapar.
Ollama artık tam OpenAI API uyumluluğu sunuyor ve OpenAI'nin bulut hizmeti için doğrudan bir yedek haline geliyor. Son özellikler arasında işlev çağırma, yapılandırılmış JSON çıktısı, görsel modeller için Flash Attention ve Apple Silicon ile AMD GPU'larda %30 daha hızlı çıkarım yer alıyor.
Ollama'yı indirme sayfasından indirebiliriz.
Kurulumu (varsayılan ayarlarla) tamamladıktan sonra, sistem tepsisinde Ollama logosu görünecektir.
Aşağıdaki terminal komutunu yazarak Llama 3 modelini indirebiliriz:
$ ollama run llama3Llama 3 artık kullanıma hazır! Aşağıda, diğer LLM'leri kullanmak istersek gerekli komutların bir listesini görüyoruz:
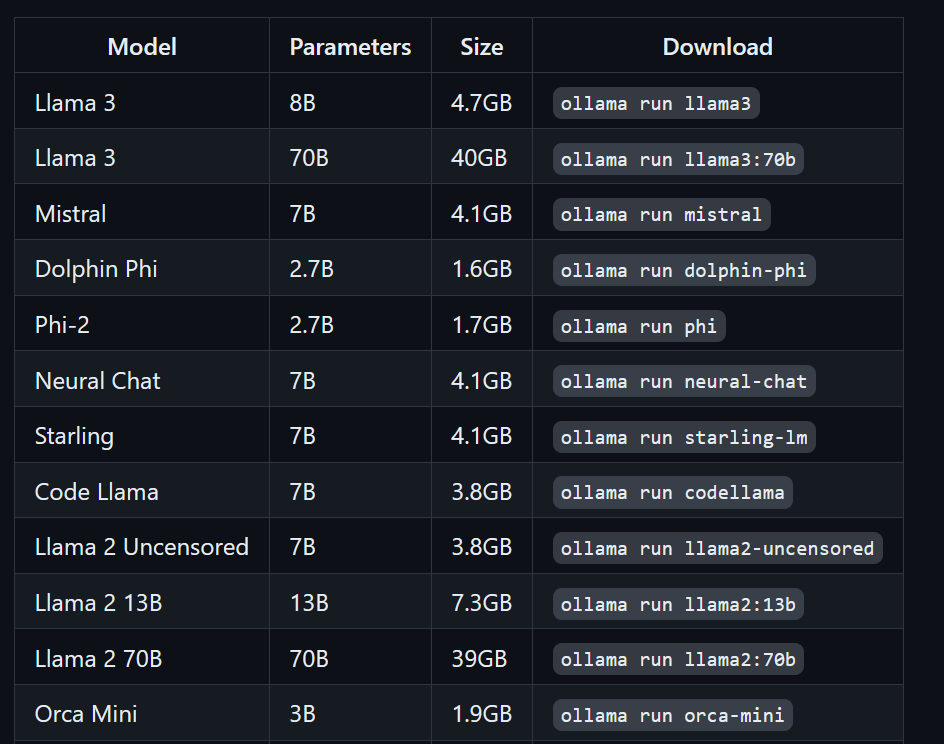
Halihazırda indirilmiş ve llama.cpp klasöründe bulunan modellere erişmek için şunları yapmalıyız:
cd komutunu kullanarak llama.cpp klasörüne gidin.$ cd C:/Repository/GitHub/llama.cppModelfile adlı bir dosya oluşturun ve "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" satırını ekleyin.$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bBu yöntemle, Hugging Face'ten .gguf uzantılı herhangi bir LLM'i indirip terminalde kullanabiliriz. Daha fazlasını öğrenmek isterseniz, Hugging Face ile Çalışmak kursuna göz atın.
LM Studio, LLM'leri yerelde çalıştırmak için hepsi bir arada bir çalışma tezgahıdır ve yerel olarak ince ayar sunar. Bunun ötesinde, birden çok eşzamanlı modeli, spekülatif kod çözmeyi (1,5x-3x daha hızlı tokenlar) ve doküman RAG entegrasyonunu destekler.
Yükleyiciyi LM Studio'nun ana sayfasından indirebiliriz.
İndirme tamamlandığında, uygulamayı varsayılan seçeneklerle kuruyoruz.
Son olarak LM Studio'yu başlatıyoruz!
Arama işlevini kullanarak Hugging Face'ten herhangi bir modeli indirebiliriz.
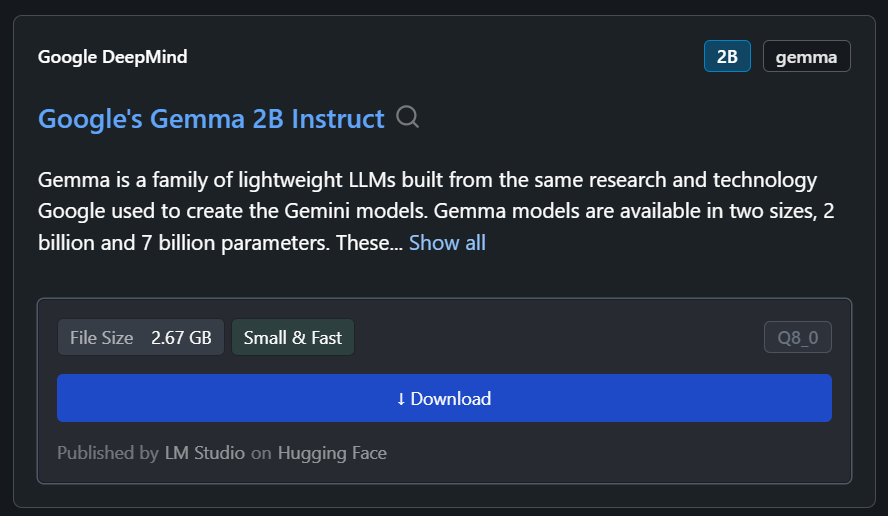
Bizim örneğimizde en küçük model olan Google'ın Gemma 2B Instruct'ı indireceğiz.
İndirilen modeli üstteki açılır menüden seçip her zamanki gibi sohbet edebiliriz. LM Studio, GPT4All'dan daha fazla özelleştirme seçeneği sunar.
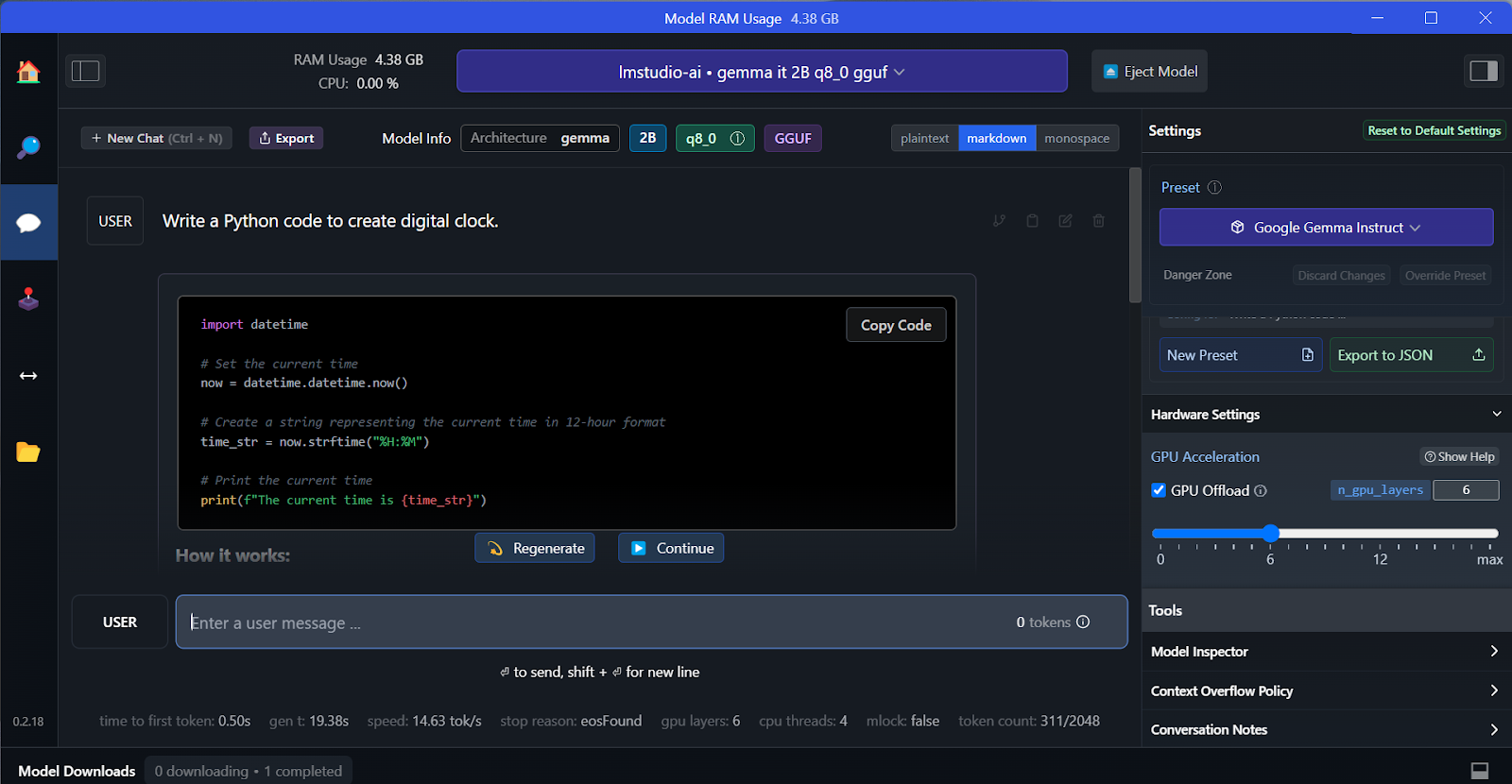
GPT4All gibi, modeli özelleştirip tek tıkla API sunucusunu başlatabiliriz. Modele erişmek için OpenAI API Python paketini, CURL'ü kullanabilir veya doğrudan herhangi bir uygulamaya entegre edebiliriz.
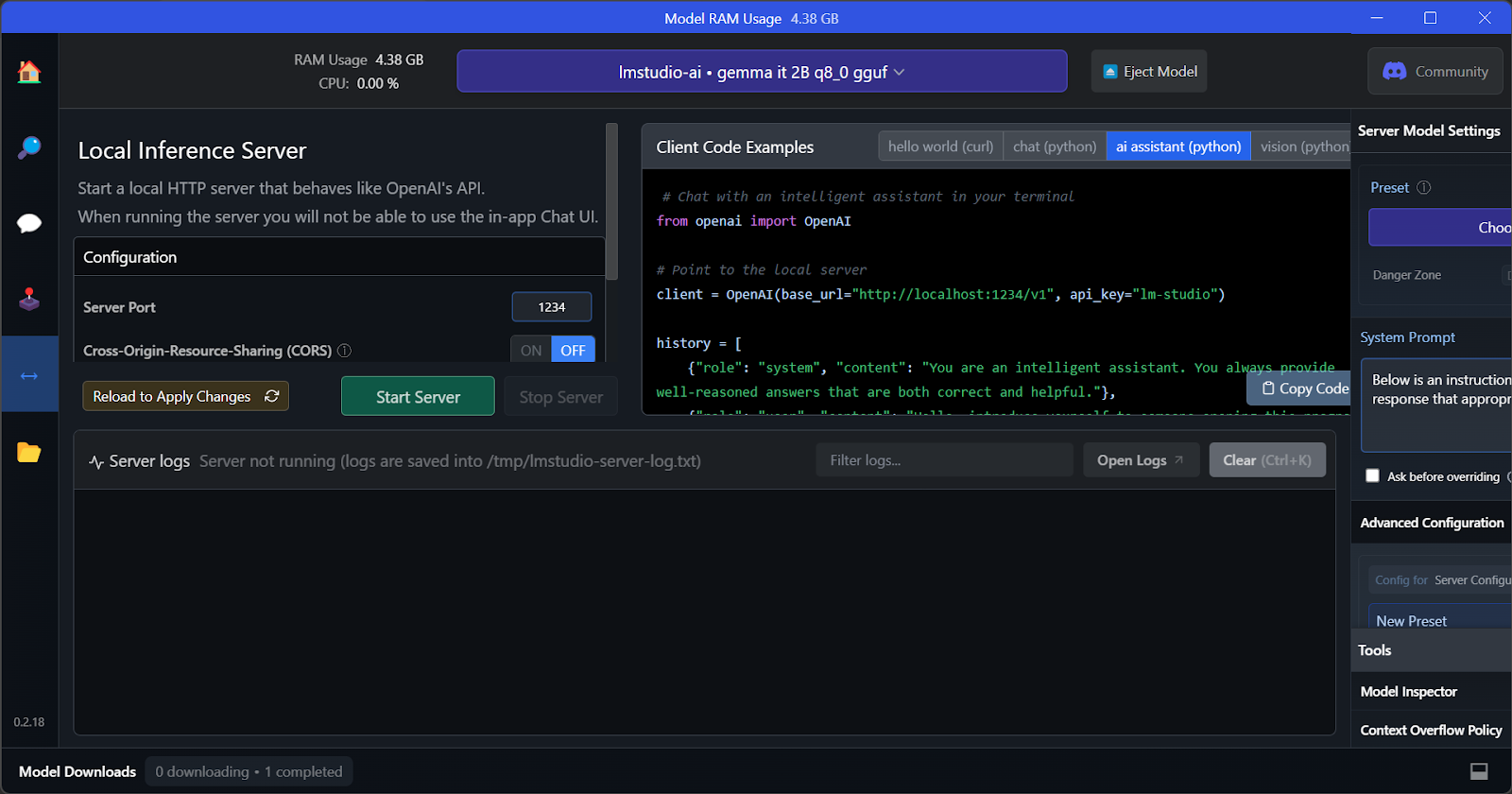
LM Studio'nun temel özelliği, aynı anda birden çok modeli çalıştırma ve sunma seçeneği sunmasıdır. Bu, kullanıcıların farklı model sonuçlarını karşılaştırmasına ve bunları birden fazla uygulama için kullanmasına olanak tanır. Birden fazla model oturumu çalıştırmak için yüksek GPU VRAM gerekir.
İnce ayar, bağlama duyarlı ve özelleştirilmiş yanıtlar üretmenin bir başka yoludur. Google Gemma'yı İnce Ayarlama: Özelleştirilmiş Yönergelerle LLM'leri Geliştirme öğreticisini izleyerek Google Gemma modelinizi nasıl ince ayarlayacağınızı öğrenebilirsiniz. GPU/TPU'larda çıkarım çalıştırmayı ve en yeni Gemma 7b-it modelini rol yapma veri kümesi üzerinde ince ayarlamayı öğreneceksiniz.
vLLM, LLM'leri üretim ölçeğinde çalıştırmak için açık kaynaklı bir çıkarım motorudur. Ollama veya LM Studio'dan farklı olarak vLLM, çok kullanıcılı senaryolarda çıktı miktarı ve gecikmeye öncelik verir.
Çekirdek yeniliği, GPU belleğini sanal bellek gibi yöneten ve büyük bloklar ayırmak yerine küçük sayfaları yeniden kullanan PagedAttention'dır; bu, sürekli yığınlama ile birleştirilmiştir. Gerçek kıyaslamalar, eşzamanlı yük altında vLLM'in Llama 70B'de saniyede 793 token üretirken Ollama'nın saniyede 41 token ürettiğini gösterir.
vLLM ayrıca GPU'lar arasında tensör paralelliğini, önek önbelleklemesini ve aynı anda ince ayarlı varyantları sunmak için çoklu-LoRA yığınlamasını destekler.
Mac ve Linux'ta vLLM, pip kullanılarak kolayca kurulabilir.
CUDA 11.8+ yüklü Linux'ta:
pip install vllmApple Silicon'lı macOS'ta:
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmŞu an için Windows için resmi destek yok. Ancak WSL2 veya Docker üzerinden çözümler mevcut.
OpenAI uyumlu sunucuyu başlatın:
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Çoklu GPU'da 70B modeller için:
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Python'da toplu işleme için:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Sorgulamak için OpenAI SDK'sını kullanın:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Bir diğer seçenek de cURL üzerinden çalıştırmaktır:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Yüzlerce eşzamanlı kullanıcıya hizmet veren üretim API'leri için vLLM'i; yerel geliştirme için Ollama'yı seçin.
En popüler ve en şık yerel LLM uygulamalarından biri Jan'dır. ChatGPT için gizlilik odaklı bir alternatiftir.
Yükleyiciyi Jan.ai'den indirebiliriz.
Jan uygulamasını varsayılan ayarlarla kurduktan sonra uygulamayı başlatmaya hazırız.
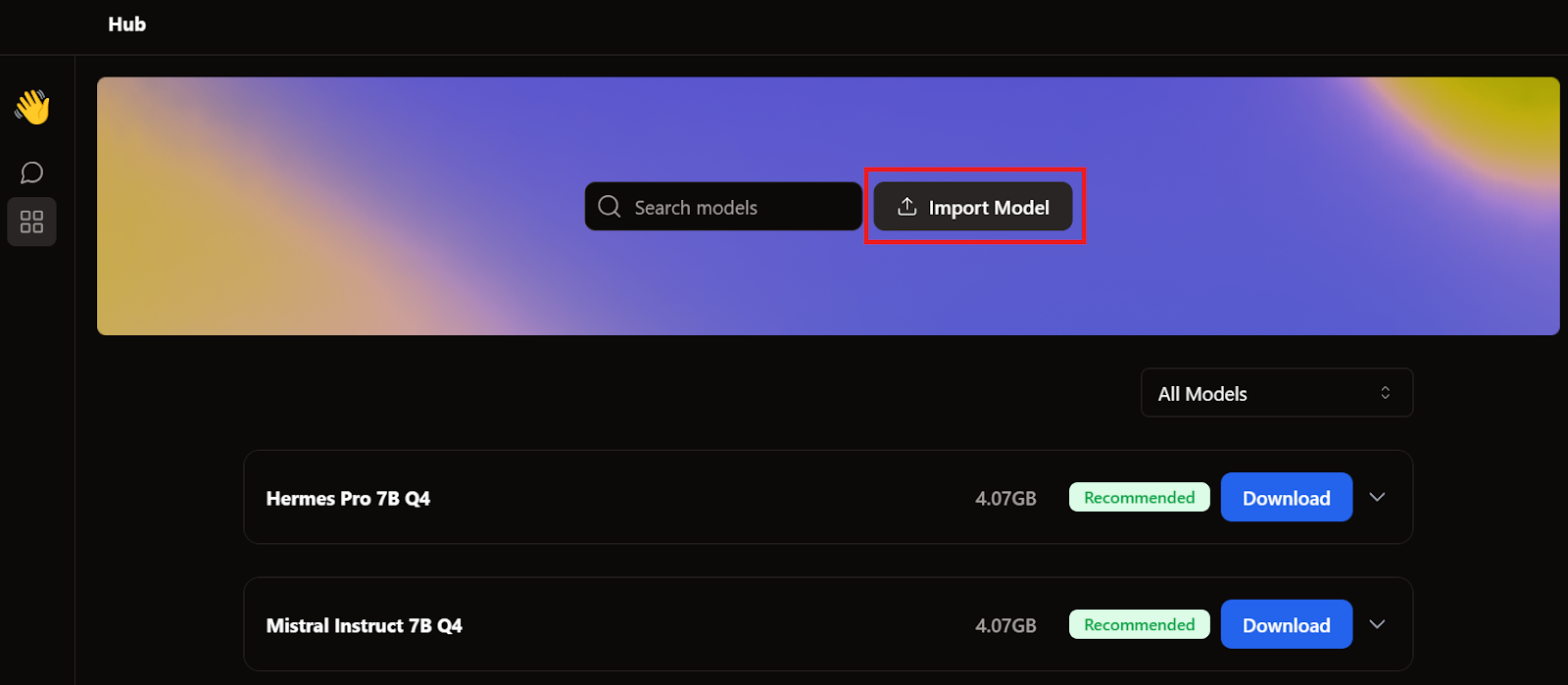
GPT4All ve LM Studio'yu ele alırken zaten iki model indirdik. Yeniden bir tane indirmek yerine, model sayfasına gidip Import Model düğmesine tıklayarak mevcut olanları içe aktaracağız.
Ardından uygulamaların dizinine gidip GPT4All ve LM Studio modellerini seçiyor ve her birini içe aktarıyoruz.
Yerel modellere erişmek için sohbet arayüzüne gidip sağ paneldeki model bölümünü açıyoruz.
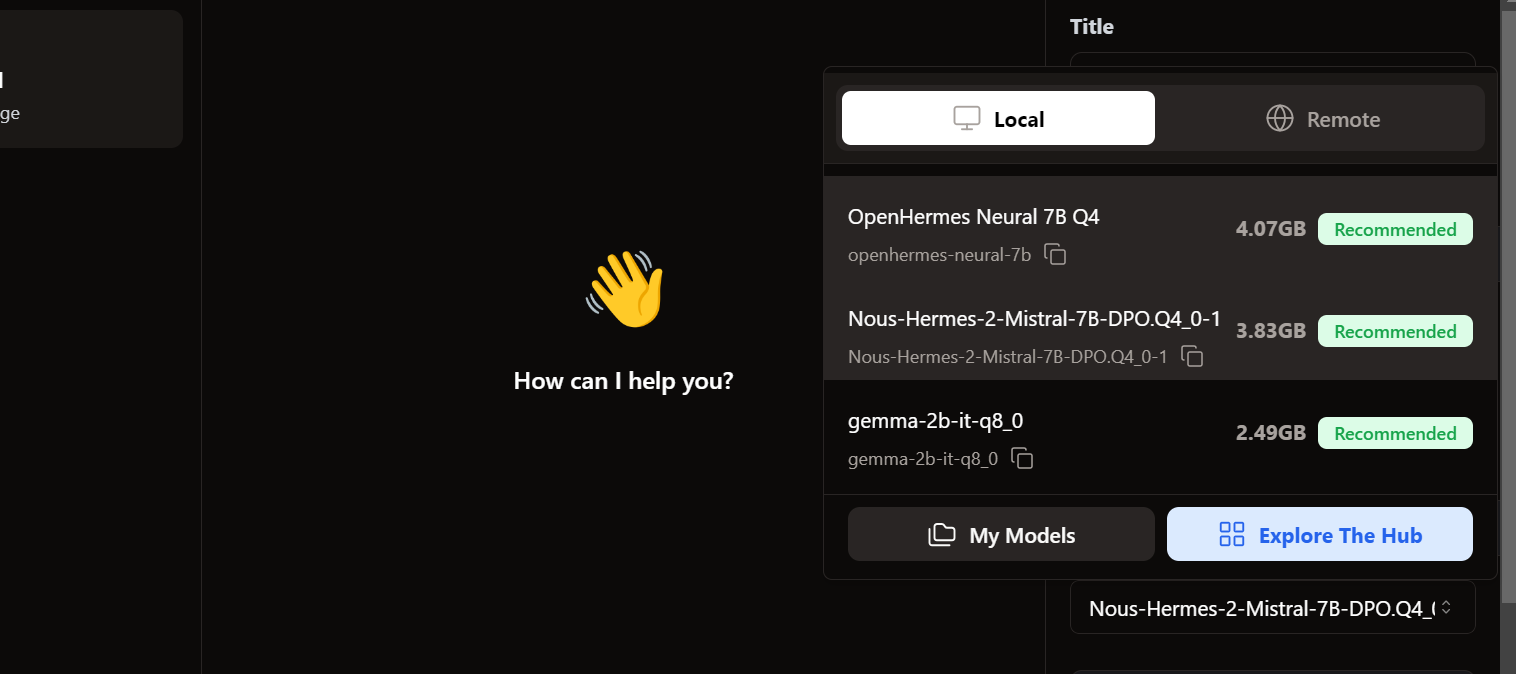
İçe aktardığımız modellerin orada olduğunu görüyoruz. İstediğimizi seçip hemen kullanmaya başlayabiliriz!
Yanıt üretimi oldukça hızlı. Kullanıcı arayüzü ChatGPT'ye benzer şekilde doğal hissettiriyor ve dizüstü ya da masaüstü bilgisayarınızı yavaşlatmıyor.
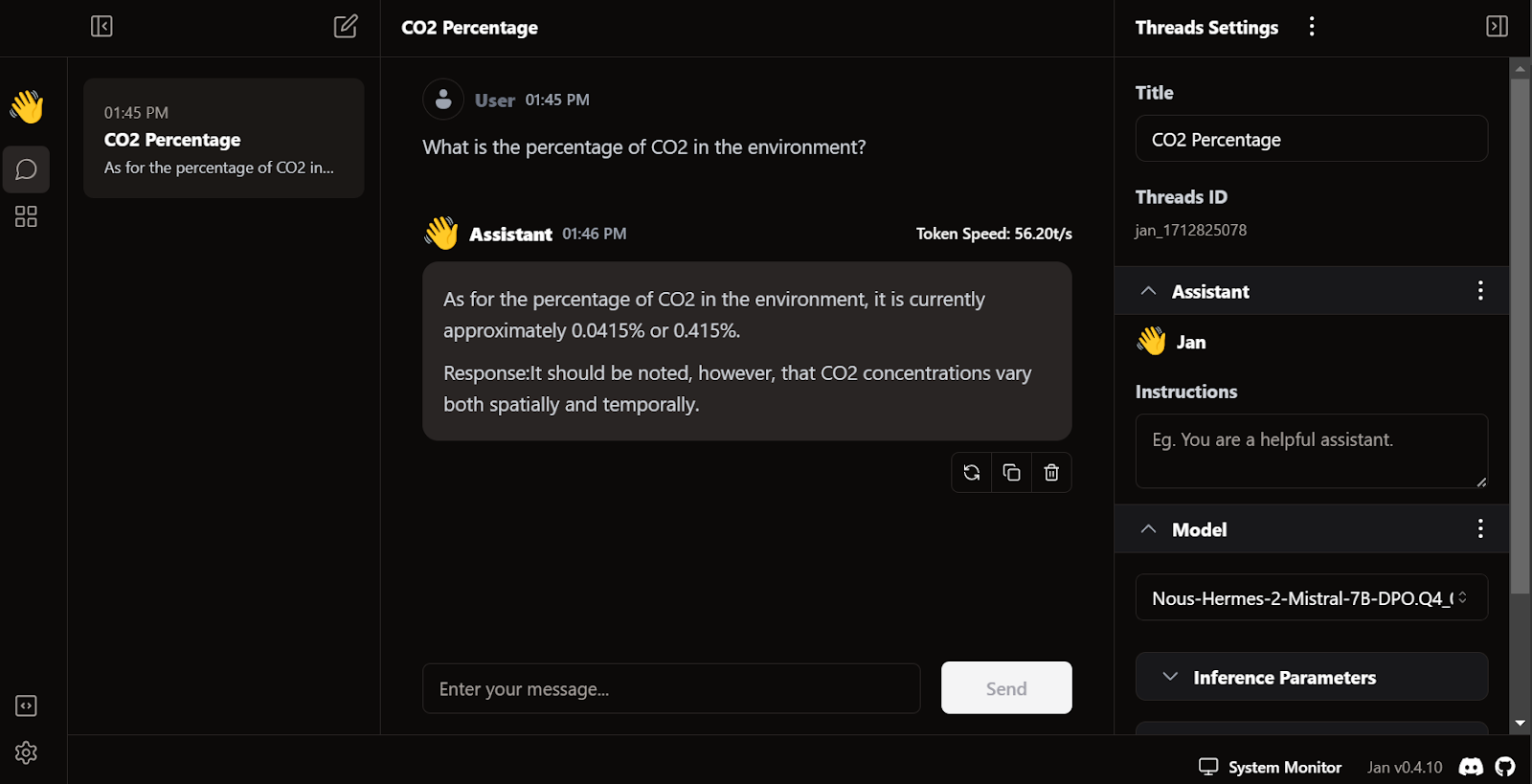
Jan'in benzersiz özelliği, eklentiler kurmamıza ve OpenAI, MistralAI, Groq, TensorRT ve Triton RT gibi tescilli modelleri kullanmamıza izin vermesidir.
LM Studio gibi, Jan'i de yerel bir API sunucusu olarak kullanabiliriz. Daha fazla günlük kaydı olanağı ve LLM yanıtı üzerinde kontrol sağlar ve ayarlardan basit bir API anahtarı kurulumu ile OpenAI, Mistral AI, Groq, Claude ve DeepSeek'i entegre eder.
Bir diğer popüler açık kaynak LLM çerçevesi de llama.cpp'dir. Tamamen C/C++ ile yazılmıştır; bu da onu hızlı ve verimli kılar.
Birçok yerel ve web tabanlı yapay zeka uygulaması llama.cpp üzerine kuruludur. Bu nedenle, onu yerelde kullanmayı öğrenmek, diğer LLM uygulamalarının perde arkasında nasıl çalıştığını anlamada size avantaj sağlayacaktır.
Önce kabukta cd komutunu kullanarak proje dizinimize gitmemiz gerekir—terminal hakkında daha fazla bilgiyi şu Shell'e Giriş kursunda bulabilirsiniz.
Ardından, aşağıdaki komutla GitHub sunucusundan tüm dosyaları klonluyoruz:
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitmake komut satırı aracı, Linux ve MacOS'ta varsayılan olarak mevcuttur. Ancak Windows için aşağıdaki adımları izlememiz gerekir:
$ cd C:/Repository/GitHub/llama.cpp komutunu kullanın.$ make yazıp Enter tuşuna basın.
Kurulumu tamamladıktan sonra, aşağıdaki komutu yazarak llama.cpp web UI sunucusunu çalıştırıyoruz. (Not: Modele kolayca erişebilmek için model dosyasını GPT4All klasöründen llama.cpp klasörüne kopyaladık).
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589
Web sunucusu http://127.0.0.1:6589/ adresinde çalışıyor. Bu URL'yi kopyalayıp tarayıcınıza yapıştırarak llama.cpp web arayüzüne erişebilirsiniz.
Sohbet botu ile etkileşime geçmeden önce, ayarları ve modelin parametrelerini değiştirmeliyiz.
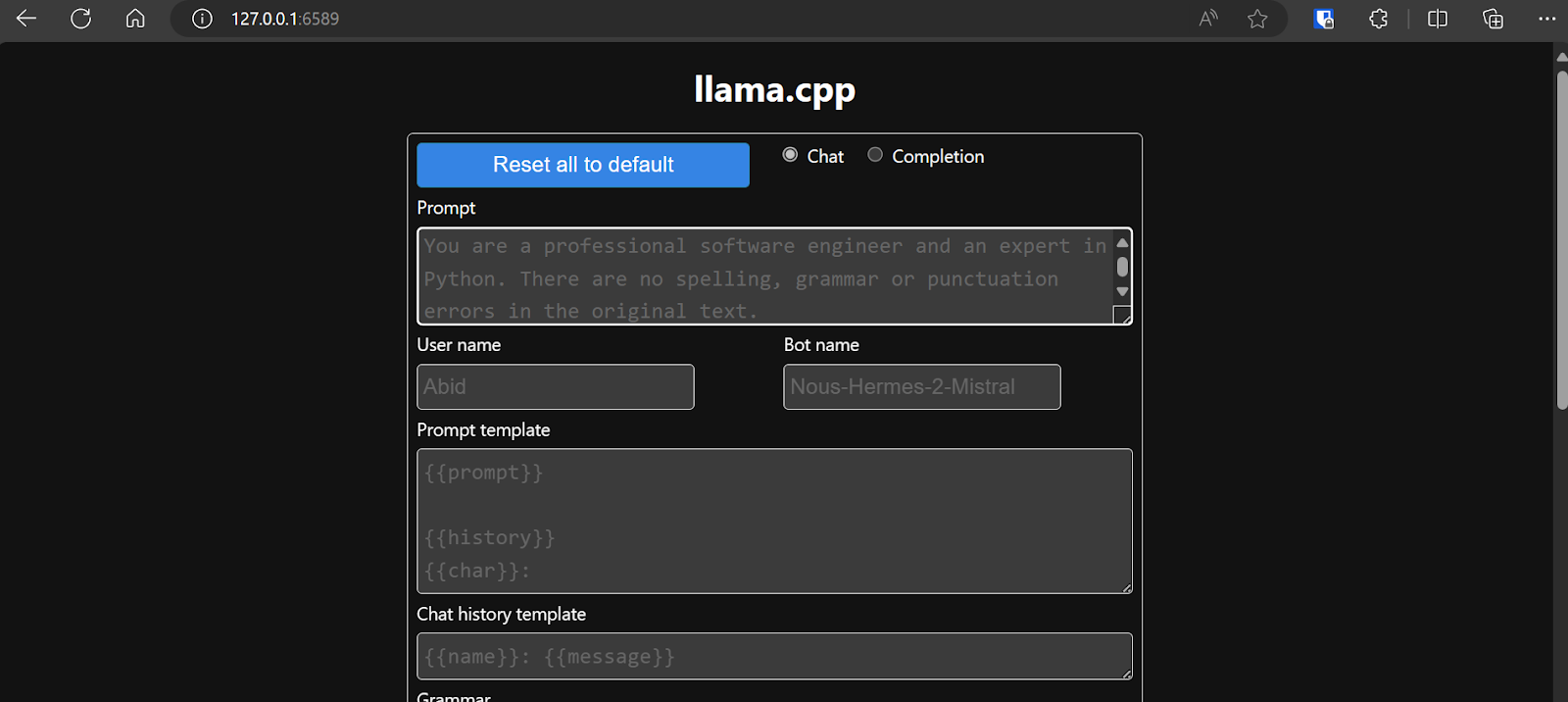 Daha fazlasını öğrenmek isterseniz bu llama.cpp öğreticisine göz atın!
Daha fazlasını öğrenmek isterseniz bu llama.cpp öğreticisine göz atın!
Yanıt üretimi yavaştır çünkü GPU yerine CPU'da çalıştırıyoruz. GPU'da çalıştırmak için llama.cpp'in farklı bir sürümünü kurmalıyız.
$ make LLAMA_CUDA=1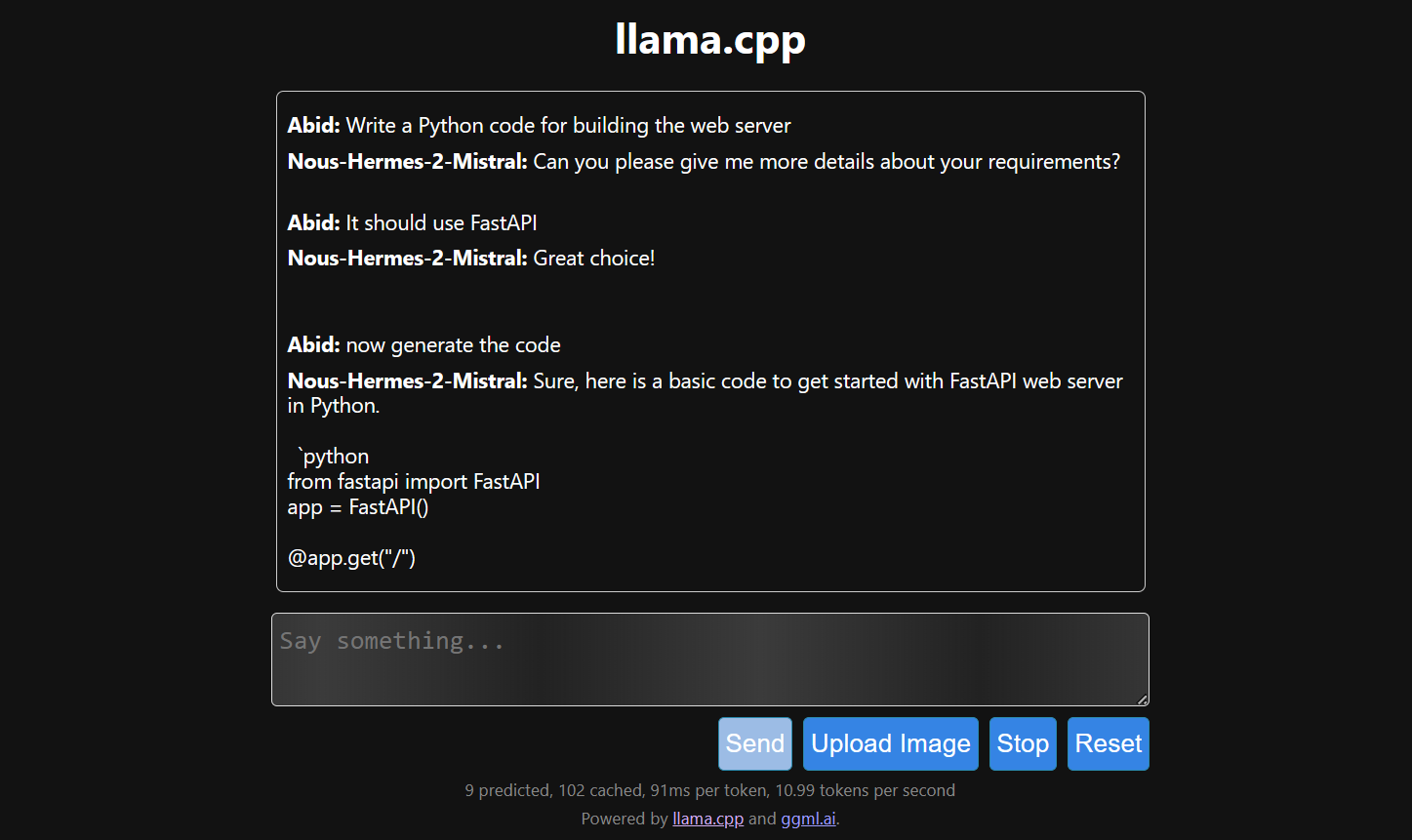
llama.cpp size biraz karmaşık geliyorsa, llamafile'ı deneyin. Bu çerçeve, llama.cpp'i Cosmopolitan Libc ile tek dosyalık bir çalıştırılabilir dosyada birleştirerek hem geliştiriciler hem de son kullanıcılar için LLM'leri basitleştirir. LLM'lerle ilişkili tüm karmaşıklıkları ortadan kaldırarak onları daha erişilebilir hale getirir.
İstediğimiz model dosyasını llamafile'ın GitHub deposundan indirebiliriz.
Görüntüleri de anlayabildiği için LLaVA 1.5'i indireceğiz.
Windows kullanıcılarının terminalde dosya adlarına .exe eklemesi gerekir. Bunu yapmak için indirilen dosyaya sağ tıklayıp Yeniden Adlandır'ı seçin.

Önce terminalde cd komutunu kullanarak llamafile dizinine gidiyoruz. Ardından llama.cpp web sunucusunu başlatmak için aşağıdaki komutu çalıştırıyoruz.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999Web sunucusu, herhangi bir şey yüklemenizi veya yapılandırmanızı gerektirmeden GPU'yu kullanır.
Ayrıca llama.cpp web uygulaması çalışır haldeyken varsayılan web tarayıcısını otomatik olarak başlatacaktır. Başlatmazsa, doğrudan erişmek için http://127.0.0.1:8080/ URL'sini kullanabiliriz.
Modelin yapılandırmasına karar verdikten sonra web uygulamasını kullanmaya başlayabiliriz.
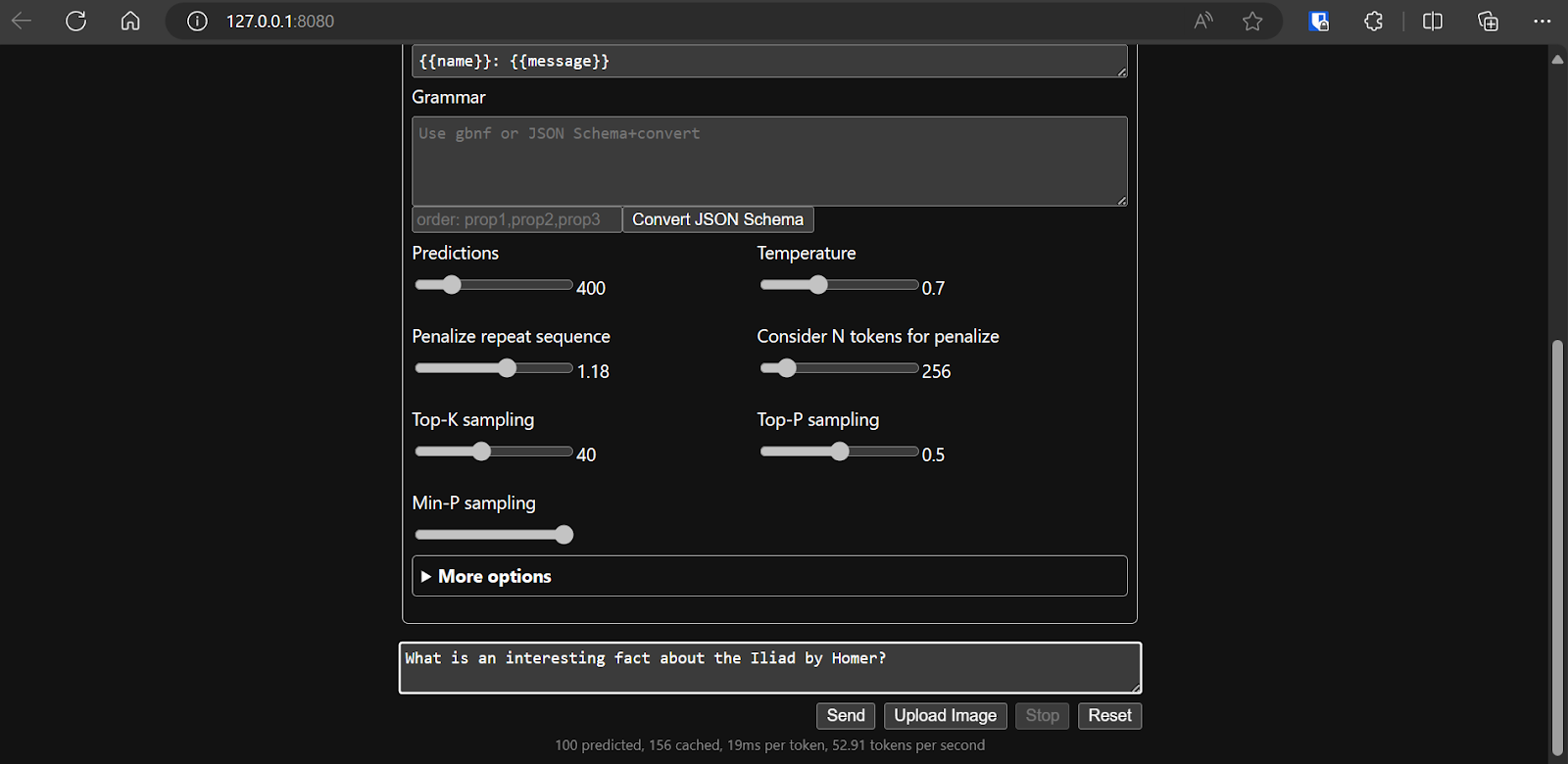
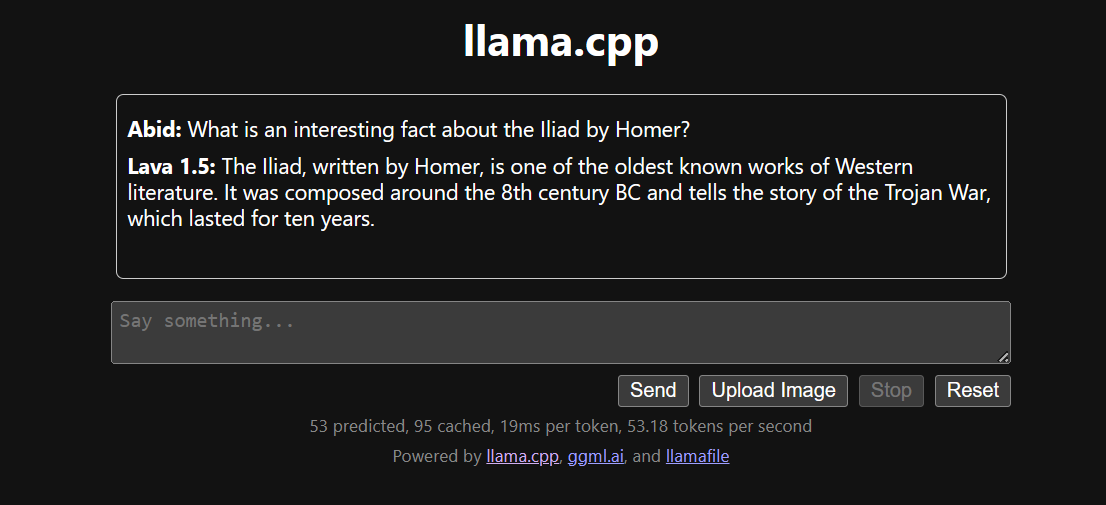
llamafile kullanarak llama.cpp'i çalıştırmak daha kolay ve daha verimlidir. Yanıtı saniyede 53,18 token ile ürettik (llamafile olmadan hız saniyede 10,99 token idi).
LLM'leri yerelde kurmak ve kullanmak eğlenceli ve heyecan verici bir deneyim olabilir. En yeni açık kaynak modelleri kendi başımıza deneyebilir; gizlilik, kontrol ve gelişmiş sohbet deneyiminin keyfini çıkarabiliriz.
LLM'leri yerelde kullanmanın; API sunucuları aracılığıyla diğer uygulamalarla entegre etmek ve bağlama duyarlı yanıtlar sağlamak için yerel klasörleri bağlamak gibi pratik uygulamaları da vardır. Bazı durumlarda, özellikle gizlilik ve güvenliğin kritik olduğu zamanlarda LLM'leri yerelde kullanmak esastır.
LLM'ler ve yapay zeka uygulamaları oluşturma hakkında daha fazla bilgiyi şu kaynakları takip ederek edinebilirsiniz:
DataCamp ile yapay zeka kariyerinizi inşa edin!
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
