
Cursus
Principes fondamentaux de l'intelligence artificielle dans le monde des affaires
12 h
L'utilisation de grands modèles linguistiques (LLM) sur des systèmes locaux gagne en popularité en raison de leur confidentialité, de leur contrôle et de leur fiabilité améliorés. Parfois, ces modèles peuvent être encore plus précis et plus rapides que chatGPT.
Nous vous présenterons sept méthodes pour exécuter des LLM localement avec accélération GPU sous Windows 11, mais les méthodes que nous abordons fonctionnent également sous macOS et Linux.
Si vous souhaitez acquérir des connaissances approfondies sur les LLM, nous vous recommandons de commencer par ce cours sur les grands modèles d'apprentissage (LLM).
Commençons par examiner notre premier cadre LLM.
Ollama est l'écosystème dominant pour l'exécution de modèles d'apprentissage automatique (LLM) tels que Llama 4, Mistral 3et Gemma 3 localement.
De plus, plusieurs applications acceptent l'intégration d'Ollama, ce qui en fait un excellent outil pour accéder plus rapidement et plus facilement aux modèles linguistiques sur notre machine locale.
Ollama offre désormais une compatibilité totale avec l'API OpenAI, ce qui en fait un substitut direct au service cloud d'OpenAI. Les fonctionnalités récentes comprennent l'appel de fonctions, la sortie JSON structurée, Flash Attention pour les modèles de vision et une inférence 30 % plus rapide sur les processeurs Apple Silicon et les GPU AMD.
Nous pouvons télécharger Ollama depuis la page de téléchargement.
Une fois l'installation effectuée (en utilisant les paramètres par défaut), le logo Ollama apparaîtra dans la barre d'état système.
Nous pouvons télécharger le modèle Llama 3 en saisissant la commande suivante dans le terminal :
$ ollama run llama3Llama 3 est désormais prêt à l'emploi. Ci-dessous, nous présentons une liste des commandes à utiliser si nous souhaitons employer d'autres modèles d'apprentissage automatique (LLM) :
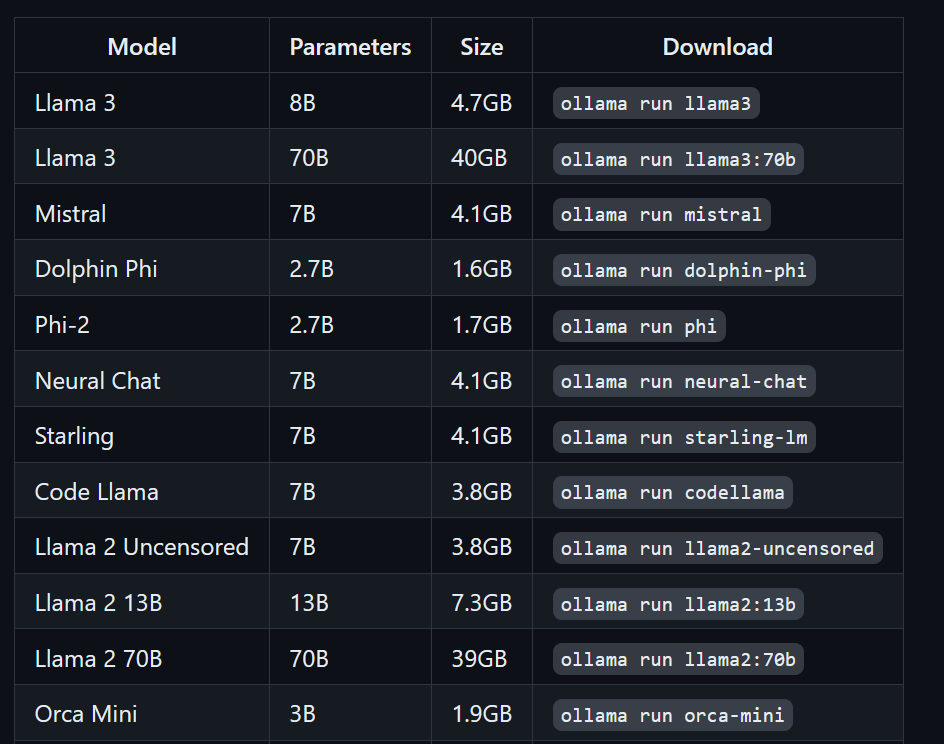
Pour accéder aux modèles déjà téléchargés et disponibles dans le dossier llama.cpp, nous devons :
cd.$ cd C:/Repository/GitHub/llama.cppModelfile et y ajouter la ligne "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf".$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bGrâce à cette méthode, nous pouvons télécharger n'importe quel LLM depuis Hugging Face avec l'extension .gguf et l'utiliser dans le terminal. Si vous souhaitez en savoir plus, veuillez consulter ce cours sur l'utilisation de Hugging Face.
LM Studio est un environnement de travail tout-en-un permettant d'exécuter des modèles d'apprentissage automatique (LLM) localement et offrant des fonctionnalités de réglage fin en mode natif. En outre, il prend en charge plusieurs modèles simultanés, le décodage spéculatif (tokens 1,5 à 3 fois plus rapides) et l'intégration RAG de documents.
Nous pouvons télécharger le programme d'installation depuis la page d'accueil de LM Studio.
Une fois le téléchargement terminé, nous installons l'application avec les options par défaut.
Enfin, nous avons le plaisir de vous annoncer le lancement de LM Studio.
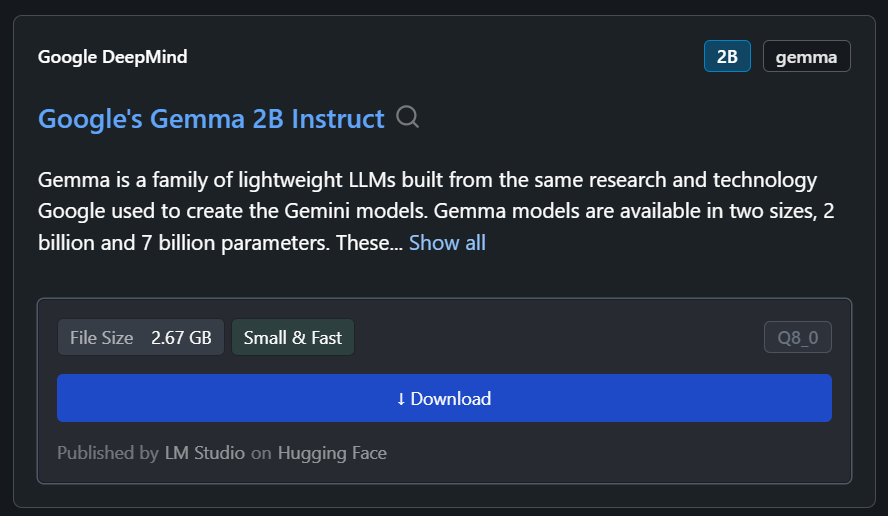
Nous pouvons télécharger n'importe quel modèle depuis Hugging Face en utilisant la fonction de recherche.
Dans notre cas, nous téléchargerons le modèle le plus petit, Gemma 2B Instruct de Google.
Nous pouvons sélectionner le modèle téléchargé dans le menu déroulant en haut et discuter avec lui comme d'habitude. LM Studio propose davantage d'options de personnalisation que GPT4All.
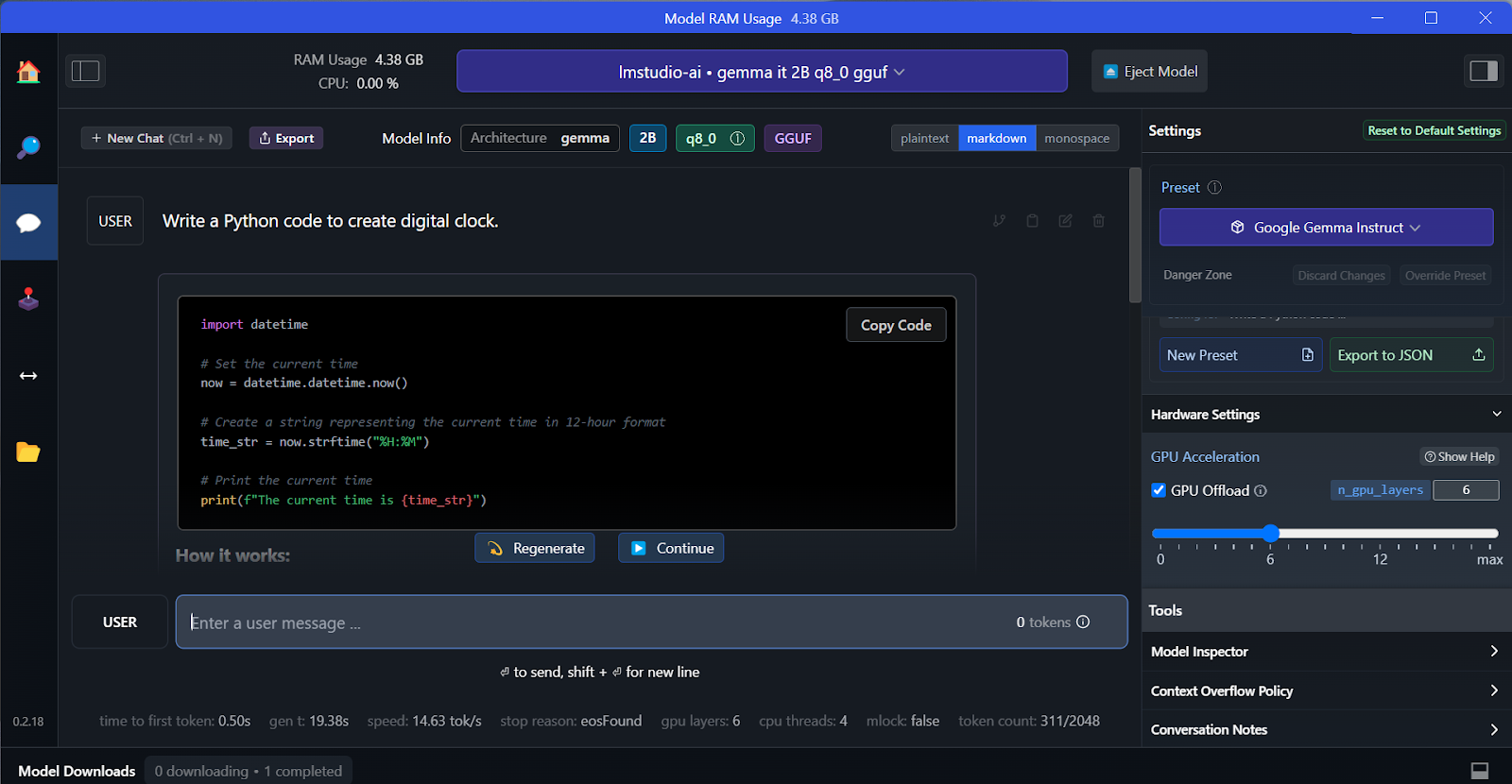
Tout comme GPT4All, nous pouvons personnaliser le modèle et lancer le serveur API en un seul clic. Pour accéder au modèle, nous pouvons utiliser le package Python OpenAI API, CURL, ou l'intégrer directement à n'importe quelle application.
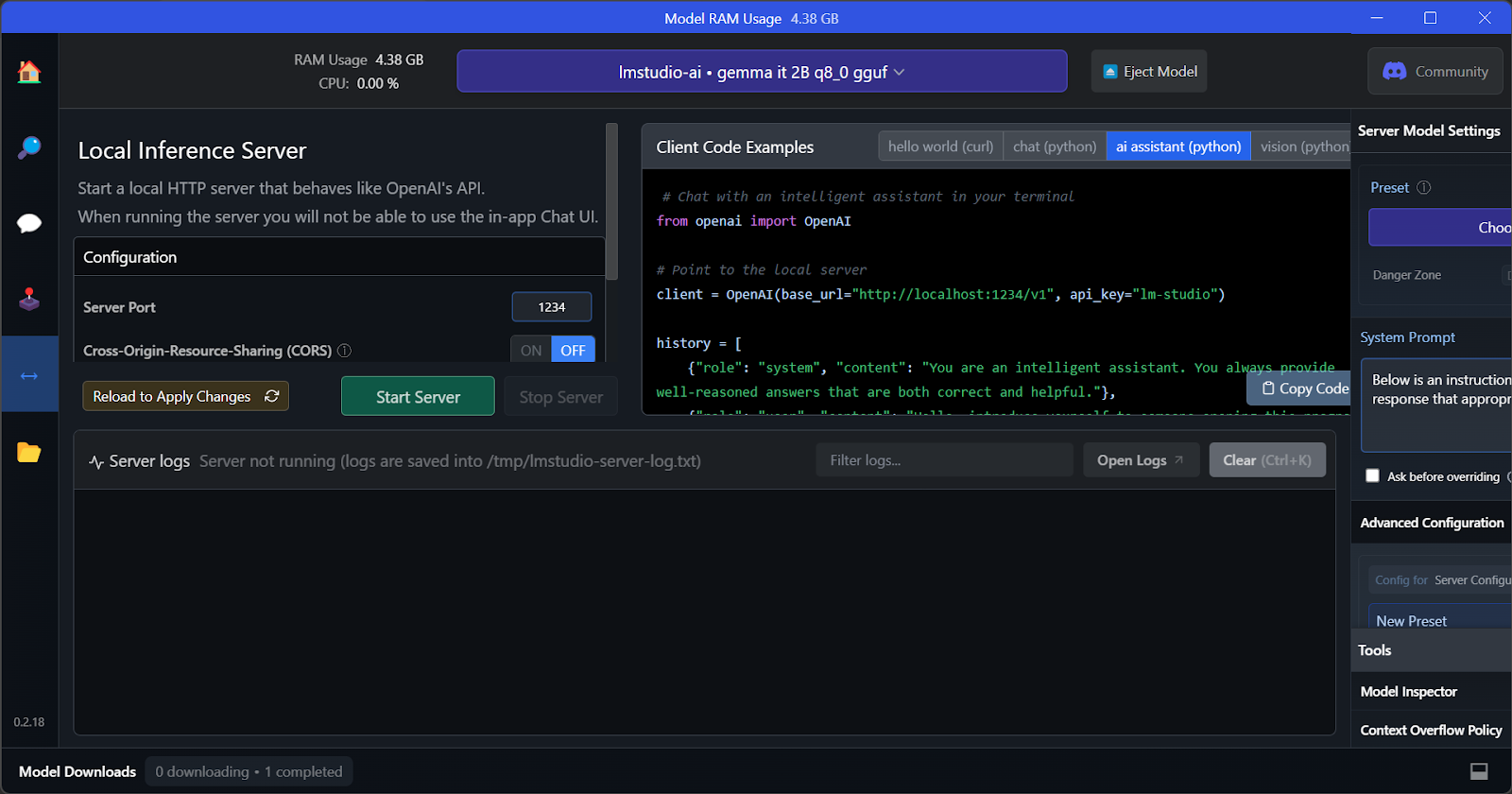
La principale caractéristique de LM Studio est qu'il offre la possibilité d'exécuter et de servir plusieurs modèles simultanément. Cela permet aux utilisateurs de comparer les résultats de différents modèles et de les utiliser pour de multiples applications. Afin de pouvoir exécuter plusieurs sessions de modélisation, nous avons besoin d'une mémoire VRAM GPU élevée.
Le réglage fin est une autre méthode permettant de générer des réponses personnalisées et adaptées au contexte. Vous pouvez apprendre à affiner votre modèle Google Gemma en suivant le tutoriel Affiner Google Gemma : Améliorer les modèles linguistiques à grande échelle grâce à des instructions personnalisées. Vous apprendrez à effectuer des inférences sur des GPU/TPU et à affiner le dernier modèle Gemma 7b-it sur un ensemble de données de jeux de rôle.
vLLM est un moteur d'inférence open source permettant d'exécuter des LLM à l'échelle de la production. Contrairement à Ollama ou LM Studio, vLLM privilégie le débit et la latence pour les scénarios multi-utilisateurs.
Sa principale innovation réside dans PagedAttention, qui gère la mémoire GPU comme une mémoire virtuelle, en réutilisant de petites pages au lieu de réserver des blocs volumineux, combiné à un traitement par lots continu. Les tests de performance réels démontrent que le vLLM fournit 793 tokens par seconde sur Llama 70B, contre 41 tokens par seconde pour Ollama sous une charge simultanée.
vLLM prend également en charge le parallélisme tensoriel entre les GPU, la mise en cache des préfixes et le traitement par lots multi-LoRA pour servir simultanément des variantes affinées.
Sur Mac et Linux, vLLM peut être facilement installé à l'aide de pip.
Sous Linux avec CUDA 11.8+ :
pip install vllmSur macOS avec Apple Silicon :
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmIl n'existe actuellement aucune assistance officielle pour Windows. Il existe toutefois des solutions de contournement via WSL2 ou Docker.
Veuillez démarrer le serveur compatible avec OpenAI :
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Pour les modèles 70B sur plusieurs GPU :
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Pour le traitement par lots en Python :
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Pour effectuer une requête, veuillez utiliser le SDK OpenAI :
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Une autre option consiste à l'exécuter via cURL :
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Veuillez choisir vLLM pour les API de production desservant des centaines d'utilisateurs simultanés ; veuillez utiliser Ollama pour le développement local.
L'une des applications LLM locales les plus populaires et les plus esthétiques est Jan. Il s'agit d'une alternative à chatGPT qui privilégie la confidentialité.
Nous pouvons télécharger le programme d'installation depuis Jan.ai.
Une fois l'application Jan installée avec les paramètres par défaut, nous sommes prêts à la lancer.
Lorsque nous avons présenté GPT4All et LM Studio, nous avons déjà téléchargé deux modèles. Au lieu d'en télécharger un autre, nous allons importer ceux que nous avons déjà en nous rendant sur la page du modèle et en cliquant sur le bouton Importer le modèle.
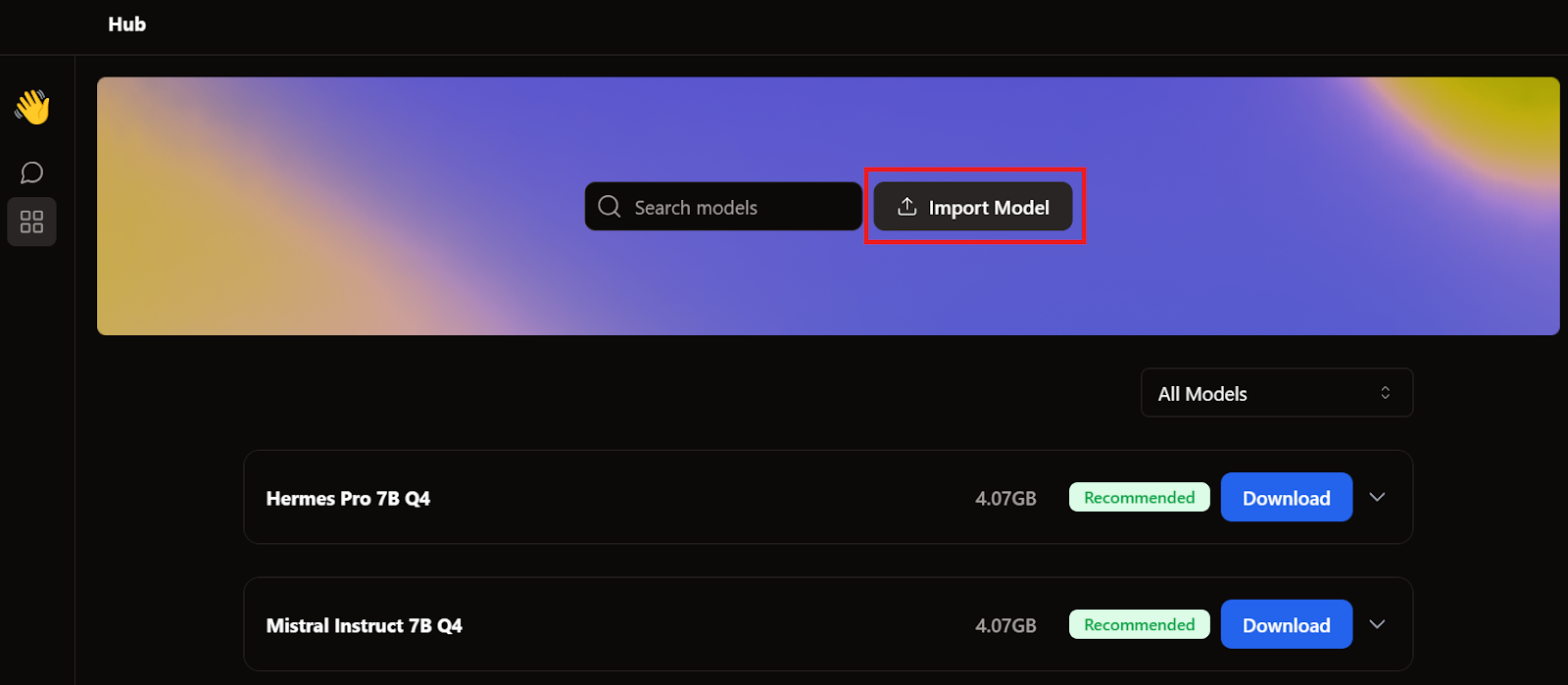
Ensuite, nous accédons au répertoire des applications, sélectionnons les modèles GPT4All et LM Studio, puis importons chacun d'eux.
Pour accéder aux modèles locaux, nous nous rendons dans l'interface utilisateur du chat et ouvrons la section des modèles dans le panneau de droite.
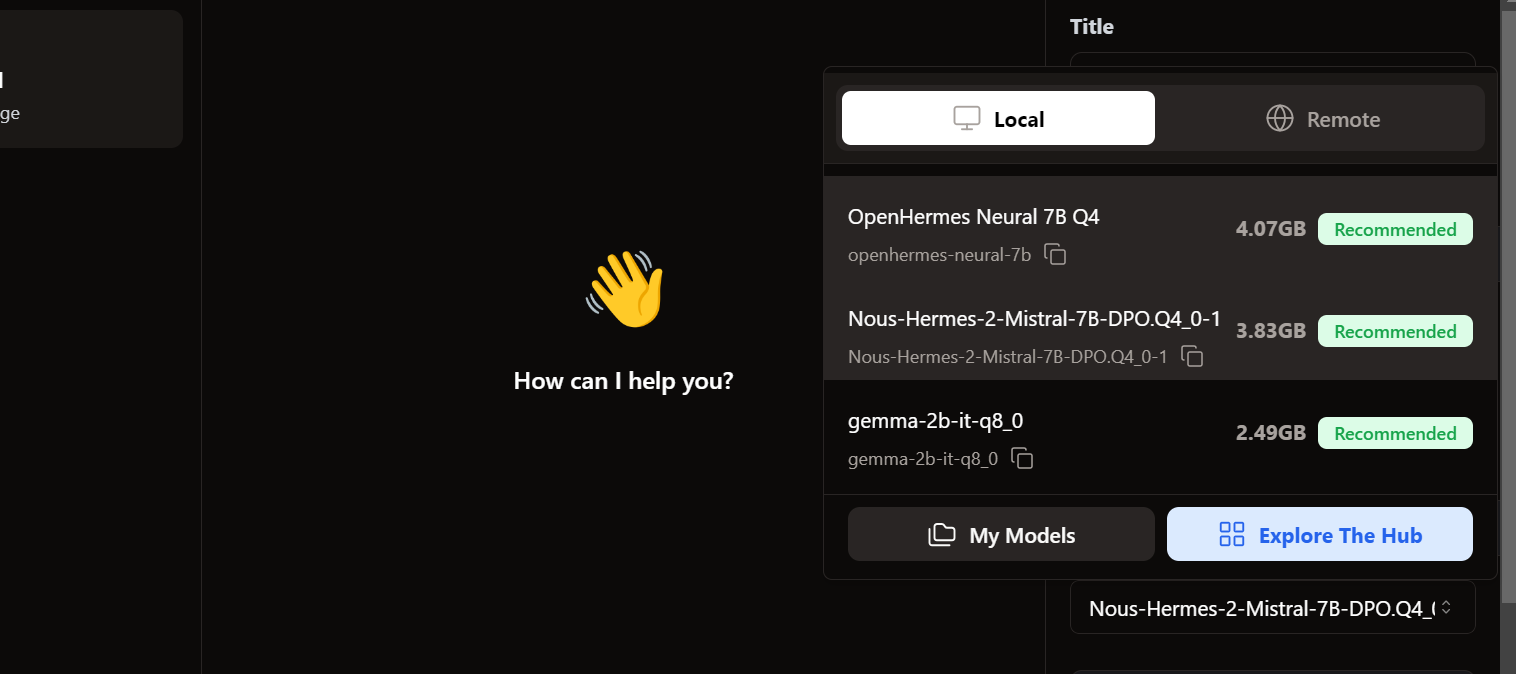
Nous constatons que nos modèles importés sont déjà présents. Nous pouvons sélectionner celui qui nous convient et commencer à l'utiliser immédiatement.
La génération de réponses est extrêmement rapide. L'interface utilisateur est intuitive, similaire à celle de chatGPT, et n'affecte pas les performances de votre ordinateur portable ou de bureau.
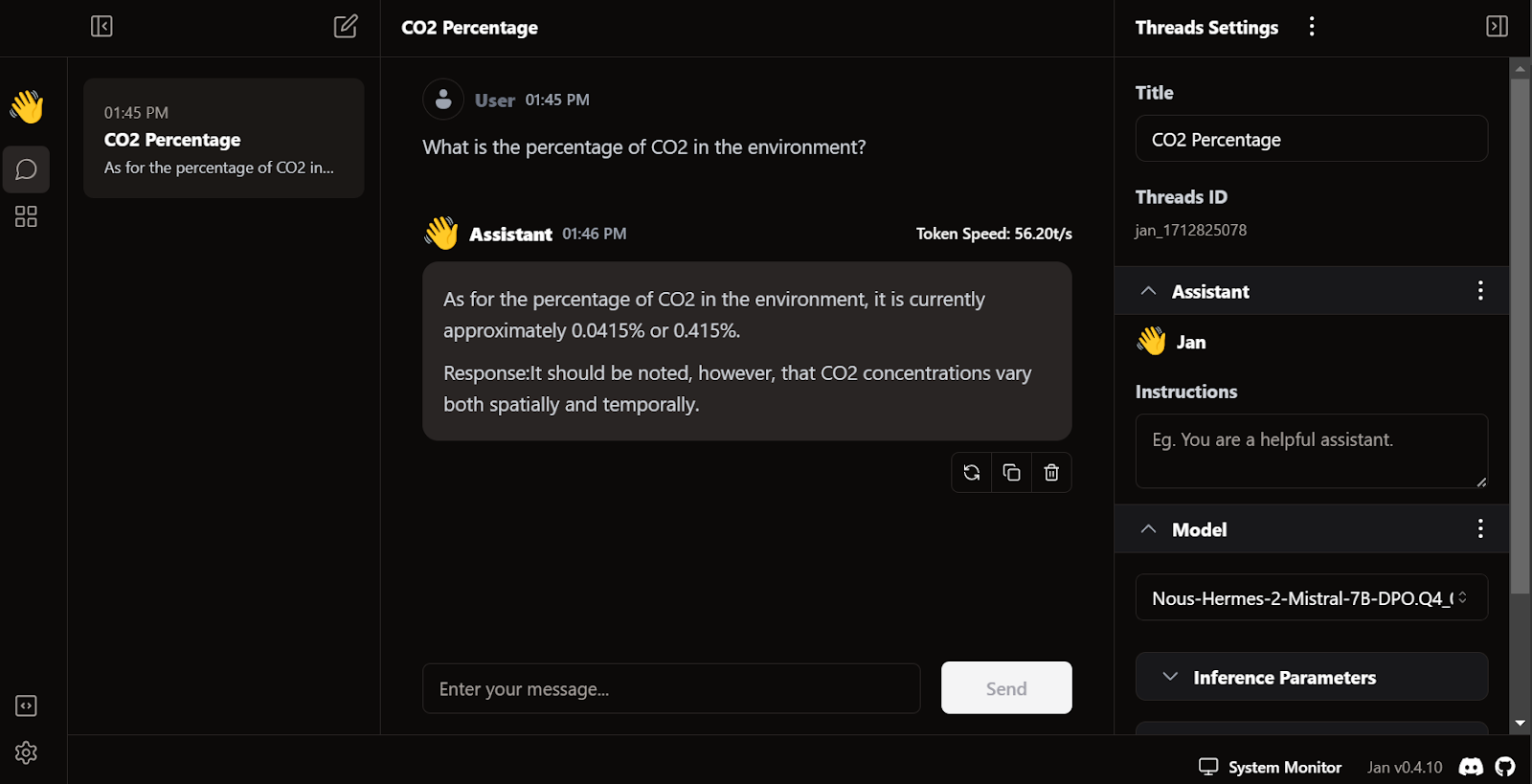
La particularité de Jan réside dans le fait qu'il nous permet d'installer des extensions et d'utiliser des modèles propriétaires provenant d'OpenAI, MistralAI, Groq, TensorRT et Triton RT.
À l'instar de LM Studio, nous pouvons également utiliser Jan comme serveur API local. Il offre davantage de fonctionnalités de journalisation et de contrôle sur la réponse LLM, et intègre OpenAI, Mistral AI, Groq, Claude et DeepSeek via une simple configuration de clé API dans les paramètres.
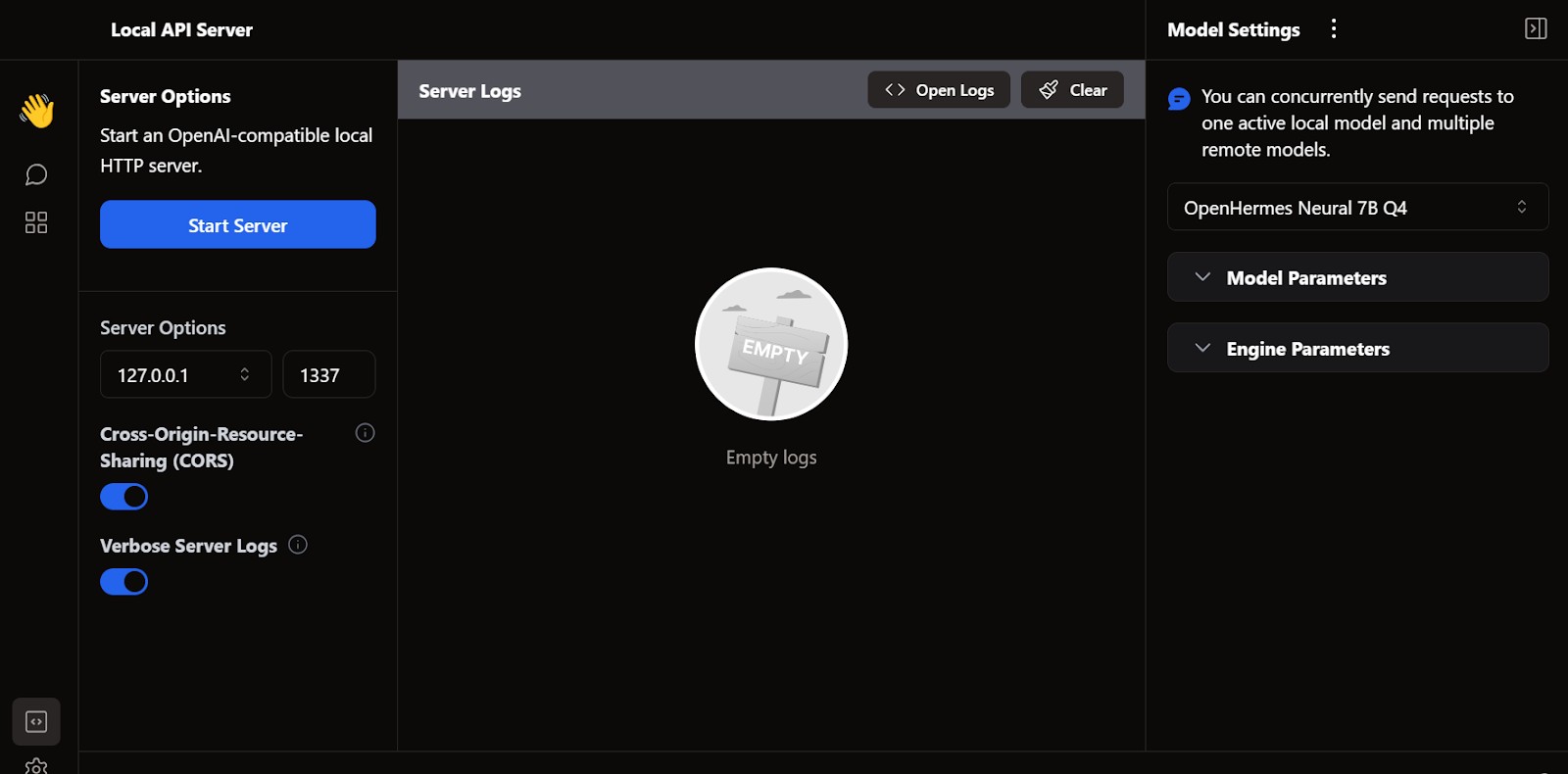
Un autre framework LLM open source très apprécié est llama.cpp. Il est entièrement écrit en C/C++, ce qui le rend rapide et efficace.
De nombreuses applications d'IA locales et basées sur le Web sont développées à partir de llama.cpp. Ainsi, apprendre à l'utiliser localement vous donnera un avantage pour comprendre comment les autres applications LLM fonctionnent en arrière-plan.
Tout d'abord, nous devons accéder au répertoire de notre projet à l'aide de la commande ` cd ` dans le shell. Vous pouvez en apprendre davantage sur le terminal dans ce cours intitulé Introduction au shell.
Ensuite, nous clonons tous les fichiers depuis le serveur GitHub à l'aide de la commande ci-dessous :
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitL'outil en ligne de commande make est disponible par défaut sous Linux et MacOS. Pour Windows, cependant, il est nécessaire de suivre les étapes suivantes :
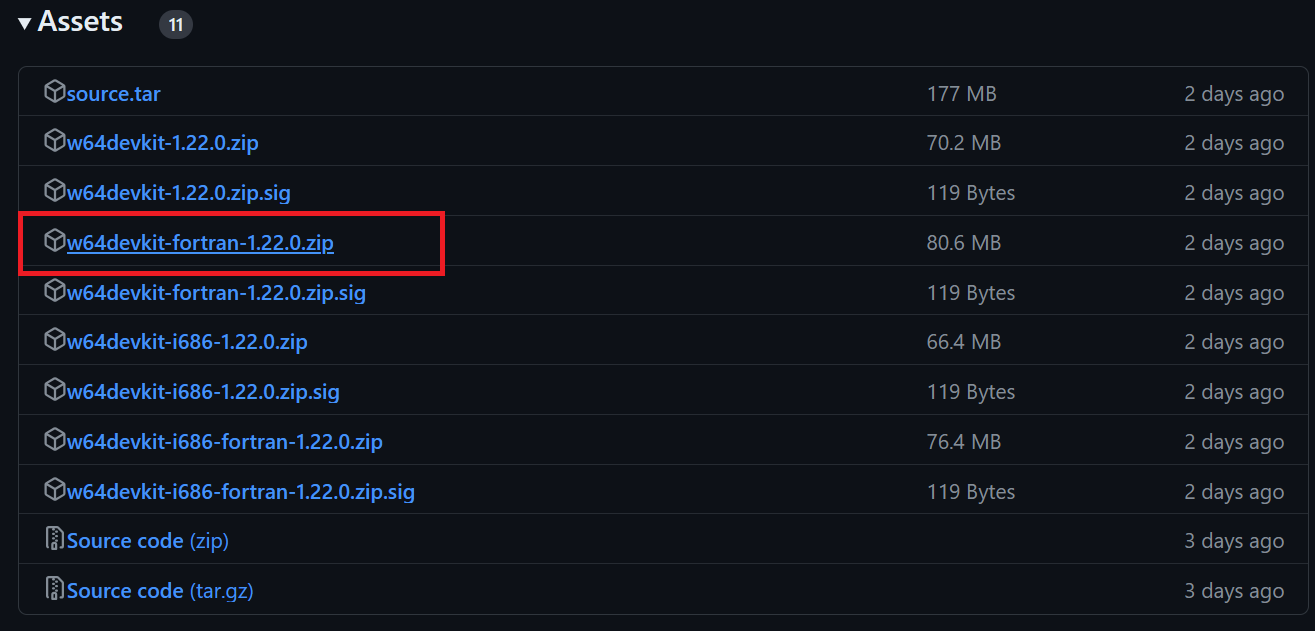
$ cd C:/Repository/GitHub/llama.cpp pour accéder au dossier llama.cpp.$ make » et appuyer sur Entrée pour installer llama.cpp.
Une fois l'installation terminée, nous lançons le serveur d'interface utilisateur web llama.cpp en saisissant la commande ci-dessous. (Remarque : Nous avons transféré le fichier modèle du dossier GPT4All vers le dossier llama.cpp afin de pouvoir accéder facilement au modèle.
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589
Le serveur web est accessible à l'adresse http://127.0.0.1:6589/. Vous pouvez copier cette URL et la coller dans votre navigateur pour accéder à l'interface web llama.cpp.
Avant d'interagir avec le chatbot, il est nécessaire de modifier les paramètres et les paramètres du modèle.
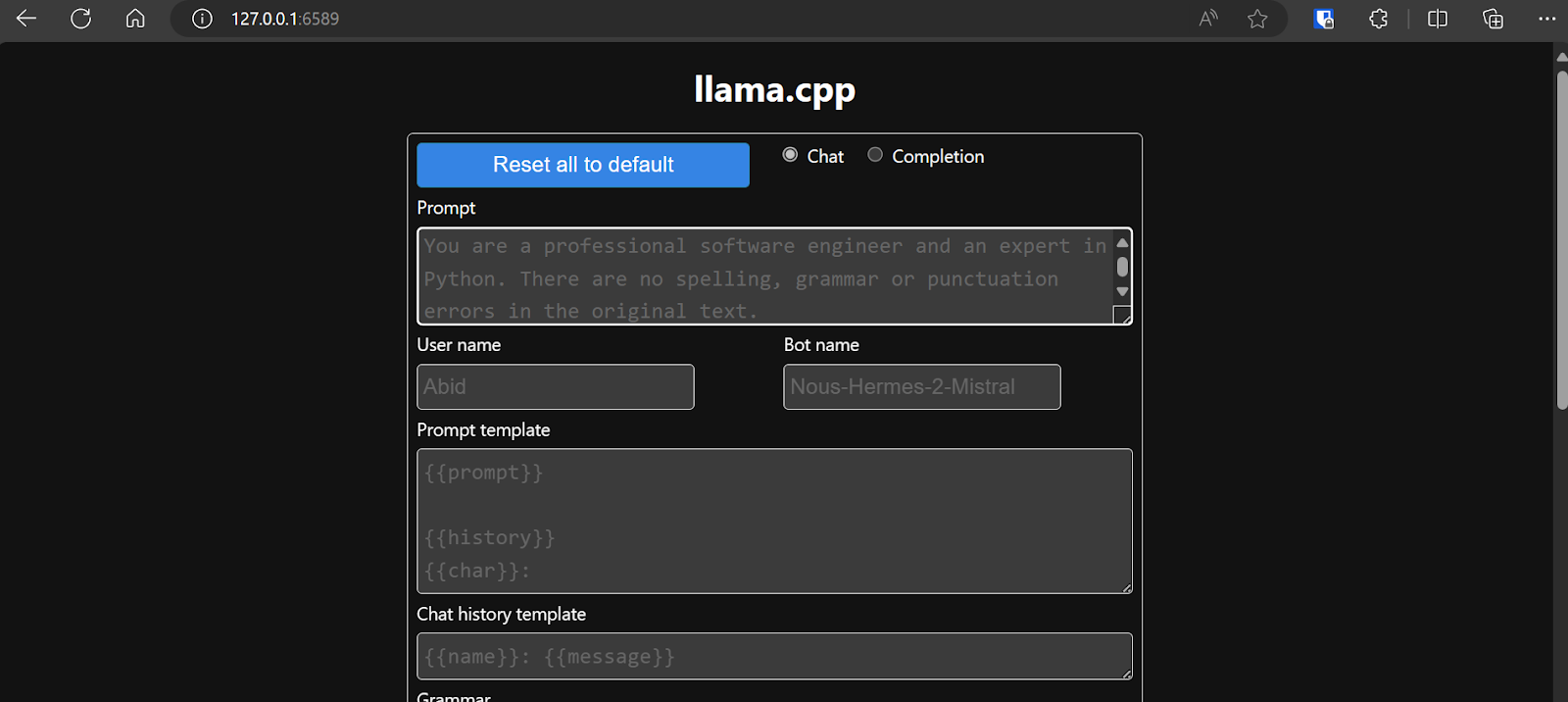 Veuillez consulter ce tutoriel llama.cpp si vous souhaitez en savoir plus.
Veuillez consulter ce tutoriel llama.cpp si vous souhaitez en savoir plus.
La génération de réponses est lente car nous l'exécutons sur le CPU et non sur le GPU. Il est nécessaire d'installer une version différente de llama.cpp pour l'exécuter sur le GPU.
$ make LLAMA_CUDA=1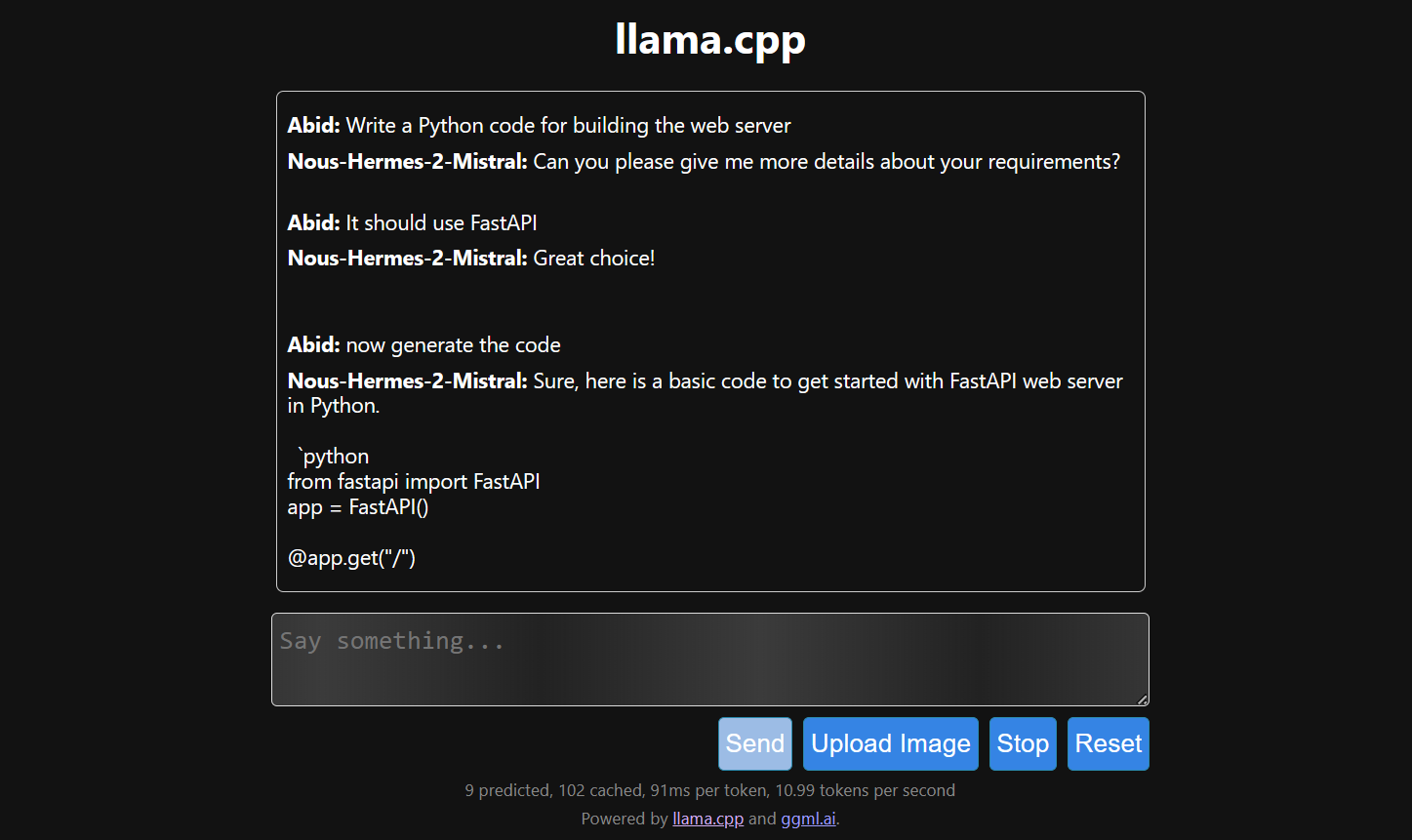
Si vous trouvez llama.cpp un peu trop complexe, veuillez essayer llamafile. Ce cadre simplifie les LLM tant pour les développeurs que pour les utilisateurs finaux en combinant llama.cpp et Cosmopolitan Libc dans un fichier exécutable unique. Il élimine toutes les complexités associées aux LLM, les rendant ainsi plus accessibles.
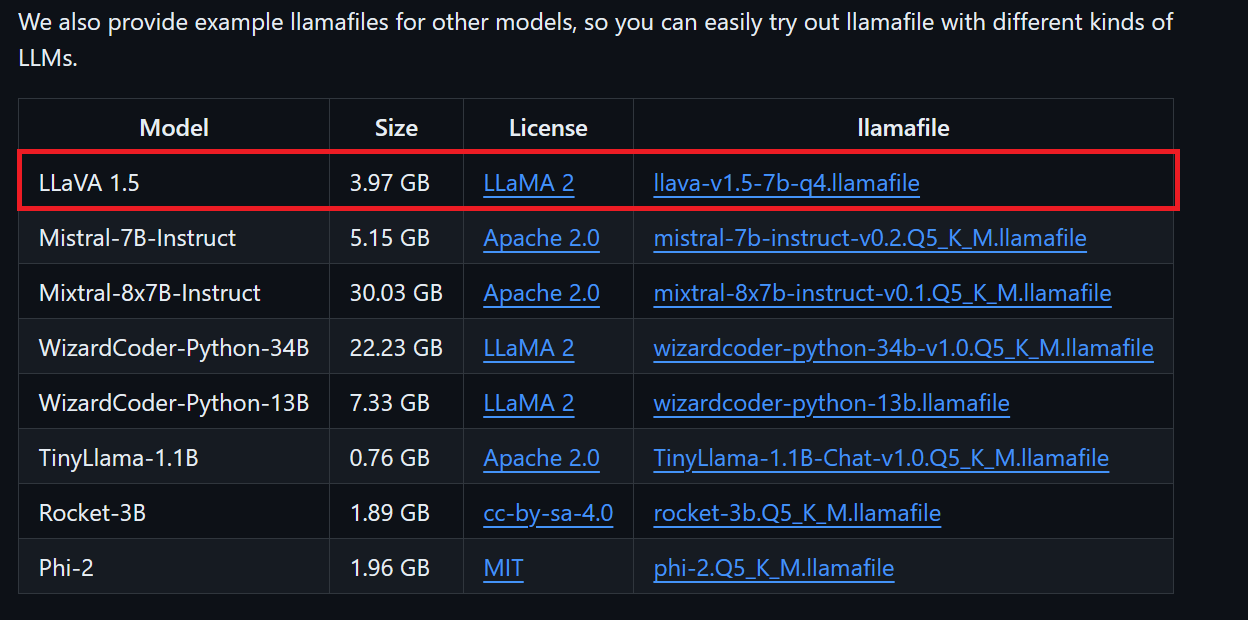
Nous pouvons télécharger le fichier modèle souhaité depuis le référentiel GitHub de llamafile.
Nous allons télécharger LLaVA 1.5, car il est également capable de comprendre les images.
Les utilisateurs Windows doivent ajouter .exe aux noms de fichiers dans le terminal. Pour ce faire, veuillez cliquer avec le bouton droit de la souris sur le fichier téléchargé et sélectionner Renommer.

Nous accédons d'abord au répertoire llamafile en utilisant la commande cd dans le terminal. Ensuite, nous exécutons la commande ci-dessous pour démarrer le serveur web llama.cpp.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999Le serveur Web utilise le GPU sans qu'il soit nécessaire d'installer ou de configurer quoi que ce soit.
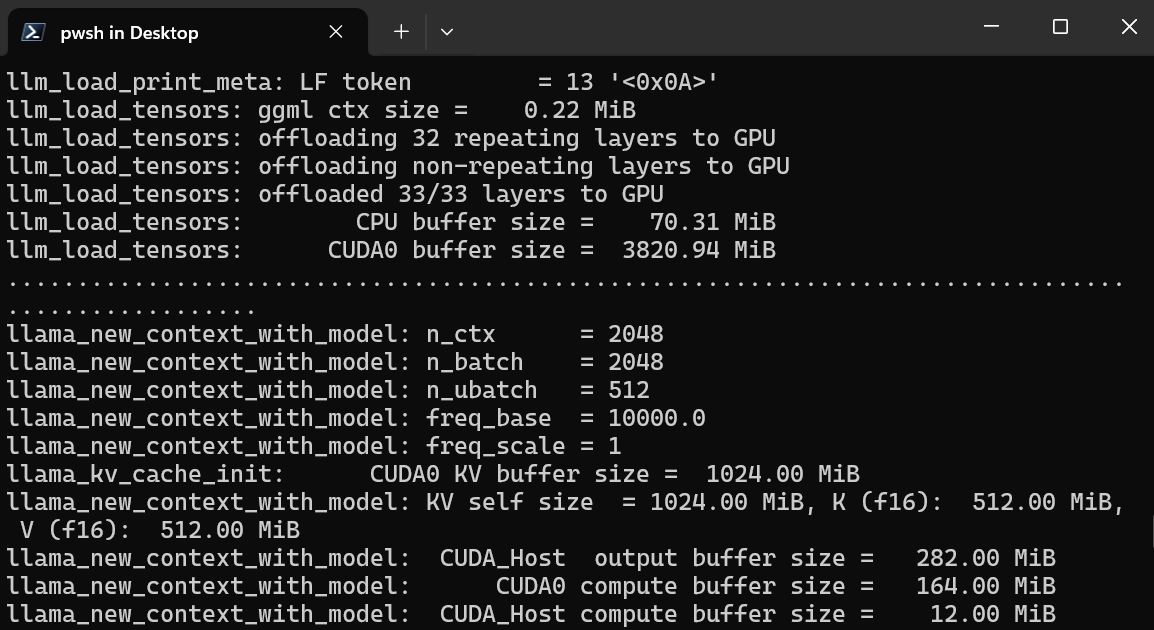
Il lancera également automatiquement le navigateur Web par défaut avec l'application Web llama.cpp en cours d'exécution. Si ce n'est pas le cas, nous pouvons utiliser l'URL http://127.0.0.1:8080/ pour y accéder directement.
Une fois la configuration du modèle définie, nous pouvons commencer à utiliser l'application web.
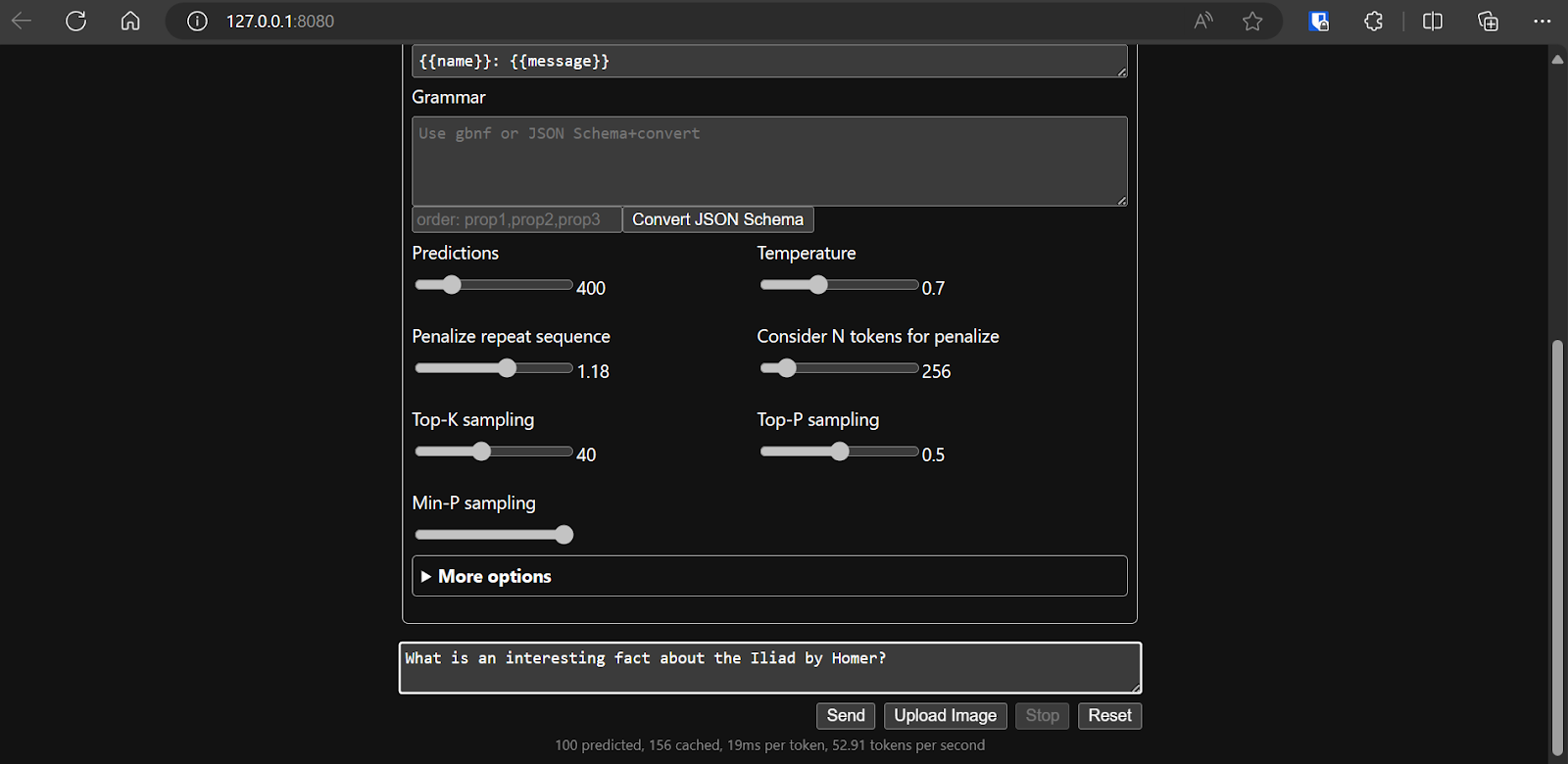
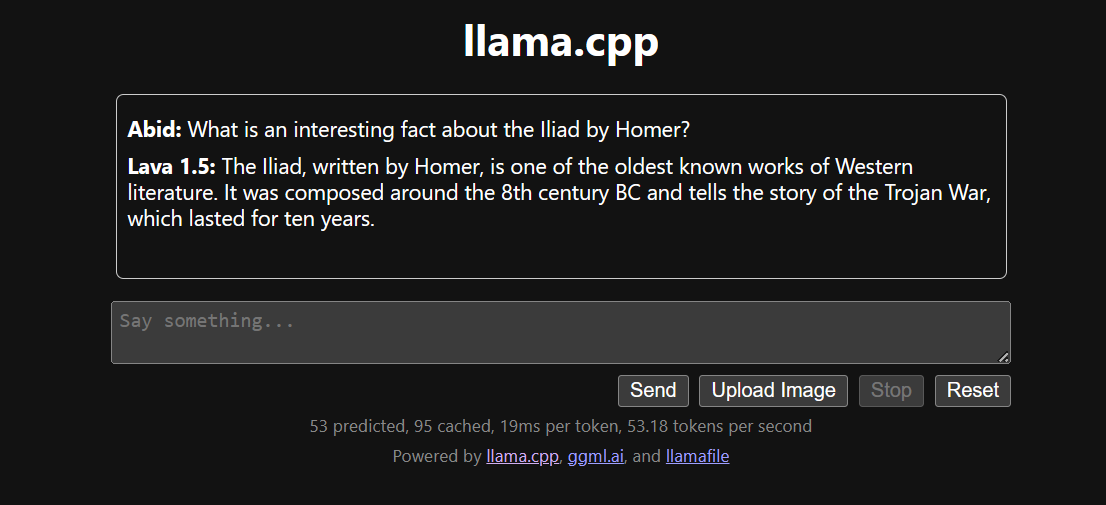
Il est plus simple et plus efficace d'exécuter le fichier llama.cpp à l'aide du fichier llamafile. Nous avons généré la réponse avec 53,18 tokens/seconde (sans llamafile, le taux était de 10,99 tokens/seconde).
L'installation et l'utilisation des LLM localement peuvent constituer une expérience agréable et stimulante. Nous pouvons tester par nous-mêmes les derniers modèles open source, profiter d'une confidentialité et d'un contrôle accrus, ainsi que d'une expérience de chat améliorée.
L'utilisation locale des LLM présente également des applications pratiques, telles que l'intégration à d'autres applications à l'aide de serveurs API et la connexion de dossiers locaux pour fournir des réponses contextuelles. Dans certains cas, il est essentiel d'utiliser les LLM localement, en particulier lorsque la confidentialité et la sécurité sont des facteurs critiques.
Vous pouvez en apprendre davantage sur les LLM et la création d'applications d'IA en consultant les ressources suivantes :
Développez votre carrière dans le domaine de l'IA avec DataCamp.
Cursus
Cours
Cours
blog
Tutoriel
Tutoriel
Mark Pedigo
Tutoriel
Stephen Gruppetta
Tutoriel
Kurtis Pykes
Tutoriel
Adel Nehme
